周边检索POI技术方案设计
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了周边检索POI技术方案设计相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享

生活必备技能——查找周边

时光荏苒,我从2018年初到北京打工,到现在已经快5年了。期间经历了两家公司,也搬过几次家,在繁华的大都市里生活,我最大的感受就是:“查找周边”已经成为了每个人生活的必备技能了。“附近的共享单车”、“附近的美食”、“附近的核酸检测点”等等,无论你走到哪里,这些周边的POI都会成为你生活的一部分。还好有“百度地图”、“美团”、“支付宝”这些App,在我需要查找周边POI时,它们总能很好的帮助我。作为程序员,实现这些功能,让人们的生活方式变简单,心里总会有莫大的成就感,今天笔者就来跟大家分享一下“周边检索POI”的技术方案设计。


1. 用mysql数据库来查找附近的POI

地理位置使用经纬度表示,经度范围[-180, 180],纬度范围[-90, 90],纬度正负以赤道为界,北正南负,经度以本初子午线为界,东正西负。我们位于东北半球,所以经纬度在[0, 180],[0, 90]范围内,比如百度大厦在北京市海淀区上地科技园,经纬度坐标是(116.30778,40.056859)。
1.1 计算POI之间的距离
当两个元素的距离不是很远时,可以根据经纬度使用勾股定理做计算,比如大学里的食堂到图书馆,使用勾股定理计算出来的距离和真实的距离误差在米级别,在业务上完全可以接受。不过需要注意的是,地球是一个椭圆球,从赤道向两极经纬度的密度不一样,使用勾股定理计算平方之后求和时,需要给每一个平方项添加加权系数。如果将地球看作一个圆球的话,使用数学上的三角函数计算距离会更加精确,下边是Go语言的代码实现。
const (
dr = math.Pi / 180.0
earthRadius = 6372797.560856
)
func degRad(ang float64) float64
return ang * dr
// Distance : 计算两个给定坐标之间的距离,单位为米
func Distance(latitude1, longitude1, latitude2, longitude2 float64) float64
radLat1 := degRad(latitude1)
radLat2 := degRad(latitude2)
a := radLat1 - radLat2
b := degRad(longitude1) - degRad(longitude2)
return 2 * earthRadius * math.Asin(math.Sqrt(math.Pow(math.Sin(a/2), 2)+
math.Cos(radLat1)*math.Cos(radLat2)*math.Pow(math.Sin(b/2), 2)))
1.2 Mysql数据表设计与SQL查询
实现根据距离查找POI,我们需要存储的是POI的唯一ID和经纬度,此外真实的业务场景中还会存储POI的其他属性信息,比如POI是美食店铺,还会添加营业时间、联系电话等。设计数据表positions:
CREATE TABLE `positions` (
`id` bitint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`poi_uid` varchar(64) NOT NULL COMMENT 'poi的唯一id',
`lng` double(15, 7) NOT NULL COMMENT 'poi的经度',
`lat` double(15, 7) NOT NULL COMMENT 'poi的纬度',
... //其他poi属性字段信息
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8有了数据表,给定一个用户的地理位置坐标($poi_lat, $poi_lng),就可以根据前边提到的三角函数写出SQL计算每个poi和给定坐标的距离,排序取出距离最近的topN条POI数据了。
SELECT
`id`, `poi_uid`, `lng`, `lat`, ...
ROUND(
6371.393 * 2 * ASIN(
SQRT(
POW(
SIN(
(
'$poi_lat' * 3.1415926 / 180 - `lat` * PI() / 180
) / 2
),
2
) + COS('$poi_lat' * 3.1415926 / 180) * COS(`lat` * PI() / 180) * POW(
SIN(
(
'$poi_lng' * 3.1415926 / 180 - `lng` * PI() / 180
) / 2
),
2
)
)
) * 1000
) AS distance_um
FROM
`positions`
ORDER BY
distance_um ASC
LIMIT '$topN'1.3 覆盖索引查询优化
为了加快查询,我们可以建立(lng, lat)的联合索引:
alter table `positions` add index idx_lng_lat(`lng`, `lat`)熟悉Mysql的读者都知道Innodb引擎以B+树的形式组织二级索引,B+树的叶子节点存储了主键id和指定的其他索引字段值。idx_lng_lat的联合索引存储了id, lng, lat三个字段的值。执行上述SQL时,Innodb引擎会优先选择数据体积较小的idx_lng_lat B+树完成排序和取值,然后拿到查询的数据记录根据主键id到主键索引中回表查询取出其他的字段信息(poi_uid, ...)返回给客户端。

