关联规则—频繁项集Apriori算法
Posted 小江_xiaojiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关联规则—频繁项集Apriori算法相关的知识,希望对你有一定的参考价值。
转载地址:http://liyonghui160com.iteye.com/blog/2080531
一、前言
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果。
关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系。其中“频繁”是由人为设定的一个阈值即支持度 (support)来衡量,“紧密”也是由人为设定的一个关联阈值即置信度(confidence)来衡量的。这两种度量标准是频繁项集挖掘中两个至关重 要的因素,也是挖掘算法的关键所在。对项集支持度和规则置信度的计算是影响挖掘算法效率的决定性因素,也是对频繁项集挖掘进行改进的入口点和研究热点。
基于关联规则的分类主要分为以下以个步骤:
1. 对训练数据进行预处理(包括离散化、缺失值处理等)
2. 关联规则挖掘
2.1 频繁项集挖掘
2.2 关联规则生成
3. 规则处理
4. 对测试集进行测试
二、频繁项集挖掘
目前频繁项集挖掘已经有很多比较成熟的算法,在网上也可以找到相关的优秀论文或源代码。算法中最经典的莫过于Apriori算法,它可以算得上是频 繁项集挖掘算法的鼻祖,后续很多的改进算法也是基于Apriori算法的。但是遗憾的是Apriori算法的性能实在不咋的,当当玩具玩玩还可以,但是即 使如此,该算法却是频繁项集挖掘必须要掌握的入门算法。
题外话:关健是要了解算法的思想,你可以不了解一个东西是怎样具体实现的,但是一定得了解它是如何出来的。这样遇到相关的问题,你可以有一个参考的 解决方法,或者在关键时刻可以跟别人忽悠忽悠。当然,了解思想的最佳途径就是自己动手去实现实现了,哪怕实现得不咋样,起码思想掌握了,也是个不小的收 获。
下面就要具体介绍如何利用Apriori算法进行频繁项集挖掘了。
(1)相关概念
项集:“属性-值”对的集合,一般情况下在实际操作中会省略属性。
候选项集:用来获取频繁项集的候选项集,候选项集中满足支持度条件的项集保留,不满足条件的舍弃。
频繁项集:在所有训练元组中同时出现的次数超过人工定义的阈值的项集称为频繁项集。
极大频繁项集:不存在包含当前频繁项集的频繁超集,则当前频繁项集就是极大频繁项集。
支持度:项集在所有训练元组中同时出现的次数。
置信度:形如A->B,置信度为60%表示60%的A出现的同时也出现B。
k项集:项集中的每个项有k个“属性-值”对的组合。
(2)两个定理
i:连接定理。若有两个k-1项集,每个项集按照“属性-值”(一般按值)的字母顺序进行排序。如果两个k-1项集的前k-2个项相同,而最后一 个项不同,则证明它们是可连接的,即这个k-1项集可以联姻,即可连接生成k项集。使如有两个3项集:{a, b, c}a, b, d,这两个3项集就是可连接的,它们可以连接生成4项集{a, b, c, d}。又如两个3项集{a, b, c}{a, d, e},这两个3项集显示是不能连接生成3项集的。要记住,强扭的瓜是不甜的,也结不了果的。
ii:频繁子集定理。若一个项集的子集不是频繁项集,则该项集肯定也不是频繁项集。这个很好理解,举一个例子,若存在3项集{a, b, c},如果它的2项子集{a, b}的支持度即同时出现的次数达不到阈值,则{a, b, c}同时出现的次数显然也是达不到阈值的。因此,若存在一个项集的子集不是频繁项集,那么该项集就应该被无情的舍弃。倘若你舍不得,那么这个项集就会无情 的影响你的效率以及处理器资源,所以在这时,你必须无情,斩立决!
