POPULATION-BASED REINFORCEMENT LEARNING FOR COMBINATORIAL OPTIMIZATION PROBLEMS 学习笔记
Posted 好奇小圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了POPULATION-BASED REINFORCEMENT LEARNING FOR COMBINATORIAL OPTIMIZATION PROBLEMS 学习笔记相关的知识,希望对你有一定的参考价值。
文章目录
摘要
使用强化学习来解决组合优化问题很具有吸引力,因为它去除了专家知识或预解决实例的需求。然而,期待一个智能体(agent)在一次推断中来解决这些困难问题(常常为NP-hard)是不现实的,因为问题内在的复杂性。因此,领先方法通常实现额外的搜索策略,从随机抽样和波束搜索到显式微调。本文中,本文主张学习大量补充政策的好处,它可以在推理时同时推演(rollout)。为此,本文介绍Poppy,一个简单的有理论基础的群(population)训练程序。Poppy没有依赖于预先定义的或手工制作的多样性概念,而是归纳出了一种无监督的专业化(specialization),其目标仅仅是使群的表现最大化。本文展示了Poppy产生了一个补充策略集合,同时获得了一个最先进的RL结果,在三个热门的NP-hard问题:旅行商问题(TSP)、有能力的载具路径规划(CVRP)和0-1背包(KP)问题。特别是在TSP问题,Poppy比先前最先进的方法表现得还好,将最优差距(gap)除以5,同时将推理时间减少了一个数量级以上。
零、一些基础
一、介绍
机器学习(ML)方法已经超过了在各种具有挑战性的任务中使用手工制作的特征和策略的算法。特别地,解决组合优化问题(CO)——最大化或最小化目标函数在一个有限的离散变量集合已经被找到——引来了很大的关注,因为它们(通常是NP)困难的性质,以及从物流到基础科学等领域的大量实际应用。
由于可行解的搜索空间随着问题规模的增加而指数增长,精确求解器面对规模大小将会是一个挑战,因此CO问题经常用带有专家知识的手动操作的启发式算法来处理。然而多种多样的基于机器学习的启发式算法已经被起初,强化学习(RL)是一个有前途的范式,因为它不需要这些困难问题的预处理案例。的确,基于强化学习CO解决器的算法改进,再加上低推理成本,并且它们的设计是针对特定的问题分布的,与传统解决器相比拥有着日益狭窄的差距(gap)。
为了提升提出的解决方案的质量,机器学习算法典型性地依靠额外的搜索程序,生成了多个候选解,可以分为两种方案。第一,改良方法从一个可行解开始,并且经过一个小的规范化逐步地提升。然而,这样逐步的搜索不能很快的获得差距很大解决方案,并且需要手动制作程序来定义可行动作空间。第二,构造方法通过一次选择一个元素逐步建造一个解决方案。可以使用采样策略建立多个解决方案,如随机采样策略或波束搜索。然而,正如改进方法有初始初始解决方案的偏差一样,构造方法也有单一的底层策略的偏差。因此,必须在利用已学习的策略(这可能不适合给定的问题实例)和探索不同的解决方案(其中纯随机策略的极端情况可能非常低效)之间取得平衡。
在本工作中,文章提出Poppy,是一种构建方法,利用具有适当不同政策的智能体群来改善困难CO问题解决空间的探索。然而一个单独的智能体的目标是在全部问题分布里表现得好,并且因此不得不作出妥协,一个群可以学习一套启发式方法,以便在任何给定的问题实例上只执行其中的一个。然而实现这样的直觉感知代表着几个挑战:(1)训练群智能体是非常昂贵的,并且在大规模上很有挑战,(2)训练好的群应该有强制策略提出不同的解决方案,(3)由于缺乏与典型CO问题的表现相一致的明确行为标记,训练方法不应在一系列政策中强加任何手工制作的多样性概念。