虽然添加的索引能够被使用到,由于字段lng, lat使用了三角函数计算公式(并不是天然有序的),Innodb引擎在排序的时候还是会扫描二级索引idx_lng_lat的所有记录来计算距离distance_num。好在Mysql5.6版本以后对topN的查询做了优化,使用优先队列(堆排序)减少了内存使用,但是当POI记录成百上千万的时候,扫描所有的POI计算距离再进行排序,这个计算量实在太大了,性能指标无法满足业务需求。一般的解决方法是通过经纬度设定一个正方形范围来限定POI的数量,然后对正方形内的POI全量扫描并排序,这样可以限制扫描POI的数量。
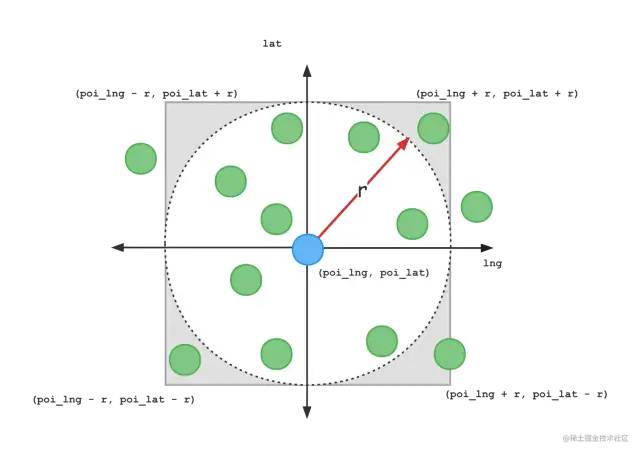
但是限制经纬度范围后,并不一定能查询到topN的POI,这个时候可以扩大范围继续查询;如果再查询不到,就继续扩大范围查找。这种POI渐进式召回的方案优点是每次查询都只扫描指定范围内的POI,查询速度相对较快。缺点是对于POI比较稀少的地方(例如大山里查找附近的50家美食店铺)需要多次扩大范围查找,这种情况下制定合理的召回策略就变得很重要,这种POI渐进式召回后边会再谈到。

2. 降维查询 —— GeoHash算法实现

Mysql通过建立索引计算POI距离并排序,然后查询topN的过程之所以要进行全表扫描,是因为经纬度描述的是二维平面空间,而B+树是对一维数据进行范围查找。那么有没有一种算法能够将二维经纬度给映射成一维数据,从而使用Mysql的between...and...或者in语句快速范围查询呢? 业界比较通用的地理位置编码算法——GeoHash算法,就可以实现将二维经纬度数据映射到一维整数,然后提供给B+树、SkipList、前缀树等支持快速范围检索的数据结构进行POI查找了;几乎所有的数据库或中间件(例如Mongo、Redis、ES、Mysql等等)都使用GeoHash算法实现了自己的空间索引来支持对地理位置的距离查询业务。
2.1 GeoHash算法的实现思路 —— 网格的切分与编码
GeoHash的算法思想是将整个地球看成一个二维平面,然后将其划分成一系列的正方形(经度比纬度多切分一次)的方格,就好比一个棋盘,地图上所有的POI坐标都被放置在唯一的方格中。