(3)Apriori算法流程
1. 扫描数据库,生成候选1项集和频繁1项集。
2. 从2项集开始循环,由频繁k-1项集生成频繁频繁k项集。
2.1 频繁k-1项集生成2项子集,这里的2项指的生成的子集中有两个k-1项集。使如有3个2项频繁集{a, b}{b, c}{c, f},则它所有的2项子集为{{a, b}{b, c}}{{a, b}{e, f}}{{b, c}{c, f}}
2.2 对由2.1生成的2项子集中的两个项集根据上面所述的定理 i 进行连接,生成k项集。
2.3 对k项集中的每个项集根据如上所述的定理 ii 进行计算,舍弃掉子集不是频繁项集即不在频繁k-1项集中的项集。
2.4 扫描数据库,计算2.3步中过滤后的k项集的支持度,舍弃掉支持度小于阈值的项集,生成频繁k项集。
3. 当当前生成的频繁k项集中只有一个项集时循环结束。
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术, 用于从大量数据中挖掘出有价值的数据项之间的相关关系。 其中关联规则挖掘的最经典的例子就是沃尔玛的啤酒与尿布的故事 ,通过对超市购物篮数据进行分析,即顾客放入购物篮中不同商品之间的关系来分析顾客的购物习惯,发现美国妇女们经常会叮嘱丈夫下班后为孩子买尿布,30%-40%的丈夫同时会顺便购买喜爱的啤酒,超市就把尿布和啤酒放在一起销售增加销售额。
三、基本概念
关联规则挖掘是寻找给定数据集中项之间的有趣联系。如下图所示:

其中,I=I1,I2,…Im是m个不同项目的集合,集合中的元素称为项目(Item)。项目的集合I称为项目集合(Itemset),长度为k的项集成为k-项集。设任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得 T ⊆ I 。每个事务有一个标识符TID;设A是一个项集,事务T包含A当且仅当 A⊆I ,则关联规则形式为A=>B(其中 A ⊂ I , B ⊂ I ,并且 A ∩ B = ∅)。
在关联规则度量中有两个重要的度量值:支持度和置信度 。对于关联规则R:A=>B,则:
1. 支持度(suppport ): 是交易集中同时包含A和B的交易数与所有交易数之比。
Support(A=>B)=P(A∪B)=count(A∪B)/|D|
2. 置信度(confidence ): 是包含A和B交易数与包含A的交易数之比。
Confidence(A=>B)=P(B|A)=support(A∪B)/support(A)

如上图中数据库D,包含4个事务,项集I=I1,I2,I3,I4,I5,分析关联规则:I1=>I4,事务1、4包含I1,事务4同时包含I1和I4。
支持度support=1/4=25%(1个事务同时包含I1和I4,共有4个事务)指 在所有交易记录中有25%的交易记录同时包含I1和I4项目
置信度confidence=1/2=50%(1个事务同时包含I1和I4,2个事务包含I1)指 50%的顾客在购买I1时同时还会购买I4
使用关联规则对购物篮进行挖掘,通常采用两个步骤进行: 下面将通超市购物的例子对关联规则挖掘进行分析。
a.找出所有频繁项集(文章中我使用Apriori算法>=最小支持度的项集)
b.由频繁项集产生强关联规则(>=最小支持度和最小置信度)
四、举例:Apriori算法挖掘频繁项集
Apriori算法是一种对有影响的挖掘布尔关联规则频繁项集的算法,通过算法的连接和剪枝即可挖掘频繁项集。 补充频繁项集相关知识: K-项集:指包含K个项的项集; 项集的出现频率:指包含项集的事务数,简称为项集的频率、支持度计数或计数; 频繁项集:如果项集的出现频率大于或等于最小支持度计数阈值,则称它为频繁项集,其中频繁K-项集的集合通常记作L k 。
下面直接通过例子描述该算法:如下图所示(注意Items已经排好序),使用Apriori算法关联规则挖掘数据集中的频繁项集。(最小支持度技术为2)
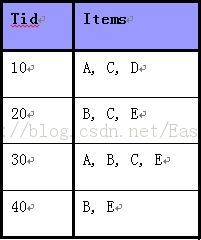
具体过程如下所示:

具体分析结果:
第一次扫描:对每个候选商品计数得C1,由于候选D支持度计数为1<最小支持度计数2,故删除D得频繁1-项集合L1;
第二次扫描:由L1产生候选C2并对候选计数得C2,比较候选支持度计数与最小支持度计数2得频繁2-项集合L2;
第三次扫描:用Apriori算法对L2进行连接和剪枝产生候选3项集合C3的过程如下:
1.连接:
C3=L2 (连接)L2=A,C,B,C,B,E,C,E A,C,B,C,B,E,C,E=A,B,C,A,C,E,B,C,E
2.剪枝:
A,B,C的2项子集A,B,A,C和B,C,其中A,B不是 2项子集L2,因此不是频繁的,从C3中删除;
A,C,E的2项子集A,C,A,E和C,E,其中A,E不是2项子集L2,因此不是频繁的,从C3中删除;
B,C,E的2项子集B,C,B,E和C,E,它的所有2项子集都是L2的元素,保留C3中.
