爬虫总被禁?看看代理在Python中的运用吧
Posted IT学习日记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫总被禁?看看代理在Python中的运用吧相关的知识,希望对你有一定的参考价值。
文章目录
单一IP的局限性
相信学习爬虫的小伙伴或多或少都遇到过一个场景,在对某些网站爬取操作时因为频率,反爬等措施被识别为机器操作,从而客户端访问受到限制,通常的方式就是IP地址封禁,时间短则5~6分钟,长则上10小时。

如果程序只是用于自己学习,封禁操作影响倒是不大,但是如果是在工作中中处理实际业务的程序遇到了IP封禁,那么可能会影响到公司整个的业务进行和流转,因为很多业务是依赖于爬虫程序拉取到的数据进行的如:使用进行习惯分析,客户行为分析等,如果数据源头被封禁,那么影响将是致命的,此时,则可以引入代理IP的方式来避免出现类似问题。
计算机通信和代理IP
在认识什么是代理IP之前,我们先来认识下互联网间各个机器是如何识别对方身份的,这样后续能够更好理解代理IP的作用。
在互联网中,不同计算机之间识别身份是通过每个机器对应的IP地址实现的(可以理解成跟身份证一样),通常说的IP地址分为局域网IP地址(如:127.00.1或者192.168.xx)和广域网IP地址(实际上对外的地址),这里提到的IP地址则是广域网的IP地址。
比如,我们可以在浏览器输入:IP,这时候显示的地址就是我们计算机对外的实际IP地址:
识别流程
当我们通过手机、电脑等设备访问一个网站如百度,百度服务器可以获取到我们这个手机或者电脑的IP地址,从而获取到对应的一些信息如IP地址所属区域,就比如现在各大平台都上线了一个用户所属地的功能,每个发言的用户后面都会携带相应的地址信息,实现的原理也是类似。
一旦代表我们手机或电脑的发出的操作被网站认为是在进行爬虫,网站则可以直接限制这个IP对网站(通过反爬策略)的操作,此时由该IP地址发出的所有请求都可能被网站进行拦截,这时候如果程序还有后续的业务逻辑,那么将无法进行。
代理IP和代理IP池
上面说到,IP地址就跟我们的身份证一样,可以识别计算机的身份,一旦IP地址被限制,我们将无法对网站进行其他操作,此时我们可以通过代理IP的方式解决这个问题。
