如何查找网页的源代码?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何查找网页的源代码?相关的知识,希望对你有一定的参考价值。
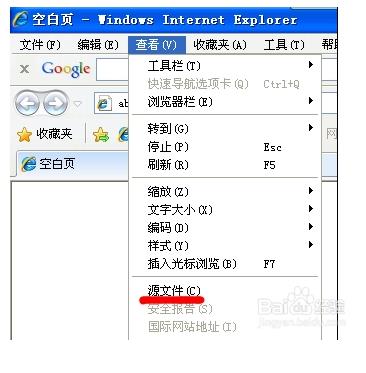
打开一个网页之后,右键---》查看源文件(IE10 为查看源),然后就会弹出网页的源文
件。
点击之后就会出现一个文本样式的代码了

第二种方法就是根据浏览器状态栏或工具栏中的点击 “查看”然后就用一项“查看源代码”,点击查看源代码即可查看此网页的源代码源文件。
Instant Source是专为IE开发的插件,所以,安装后你在开始菜单找不到启动它的程序。它整合在IE中,如果在你的IE浏览器工具栏上没有发现它的图标,可以通过“查看→工具栏→自定义”添加。
点击IE浏览器工具栏上的Instant Source图标,如图1所示,Instant Source会在IE窗口的下面露出它的真面目,Instant Source几乎所有的功能,都要通过整合在IE中的这个窗口才能完成。
二、查看源代码
Instant Source提供了多种源代码的查看方式,它可以查看整个页面的源代码,也可以查看选定文本的源代码,甚至还可以查看鼠标所指网页元素的源代码。点击工具栏上的“显示”按钮,如图2所示,在菜单上选择“鼠标所指元素”,这样,在IE中,鼠标所指网页元素的源代码就实时地显示在Instant Source窗口中了。
三、编辑源代码
首先需要说明的是,Instant Source对网页源代码的编辑,只适合于本地的html网页文件。
在IE中打开一个本地网页文件,在图2中选择“整个页面(原始)”,这时,你会发现,在Instant Source工具栏上的“应用”按钮已变为可用状态,现在,你就可以在Instant Source窗口中编辑该网页的源代码了。编辑完成后,点击“应用”,Instant Source会自动保存该网页并在IE中实时显示。这一功能,对于那些习惯于使用源代码编辑网页的朋友,无疑是一大福音。
四、保存外部对象
在IE中打开“新浪网”首面,在Instant Source工具栏上点击“对象”,打开“页面对象”对话框,你看到了什么?没错,“新浪网”首页中链接到的所有外部对象,包括图像、Flash电影、js脚本、样式表以及链接到的其它网页文件都一览无余
选定一个对象,点击对话框上的“查看”,可以在默认的浏览器中打开该对象;点击“保存”,可以在本地保存该对象,当然了,点击“保存全部”,可以保存所有对象;点击“复制URL”,可以把选定对象的绝对地址复制到剪贴板。不是有很多朋友老问我,怎样才能保存网页上的Flash动画吗,今天把这个软件介绍给你,希望再不要问我这样的问题。
在Instant Source的窗口中,我们可以复制选定的源代码,也可以点击工具栏上的“查找”,在网页源代码中查找你需要的内容。总之,Instant Source是一款对网页制作爱好者非常实用的工具,对于其它网民,你也可以利用它查找并保存网页上的资源
呵呵本回答被提问者采纳 参考技术B 一、安装和界面
Instant Source是专为IE开发的插件,所以,安装后你在开始菜单找不到启动它的程序。它整合在IE中,如果在你的IE浏览器工具栏上没有发现它的图标,可以通过“查看→工具栏→自定义”添加。
点击IE浏览器工具栏上的Instant Source图标,如图1所示,Instant Source会在IE窗口的下面露出它的真面目,Instant Source几乎所有的功能,都要通过整合在IE中的这个窗口才能完成。
二、查看源代码
Instant Source提供了多种源代码的查看方式,它可以查看整个页面的源代码,也可以查看选定文本的源代码,甚至还可以查看鼠标所指网页元素的源代码。点击工具栏上的“显示”按钮,如图2所示,在菜单上选择“鼠标所指元素”,这样,在IE中,鼠标所指网页元素的源代码就实时地显示在Instant Source窗口中了。
三、编辑源代码
首先需要说明的是,Instant Source对网页源代码的编辑,只适合于本地的HTML网页文件。
在IE中打开一个本地网页文件,在图2中选择“整个页面(原始)”,这时,你会发现,在Instant Source工具栏上的“应用”按钮已变为可用状态,现在,你就可以在Instant Source窗口中编辑该网页的源代码了。编辑完成后,点击“应用”,Instant Source会自动保存该网页并在IE中实时显示。这一功能,对于那些习惯于使用源代码编辑网页的朋友,无疑是一大福音。
四、保存外部对象
在IE中打开“新浪网”首面,在Instant Source工具栏上点击“对象”,打开“页面对象”对话框,你看到了什么?没错,“新浪网”首页中链接到的所有外部对象,包括图像、Flash电影、js脚本、样式表以及链接到的其它网页文件都一览无余
选定一个对象,点击对话框上的“查看”,可以在默认的浏览器中打开该对象;点击“保存”,可以在本地保存该对象,当然了,点击“保存全部”,可以保存所有对象;点击“复制URL”,可以把选定对象的绝对地址复制到剪贴板。不是有很多朋友老问我,怎样才能保存网页上的Flash动画吗,今天把这个软件介绍给你,希望再不要问我这样的问题。
在Instant Source的窗口中,我们可以复制选定的源代码,也可以点击工具栏上的“查找”,在网页源代码中查找你需要的内容。总之,Instant Source是一款对网页制作爱好者非常实用的工具,对于其它网民,你也可以利用它查找并保存网页上的资源。 参考技术C 两种查看方式:
一、打开网页,鼠标放到网页空白位置,然后点击右键,有个菜单查看源/查看页面源代码;
二、打开网页,点击浏览器菜单里面的查看,下面有个选项是查看源代码,点击即可查看。 参考技术D 方法一、网页空白处——单击鼠标右键——点查看源文件