经过Apriori算法对L2连接和剪枝后产生候选3项集的集合为C3=B,C,E. 在对该候选商品计数,由于等于最小支持度计数2,故得频繁3-项集合L3,同时由于4-项集中仅1个,故C4为空集,算法终止。
五、举例:频繁项集产生强关联规则
强关联规则是指:如果规则R:X=>Y满足support(X=>Y)>=supmin(最小支持度,它 用于衡量规则需要满足的最低重要性)且confidence(X=>Y)>=confmin(最小置信度,它表示关联规则需要满足的最低可靠 性)称关联规则X=>Y为强关联规则,否则称关联规则X=>Y为弱关联规则。
例:下图是某日超市的购物记录(注意Items已经排好序),使用上面叙述的Apriori算法实现了挖掘频繁项集,其中频繁项集I=i1,i2,i5为频繁3-项集合L3,求由I产生哪些强关联规则?(最小支持度阈值为20%,最小置信度阈值为80%)

I的非空子集有i1,i2、i1,i5、i2,i5、i1、i2和i5。
结果关联规则如下,每个都列出置信度
1).i1 ∧i2=>i5 ,共10个事务;5个事务包含i1,i2;2个事务包含i1,i2和i5 confidence=2/5=40%,support=2/10=20%
2).i1 ∧i5=>i2 ,共10个事务;2个事务包含i1,i5;2个事务包括i1,i2和i5 confidence=2/2=100%,support=2/10=20%
3).i2 ∧i5=>i1 ,共10个事务;2个事务包含i2,i5;2个事务包含i1,i2和i5 confidence=2/2=100%,support=2/10=20%
4).i1=>i2 ∧i5 ,共10个事务;7个事务包含i1;2个事务包含i1,i2和i5 confidence=2/7=28%,support=2/10=20%
5).i2=>i1 ∧i5 ,共10个事务;8个事务包含i2;2个事务包含i1,i2和i5 confidence=2/8=25%,support=2/10=20%
6).i5=>i1 ∧i2 ,共10个事务;2个事务包含i5;2个事务包含i1,i2和i5 confidence=2/2=100%,support=2/10=20%
因最小置信度阈值为80%,最小支持度阈值为20%,则236规则符合要求,是频繁项集I=i1,i2,i5产生的强关联规则且可以输出。
(自己的推测:如果给定的是最小支持度计数为2,则有10个事务,最小支持度阈值supmin=2/10=20%)
在实际应用中订单每天增加,我们采用增量的方式计算,去掉支持度的限制。
算法实现(java):
算法主体类:
package com.datamine.apriori;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 本程序用于频繁集的挖掘
* 首先用List<List<String>>类型的record将矩阵形式的数据读入内存
*
* 程序先求出k-1候选集,由后选集和数据库记录record求得满足支持度的k-1级集合,
* 在满足支持度集合中求出满足置信度的集合
* 若满足置信度的集合为空,程序停止
* 否则输出满足自信度的集合,以及对应的支持度和置信度
* 并由满足支持度的k-1级集合求出候选k级集合,进入下一轮循环
*
* 直至程序结束,输出全部频繁集
* @author Administrator
*
*/
public class Apriori
static boolean endTag = false;
static Map<Integer,Integer> dCountMap = new HashMap<Integer, Integer>(); //k-1频繁集的记数表
static Map<Integer,Integer> dkCountMap = new HashMap<Integer, Integer>(); //k频繁集的记数表
static List<List<String>> record = new ArrayList<List<String>>(); //数据记录表
// final static double MIN_SUPPORT = 0.2; //最小支持度
// final static double MIN_CONF = 0.8; //最小置信度
static double MIN_SUPPORT = 0.2; //最小支持度
static double MIN_CONF = 0.8; //最小置信度
static int lable = 1; //用于输出时的一个标记,记录当前打印第几级关联集
static List<Double> confCount = new ArrayList<Double>(); //置信度记录表
static List<List<String>> confItemset = new ArrayList<List<String>>(); //满足支持度的集合
/*public static void main(String[] args) throws Exception
record = new TxtReader().getRecord(); //获取数据
//System.out.println(record);
List<List<String>> cItemset = findFirstCandidate(); //获取第一次的候选集
//System.out.println(cItemset);
List<List<String>> lItemset = getSupportedItemset(cItemset); //获取候选集cItemset满足支持的集合
while(endTag != true) //只要能继续挖掘
List<List<String>> ckItemset = getNextCandidate(lItemset); //获取下一次的候选集
List<List<String>> lkItemset = getSupportedItemset(ckItemset); //获取候选集ckItemset满足支持的集合
System.out.println(lkItemset);
getConfidencedItemset(lkItemset,lItemset,dCountMap,dkCountMap);
if(confItemset.size() != 0) //满足置信度的集合不为空
printConfItemset(confItemset); //打印满足置信度的集合
confItemset.clear(); //清空置信度集合
cItemset = ckItemset;
lItemset = lkItemset;
dCountMap.clear();
dCountMap.putAll(dkCountMap);
*/
public void run(List<List<String>> record2,double support,double conf)
record = record2;
MIN_SUPPORT = support;
MIN_CONF = conf;
