菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition
Posted 猫头丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition相关的知识,希望对你有一定的参考价值。
【菜鸡读论文】Margin-Mix: Semi-Supervised Learning for Face Expression Recognition
感觉最近的每天都在见证历史,上海现在也开始全面放开了,很多高校都已经开始遣返了。小伙伴们都回到家了吗?

上周周末太懒了,就没有更新论文,今天周一来补上。
 这篇文章讲的就是基于本监督方法来学习表情识别。我们先总体概括一下:我们希望深度学习模型具有很好的嵌入表示能力,因此我们训练一个WideResNet模型,其嵌入层后直接连接全连接层进行分类。
这篇文章讲的就是基于本监督方法来学习表情识别。我们先总体概括一下:我们希望深度学习模型具有很好的嵌入表示能力,因此我们训练一个WideResNet模型,其嵌入层后直接连接全连接层进行分类。
- 现在我们有已经打好标签的图片和没有打好标签的图片,我们将打好标签的图片输入模型得到关于图片的嵌入表示,接下来借鉴K-means聚类的思想,按照不同的图片类别计算其类心。
- 下面我们将没有标记的图片输入到模型中得到嵌入表示,通过公式计算应该将其分到哪个类中。
- 接下来我们计算损失,包括模型权重的L2正则和一个希望各个嵌入表示离自己的类心近,离其它类心远的约束,用该约束来优化模型的学习。
确定类心
类心的计算可以看做是嵌入向量取平均。我们希望样本嵌入在训练过程中向特征空间(嵌入)中相应的类中心移动,因此引入中心损失,其定义如下:
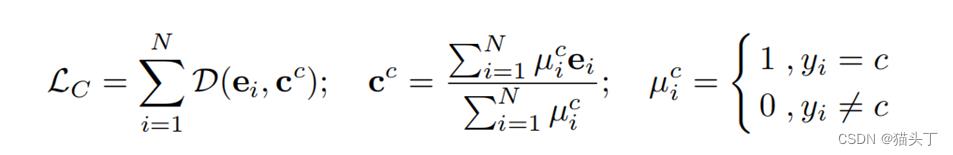 但是该损失有局限性,可能会出现多个类心重叠的情况,且可能会使得模型学习到一些偏差,而我们希望某个类中的样本嵌入离自己的类心近,离其他类心远,因此我们提出一种归一化嵌入,通过支持对归属类质心的小距离和对其他类质心的大距离来修改损失。
但是该损失有局限性,可能会出现多个类心重叠的情况,且可能会使得模型学习到一些偏差,而我们希望某个类中的样本嵌入离自己的类心近,离其他类心远,因此我们提出一种归一化嵌入,通过支持对归属类质心的小距离和对其他类质心的大距离来修改损失。
定义如下:
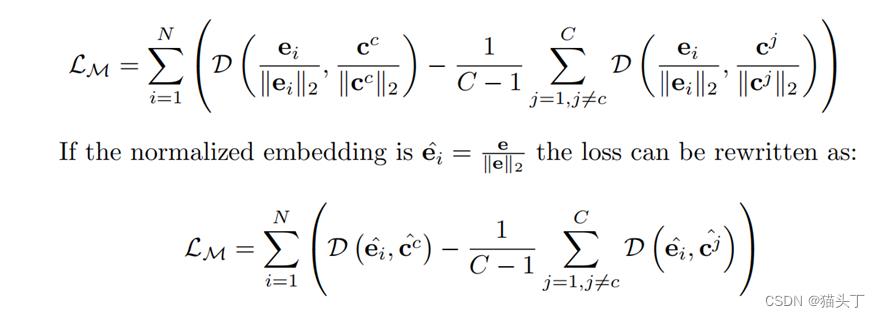
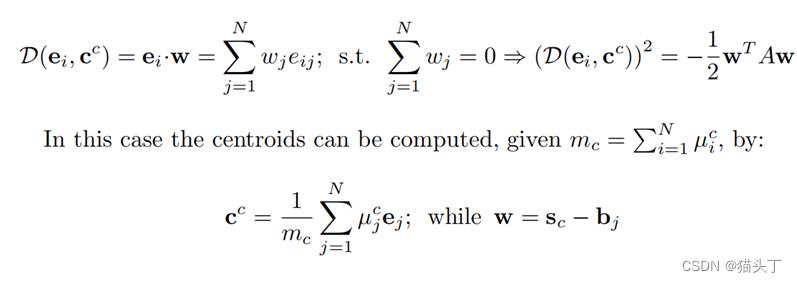
未标记图片打标签(Self-labeling)
采用模糊C均值算法的方法
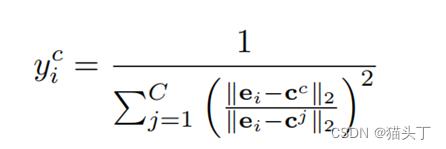