方法二、网页最上面“查看”——查看源文件
使用 selenium 从动态网页表中查找值
【中文标题】使用 selenium 从动态网页表中查找值【英文标题】:Using selenium to find values from a dynamic webpage table 【发布时间】:2020-07-24 18:58:33 【问题描述】:我有一个 python 代码,它使用 selenium 打开一个大学成绩网页,输入一些学生值并打开该学生的成绩页面。 结果页面有一个动态表格,我无法访问其 HTML 代码。如何找到特定行和列的值?
我打开大学成绩网页的python代码是:
from selenium.webdriver.support.ui import Select
firefox_browser = webdriver.Firefox(executable_path=r'C:\Program Files\gecko\geckodriver.exe')
firefox_browser.get("http://results.drait.in/")
time.sleep(5)
print("Opening firefox")
select = Select(firefox_browser.find_element_by_id('ugpg'))
select.select_by_visible_text('UG-SEE')
name_input = firefox_browser.find_element_by_css_selector("#usn")
play_button = firefox_browser.find_element_by_css_selector("#submit")
name_input.send_keys("1DA17ISxxx")
play_button.send_keys(Keys.ENTER)
print("Done")
上面的代码打开了主结果页面,其中包含学生注册的科目和相应的成绩。
如何根据主题代码和考试类型访问特定的行和列,并将该值返回到我的 python 代码以进行打印?
我无法找到结果页面的 HTML 代码以使用表格名称访问表格。
结果页面的首页是这样的:https://imgur.com/a/1ZgENY6
提供学生证后显示学科详细信息和成绩的结果页面如下所示:https://imgur.com/a/xDAJ7IL
谢谢
【问题讨论】:
无法访问您的链接,能否提供有效的 url 或 DOM? 使用这个:results.drait.in或者你可以点击这里的第一个链接:dr-ait.org/autonomy/results 两个都试过了,但是无法访问这个网站 没有别人的usn就看不到你说的结果页 检查中选择“UG-SEE”选项,对于USN,可以给1IDA17ISxxx,xxx的范围是002-045。这应该会让你进入结果页面 【参考方案1】:首先你要导入 selenium webdriver
from selenium import webdriver
然后您必须导入密钥才能启用输入密钥
from selenium.webdriver.common.keys import Keys
那么如果你想使用time.sleep()你必须导入时间模块
import time
检查表格,您可以获取表格标签中所有<tr>标签的xpath
您的 xpath 将如下所示 /html/body/form/center/table/tbody/tr[1]
从此删除索引值/html/body/form/center/table/tbody/tr
使用 len 方法可以看到有多少行
a = len(firefox_browser.find_elements_by_xpath("/html/body/form/center/table/tbody/tr"))
类似地使用 xpath 的 <th> 标记列
您的 xpath 将如下所示 /html/body/form/center/table/tbody/tr[1]/th[1]
从此删除<th>标签/html/body/form/center/table/tbody/tr[1]/th的索引值
使用 len 方法可以看到有多少列
b = len(firefox_browser.find_elements_by_xpath("/html/body/form/center/table/tbody/tr[1]/th"))
现在a 代表有多少行,b 代表列数
写一个for循环
for r in range(2,a+1):#starting from 2 because first rows is headings
for c in range(1,b+1):
#use the variables a and b instead of the index of <tr> and <th>
value =
firefox_browser.find_elements_by_xpath("/html/body/form/center/table/tbody/tr["+r+"]/th["+c+"]")
print(value.text)
如果你想使用 if 语句从特定标题中选择元素
这样使用
check=firefox_browser.find_elements_by_xpath("/html/body/form/center/table/tbody/tr[1]/th[1]")
if check.text == "your value":
#do something
【讨论】:
以上是关于如何查找网页的源代码?的主要内容,如果未能解决你的问题,请参考以下文章