List<List<String>> cItemset = findFirstCandidate(); //获取第一次的候选集
List<List<String>> lItemset = getSupportedItemset(cItemset); //获取候选集cItemset满足支持的集合
while(endTag != true) //只要能继续挖掘
List<List<String>> ckItemset = getNextCandidate(lItemset); //获取下一次的候选集
List<List<String>> lkItemset = getSupportedItemset(ckItemset); //获取候选集ckItemset满足支持的集合
System.out.println(lkItemset);
getConfidencedItemset(lkItemset,lItemset,dCountMap,dkCountMap);
if(confItemset.size() != 0) //满足置信度的集合不为空
printConfItemset(confItemset); //打印满足置信度的集合
confItemset.clear(); //清空置信度集合
cItemset = ckItemset;
lItemset = lkItemset;
dCountMap.clear();
dCountMap.putAll(dkCountMap);
/**
* 打印结果
* @param confItemset2
*/
private static void printConfItemset(List<List<String>> confItemset2)
System.out.println("*******************频繁模式挖掘结果***********************");
for(int i = 0; i < confItemset2.size();i++)
int j =0;
for(j = 0; j < confItemset2.get(i).size()-3;j++)
System.out.print(confItemset2.get(i).get(j)+" ");
System.out.print("-->");
System.out.print(confItemset2.get(i).get(j++));
System.out.print(" 相对支持度:"+confItemset2.get(i).get(j++));
System.out.print(" 自信度:"+confItemset2.get(i).get(j++)+"\\n");
/**
* 根据4个参数求出满足自信度的集合
* @param lkItemset k项候选集
* @param lItemset k-1项集
* @param dCountMap2 k-1项频繁项纪录数
* @param dkCountMap2 k项频繁项纪录数
*/
private static void getConfidencedItemset(List<List<String>> lkItemset,
List<List<String>> lItemset, Map<Integer, Integer> dCountMap2,
Map<Integer, Integer> dkCountMap2)
for(int i = 0;i<lkItemset.size();i++)
getConfItem(lkItemset.get(i),lItemset,dkCountMap2.get(i),dCountMap2);
/**
* 检验集合list是否满足最低自信度要求
* 若满足则在全局变量confiItemset添加list
* 不满足返回null
* @param list k频繁项集中第i个元组
* @param lItemset k-1项集
* @param count k项集第i个元组计数
* @param dCountMap2 k-1项频繁项纪录map
*/
private static void getConfItem(List<String> list,
List<List<String>> lItemset, Integer count,
Map<Integer, Integer> dCountMap2)
for(int i = 0;i < list.size() ;i++)
List<String> testList = new ArrayList<String>();
for(int j = 0; j <list.size(); j++)
if( i !=j )
testList.add(list.get(j));
//查找testList中的内容在lItemset的位置
int index = findConf(testList,lItemset);
Double conf = count*1.0/dCountMap2.get(index);
if(conf > MIN_CONF)
testList.add(list.get(i));
Double relativeSupport = count*1.0 /(record.size() - 1);
testList.add(relativeSupport.toString());
testList.add(conf.toString());
confItemset.add(testList);
/**
* 查找testList中的内容在lItemset的位置
* @param testList
* @param lItemset
* @return
*/
private static int findConf(List<String> testList,
List<List<String>> lItemset)
for(int i = 0; i < lItemset.size(); i++)
boolean notHaveTag = false;
for(int j = 0;j < testList.size();j++)
if(haveThisItem(testList.get(j),lItemset.get(i))==false)
notHaveTag = true;
break;
if(notHaveTag == false)
return i;
return -1;
/**
* 检验list中是否包含s
* @param s
* @param list
* @return boolean
*/
private static boolean haveThisItem(String s, List<String> list)
for(int i = 0; i<list.size() ;i++)
if(s.equals(list.get(i)))
return true;
return false;
/**
* 根据cItemset求得下一次的候选集合组,求出候选集合组中每一个集合的元素的个数比cItemset中的集合元素大1
* @param cItemset
* [[I1], [I2], [I5], [I4], [I3]]
