Redis缓冲区不会还有人不知道吧?
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis缓冲区不会还有人不知道吧?相关的知识,希望对你有一定的参考价值。
1 简介
缓冲区,用一块内存空间暂时存放命令数据,以免因
数据和命令的处理速度<发送速度
而导致数据丢失和性能问题。但缓冲区的内存空间有限,若持续:
往里写数据速度>从里读数据速度
会导致缓冲区需越来越多内存暂存数据。当缓冲区占用内存>设定上限阈值,就会出现缓冲区溢出。发生溢出,就会丢数据。不给缓冲区设上限,不就没这问题了?No!随累积数据增多,缓冲区所占内存空间越大,耗尽Redis机器可用内存时,Redis实例就会崩溃!
所以缓冲区是用来避免请求或数据丢失,使用姿势须正确,才能发挥作用。Redis所有操作命令都需通过C发给S。所以,缓冲区就是:
- 在C、S间通信时,暂存客户端发送的命令数据或S返给C的数据结果
- 主从节点间数据同步时,暂存主节点接收的写命令和数据
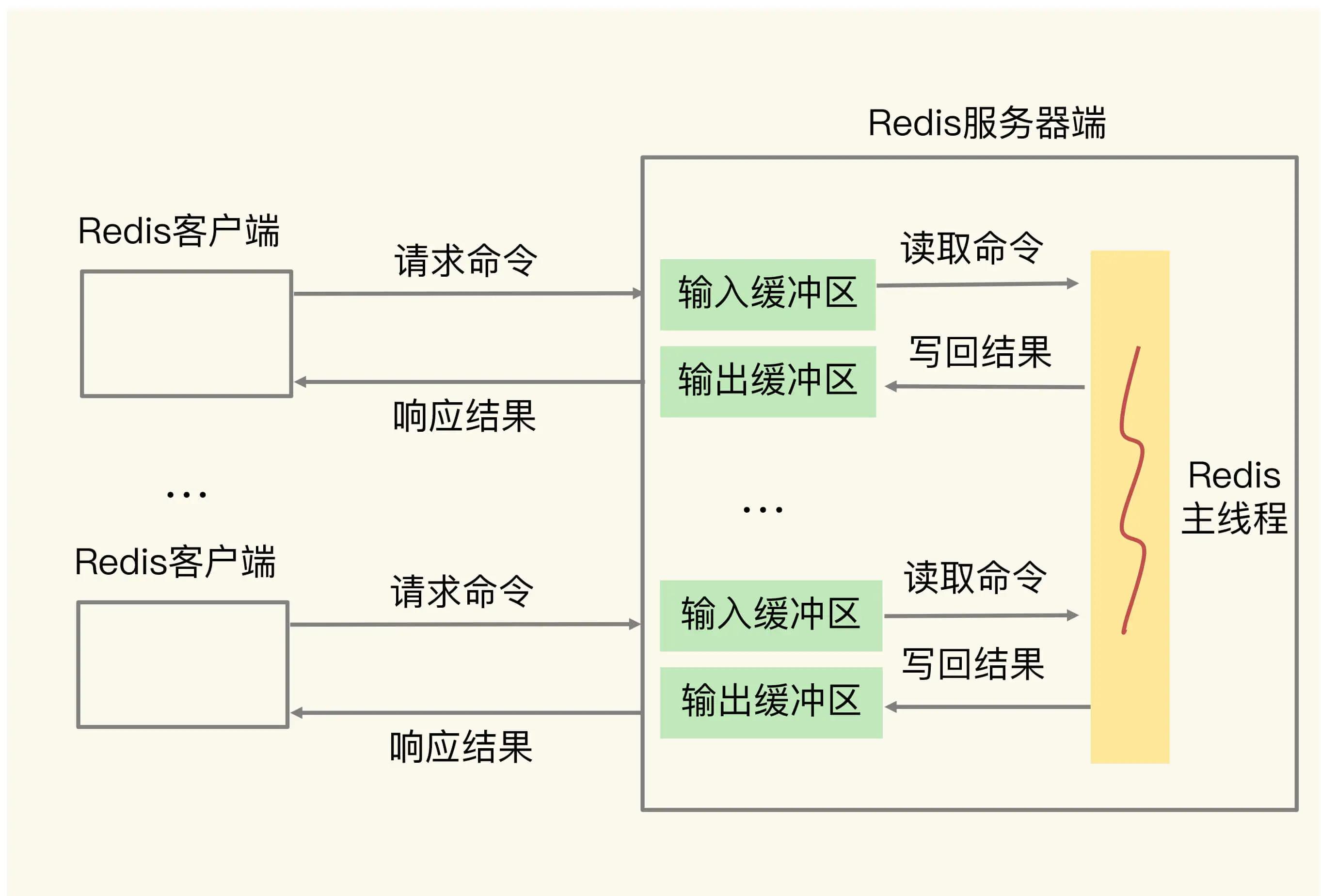
2 客户端输入、输出缓冲区
服务器端和客户端之间的缓冲区。
为避免C、S 的请求发送和处理速度不匹配,S给每个连接的C都设个输入、输出缓冲区,称为客户端输入、输出缓冲区。
- 输入缓冲区先暂存C发来的命令,Redis主线程再从中读命令并处理
- 当Redis主线程处理完数据,会把结果写入输出缓冲区,再通过输出缓冲区返给客户端
3 输入缓冲区溢出,怎么办?
可能溢出case:
- 写入bigkey,如一下写入多个百万级别的集合类型数据
- 服务器端处理请求速度过慢,如Redis主线程出现间歇性阻塞,无法及时处理正常发送的请求,导致客户端发送的请求在缓冲区越积越多
查看输入缓冲区的内存使用
要查看和Server相连的每个C对输入缓冲区的使用情况,可使用CLIENT LIST命令:
CLIENT LIST
id=5 addr=127.0.0.1:50487 fd=9 name= age=4 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client
CLIENT命令返回信息虽多,只需关注:
- 与服务器端连接的客户端信息
