14. UserAgent 反爬是如何实现的,来看看这篇博客 &
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了14. UserAgent 反爬是如何实现的,来看看这篇博客 &相关的知识,希望对你有一定的参考价值。
本篇博客实现 【爬虫训练场】 的第一个反爬案例,User-Agent 反爬。
文章目录
什么是 User-Agent 反爬
User-Agent 反爬是一种防止网站被爬虫爬取的技术。
当爬虫向网站发送 HTTP 请求时,会在请求头中包含一个名为 “User-Agent” 的字段,该字段用于告知网站服务器请求来自哪种浏览器或爬虫。网站服务器可以通过检查这个字段来判断请求是由真实的浏览器发起的,还是由爬虫发起的。
如果服务器发现请求中的 User-Agent 字段不是某种常见浏览器的名称,就可能认为请求来自爬虫,并返回一个错误响应或拒绝请求。这就是 User-Agent 反爬的原理。
为了避免被 User-Agent 反爬,爬虫可以在发送请求时将 User-Agent 字段设置为某种常见浏览器的名称,从而使得服务器将请求识别为来自真实浏览器的请求。但这并不意味着爬虫可以随意爬取网站的内容,网站仍然可以使用其他手段来防止爬虫的滥用。
User-Agent 反爬是一种常用的反爬技术,但它并不是唯一的反爬手段。网站还可以使用其他技术来防止爬虫的滥用,例如:
- IP 限制:网站可以将访问权限限制在特定的 IP 地址范围内,从而拒绝来自其他 IP 地址的请求。
- 图形验证码:网站可以在用户提交表单之前要求输入图形验证码,以防止爬虫自动提交表单。
- 反抓取:网站可以使用 javascript 或其他技术动态生成网页内容,从而防止爬虫直接抓取网页源代码。
- 限制请求频率:网站可以限制爬虫每小时发送的请求数量,以避免爬虫对服务器造成过大负荷。
这些手段,在之后的爬虫训练场中都会涉及。
咱们本篇博客要在 Python Flask 中实现 User-Agent 反爬。
在 Python Flask 中实现 User-Agent 反爬
方法如下,按照步骤操作即可。
-
在 Flask 程序中使用
@app.before_request装饰器,指定一个函数来处理所有的请求,在该函数中检查请求头中的User-Agent字段。 -
获取 User-Agent 字段的值,在
app目录中建立antispider文件夹,然后新增index.html文件,输入如下内容。
% extends "base.html" %
% block content %
<div class="container text-center pt-5">
<h3>寓言故事:最可爱的孩子</h3>
<div>
<p>有一个人在外地做事,托他的一位同乡带一件精巧又昂贵的玩具回家。</p>
<p>同乡问:“这东西带给谁呢?”</p>
<p>这个人认为自己的儿子长得伶俐聪明,是全村最可爱的孩子,就得意地说:“带给我们村里最可爱的孩子。”</p>
<p>同乡点点头,拿起东西走了。</p>
<p>过了几个月,这人回到家里,知道他的儿子并没有收到同乡带回来的玩具,便跑去问那个同乡:</p>
<p>“我托你带的玩具,怎么没有带给我的儿子?”</p>
<p>那同乡说:“你不是说带给全村最可爱的孩子吗?我认为我的儿子是全村最可爱的孩子,所以把玩具给了我的孩子啦!”</p>
</div>
</div>
% endblock %
- 在
check_user_agent()函数中,对user_agent进行判断,如果是某种常见浏览器的名称,则允许请求通过,否则返回一个错误响应。例如:
from flask import Blueprint, jsonify, request
from flask import render_template
antispider = Blueprint('antispider', __name__, url_prefix='/as')
@antispider.before_request
def check_user_agent():
user_agent = request.headers.get("User-Agent")
print(user_agent)
if "Mozilla" in user_agent:
# 允许请求通过
return None
else:
return "错误请求",403
注意:以上代码仅供参考,并不能保证能够完全防止爬虫的滥用。网站的反爬措施应该根据实际情况进行调整,以便最大程度地保护网站的服务器和数据安全。
还有 @app.before_request 装饰器是 Flask 框架中的一种特殊装饰器,用于在处理每一个请求之前执行特定的代码。
使用 @app.before_request装饰器的方法如下:
- 在 Flask 程序中定义一个函数,该函数将在处理每一个请求之前被执行。
- 在函数定义的上方使用
@app.before_request装饰器,并将函数名作为参数传递给装饰器。
为了更好地实现 User-Agent 反爬,可以进一步完善上述代码,例如:
-
在
check_user_agent()函数中,不仅要判断 User-Agent 是否是某种常见浏览器的名称,还要判断是否是一些常见爬虫的名称。这样,当爬虫伪装成某种浏览器时,也可以被检测出来。 -
使用黑名单或白名单的方式,来指定哪些 User-Agent 是可以接受的,哪些是不可以接受的。例如,使用黑名单的方式,指定一个包含不可接受 User-Agent 的列表,然后在
check_user_agent()函数中遍历该列表,如果 User-Agent 在该列表中,则返回错误响应;否则,允许请求通过。
此时如果希望运行我们的项目,还需要继续补齐 antispider/index.py 文件,添加视图相关函数。
@antispider.route('/show')
def index():
return render_template("antispider/ua_show.html")
@antispider.route('/error403')
def error403():
return "缺少关键参数", 403
注册蓝图之后,通过浏览器访问,正常情况得到如下界面。
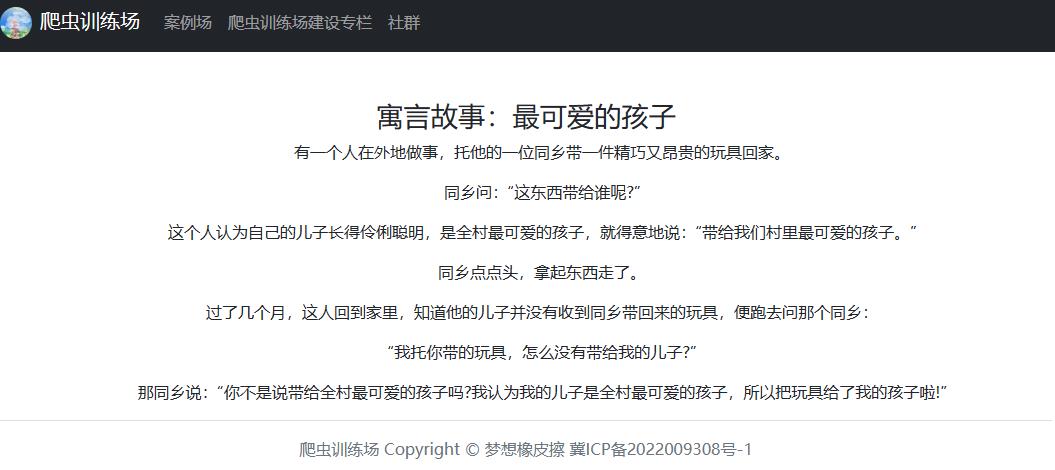
最后就可以测试请求头中,如果没有 user-agent 参数,是否还能得到正确数据。
import requests
res = requests.get('http://pachong.vip/as/show', allow_redirects=False)
print(res.request.headers)
print(res.text)
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 811 篇原创博客
从订购之日起,案例 5 年内保证更新
以上是关于14. UserAgent 反爬是如何实现的,来看看这篇博客 &的主要内容,如果未能解决你的问题,请参考以下文章