地球的半径约为 6371 km,第一次分割后可以得到四个东西宽 6371π km 南北高 3186π km 的矩形,使用两个二进制位对这四个矩形进行编码。
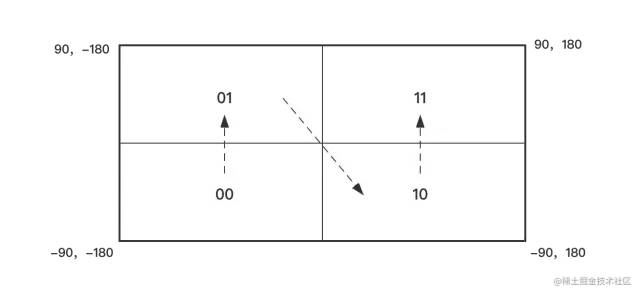
纬度[-90, 0] 用0表示,[0, 90]用1表示;经度[-180, 0] 用0表示,[0, 180]用1表示。经度在前纬度在后,这样四个部分都有了一个二进制编码。
继续对四个小矩形继续二等分成16个矩形,这一次切分后就需要使用四个二进制位对所有矩形进行编码了。
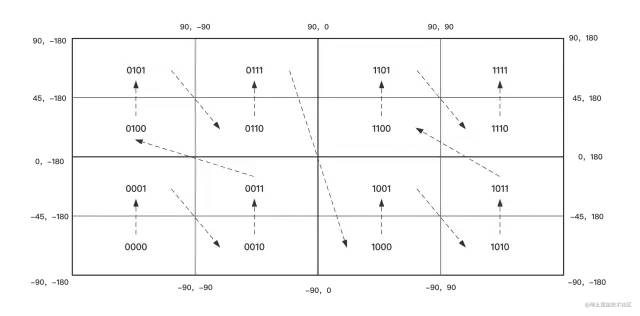
对这些矩形进一步切分,切分的次数越多矩形越小,计算距离的误差也越小,最终就可以得到足够小的矩形来表示一个范围了,用这个小矩形的二进制编码来表示它的整数hash值,矩形的边长就是GeoHash的误差。通过计算切分10次后就可以得到宽约40km、高约20km的矩形。也就是说用20bit(经度后纬度各10bit)的GeoHash编码后,能够得到东西方向上误差40km,南北方向误差20km的整数编码。
下边是推算出的GeoHash的编码长度和精度误差关系表:
| GeoHash长度(base32编码) | Lat位数(bit) | Lng位数(bit) | km误差 |
|---|---|---|---|
| 1 | 2 | 3 | ±2500 |
| 2 | 5 | 5 | ±630 |
| 3 | 7 | 8 | ±78 |
| 4 | 10 | 10 | ±20 |
| 5 | 12 | 13 | ±2.4 |
| 6 | 15 | 15 | ±0.61 |
| 7 | 17 | 18 | ±0.076 |
| 8 | 20 | 20 | ±0.01911 |
| 9 | 22 | 23 | ±0.00478 |
| 10 | 25 | 25 | ±0.0005971 |
| 11 | 27 | 28 | ±0.0001492 |
| 12 | 30 | 30 | ±0.0000186 |
观察我们对经纬度二维平面进行切割的过程,第一次切割后我们可以用一条线将00、01、10、11给连接起来,这条线是一个Z字;第二次切割后,我们同样使用一条线将0000到1111这16个编码矩形给连接了起来,观察整条曲线也是一个Z字型,这16个编码矩形中的每4个一组的矩形也是用类似Z字型的曲线给连接起来的。Z阶曲线中元素的数量一定为4的n次方,也即等于4乘以4的n-1次方。此处把4的n-1次方当成一个点,即可得到一个Z字形的曲线;4的n-1次方还是一个Z阶曲线。这个我们就可以得到一个递归的定义,这种空间填充曲线又叫Peano空间填充曲线。
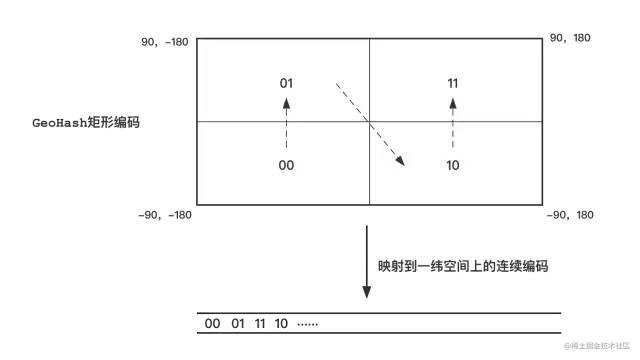
除了Peano空间填充曲线之外还有其他的空间填充曲线,这些空间填充曲线的一个共同特点是能够用一条线将整个平面切分的网格给连接起来。GeoHash编码选择空间填充曲线的考量标准有两个,一是编码是否简单,是否能够进行范围查找;二是网格之间相互连接的突变性(相隔很远的网格之间的曲线连接)。