案例展示的是一个客户端的输入缓冲区情况,如有多个客户端,输出结果中的addr会显示不同客户端的IP和端口号 - 输入缓冲区相关参数:
- cmd
客户端最新执行的命令。这个例子中执行的是CLIENT命令。 - qbuf
输入缓冲区已经使用的大小。这个例子中的CLIENT命令已使用了26字节大小的缓冲区。 - qbuf-free
输入缓冲区尚未使用的大小。这个例子中的CLIENT命令还可以使用32742字节的缓冲区。qbuf和qbuf-free的总和就是,Redis服务器端当前为已连接的这个客户端分配的缓冲区总大小。这个例子中总共分配了 26 + 32742 = 32768字节,也就是32KB的缓冲区。
- cmd
有了CLIENT LIST命令,就可通过输出结果判断C输入缓冲区的内存占用情况:
若qbuf很大,qbuf-free很小,这时输入缓冲区已占用很多内存,而且没啥空闲空间。此时,C再写入大量命令,就会引起C输入缓冲区溢出,Redis就把C连接关闭,结果就是业务程序无法进行数据存取。
通常Redis S不止服务一个C,当多个C连接占用的内存总量,超过maxmemory配置项(如4G),触发Redis数据淘汰。一旦数据被淘汰,再要访问这部分数据,就需要去后端DB读,降低业务应用访问性能。如使用多个客户端,导致Redis内存占用过大,也会导致内存溢出(out-of-memory),进而引起Redis崩溃,给业务应用造成严重影响。
须避免输入缓冲区溢出,考虑:
- 缓冲区调大
- 从数据命令的发送和处理速度入手。
有没有办法通过参数调整输入缓冲区的大小?没。Redis客户端输入缓冲区大小的上限阈值,在代码中就定为1G。即Redis服务器端允许为每个客户端最多暂存1G命令和数据。对一般生产环境已经合适:
- 这个大小对于处理绝大部分客户端的请求已经够用了
- 再大,Redis就可能因客户端占用过多内存而崩溃
所以,Redis并没有提供参数调节客户端输入缓冲区大小。如要避免输入缓冲区溢出,只能从数据命令的发送和处理速度入手,即避免客户端写入bigkey,以及避免Redis主线程阻塞。
4 输出缓冲区溢出解决方案
Redis输出缓冲区暂存Redis主线程要返回给客户端的数据。
一般主线程返回给客户端的数据,既有简单且大小固定的OK响应(例如,执行SET命令)或报错信息,也有大小不固定的、包含具体数据的执行结果(例如,执行HGET命令)。