Poppy处理(1)通过在群中共享大部分计算,只专业化轻量级的策略头来实现智能体的多样性。挑战(2)和(3)都通过引入一个强化学习目标,旨在专业研究问题分布的不同子集来共同实现的。具体地说,本文推导了真正的群水平目标的一个下界,它对应于只训练在每个问题上表现最好的智能体。这是可以直观证明的,在给定的问题上,当其他智能体已经有了更好的表现时,群的表现没有通过在一个实例上训练一个智能体而改善。引人注目的是,本文发现,明智地应用这一概念上简单的目标,会产生一个群,在没有明确的监督下获得政策的多样性(因此适用于一系列问题,无需修改),并且对强大的表现至关重要。
本文的贡献总结如下:
1.本文引入并激励使用群的组合问题。
2.本文展示了一个编码器-译码器结构,可以被用来高效的训练群。
3.本文提出了一个新的训练目标,并提出了一个实用的培训程序,以鼓励绩效驱动的多样性(即不使用明确的行为标记或其他外部监督的有效多样性)。
4.本文在三个CO问题上评估Poppy: TSP, CVRP和0-1背包(KP)。
在TSP和KP, Poppy显著优于其他基于RL的方法。在CVRP上,它始终优于其他仅推理的方法,并接近积极微调问题特定政策的性能。
二、相关工作
(1)组合优化的机器学习方法
第一次尝试用神经网络解决TSP问题归功于Hopfield & Tank,只将规模提升到30个城市。最近定制神经架构的发展(Vinyals et al.,2015;Vaswani et al.,2017),以及性能良好的硬件已经使得机器学习方法越来越高效。的确,几个框架已经被用于处理CO问题,比如图神经网络 (Dai et al., 2017),循环神经网络 (Nazari et al.,2018),和注意力机制(Deudon et al., 2018)。在本文中,本文使用编码器-译码器架构,有Kool et al.,2019提出。消耗高的编码器在每个问题实例下只运行一次,使得嵌入被反馈到一个小的译码器中,迭代的推演出全部轨迹,这使得高效推演变得可能。这一方法被Kwon et al.,2020进一步发展,他充分利用典型CO问题的潜在对称性(如起始位置和旋转)使用实例增强来实现训练和推理变现的改善。
值得注意的是,机器学习方法经常依赖于机制,来生成多个候选解决方案(Mazyavkina et al., 2021)。其中一种机制包括在初始解决方案上使用改进方法de O. da Costa et al. (2020):使用策略梯度来学习在TSP中给定当前解决方案时选择本地操作符(2-opt)的策略,而Lu et al.(2020)和Wu et al.(2021)将此方法扩展到CVRP。这一想法已被扩展到能够搜索习得的解决方案潜在空间(Hottung et al.,2021年)。然而,这些方法有两个局限性:它们是特定于环境的,并且搜索过程固有地受初始解的影响。
依靠替代的探索机制是通过随机采样一个已经学习了的策略生成一个多样性轨迹集合,潜在的带上额外的波束搜索 (Joshi et al., 2019),蒙特卡洛数搜索(Fu et al., 2021),动态规划(Kool et al., 2021)或动态搜索(Hottung et al., 2022)。然而,直观地说,生成的解决方案倾向于接近潜在的确定性策略,这意味着额外抽样候选的好处迅速减少。
(2)基于群体的强化学习方法
群已经被用于强化学习来学习多样性的行为。在另一篇文章,, Gupta et al. (2018), Eysenbach et al. (2019), Hartikainen et al. (2020) 和 Pong et al. (2020)使用以一组目标为条件的单一策略作为无监督技能发现的隐性群体。更接近本文的方法,另一行工作围绕着显式地存储一组不同的策略参数 Doan et al. (2020), Hong et al. (2018), Jung et al. (2020) 和Parker-Holder et al. (2020)利用一个群来实现更好的策略空间覆盖。这在稀疏奖励环境或避免欺骗性的局部最优环境中特别有用。然而,它们强制执行基于策略距离的显式吸引-排斥机制,这被添加到损失函数中。因此,它们依赖于性能-多样性的权衡,这是与本文的方法相比的一个主要区别,本文的多样性纯粹是性能优化的副产品。