从整体效果上来看Hilbert空间填充曲线更加平滑,没有太大的突变,但是Peano实现简单,所以GeoHash算法采用的是Peano空间填充曲线。GeoHash的整个编码过程就是这样的,读者需要注意两个关键点,第一个关键点是GeoHash将网格编码成整数值采用的是计算机字节的大端序,经度和纬度以奇偶交错的方式进行编码;第二个关键点是映射到相同网格内的POI具有相同的二进制字节编码前缀,理论上两个POI的GeoHash编码值公共编码前缀越长,它们之间的距离就越近。
2.2 Go语言实现GeoHash编码(二分查找法)
GeoHash编码其实就是将一对经纬度坐标(lng, lat)给编码映射成一个无符号正整数,其中正整数的二进制中奇数位是经度,偶数位是纬度。Go语言有uint8,uint16,uint32, uint64几种规格的正整数,可以使用这些正整数的中一部分位(比如uint64有64个bit位,使用其中的52个bit位存储GeoHash的编码值)。使用的位数越多,能够表达的坐标就越是精确,通过前边GeoHash的精度误差表可以看出,使用52bit进行编码已经可以将误差范围控制在1米以内了,这对于大多数业务来说都是可以接受的。
下面以百度大厦的经纬度坐标(116.30778,40.056859)为例,采用二分查找思想对其进行编码,这种算法虽然速度慢,但是方便理解。
先对经度编码,将
[-180, 180]分为两份:[-180, 0], [0, 180];116.30778 位于右侧,将编码值第一个位标记为1;然后再对纬度编码,将[-90, 90]分为两份:[-90, 0], [0, 90];40.056859位于右侧,将编码值的第二位标记为1;第一轮编码结束。下面开始第二轮编码,将
[0, 180]分为两份:[0, 90], [90, 180];116.30778 位于右侧,将编码值的第三位标记为1;然后再对纬度编码,将[0, 90]分为两份:[0, 45], [45, 90];40.056859位于左侧,将编码值的第四位标记为0;第二轮编码结束。经过两轮编码,我们得到了百度大厦的坐标位于前边切分的网格1110中。上述步骤一共重复26次,奇数位的经度会无限趋向
116.30778,偶数位的纬度会无限趋向40.056859。最终将经度编码和纬度编码奇偶位交叉到一个uint64的整数中。
代码非常简单,因为golang 操作二进制数据的最小单位是 byte 而非 bit,还需要额外做一些工作来实现按bit编码:
const defaultBitSize = 52 // 一共使用52个位, 其中26个位表示经度, 26个位表示纬度
// return: geohash, llbox
func encode0(lng, lat float64, bitSize uint) ([]byte, [2][2]float64)
llbox := [2][2]float64
-180, 180, // lng
-90, 90, // lat
pos := [2]float64lng, lat
hash := &bytes.Buffer
bit := 0
var step uint8 = 0
code := uint8(0)
for step < bitSize
for direction, val := range pos
mid := (llbox[direction][0] + llbox[direction][1]) / 2
if val < mid
llbox[direction][1] = mid
else
llbox[direction][0] = mid
code |= 1 << (7 - bit) //[]uint8128, 64, 32, 16, 8, 4, 2, 1
bit++
if bit == 8
hash.WriteByte(code)
bit = 0
code = 0
step++
if step == bitSize
break
// 最后不足8bit有剩余的作为一个字节
if code > 0
hash.WriteByte(code)
return hash.Bytes(), llbox
得到了GeoHash字节数组后,可以很容易转换为uint64整数值存储到数据库中:
// ToUint64 将geohash code转化为uint64表达
func ToUint64(buf []byte) uint64
// padding
if len(buf) < 8
buf2 := make([]byte, 8)
copy(buf2, buf)
return binary.BigEndian.Uint64(buf2)
return binary.BigEndian.Uint64(buf)
也可以对GeoHash字节数组进行base32编码,将其转化为字符串,更方便传输和表达,base32的编码由10个数字和去掉a、i、l、o的小写英文字母组成,如下图:
// hashcode转换为base32编码
var enc = base32.NewEncoding("0123456789bcdefghjkmnpqrstuvwxyz").WithPadding(base32.NoPadding)
// ToStr 将geohash code进行base32编码
func ToStr(buf []byte) string
return enc.EncodeToString(buf)
2.3 九宫格检索
明白了GeoHash的编码过程,我们再来看看如何利用GeoHash编码实现周边检索,如下图:

假定给到定位点1,查找半径为r区域内的POI点,实际情况下POI点2是符合条件的,但是在查找扫描POI时会被遗漏掉,我们来看一下究竟是为什么。查找的过程分两步,第一步是计算得到定位点1所在的切分网格GeoHash编码值,最终得到的结果是wx4g41,根据前边二分法的切割网格的过程分析,可以根据查找半径r动态计算GeoHash编码的长度,Go语言实现代码如下:
mercatorMax = 20037726.37 // pi * earthRadius
func geohashEstimatePrecisionByRadius(radiusMeters float64, latitude float64) (step uint8)
step = 1
for radiusMeters < mercatorMax
radiusMeters *= 2
step++
step -= 2
if latitude > 66 || latitude < -66
step--
if latitude > 80 || latitude < -80
step--
if step < 1
step = 1
if step > 32
step = 32
return step*2 - 1
找到编码步长step,其中每个step对应两个二进制位,表示一次经纬度切割。之后将step减2,降低精度以确保能包含r的查找范围。由于极地放大,也需要降低精度,扩大搜索区间。最后返回值是一个奇数step*2 - 1,这是因为要确保经度比纬度多一次切割,这样才能保证切分的网格是正方形。
第二步是在计算得到了GeoHash编码值wx4g41后,扫描网格内的所有POI,可以看到POI点2并不在网格中,真实的查找周边POI业务场景中,遗漏符合条件的POI是无法接受的。
业界的做法通常是除了扫描定位点所在网格内的POI之外,还会扫描该网格周围的8个邻居网格中所有的POI,最后根据计算排除r距离范围之外的POI点,这样就做到了无遗漏的POI检索。也就是我们要检索一个九宫格,问题就变成了如何确定这9个切分网格的编码值了。
一个直观的思路是根据定位点坐标经纬度,根据检索半径r查找网格8个方向的邻居中心点坐标,然后对这9个中心点坐标分别编码,确定九宫格的GeoHash查找范围,对应的是九个uint64的GeoHash编码范围,Go语言的实现代码如下:
// GetNeighbours 根据给定的 geohash code 返回坐标半径内的所有网格块
func GetNeighbours(latitude, longitude, radiusMeters float64) [][2]uint64
step := geohashEstimatePrecisionByRadius(radiusMeters, latitude)
center, box := encode0(latitude, longitude, step)
height := box[0][1] - box[0][0]
width := box[1][1] - box[1][0]
centerLng := (box[0][1] + box[0][0]) / 2
centerLat := (box[1][1] + box[1][0]) / 2
maxLat := centerLat + height
minLat := centerLat - height
maxLng := centerLng + width
minLng := centerLng - width
var result [9][2]uint64
leftUpper, _ := encode0(maxLat, minLng, step)
result[0] = toRange(leftUpper, step)
upper, _ := encode0(maxLat, centerLng, step)
result[1] = toRange(upper, step)
rightUpper, _ := encode0(maxLat, maxLng, step)
result[2] = toRange(rightUpper, step)
left, _ := encode0(centerLat, minLng, step)
result[3] = toRange(left, step)
result[4] = toRange(center, step)
right, _ := encode0(centerLat, maxLng, step)
result[5] = toRange(right, step)
leftDown, _ := encode0(minLat, minLng, step)
result[6] = toRange(leftDown, step)
down, _ := encode0(minLat, centerLng, step)
result[7] = toRange(down, step)
rightDown, _ := encode0(minLat, maxLng, step)
result[8] = toRange(rightDown, step)