Augmentative Processing
为了防止网络记忆数据,我们正则化训练权重衰减(即惩罚模型参数的L2范数)。此外,在上一阶段,还提出几种提高效率的技术
Classical data augmentation
数据增强就是传统的数据增强
Label guessing
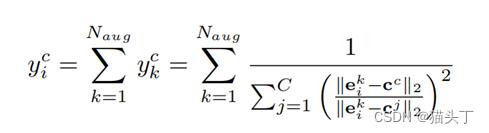
Sharpening
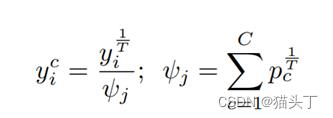
MixUP
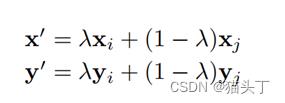
完整的算法流程如下:

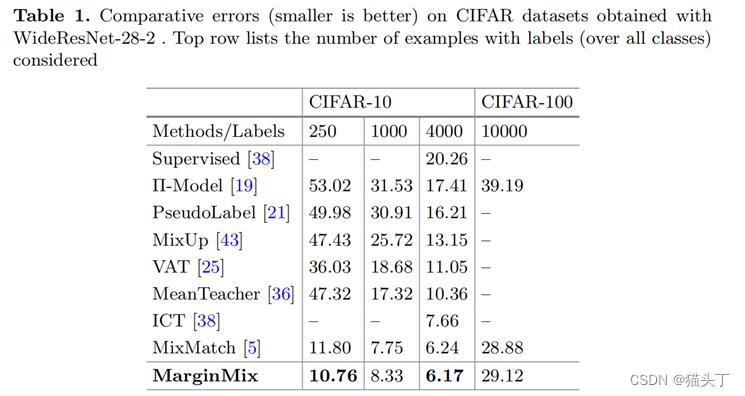
下面是一些结果展示
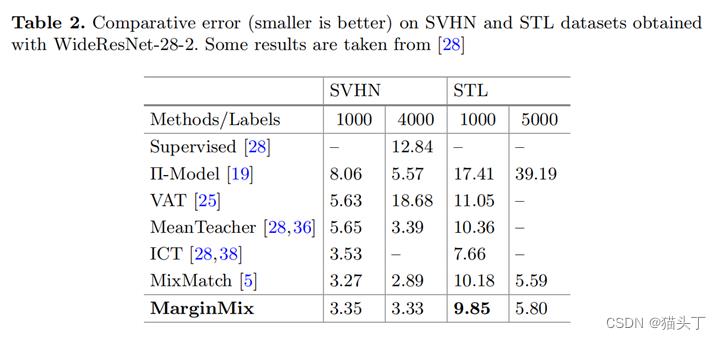
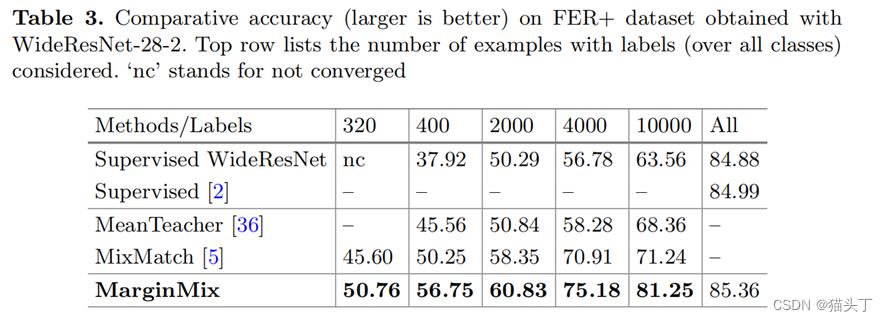
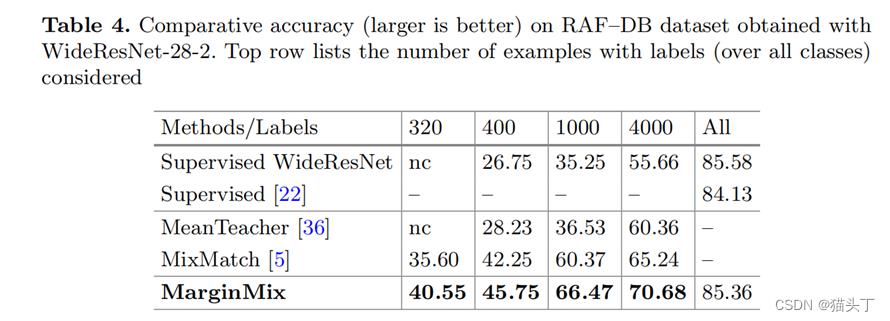
以上是关于菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition的主要内容,如果未能解决你的问题,请参考以下文章
菜鸡读论文Former-DFER: Dynamic Facial Expression Recognition Transformer
菜鸡读论文Dive into Ambiguity: Latent Distribution Mining and Pairwise Uncertainty Estimation for Facia
菜鸡读论文Face2Exp: Combating Data Biases for Facial Expression Recognition
菜鸡读论文Face2Exp: Combating Data Biases for Facial Expression Recognition
菜鸡读论文AU-assisted Graph Attention Convolutional Network for Micro-Expression Recognition