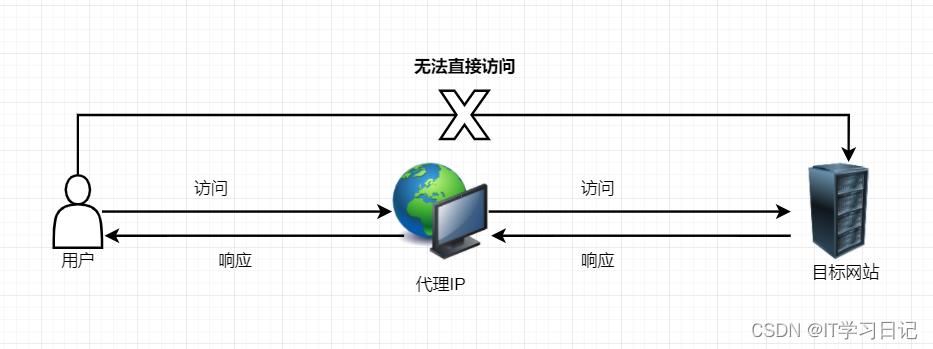
代理IP: 可以理解成一个中间平台,我们的程序先将请求发出到代理IP,由代理IP再将我们的实际请求发给对应的网站,此时,网站看到的访问IP就是代理IP,而不是我们的计算机的实际IP地址,这样就可以避开网站的封禁限制(通俗的理解:我们的“身份证”被拉入了访问黑名单,此时可以通过借助其他人的“身份证”来访问)。
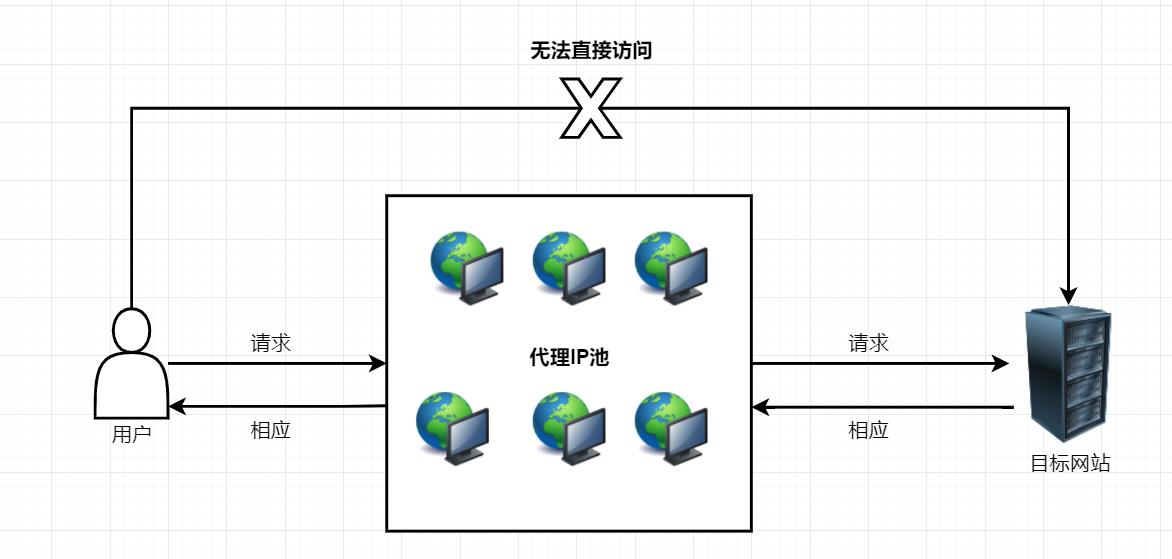
代理IP池: 单一的代理IP还是存在容易被封禁的问题,因此,可以将多个代理IP维护到一个“池”中(跟线程池类似),当某个代理IP被封禁时,可以切换到其他的代理IP,这样被封禁的概率将大大降低。
代理IP的优点
-
降低被封禁概率: 因为有了代理IP池,可以进行代理IP地址的切换,从而避免了"单点故障",代理IP池越大,使用时被限制的几率就越低。
-
提高了安全性: 在IP代理平台,用户可以进行IP地址过滤,限制内部网对外部网的访问权限、封锁指定IP地址,控制用户访问某些网络的权限,从而起到类似防火墙的作用,极大提高了安全性。
-
隐藏真实IP地址: 通过代理IP,可以将用户的真实IP隐藏,使用代理IP发起请求,从而保证了隐私(很多黑客在进行网络攻击时,都会通过几台甚至几十台代理的方式,层层隐蔽,从而避免暴露真实身份)
-
提升网络访问速度,降低延迟: 通常IP代理都会有缓存区功能,用户访问相同消息的时候,可以直接从缓冲区中读取返回,从而提高访问速度。
-
避开地域访问限制: 一些网站会通过IP地址对访问的用户进行限制,使用代理IP平台,可以根据实际情况进行所需要的的地域IP选择,从而跳出地域访问限制(如A想访问C网站,但是中间网络存在问题,则可以先通过访问B代理,再由B代理访问C,实现跳出限制)。
代理IP使用的实战
通过前面的理论知识铺垫,下面通过实战的方式来讲解代理IP的使用,帮助大家更好地理解代理IP在实际业务中发挥的作用。
一、选择合适代理池
本次演示是通过:IPIDEA代理池,注册即可领取100M流量,不够还可以根据需要购买。
地址:代理池申请