return result[1:]
// toRange : 将 geohash 转化为uint64的范围
func toRange(scope []byte, step uint8) [2]uint64
lower := ToUint64(scope)
radius := uint64(1 << (64 - step))
upper := lower + radius
return [2]uint64lower, upper
2.4 GeoHash编码的应用——渐进式召回查询优化
有了GeoHash编码值,就可以再次对前边的SQL查询进行优化了。经过分析可知,搜索半径5km范围内的POI,仅需要26位GeoHash编码,如果对这26位GeoHash进行base32编码,得到的是6位的字符串。如果我们使用5位的GeoHash的字符串编码,就可以表达半径20km内的POI了;4位的GeoHash编码则可以表达半径160km内的POI,几乎可以覆盖整个城市了。
我们可以给positions添加三个GeoHash字段(geohash_4、geohash_5、geohash_6)方便范围检索,他们的字段类型是char定长字段,并且由于字段区分度高,比较简短,我们再将覆盖索引idx_lng_lat 拆分成3个覆盖索引。现在的positions数据表如下所示:
CREATE TABLE `positions` (
`id` bitint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`poi_uid` varchar(64) NOT NULL COMMENT 'poi的唯一id',
`lng` double(15, 7) NOT NULL COMMENT 'poi的经度',
`lat` double(15, 7) NOT NULL COMMENT 'poi的纬度',
`geohash_4` char(4) NOT NULL DEFAULT '' COMMENT 'geohash的前4位',
`geohash_5` char(5) NOT NULL DEFAULT '' COMMENT 'geohash的前5位',
`geohash_6` char(4) NOT NULL DEFAULT '' COMMENT 'geohash的前6位',
... //其他poi属性字段信息
PRIMARY KEY (`id`),
INDEX KEY `idx_geohash4_lng_lat`(`geohash4`, `lng`, `lat`),
INDEX KEY `idx_geohash5_lng_lat`(`geohash5`, `lng`, `lat`),
INDEX KEY `idx_geohash6_lng_lat`(`geohash6`, `lng`, `lat`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8我们的业务逻辑上就可以对周边检索的SQL根据得到的九宫格GeoHash字符串编码进行范围查询了:
SELECT
`id`, `poi_uid`, `lng`, `lat`, ...
ROUND(
6371.393 * 2 * ASIN(
SQRT(
POW(
SIN(
(
'$poi_lat' * 3.1415926 / 180 - `lat` * PI() / 180
) / 2
),
2
) + COS('$poi_lat' * 3.1415926 / 180) * COS(`lat` * PI() / 180) * POW(
SIN(
(
'$poi_lng' * 3.1415926 / 180 - `lng` * PI() / 180
) / 2
),
2
)
)
) * 1000
) AS distance_um
FROM
`positions`
WHERE `geohash_6` in ("wx4gef", "wx4g44", "wx4g40", "wx4g41",
"wx4g42", "wx4g43", "wx4g1c","wx4g1b", "wx4g46")
ORDER BY
distance_um ASC
LIMIT '$topN'这条SQL语句是能够使用到二级索引,使查询扫描行数减少从而加快查询效率。
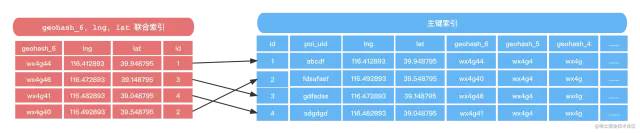
假如使用idx_geohash6_lng_lat没有获取到topN的POI记录,就可以根据我们的估算,再次扩大距离,使用idx_geohash5_lng_lat、idx_geohash4_lng_lat覆盖索引再次查询。就拿检索周边的美食店铺来说,在城市的热门地区,美食店铺POI密集,idx_geohash6_lng_lat足以覆盖大多数的查询;而对于偏僻地区,美食店铺POI比较少,通常查询idx_geohash6_lng_lat,扫描的数据也会比较少,查询比较快,用户请求量也不大。所以给Mysql添加GeoHash字符串索引,渐进式匹配召回POI是一个解决周边检索业务很好的方案。