因此,Redis为每个客户端设置的输出缓冲区也包括两部分:
- 一个16KB固定缓冲空间,暂存OK响应和出错信息
- 可动态增加的缓冲空间,暂存大小可变的响应结果
5 输出缓冲区溢出场景
执行了MONITOR命令;
缓冲区大小设置得不合理。
5.1 bigkey
服务器端返回大量bigkey结果。原本就会占用大量的内存空间,所以服务器端返回的结果包含bigkey,必影响输出缓冲区。
5.2 MONITOR
用来监测Redis执行的。执行这命令后,会持续输出监测到的各个命令操作:
MONITOR
OK
1600617456.437129 [0 127.0.0.1:50487] "COMMAND"
1600617477.289667 [0 127.0.0.1:50487] "info" "memory"
MONITOR输出结果会持续占用输出缓冲区,并越占越多,最后就是发生溢出。
MONITOR命令主要用在调试环境,生产环境禁止持续使用MONITOR。若线上偶尔使用MONITOR检查Redis命令执行情况,也没问题。
5.3 client-output-buffer-limit
设置缓冲区大小:
- 设置缓冲区上限阈值
- 设置输出缓冲区持续写入数据的数量上限阈值,和持续写入数据的时间的上限阈值
设置缓冲区大小前,需先区分客户端类型。和Redis实例进行交互的应用程序,主要使用如下客户端:
- 常规和Redis服务器端进行读写命令交互的普通客户端(normal)
- 订阅了Redis频道的订阅客户端(pubsub)
① normal
给normal设置缓冲区大小时,可在redis.conf设置如下:

- normal
当前设置的是普通客户端 - 【1】0
设置的缓冲区大小阈值 - 【2】
缓冲区持续写入量限制 - 【3】0
缓冲区持续写入时间限制
对于normal,它每发送完一个请求,会等到请求结果返回后,再发下一个请求-阻塞式发送。
这时,若非读取体量特大的大K,S输出缓冲区一般不会被阻塞。
所以,Redis默认把normal的缓冲区大小限制、持续写入量限制、持续写入时间限制都置0,即不限制。
② pubsub
一旦订阅的Redis频道有消息,S都会通过输出缓冲区把消息发给C。
所以,订阅C、S间的消息发送方式,不属阻塞式发送。
但若频道消息较多,也会占用较多输出缓冲区空间。