本文的方法是结合了强化学习与进化算法的 (EA; Khadka & Tumer, 2018; Khadka et al., 2019; Pourchot & Sigaud, 2019),它们受益于同样有效的强学学习策略更新,同时享受进化群水平的探索。然而,群是学习一种独特的强策略的手段,而Poppy学习的是一套互补的策略。更密切相关的是,Quality-Diversity (QD; Pugh et al., 2016; Cully & Demiris, 2018)是一个流行的EA框架,它维护多样化策略的选集。Pierrot et al.(2022)最近将强化学习与QD算法结合起来,既Map - Elite (Mouret & Clune, 2015);与Poppy不同的是,这些方法依赖于专家知识来定义行为标记,这并不容易适应CO上下文。
基于群的强化学习的缺点之一是其高昂的成本。然而,最近的方法表明,现代硬件和目标框架能够实现有效的向量化群训练 (Flajolet et al., 2022),为更广泛的应用打开了大门。
三、方法
1.背景和激励
(1)强化学习公式
一个问题实例
ρ
\\rho
ρ,采样自由
N
N
N个变量(如TSP问题里的城市位置)组成的离散集合分布
D
\\mathcalD
D。本文建立了一个组合优化问题模型,作为马尔科夫决策过程(MDP),定义一个状态空间
S
\\mathcalS
S,一个动作空间
A
\\mathcalA
A,一个转换函数
T
T
T,一个奖励函数
R
R
R,和一个折扣因子
γ
\\gamma
γ。
一个状态是一个通过问题实例
τ
t
=
(
x
1
,
.
.
.
.
.
.
,
x
t
)
∈
S
\\tau_t=(x_1,......,x_t) \\in \\mathcalS
τt=(x1,......,xt)∈S(其中
x
i
∈
ρ
x_i \\in \\rho
xi∈ρ)的轨迹,并且因此由一个有序的变量列表组成(长度不一定为
N
N
N)。
一个动作,
a
∈
A
⊆
ρ
a \\in \\mathcalA \\subseteq \\rho
a∈A⊆ρ包括选择下一个要添加的变量;因此,给定状态
τ
t
=
(
x
1
,
.
.
.
.
.
.
,
x
t
)
\\tau_t=(x_1,......,x_t)
τt=(x1,......,xt)和动作
a
a
a,下一个状态是
τ
t
+
1
=
T
(
τ
t
,
a
)
=
(
x
1
,
.
.
.
.
.
.
,
x
t
,
a
)
\\tau_t+1=T(\\tau_t,a)=(x_1,......,x_t,a)
τt+1=T(τt,a)=(x1,......,xt,a)。
使得
S
∗
⊆
S
\\mathcalS^* \\subseteq \\mathcalS
S∗⊆S成为解决方案的集合;也就是说,符合问题约束的状态(例如,一系列城市,即每个城市被访问一次,并以TSP中的起始城市结束)。
奖励函数
R
R
R:
S
∗
→
R
\\mathcalS^* → \\mathbbR
S∗→R将解决方案映射到标量。本文假设奖励是被最优解决方案最大化的(如 R但会负的旅程长度在TSP中)。