3. RedisGeo 快速检索周边

对于“美团”、“百度地图”、“支付宝”这些App,用户体量庞大,并发请求巨大,Mysql数据库根本无法支撑周边检索POI的服务。应对这种高并发场景,Redis在3.2版本以后添加了Geo模块,支持高并发的周边检索POI的服务。
和我们前边提到的Mysql解决方案不同,Redis使用有序集合zset实现POI的范围检索。在Redis中,经纬度使用52位的GeoHash整数编码作为zset的score,zset的score是64位double类型,但是对于52位的整数值,它可以无损存储。
3.1 Geo指令和周边检索
从业务上看我们可以将Redis的Geo想象成一个容器,容器里装满了POI信息,Redis提供了根据经纬度从容器中查询这些POI信息的能力。从数据结构实现上看,Redis的Geo使用的是有序集合zset,一切有关于zset的Redis指令,对于Geo都适用;Redis官方没有提供从Geo中移除POI信息的指令,因为我们可以通过zrem指令达到这个目的。
Redis提供了6个Geo指令,它们的参数很多,不过很容易理解,下边简单列举一下。
geoadd : 添加经纬度信息的POI信息到geo容器中
geodist : 计算两个POI之间的距离
geopos : 获取POI的经纬度坐标
geohash : 获取根据添加POI经纬度进行GeoHash编码后的字符串
georadiusbymember : 用来查询POI附近的其他POI
georadius : 根据经纬度坐标查询附近的元素
Redis实现周边检索只需要两个步骤,第一步是构建Geo容器,也就是添加POI到集合中,比如将我们上边提到的positions数据表中的POI添加到geo容器里,使用geoadd命令(支持批量)即可
redis-cli
127.0.0.1:6379> geoadd positions 116.412893 39.948795 abcdf
(integer) 1
127.0.0.1:6379> geoadd positions 116.492893 39.548795 fdsafasf
(integer) 1
127.0.0.1:6379> geoadd positions 116.472893 39.148795 gdfsdas 116.482893 39.048795 sdgdgd
(integer) 2第二步和Mysql的查询类似,使用georadius来完成,例如给定一个定位点(116.432893 39.178795),查询50km以内的最近的top3 POI
127.0.0.1:6379> georadius positions 116.432893 39.178795 20 km withdist count 3 asc
1) 1) "gdfsdas"
2) "4.7992"
2) 1) "sdgdgd"
2) "15.0896"同样的,redis也存在查找topN的POI不完整的情况,我们也可以使用渐进式召回的策略查找,为了减少redis请求的网络io,可以使用Lua脚本封装渐进式召回的逻辑。
Redis 7.0 新增了# Redis Functions的新特性,支持自定义lua函数维护在redis的服务端,并随着集群做传播,它是原子性的,可以组合redis现有的所有指令作为新的功能使用,感兴趣的读者可以了解一下。
3.2 大key问题
在地图的应用中,各种POI数据可能有几亿个,显然不可能通过单实例部署。即使在集群环境,Redis的Geo数据结构是一个zset集合,几万的POI信息也会给集群的迁移工作造成影响,影响服务的运行。这种情况下就要从业务上考虑,将Geo数据按照省、市或者地理位置范围做拆分了,例如可以将全国的美食店铺,按照城市做划分,这样就可以显著降低单个zset集合的内存占用,也会加快检索速度。