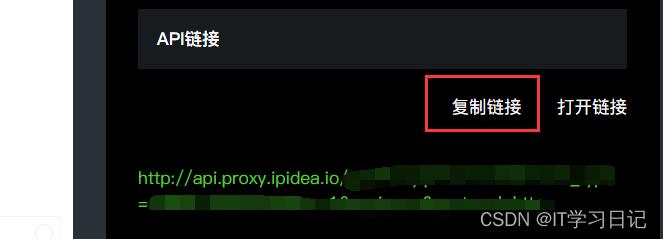
流程一:生成API链接
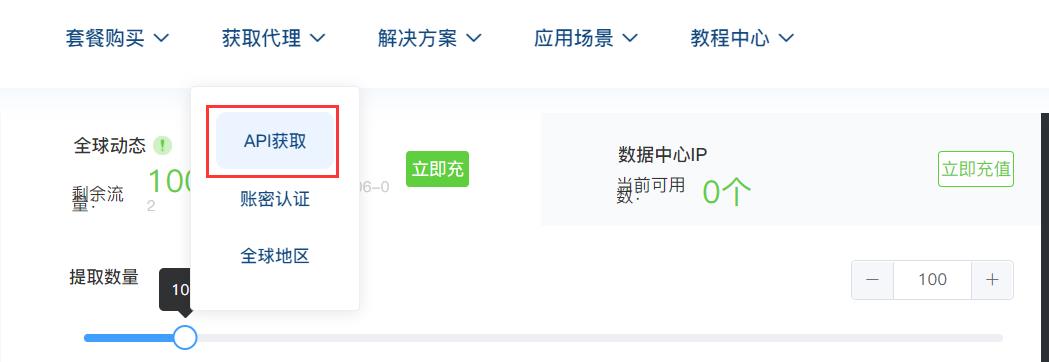
流程二:将生成的API链接保存供程序使用
二、实战案例
案例目的: 爬取亚马逊下网站电脑的价格进行数据分析
网战地址: 爬取地址
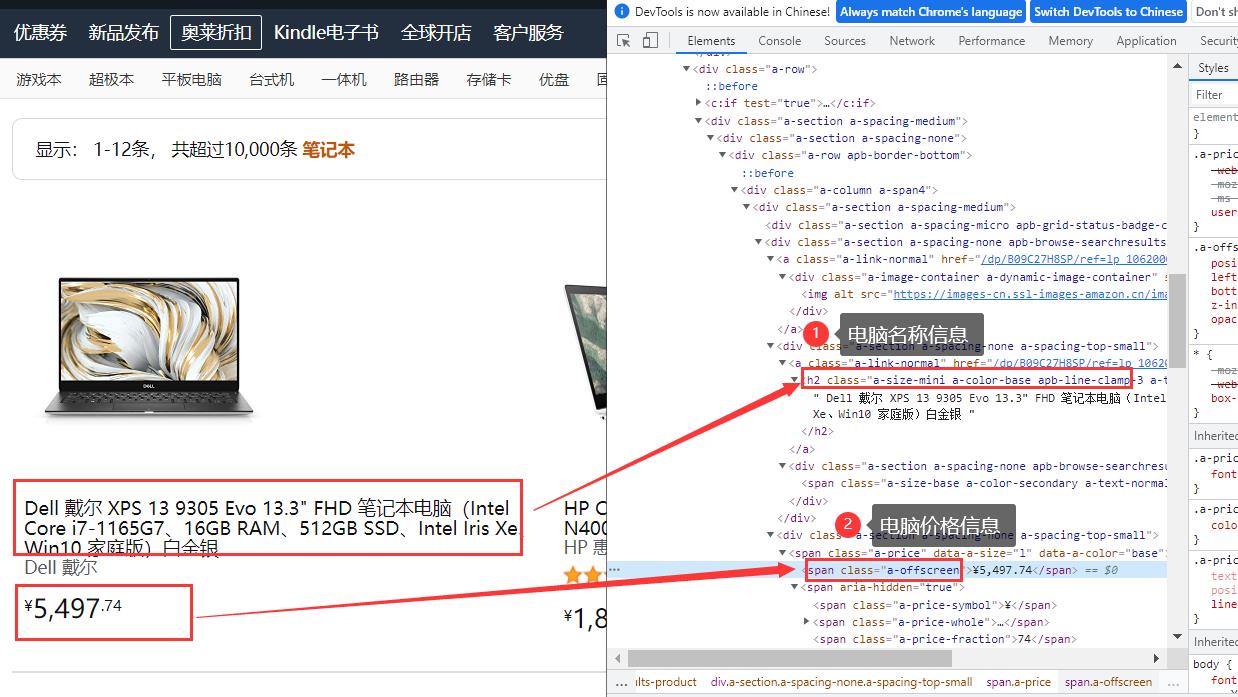
逻辑分析: 通过浏览器调试工具查询到需要获取信息的标签,然后使用xpath获取指定元素数据,具体如下图:
实现代码:
import requests
import json
from lxml import etree
# 代理对象
proxies =
# 代理IP URL获取代理IP
proxy_pool_url = '你在ipidea平台申请的代理池URL地址'
res = requests.get(proxy_pool_url)
# 将响应数据转换诚json对象
resJson = json.loads(res.text)
print(resJson)
# 组装代理池(此处省略ip封禁时切换ip地址的逻辑,需要的可以可以自定义)
for item in resJson["data"]:
http_itemStr = "http://"+ item["ip"] + ":"+ str(item["port"])
https_itemStr = "https://"+ item["ip"] + ":"+ str(item["port"])
proxies["http"] = http_itemStr
#proxies["https"] = https_itemStr
print(proxies)
# 伪装成浏览器进行访问
headers =
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'rtt': '50',
'downlink': '10',
'ect': '4g',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Referer': 'https://www.amazon.cn/default.asp',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8'