因此,要给订阅C设置缓冲区大小限制、缓冲区持续写入量限制及持续写入时间限制,Redis默认配置:

- 32mb
输出缓冲区的大小上限阈值,一旦实际占用的缓冲区大小超过,S就会直接关闭C的连接 - 8mb和60
若连续60s内对输出缓冲区的写入量超过8MB,S也会关闭C的连接
小结应对输出缓冲区溢出:
- 避免大K操作返回大量数据结果
- 避免在线上环境中持续使用MONITOR
- 使用
client-output-buffer-limit设置合理缓冲区大小上限或缓冲区连续写入时间和写入量上限
6 主从集群中的缓冲区
主从集群间的数据复制包括:
- 全量复制
同步所有数据 - 增量复制
只会把主从库网络断连期间主库收到的命令,同步给从库
无论在哪种形式的复制,为保证主从节点数据一致,都会用到缓冲区。
6.1 复制缓冲区的溢出问题(全量复制)
全量复制,Master(后文简称为M)在向Replica(后文简称为R)传输RDB文件同时,会继续接收C发送的写请求。
这些写命令先保存在复制缓冲区,等RDB传输完,再发给从节点执行。
主节点会为每个从节点都维护一个复制缓冲区,保证和主从节点间的数据同步。
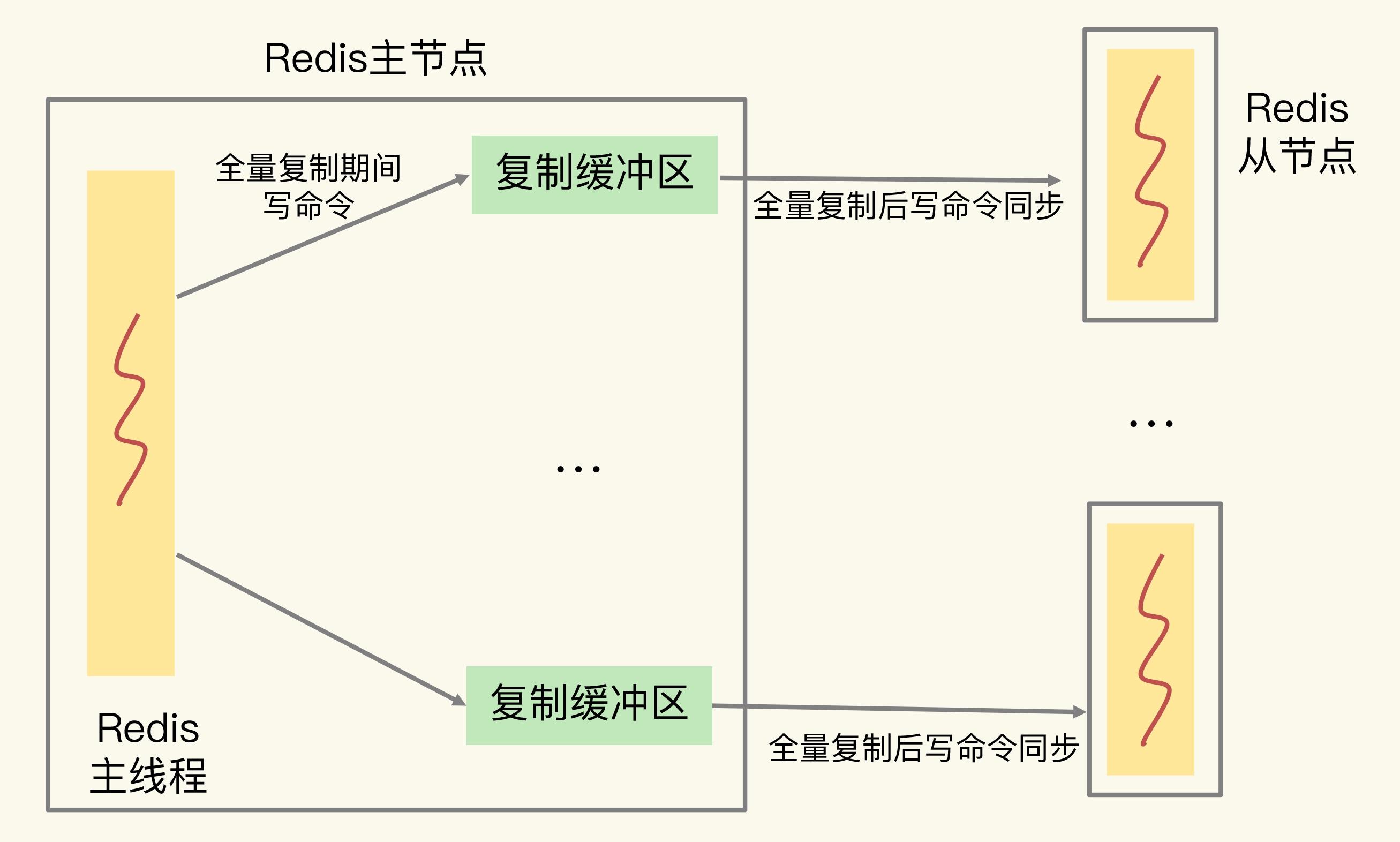
所以,若全量复制时,R接收和加载RDB较慢,同时M接收到大量写命令,写命令在复制缓冲区中就会积压,最终溢出。
M的复制缓冲区,其实也是个用于和R连接的客户端(称为从节点客户端),使用的输出缓冲区。复制缓冲区一旦溢出,M也会直接关闭和R进行复制操作的连接,全量复制直接失败。
6.2 避免复制缓冲区发生溢出
- 可控制M保存的数据量大小
一般把主节点的数据量控制在2~4GB,这可让全量同步执行更快,避免复制缓冲区积压过多 - 可通过
client-output-buffer-limit配置项设置合适复制缓冲区大小
设置依据:主节点的数据量大小、主节点的写负载压力和主节点本身的内存大小
从案例如何设置
在M执行:
config set client-output-buffer-limit replica 512mb 128mb 60
- replica
该配置项针对复制缓冲区 - 512mb
将缓冲区大小的上限设为512M - 128mb和60
若连续60s内写入量>128M,也会触发缓冲区溢出
这设置何用?