* @return nextItemset
* [[I1, I2], [I1, I5], [I1, I4], [I1, I3], [I2, I5], [I2, I4], [I2, I3], [I5, I4], [I5, I3], [I4, I3]]
*/
private static List<List<String>> getNextCandidate(
List<List<String>> cItemset)
List<List<String>> nextItemset = new ArrayList<List<String>>();
for(int i =0;i<cItemset.size();i++)
List<String> tempList = new ArrayList<String>();
//tempList先存入一项
for(int k = 0;k<cItemset.get(i).size();k++)
tempList.add(cItemset.get(i).get(k));
//接下来每次添加下一项的一个元素
for(int h=i+1;h<cItemset.size();h++)
for(int j = 0;j<cItemset.get(h).size();j++)
tempList.add(cItemset.get(h).get(j));
//tempList的子集全部在cItemset中
if(isSubsetInC(tempList,cItemset))
List<String> copyValueHelpList = new ArrayList<String>();
for(int p =0;p<tempList.size();p++)
copyValueHelpList.add(tempList.get(p));
if(isHave(copyValueHelpList,nextItemset))
nextItemset.add(copyValueHelpList);
tempList.remove(tempList.size()-1);
return nextItemset;
/**
* 检验nextItemset中是否包含copyValueHelpList
* @param copyValueHelpList
* @param nextItemset
* @return boolean
*/
private static boolean isHave(List<String> copyValueHelpList,
List<List<String>> nextItemset)
for(int i =0;i<nextItemset.size();i++)
if(copyValueHelpList.equals(nextItemset.get(i)))
return false;
return true;
/**
* 检验tempList是不是cItemset的子集
* @param tempList
* @param cItemset
* @return boolean
*/
private static boolean isSubsetInC(List<String> tempList,
List<List<String>> cItemset)
boolean haveTag = false;
for(int i = 0;i<tempList.size();i++)
List<String> testList = new ArrayList<String>();
for(int j = 0;j<tempList.size();j++)
if(i != j )
testList.add(tempList.get(j)); //testList记录tempList中k-1级频繁集
for(int k = 0;k < cItemset.size();k++)
if(testList.equals(cItemset.get(k))) //子集存在于k-1频繁集中
haveTag = true;
break;
if(haveTag == false) //其中一个子集不再k-1频繁集中
return false;
return haveTag;
/** 返回候选集中满足最低支持度的集合
* @param cItemset
* [[I1, I2], [I1, I5], [I1, I4], [I1, I3], [I2, I5], [I2, I4], [I2, I3], [I5, I4], [I5, I3], [I4, I3]]
* @return supportedItemset
* [[I1, I2], [I1, I5], [I1, I3], [I2, I5], [I2, I4], [I2, I3], [I4, I3]]
*/
private static List<List<String>> getSupportedItemset(
List<List<String>> cItemset)
boolean end = true;
List<List<String>> supportedItemset = new ArrayList<List<String>>();
int k = 0;
for(int i = 0; i < cItemset.size(); i++)
int count = countFrequent(cItemset.get(i)); //统计记录数
//System.out.println(cItemset.get(i)+" " +count);
if(count >= MIN_SUPPORT*(record.size()-1)) //count值大于支持度与记录数的乘积,即满足支持度要求
if(cItemset.get(0).size() == 1)
dCountMap.put(k++, count);
else
dkCountMap.put(k++, count);
supportedItemset.add(cItemset.get(i));
end = false;
endTag = end;
return supportedItemset;
/**
* 统计数据库记录record中出现list中的集合的个数
* @param list
* @return 频繁项集 个数
*/
private static int countFrequent(List<String> list)
int count = 0;
for(int i = 1; i<record.size(); i++)
boolean notHaveThisList = false;
for(int k = 0;k<list.size();k++)
boolean thisRecordHave = false;
for(int j = 1;j<record.get(i).size();j++)
if(list.get(k).equals(record.get(i).get(j)))
thisRecordHave = true;
if(!thisRecordHave) // 扫描一遍记录表的一行,发现list.get(i)不在记录表的第j行中,即list不可能在j行中
