论文解析[9] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Posted 默_silence
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解析[9] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows相关的知识,希望对你有一定的参考价值。
发表时间:2021
论文地址:https://arxiv.org/abs/2103.14030
代码地址:https://github.com/microsoft/Swin-Transformer
文章目录
摘要
这篇论文提出了一个新的ViT叫作Swin Transformer, 它可以被用来当作计算机视觉领域一个通用的骨干网络。将Transformer从语言改编到视觉的挑战来自于两个领域的差异,比如同一个视觉实体有不同的尺度、相比于文本中单词,图像中像素的高分辨率。
为了解决这些差异,我们提出了一种层级的Transformer,它的特征是通过移动窗口来进行计算的。移动窗口不仅带来了更好的效率,也允许交叉窗口连接。这种层级结构拥有在不同尺度建模的灵活性,也拥有关于图像大小的线性计算复杂度。
这些Transformer的特征可以让它使用到广泛的下游任务中,包括图像分类,密集预测任务例如目标检测和语义分割。
层级设计和移动窗口方法也能够提升所有的MLP结构。
3 方法
3.1 总体框架

Swin Tranformer block

Swin Transformer是用基于移动窗口的模块替换Transformer block中的标准多头自注意力(MSA)模块。
一个Transformer block包括一个基于MSA的移动窗口模块,然后是一个二层的MLP。在MSA模块和MLP层之前,都有一个标准化层(LN)。
3.2 基于自注意力的移动窗口
用于图像分类的标准Transformer结构和它的改编都是使用全局自注意力,计算一个token和其他全部token的关系。全局计算导致了关于token数量平方的复杂度,导致了它不适合许多需要极大token的数据集的视觉任务,例如密集预测,或者表示一个高分辨率图像。
Self-attention in non-overlapped windows
对于有效的建模,我们提出在窗口中计算自注意力。窗口是以一种不重叠的方式均匀划分图像。假设每个窗口包含M×M个patch,计算一个全局MSA模块和一个基于h×w个patch的图像的复杂度:

前者是关于patch数量hw的平方复杂度,后者当M固定时,关于hw线性复杂度。当基于自注意力的窗口很大时,全局自注意力的计算往往是不可接受的。
Shifted window partitioning in successive blocks
基于窗口的自注意力模块缺少窗口之间的连接,会限制它的建模能力。为了引入窗口之间的连接并且保持不重叠窗口的计算效率,我们提出了一种移动窗口的划分方式,它可以在连续的Swin Transformer块中的两种划分方式之间交替。
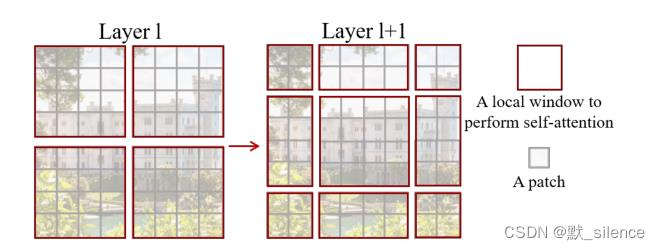
第一个模块使用正常的窗口分割策略,从左上方像素开始,8×8的特征图平均分割成了2×2个4×4大小的窗口。下一个模块采用从上一层移动而来的窗口策略,通过(是⌊M/2⌋, ⌊M/2⌋)像素替换正常分割窗口。
带有移动窗口策略的Swin Transformer block计算:
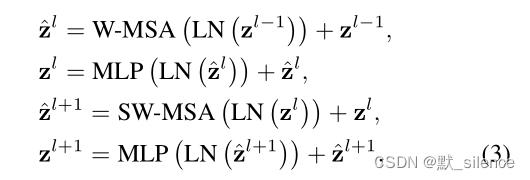
z
^
l
\\hatz^l
z^l 和
z
l
z^l
zl 代表W-MSA模块和MLP的输出特征,W-MSA和SW-MSA代表基于多头自注意力使用正常和移动分割策略。
移动窗口分割方式带来了邻近不重叠窗口之间的连接,对于图像分类、目标检测和语义分割来说是有效的。
Efficient batch computation for shifted configuration
使用移动窗口分割的一个问题是它会导致更多的窗口,从 ⌈h/M⌉×⌈h/M⌉ 变为 (⌈h/M⌉ + 1)×(⌈h/M⌉ + 1),一些窗口会小于 M×M。一个朴素的办法是将小窗口填充为M×M,在计算注意力时掩盖填充的值。当使用正常分割的窗口数比较小时,例如2×2,使用这种方法提升的计算量是相当大的(2×2到3×3,2.25倍)。我们提出了一个更有效的batch计算方式,通过向左上方循环移动,如图4。

经过这次移动,一个窗口会由几个在特征图中不相邻的子窗口组成,因此一个掩码机制被用来限制每个子窗口中的自注意力计算。通过循环移动,窗口的数目和正常分割相同,并且是有效率的。
3.3 结构变形
我们创建了基础模型Swin-B,具有和ViT-B/DeiT-B相似的模型大小和计算复杂度。我们也引入了Swin-T, Swin-S和Swin-L,是0.25倍,0.5倍和2倍模型大小和复杂度。注意到Swin-T和Swin-S的复杂度相似于ResNet-50 (DeiT-S) 和ResNet-101。
5 结论
这篇论文提出了Swin Transformer,可以生成层级特征表示和关于输入图像大小线性复杂度的一个新ViT。它在COCO目标检测和ADE20K语义分割上取得了sota的表现,显著超过先前的最佳表现。我们希望Swin Transformer在不同视觉问题上的强大表现可以激发视觉和语言信号的统一建模。
作为Swin Transformer的一个关键元素,基于自注意力的移动窗口在视觉领域上是有效和有效率的,我们期待研究它在 nlp 上的使用。
以上是关于论文解析[9] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文速递ECCV2022 - 开销聚合与四维卷积Swin Transformer_小样本分割
论文速递ECCV2022 - 开销聚合与四维卷积Swin Transformer_小样本分割