假设一条写命令数据是1KB,则复制缓冲区可积压512K条(512MB/1KB = 512K)写命令。
M在全量复制期间,可承受写命令速率上限=2000条/s(128MB/1KB/60≈2000)。
这就得到一种方案,设置复制缓冲区大小时:
- 根据写命令数据的大小 && 实际负载情况(即写命令速率),估计缓冲区中会积压的写命令数据量
- 再和所设置的复制缓冲区大小比较,判断设置的缓冲区是否够支撑积压的写命令数据量
由于M复制缓冲区的内存开销,会是每个R客户端输出缓冲区占用内存的总和。若集群中的R很多,M内存开销就很大。所以还得控制和M连接的R个数,不要使用大规模主从集群。
小结
为避免复制缓冲区积压过多命令造成溢出,导致全量复制失败,可:
- 控制M保存的数据量大小,并设置合理复制缓冲区大小
- 控制R数量,避免M的复制缓冲区占用内存过多
6.3 复制积压缓冲区的溢出(增量复制)
增量复制时使用的缓冲区,这个缓冲区称为复制积压缓冲区。
M在把接收到的写命令同步给R时,同时会把这些写命令写入复制积压缓冲区。
一旦R发生网络闪断,和M重连后,R就会从复制积压缓冲区读取 断连期间 M接收到的写命令,进行增量同步:
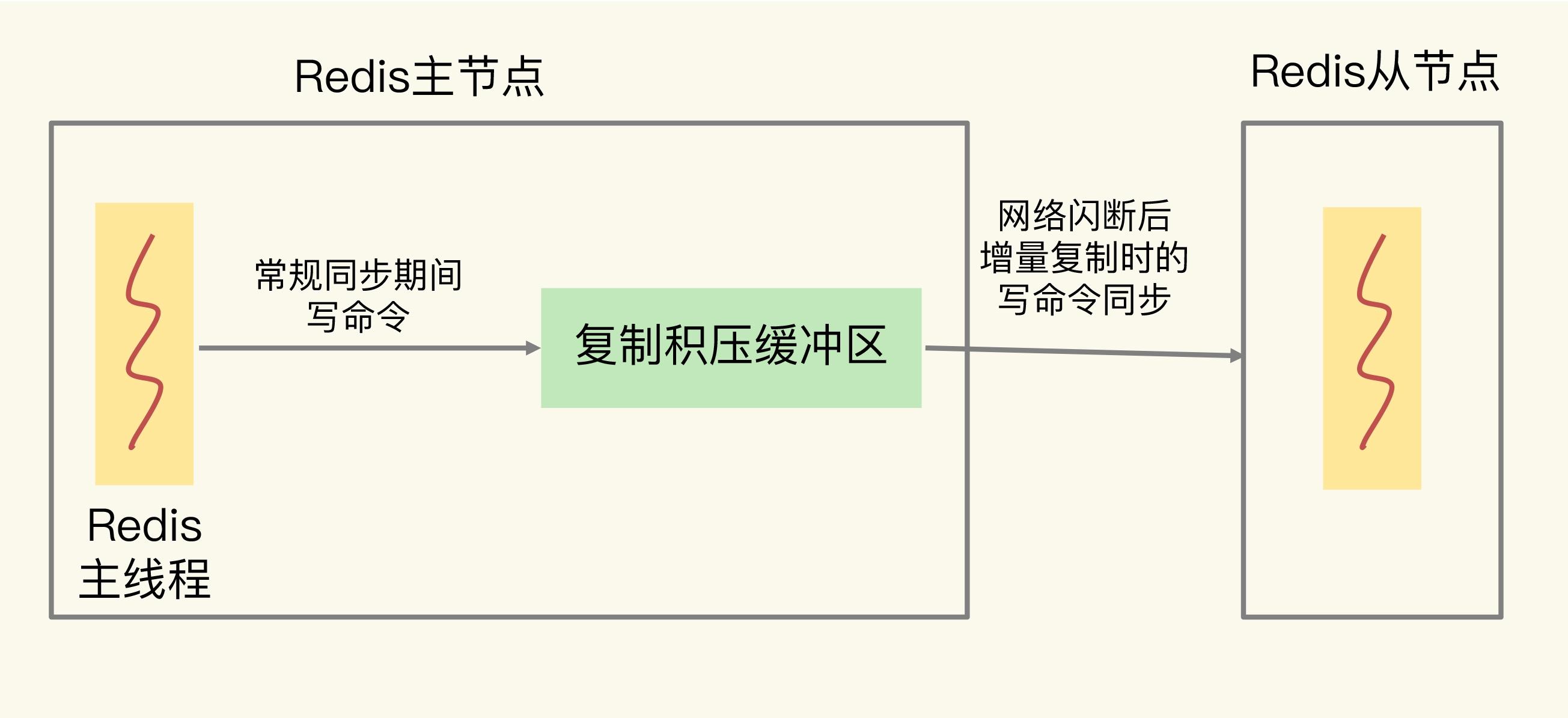
repl_backlog_buffer。在缓冲区溢出角度来看:
- 复制积压缓冲区是个有限的环形缓冲区
当主节点把复制积压缓冲区写满后,会覆盖缓冲区中的旧命令数据。如果从节点还没有同步这些旧命令数据,就会造成主从节点间重新开始执行全量复制。 - 为了应对复制积压缓冲区的溢出问题,我们可以调整复制积压缓冲区的大小,即repl_backlog_size参数值。