4. Geo本地索引构建与并发查询

通过对Mysql和Redis实现周边检索POI的分析可知,Geo的索引本质上是通过GeoHash的编码进行范围查询的数据结构。我们完全可以使用Go语言自己实现一个跳表或者前缀树来构建业务中的Geo索引,只存储经纬度和POI的唯一ID的基本信息对于内存的占用是非常小的,假如Geo中存储一条完成的的POI信息只需要20个字节,存储100万个POI只需要19M内存,由此可见构建自己的Geo本地索引是一件很划算的事。
有了Geo本地索引,我们还可以利用Go语言的并发查找能力加快查询。笔者有专门做过压测,在1000并发请求的环境中,Go语言可以在0.02ms内从100万POI中快速检索出top100,也就是说周边检索POI这件看似困难的工作,使用本地Geo索引库几乎是零成本。下边是使用Go语言并发压测检索的代码,感兴趣的读者可以按照本文的思路构建一个Geo本地索引做尝试。
package fastgeo
import (
"math/rand"
"strconv"
"testing"
"time"
)
var fastGeo *FastGeo
// init : 初始化fastgeo实例
func init()
fastGeo = MakeFastGeo()
lngMin, lngMax := 116171356, 116638188
latMin, latMax := 39748529, 40155613
rand.Seed(time.Now().UnixNano())
// 插入100万的poi坐标
for i := 1; i <= 1000000; i++
lngRandom := float64(rand.Intn(lngMax-lngMin) + lngMin) / 1000000
latRandom := float64(rand.Intn(latMax-latMin) + latMin) / 1000000
fastGeo.GeoAdd(lngRandom, latRandom, strconv.Itoa(i))
// BenchmarkFastGeo_GeoRadius : 压测GeoRadius函数
func BenchmarkFastGeo_GeoRadius(b *testing.B)
lngMin, lngMax := 116171356, 116638188
latMin, latMax := 39748529, 40155613
rand.Seed(time.Now().UnixNano())
for n := 0; n < b.N; n++
lngRandom := float64(rand.Intn(lngMax-lngMin) + lngMin) / 1000000
latRandom := float64(rand.Intn(latMax-latMin) + latMin) / 1000000
// 随机生成经纬度坐标并查询附近10km所有的POI
fastGeo.GeoRadius(lngRandom, latRandom, 10000, 0, 100)
对于GeoRadius,Go语言实现并发查找也很简单,在计算出九宫格的GeoHash范围后,使用waitGroup添加9个协程分别查询各自网格中的POI;待所有的协程完成工作后将结果merge起来,按照距离排序使用内置函数即可。
// GeoRadius : 获取指定半径内的元素
func (fastGeo *FastGeo) GeoRadius(lng, lat, radius float64, offset, limit int64) []string
areas := geohash.GetNeighbours(lat, lng, radius)
parallelNum := len(areas)
var waitGroup sync.WaitGroup
waitGroup.Add(parallelNum)
var mutex sync.Mutex
members := make([]string, 0)
for _, area := range areas
go func(area [2]uint64)
lower := &sortedset.ScoreBorderValue: float64(area[0])
upper := &sortedset.ScoreBorderValue: float64(area[1])
elements := fastGeo.Container.RangeByScore(lower, upper, offset, limit, true)
for _, elem := range elements
mutex.Lock()
members = append(members, elem.Member)
mutex.Unlock()
(area)
waitGroup.Done()
// todo: 根据距离排序
return members

5. 总结与展望

本文结合周边检POI的业务场景,跟大家分享了Mysql和Redis如何使用优化;对GeoHash的编码原理做了详细的介绍,并附有源码实现。文章的最后给出了构建自己本地Geo索引库的思路,业务中有需要的读者可以借鉴实现。总体来说周边检索POI的技术实现并不难,但是越来越多的周边检索服务出现在我们的生活中,给我们带来了很多便利,希望有兴趣的开发者在工作中遇到此类问题时能够借鉴本文的思路。
对于GeoHash中的实现,Redis在经纬度位交叉编码、查找九宫格采用的算法思路,都比本文中介绍的更优。本文的初衷是帮助读者理解GeoHash的原理,感兴趣肯钻研的读者推荐研究一下Redis的Geo代码实现。
在真实的业务场景中,除了周边检索POI,还有根据其他因素检索排序的需求,例如大众点评上的美食,距离只是影响其中展现的一个因素,价格、大众评分、用户搜索分类也会影响POI排名。对于此类业务场景,需要构建更复杂的索引,其中包含Geo索引、倒排索引等等,后续笔者也会继续研究此类通用业务,期望将来实现一个本地通用的索引库帮助开发者做更多的事情。
笔者水平有限,文中有不足或错误之处,欢迎留言指正。
最后说一句(别白嫖,求关注)
回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
lazy-mock ,一个生成后端模拟数据的懒人工具
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
字节跳动一面:i++ 是线程安全的吗?
一条 SQL 引发的事故,同事直接被开除!!
太扎心!排查阿里云 ECS 的 CPU 居然达100%
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术!
喜欢就给个“在看”以上是关于周边检索POI技术方案设计的主要内容,如果未能解决你的问题,请参考以下文章