使用SparkSQL迁移oracle数据到impala创建的kudu表中,出现Primary key column riskcode is not set错误
Posted ITboy-Bear
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用SparkSQL迁移oracle数据到impala创建的kudu表中,出现Primary key column riskcode is not set错误相关的知识,希望对你有一定的参考价值。
前段时间公司业务需求,需要把oracle中的数据迁移到数据仓库中(kudu整合的hive),为了使用kudu方便,kudu的日常操作通过impala来完成。由于第一次整合sparkSQL与kudu,所以打算通过一些demo记录一下遇到的问题。
oracle数据导入到kudu中,代码如下:
object OracleToKudu
def main(args: Array[String]): Unit =
val spark = SparkSession.builder.appName("test").master("local").getOrCreate
val tableName = "impala::default.LMRISKDEF"
val sql = "SELECT RISKCODE,RISKNAME,SALECHNL,RISKTYPE FROM LMRISKDEF"
//读取oracle数据
val data = spark.read.format("jdbc")
.option("driver", "oracle.jdbc.OracleDriver")
.option("url", "jdbc:oracle:thin:@x.x.x.x:1521:TESTDB")
.option("user", "rdi")
.option("password", "rdi")
.option("dbtable", "(" + sql + ") temp")
.load
//写入到kudu中
data.write.mode(SaveMode.Append)
.format("org.apache.kudu.spark.kudu")
.option("kudu.master", "x.x.x.x:7051,x.x.x.x:7051")
.option("kudu.table", tableName)
.save()
便出现了:org.apache.kudu.client.NonRecoverableException: Primary key column riskcode is not set
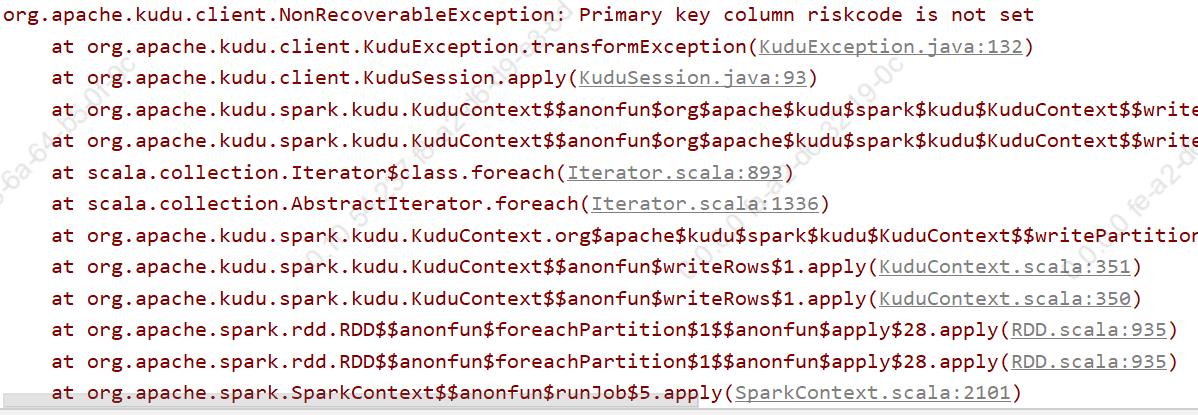
分析错误原因是:Primary key column riskcode is not set。可无论是oracle中的LMRISKDEF表还是通过impala创建的LMRISKDEF表都是具有主键的(还特意将字段在select语句中全部列出,),查询语句字段顺序与kudu表顺序也一致(impala建表主键必须在前),那就可能是查询出的字段与目的字段无法匹配。
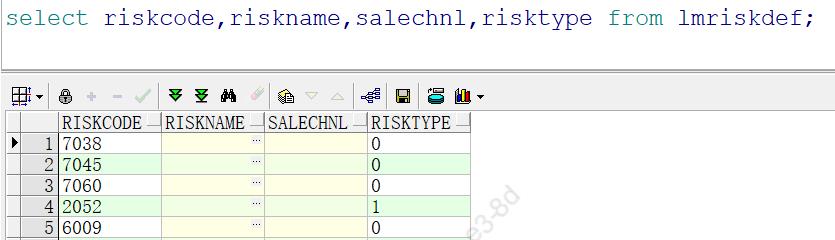
查看输出输入对象的字段,如下:
查询语句在oracle中的查询结果,可以看出无论字段大小写,输出结果的字段均是大写。
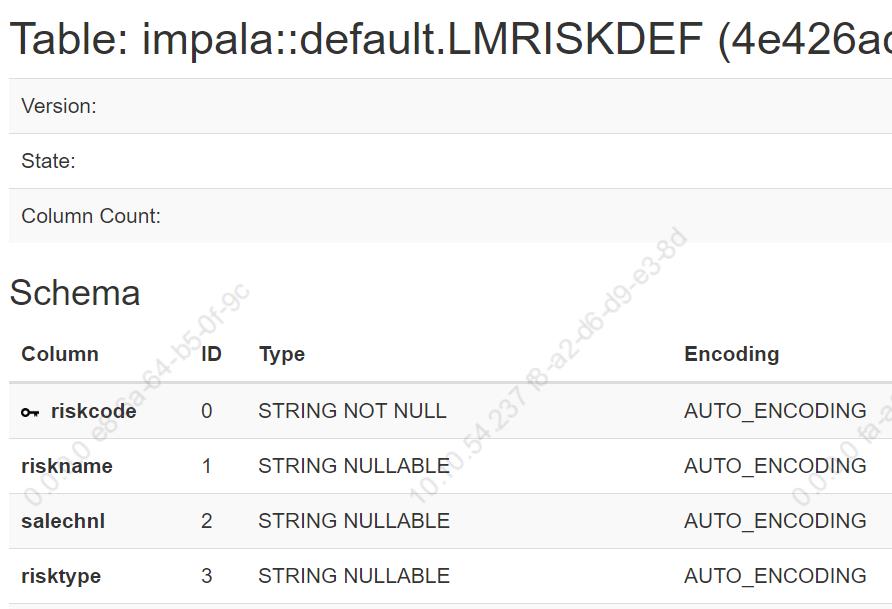