7 总结
使用缓冲区后,当命令数据的接收方处理速度跟不上发送方的发送速度,缓冲区可避免丢失命令数据。
按缓冲区用途,如客户端通信or主从节点复制,分为:
- 客户端的输入和输出缓冲区
- 主从集群中主节点上的复制缓冲区和复制积压缓冲区
从缓冲区溢出对Redis的影响的角度,把四个缓冲区分成两类总结
- 缓冲区溢出导致网络连接关闭
普通客户端、订阅客户端及从节点客户端,所用缓冲区本质都是Redis客户端和服务器端间,或主从节点间为传输命令数据而维护。这些缓冲区一旦溢出,处理机制都是直接关闭客户端和服务器端的连接,或主从节点间的连接。
而网络连接关闭造成的直接影响,就是业务程序无法读写Redis,或者是主从节点全量同步失败,需重新执行。 - 缓冲区溢出导致命令数据丢失
M的复制积压缓冲区属环形缓冲区,一旦溢出,新写入的命令数据就会覆盖旧的命令数据,导致旧命令数据的丢失,进而导致主从节点重新全量复制。
缓冲区溢出的原因:
- 命令数据发送过快、过大
对普通客户端,可避免bigkey,而对复制缓冲区,就是避免过大RDB文件 - 命令数据处理较慢
减少Redis主线程上的阻塞操作,如使用异步删除操作 - 缓冲区空间过小
使用client-output-buffer-limit配置项设置合理的输出缓冲区、复制缓冲区和复制积压缓冲区大小
输入缓冲区的大小默认是固定的,无法通过配置修改,除非改源码。
FAQ
1 应用程序中使用的客户端要用缓冲区吗?