notHaveThisList = true;
break;
if(notHaveThisList == false)
count++;
return count;
/**
* 根据数据库记录求出第一次候选集
* @return 返回一级候选集
*/
private static List<List<String>> findFirstCandidate()
List<List<String>> tableList = new ArrayList<List<String>>();
List<String> lineList = new ArrayList<String>();
int size = 0;
for(int i = 1; i < record.size(); i++)
for(int j = 1; j<record.get(i).size();j++)
if(lineList.isEmpty())
lineList.add(record.get(i).get(j));
else
boolean haveThisItem = false;
size = lineList.size();
for(int k = 0; k<size;k++)
if(lineList.get(k).equals(record.get(i).get(j)))
haveThisItem = true;
break;
if(haveThisItem == false)
lineList.add(record.get(i).get(j));
// [I1, I2, I5, I4, I3]
// System.out.println(lineList);
for(int i = 0; i<lineList.size();i++)
List<String> helpList = new ArrayList<String>();
helpList.add(lineList.get(i));
tableList.add(helpList);
// [[I1], [I2], [I5], [I4], [I3]]
// System.out.println(tableList);
return tableList;
测试数据读取类:
package com.datamine.apriori;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
/**
* 本程序用于读取矩阵型的记录数据,并转换为List<List<String>> 格式数据
* @author Administrator
*
*/
public class TxtReader
public List<List<String>> getRecord() throws Exception
List<List<String>> record = new ArrayList<List<String>>();
String encoding = "GBK"; //字符编码 解决中文乱码问题
String simple = new File("").getAbsolutePath() + File.separator + "data\\\\Apriori.txt";
File file = new File(simple);
if(file.isFile() && file.exists())
InputStreamReader read = new InputStreamReader(new FileInputStream(file),encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while((lineTxt = bufferedReader.readLine()) != null) //读一行文件
String[] lineString = lineTxt.split(" ");
List<String> lineList = new ArrayList<String>();
for(int i = 0; i < lineString.length ; i++) //处理矩阵中的T、F、YES、NO
if(lineString[i].endsWith("T") || lineString[i].endsWith("YES"))
lineList.add(record.get(0).get(i)); //保存 T或者YES对应的头(也就是商品)
else if (lineString[i].endsWith("F") || lineString[i].endsWith("NO"))
; //F、NO记录不保存 :当为F、NO时,说明没有购买响应的商品
else
lineList.add(lineString[i]);
record.add(lineList);
read.close();
else
System.out.println("找不到 指定的文件!");
return record;
程序入口类:
package com.datamine.apriori;
import java.util.List;
public class TestApriori
public static void main(String[] args) throws Exception
//输入数据
TxtReader reader = new TxtReader();
List<List<String>> record = reader.getRecord();
//最小支持度
double support = 0.2;
//最小置信度
double conf = 0.8;
Apriori apriori = new Apriori();
apriori.run(record, support, conf);
实验数据与结果:
实验数据:
TID I1 I2 I3 I4 I5
T100 T T F F T
T200 T T F F F
T300 F T F T F
T400 T T F T F
T500 T F T F F
T600 T T T F T
T700 T T T F F
T800 F T F F T
T900 F T T T F
T1000 F F T T F实验结果:
[[I1, I2], [I1, I5], [I1, I3], [I2, I5], [I2, I4], [I2, I3], [I4, I3]]
*******************频繁模式挖掘结果***********************
I1 -->I2 相对支持度:0.5 自信度:0.8333333333333334
I5 -->I2 相对支持度:0.3 自信度:1.0
[[I1, I2, I5], [I1, I2, I3]]
*******************频繁模式挖掘结果***********************
I1 I5 -->I2 相对支持度:0.2 自信度:1.0
[]
以上是关于关联规则—频繁项集Apriori算法的主要内容,如果未能解决你的问题,请参考以下文章