如下是查看kudu中的建表信息,可发现字段类型均是小写。(单纯的kudu建表,字段可大写可小写,但表无法使用impala操作,在后续的使用中不便; 而通过impala创建的kudu表,无论建表语句大小写,结果都是小写,目前还没有找到解决办法)
修改后的代码:
object OracleToKudu
def main(args: Array[String]): Unit =
val spark = SparkSession.builder.appName("test").master("local").getOrCreate
val tableName = "impala::default.LMRISKDEF"
val sql = "SELECT RISKCODE,RISKNAME,SALECHNL,RISKTYPE FROM LMRISKDEF"
val schema = StructType(
StructField("riskcode", StringType, false) ::
StructField("riskname", StringType, true) ::
StructField("salechnl", StringType, true) ::
StructField("risktype", StringType, true) :: Nil)
val fields = new util.ArrayList[StructField]()
fields.add(DataTypes.createStructField("riskcode", DataTypes.StringType, false))
fields.add(DataTypes.createStructField("riskname", DataTypes.StringType, true))
fields.add(DataTypes.createStructField("salechnl", DataTypes.StringType, true))
fields.add(DataTypes.createStructField("risktype", DataTypes.StringType, true))
val schema2 = DataTypes.createStructType(fields);
//读取oracle数据
val data = spark.read.format("jdbc")
.option("driver", "oracle.jdbc.OracleDriver")
.option("url", "jdbc:oracle:thin:@x.x.x.x:1521:TESTDB")
.option("user", "rdi")
.option("password", "rdi")
.option("dbtable", "(" + sql + ") temp")
.load
//写入到kudu中
spark
.createDataFrame(data.rdd, schema)//schema||schema2都可以只是两种方式
.write.mode(SaveMode.Append)
.format("org.apache.kudu.spark.kudu")
.option("kudu.master", "x.x.x.x:7051,x.x.x.x:7051")
.option("kudu.table", tableName)
.save()
建议以后再进行数据迁移过程中还是指定字段和类型(自己图简便反而把自己坑了)
以上是关于使用SparkSQL迁移oracle数据到impala创建的kudu表中,出现Primary key column riskcode is not set错误的主要内容,如果未能解决你的问题,请参考以下文章