大数据Kudu:Kudu与Impala整合
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Kudu:Kudu与Impala整合相关的知识,希望对你有一定的参考价值。

文章目录
四、Impala SQL操作Kudu
Kudu与Impala整合
Impala是cloudera提供的一款高效率的sql查询工具,使用内存进行计算提供实时的SQL查询,impala强依赖于Hive 的MetaStore,直接使用hive的元数据,意味着impala元数据都存储在hive的MetaStore当中,并且impala兼容hive的绝大多数sql语法,具有实时,批处理,多并发等优点。
Kudu不支持标准SQL操作,可以将Kudu与Apache Impala紧密集成,impala天然就支持兼容kudu,允许开发人员使用Impala的SQL语法从Kudu的tablets 插入,查询,更新和删除数据,Kudu与Impala整合本质上就是为了可以使用Hive表来操作Kudu,主要支持SQL操作。
一、Kudu与Impala整合配置
先安装Impala后安装Kudu,Impala默认与Kudu没有形成依赖,这里需要首先在Impala中开启Kudu依赖支持,打开Impala->“配置”->“Kudu服务”:
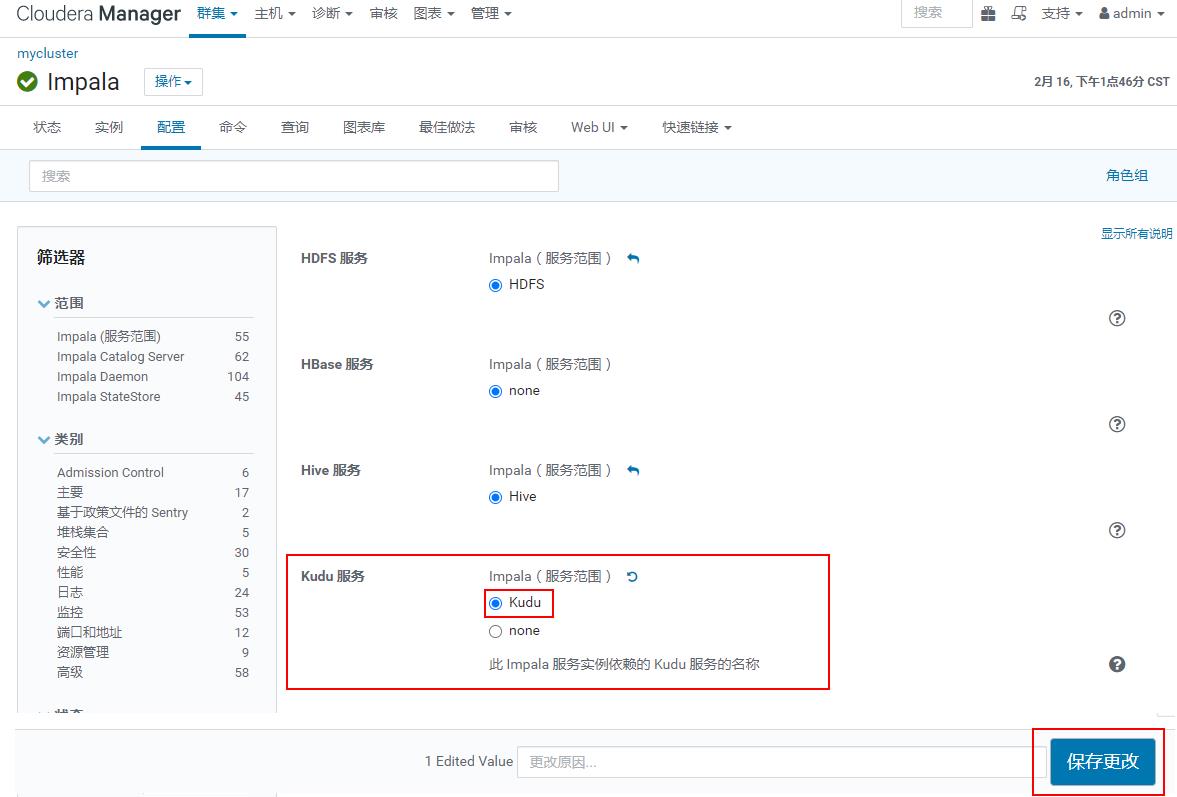
以上配置完成之后,重启Impala即可。
二、内部表
使用 Impala 创建新的 Kudu 表时,可以将表创建为内部表或外部表。内部表由Impala管理,当您从Impala中删除时,数据和表确实被删除。当您使用 Impala 创建新表时,通常是内部表。
使用impala创建内部表时,必须先列出主键列,主键默认就是不能为NULL。例如:创建内容表如下:
CREATE TABLE t_impala_kudu(
id int ,
name string,
age int,
primary key (id)
)
PARTITION BY HASH PARTITIONS 5
STORED AS KUDU
TBLPROPERTIES(
'kudu.master_address'='cm1:7051,cm2:7051'
)在impala-shell中执行以上命令,可以查看impala中对应的表创建成功:
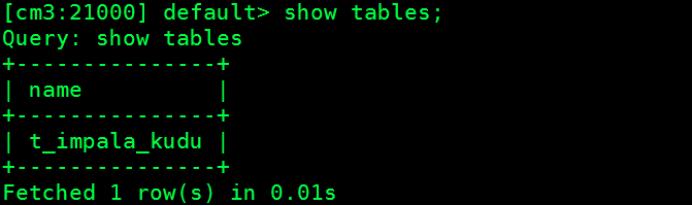
登录Kudu页面,也可以看到在Kudu中表创建成功。

内部表由impala管理,当创建表时,'kudu.master_address'指定Kudu集群,在ClouderaManager中impala配置了支持Kudu,也可以不指定;不能设置属性'kudu.table_name'指定Kudu中表的名字,表名默认就是“impala::xxx.xx”,当删除表时,对应的表在impala中和kudu中都会删除。
注意:Kudu不支持Impala建表关键字PARTITIONED、LOCATION、ROW FORMAT。
三、外部表
外部表(由CREATE EXTERNAL TABLE创建)不受 Impala 管理,并且删除此表不会将表从其源位置(此处为 Kudu)丢弃。相反,它只会去除Impala和Kudu之间的映射。这是 Kudu 提供的用于将现有表映射到 Impala 的语法。
使用Java api 在Kudu中创建表personInfo,创建好之后,可以通过Kudu WebUI中发现对应的在Impala中创建外表映射Kudu表的语句:
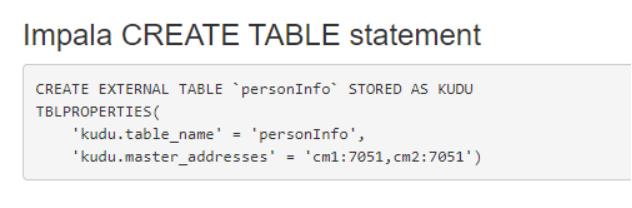
在Impala中执行创建Impala外表的语句,可以在Impala中创建的表名称与Kudu中表的名称不一致,在Impala-shell中执行如下创建外表语句,将personInfo映射到Impala:
CREATE EXTERNAL TABLE `t_kudu_map` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'personInfo',
'kudu.master_addresses' = 'cm1:7051,cm2:7051'
)执行完成之后,可以查看Impala中的表如下:
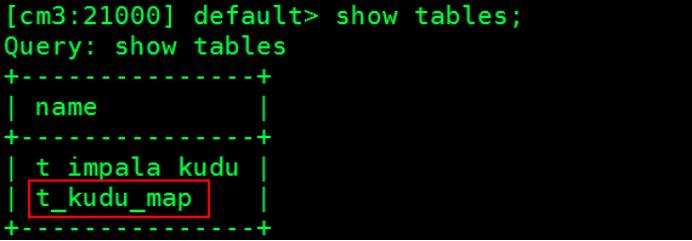
以上就是在Impala中创建的外部表,外部表映射Kudu中的表,当删除Impala中的t_kudu_map表时,在Impala中表被删除,在Kudu中表personInfo不会被删除。生产环境中建议使用外部表。
四、Impala SQL操作Kudu
在Impala中创建内部表 t_test,存储在Kudu中:
CREATE TABLE t_test(
id int ,
name string,
age int,
primary key (id)
)
PARTITION BY HASH PARTITIONS 5
STORED AS KUDU
TBLPROPERTIES(
'kudu.master_address'='cm1:7051,cm2:7051'
)- 向表中插入数据
#插入一条数据
[cm3:21000] default> insert into t_test (id,name,age) values (1,"zhangsan",18)
#查询数据
[cm3:21000] default> select * from t_test;
+----+----------+-----+
| id | name | age |
+----+----------+-----+
| 1 | zhangsan | 18 |
+----+----------+-----+
#插入多条数据
[cm3:21000] default> insert into t_test (id,name,age) values (2,"lisi",19),(3,"王五",20);
#查询结果
[cm3:21000] default> select * from t_test;
+----+----------+-----+
| id | name | age |
+----+----------+-----+
| 2 | lisi | 19 |
| 1 | zhangsan | 18 |
| 3 | 王五 | 20 |
+----+----------+-----+以上表使用Java api 查询Kudu中的数据也一样可以查询出来。
- DML-向表中批量插入数据
#在Impala中再创建一个表 t_test2表,与表t_test结构一样
CREATE TABLE t_test2(
id int ,
name string,
age int,
primary key (id)
)
PARTITION BY HASH PARTITIONS 5
STORED AS KUDU
TBLPROPERTIES(
'kudu.master_address'='cm1:7051,cm2:7051'
)
#向表 t_test2中插入以下数据
[cm3:21000] default> insert into t_test2 (id,name,age) values (10,"maliu",100),(20,"tianqi",200);
#向表t_test中批量插入数据
[cm3:21000] default> insert into t_test select * from t_test2;
#查询表t_test中的数据:
+----+----------+-----+
| id | name | age |
+----+----------+-----+
| 10 | maliu | 100 |
| 2 | lisi | 19 |
| 20 | tianqi | 200 |