客户端需使用缓冲区,好处:
- C、S交互,一般制定一个交互协议,C给S发数据时,按协议组装数据,写到客户端buffer,C一次性把buffer写到 os 的网络缓冲区,最后由os发给S。这样S就能从网络缓冲区中读到一整块数据,按协议解析数据。使用buffer发送数据会比一个个发送数据到服务端效率高。
- C还可使用Pipeline批量发送命令到服务端,以提高访问性能。不使用Pipeline时,C是发一个命令、读一次结果。而使用Pipeline,C先把一批命令暂存到buffer,然后一次性把buffer中的命令发到服务端,服务端处理多个命令后批量返回结果,这可减少网络I/O次数,降低延迟,提高访问性能。Redis服务端的buffer内存也会相应增长,可以控制好Pipeline命令的数量防止buffer超限。
缓冲区的意义
无处不在,客户端缓冲区、服务端缓冲区、操作系统网络缓冲区等等,凡涉及数据交互的两端,一般都会使用缓冲区降低两端速度不匹配的影响。
没有缓冲区,就好比一个个工人搬运货物到目的地,每个工人不仅成本高,而且运输效率低。而有了缓冲区后,相当于把这些货物先装到一个集装箱里,然后以集装箱为单位,开车运送到目的地,这样既降低了成本,又提高了运输效率。
缓冲区相当于把需要运送的零散数据,进行一块块规整化,然后分批运输。
Redis服务端为客户端分配的输出缓冲区:主库上的从库输出缓冲区(slave client-output-buffer)是不计算在Redis使用的总内存,即主从同步延迟,数据积压在主库上的从库输出缓冲区中,这个缓冲区内存占用变大,不会超过maxmemory导致淘汰数据。
只有普通客户端和订阅客户端的输出缓冲区内存增长,超过maxmemory时,才会淘汰数据。
2 TCP已有读写缓冲区,redis为何单独维护读写缓冲区?
缓冲区类似队列,读写变成异步,主线程跟缓冲区交互,是什么线程负责缓冲区跟tcp的数据同步?
解决的虽都是速率不一致,缓冲问题:
- TCP缓存解决C、S的网络及处理速度问题,偏网络速率缓冲。这是全局配置,修改后对这台宿主机上的应用都生效
- redis的缓存则是解决redis服务器的处理速度与客户端的发送速度问题。这部分redis应用可修改。可以只针对这个redis应用粒度修改
tcp 的缓冲区面向的是网络的不可靠,redis 的缓冲区面向的是程序处理性能的不可靠。
- TCP的缓冲区运行在Ring0内核态,由内核和网卡驱动控制,应用程序控制不到,而内核和网卡驱动,不关心发送接收了什么内容,更不会有应用层面的收发控制策略。
- 而redis的缓冲区运行在Ring3,只关心应用层需要做什么策略,不太关心TCP层面做了什么东西的
- redis数据与TCP发生读写,是通过内核来调度的,网卡收到数据后,发送中断告知内核数据来了,内核将数据搬送到Redis的应用层内存,然后告诉redis数据来了,redis就收到通知,可以读取数据了。
tcp的缓冲区是系统内核维护的,负责tcp的可靠传输,确认机制,窗口大小,流量控制和拥塞控制等都需要缓冲区。redis的缓冲区是redis自己用,用于client-server机制,就是老师讲的。redis主线程发送数据时就是把自己缓存区的数据拷贝到内核的tcp缓冲区,之后由内核负责发送数据到网卡,内核是通过epoll机制知道有数据要发送的。
以上是关于Redis缓冲区不会还有人不知道吧?的主要内容,如果未能解决你的问题,请参考以下文章
不会吧,都2020年了,还有人不知道jmeter和locust的区别?
不会吧,都2020年了,还有人不知道jmeter和locust的区别?