一个策略 π θ \\pi_\\theta πθ由 θ \\theta θ进行参数化,用于对实例 ρ ∼ D \\rho \\sim \\mathcalD ρ∼D生成生成解决方案,根据概率分布 π θ ( ⋅ ∣ ρ , τ t ) \\pi_\\theta (·|\\rho,\\tau_t) πθ(⋅∣ρ,τt)迭代采样下一个动作 a ∈ A a \\in \\mathcalA a∈A。本文用REINFORCE学习 π θ \\pi_\\theta πθ。该方法意在通过调整 θ \\theta θ最大化强化学习目标 J ( θ ) ≐ E ρ ∼ D E τ ∼ π θ , ρ R ( τ ) J(\\theta) \\doteq \\mathbbE_\\rho \\sim \\mathcalD \\mathbbE_\\tau \\sim \\pi_\\theta, \\rho R(\\tau) J(θ)≐Eρ∼DEτ∼πθ,ρR(τ),这样,良好的轨迹就更有可能在未来被采样。正式地,策略参数 θ \\theta θ由梯度上升更新 ∇ θ J ( θ ) = E τ ∼ D E τ ∼ π θ , ρ ( R ( τ ) − b ρ ) ∇ θ log ( p θ ( τ ) ) \\nabla_\\theta J(\\theta)=\\mathbbE_\\tau \\sim \\mathcalD \\mathbbE_\\tau \\sim \\pi_\\theta, \\rho\\left(R(\\tau)-b_\\rho\\right) \\nabla_\\theta \\log \\left(p_\\theta(\\tau)\\right) ∇θJ(θ)=Eτ∼DEτ∼πθ,ρ(R(τ)−bρ)∇θlog(pθ(τ)) 其中 p θ ( τ ) = ∏ t π θ ( a t + 1 ∣ ρ , τ t ) p_\\theta(\\tau)=\\prod_t \\pi_\\theta\\left(a_t+1 \\mid \\rho, \\tau_t\\right) pθ(τ)=∏tπθ(at+1∣ρ,τt) 和 b ρ b_\\rho bρ 是基线(baseline)。
(2)激励案例
本文主张用图一中的实例训练一个群的收益。
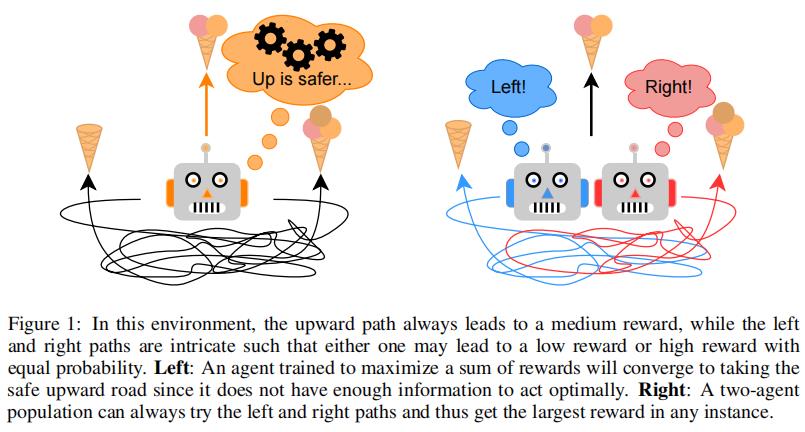
在这个环境中,有三个动作:左、右和上。上获得中等奖励,而左/右获得低/高或者高/低奖励(该配置是在每一回合(episode)开始时以相等的概率确定的)。至关重要的是,左右路径都是复杂的,所以主体不能轻易地从观察中推断出哪一个能带来更高的回报。那么,对于单个智能体来说,最好的策略是总是向上的,因为保证的中等奖励(2scoops)高于左右猜测的预期奖励(1.5scoops)。相比之下,群中的两个智能体可以朝相反的方向前进,但总能找到最大的奖励。有两个惊人的观察结果:(1)智能体不需要为了群性能最优,而最优执行(一个智能体获得最大奖励),(2)平均性能比单智能体情况下更差。
具体来说,当(1)一些最优行动难以从观察中推断出来,(2)选择是不可逆的(即不可能从次优决策中恢复过来)时,就会发生上述讨论过的现象。这些条件通常在解决困难的CO问题时成立。如上所示,在这些情况下,要使群的性能最大化,将需要智能体专业化(specialize),并且可能产生比单一智能体情况下更好的结果。
2.Poppy
本文提出了Poppy的三个不同的组成部分:实现有效群推广的架构,鼓励智能体专业化的强化学习目标,以及整体训练过程。
(1)建构
本文使用注意力模型Kool et al. (2019),该文章将策略模型分为两个部分。首先,一个大的编码器
h
ψ
h_\\psi
hψ,使得一个实例
ρ
\\rho
ρ作为输入,对于每个实例中的变量输出嵌入
w
w
w。其次,一个小的译码器
q
Φ
q_\\Phi
qΦ将输出嵌入
w
w
w和一个轨迹
以上是关于POPULATION-BASED REINFORCEMENT LEARNING FOR COMBINATORIAL OPTIMIZATION PROBLEMS 学习笔记的主要内容,如果未能解决你的问题,请参考以下文章