| 3 | 王五 | 20 |
| 1 | zhangsan | 18 |
+----+----------+-----+- DML-更新数据
#更新表t_test中的id为1的age为180
[cm3:21000] default> update t_test set age = 180 where id =1;
#查询t_test中id为1的数据更新结果
[cm3:21000] default> select * from t_test where id = 1;
+----+----------+-----+
| id | name | age |
+----+----------+-----+
| 1 | zhangsan | 180 |
+----+----------+-----+- DML-删除数据
#删除表中id 为20的数据
[cm3:21000] default> delete from t_test where id = 20;
#查询t_test表中的结果
[cm3:21000] default> select * from t_test;
+----+----------+-----+
| id | name | age |
+----+----------+-----+
| 2 | lisi | 19 |
| 1 | zhangsan | 180 |
| 3 | 王五 | 20 |
| 10 | maliu | 100 |
+----+----------+-----+- DDL-表重命名
#将表t_test重命名为t_test1
[cm3:21000] default> alter table t_test rename to t_test1;
#查看impala中的表信息
[cm3:21000] default> show tables;
+---------------+
| name |
+---------------+
| t_impala_kudu |
| t_test1 |
| t_test2 |
+---------------+- DDL-修改Impala映射底层的Kudu表
#在Impala中创建外表 t_kudu_map 映射Kudu表 personInfo
CREATE EXTERNAL TABLE `t_kudu_map` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'personInfo',
'kudu.master_addresses' = 'cm1:7051,cm2:7051'
)
#在Kudu中使用Java api 创建一张表 personInfo2,结构与表personInfo一样即可。
#修改Impala 外表 t_kudu_map 底层映射的personInfo为personInfo1表
[cm3:21000] default> alter table t_kudu_map set TBLPROPERTIES('kudu.table_name'='personInfo1');
注意:使用 “show create table t_kudu_map”查看表 t_kudu_map的建表语句,发现底层映射的Kudu表变成了 personInfo1。- DDL-将内部表转换成外部表
#将表 t_test1内部表转换成外部表
[cm3:21000] default> alter table t_test1 set tblproperties('EXTERNAL'='true');- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据Kudu:Kudu与Impala整合的主要内容,如果未能解决你的问题,请参考以下文章
使用SparkSQL迁移oracle数据到impala创建的kudu表中,出现Primary key column riskcode is not set错误