# 查询参数
params =
'node': '106200071',
'ref_': 'nav_em__pc_notebook_0_2_3_2',
# 使用代理IP发起爬虫请求
response = requests.get('https://www.amazon.cn/gp/browse.html', params, headers=headers, proxies=proxies)
# 读取电脑名称
name_list = etree.HTML(response.text).xpath('//h2/text()')
# 读取电脑价格
price_list = etree.HTML(response.text).xpath('//span[@class="a-offscreen"]/text()')
# 输出电脑名称和价格
for name, price in zip(name_list, price_list):
# 去除名称前后的制表符和换换行符
nameStr = name.strip();
print(nameStr, price, '\\n')
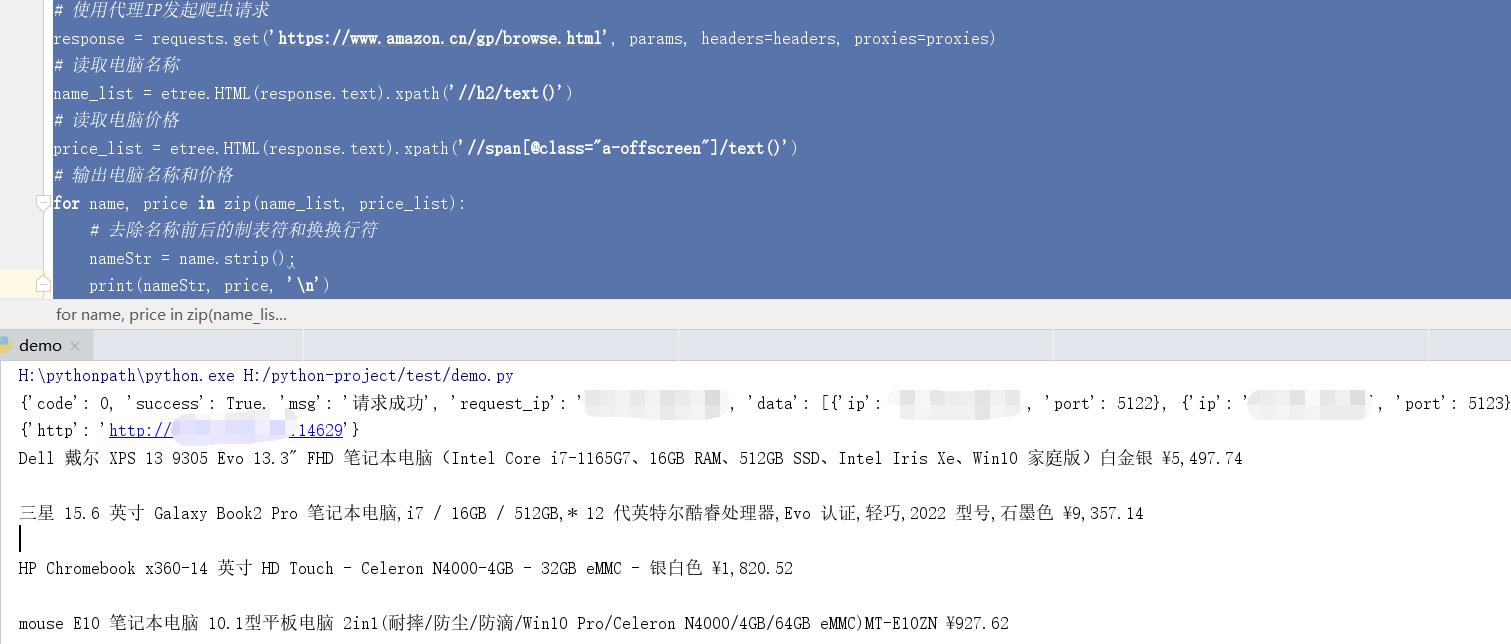
完成效果:
写在最后
工欲善其事必先利其器,稳定性对于程序有着至关重要的作用,程序的操作频率越高,被限制的机率就越大,引入代理IP可以规避掉大部分风险。IPIDEA代理池是一个不错的选择,除了可用IP量(9000多万)大外,还提供了住宅IP等功能,有类似需求的可以到官网进一步了解。
大家有任何关于学习、面试、开源等方面知识,欢迎点击下方图标添加我一起进行交流。如果文章对您有帮助,请给博主关注,点赞、收藏,后续会输出更多优质文章。
以上是关于爬虫总被禁?看看代理在Python中的运用吧的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫伪装,请求头User-Agent池,和代理IP池搭建使用
Python爬虫伪装,请求头User-Agent池,和代理IP池搭建使用