菜鸡读论文Former-DFER: Dynamic Facial Expression Recognition Transformer
Posted 猫头丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了菜鸡读论文Former-DFER: Dynamic Facial Expression Recognition Transformer相关的知识,希望对你有一定的参考价值。
Former-DFER: Dynamic Facial Expression Recognition Transformer
哈喽,大家好呀!本菜鸡又来读论文啦!先来个酷炫小叮当作为我们的开场!
粉红爱心泡泡有没有击中你的少女心!看到这么可爱的小叮当陪我们一起读论文,是不是感觉瞬间充满动力了呢!突然想到下次确实可以搞一个漂亮妹妹的动图,让漂亮妹妹陪我们一起读论文,不知道大家有没有什么好建议呢!
 不知不觉!今天竟然是冬至了!感觉时间真的过得好快,在我们老家,冬至应该吃饺子,不过我也是突然想起来这回事,因为我早上起的太晚了,竟然睡到快11点才醒。其实,我最近有点失眠,就很害怕早上起来看到手机时间才六点或七点这样,因为这样的话,我就要接着努力去睡觉,没想到今天早上起来竟然已经快11点了,感觉像是另一种惊吓。
不知不觉!今天竟然是冬至了!感觉时间真的过得好快,在我们老家,冬至应该吃饺子,不过我也是突然想起来这回事,因为我早上起的太晚了,竟然睡到快11点才醒。其实,我最近有点失眠,就很害怕早上起来看到手机时间才六点或七点这样,因为这样的话,我就要接着努力去睡觉,没想到今天早上起来竟然已经快11点了,感觉像是另一种惊吓。
昨天晚上看了一部电影《伊甸湖》,后劲儿还挺大的,差不多八点看完,结果一直难受到十点多,真的太让人难受了。如果没有看过这部电影的小朋友可以去看一看,真的挺不一样的,我是第一次看这种题材,后来发现竟然还是真实故事改变,更难受了。好像还有一些同类型的电影,不过我应该要再缓缓才能接着看别的电影了。
话不多说,让我们在小叮当的陪伴下,来看今天的论文:
 在现实生活中的表情序列识别存在一些挑战,比如遮挡、非额叶姿势和头部运动。如下图:
在现实生活中的表情序列识别存在一些挑战,比如遮挡、非额叶姿势和头部运动。如下图:

基于这些问题,作者提出dynamic facial expression recognition transformer(Former-DFER)。Transformer的自注意力机制可以学习到区域面部特征的相关性以及时间上面部特征之间的相关性,具有处理以上挑战的能力。(哦对了!这篇论文还有github代码,我也去跑了一下,可以跑出来,大家放心去试)
下面,让我们来看一下这个模型的架构图,可以看到这个模型包括两个部分(绿色和蓝色)
1、convolutional spatial transformer(CS-former)
CS-former由五个卷积块和N个空间编码器组成,旨在引导网络从空间角度学习遮挡和姿态稳健的面部特征。
2、temporal transformer(T-former)
T-former由M个时间编码器组成,旨在允许网络从时间的角度学习上下文的面部特征。
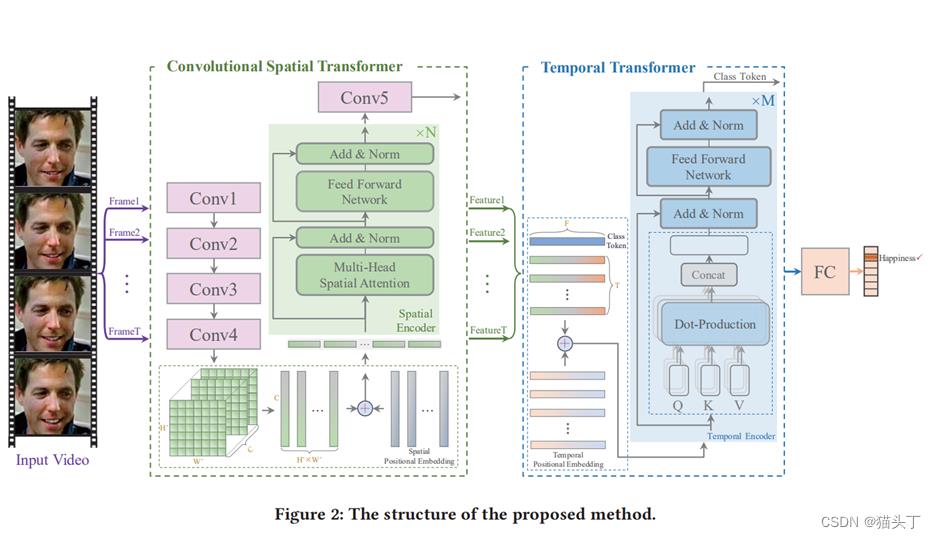
接下来我们详细来看这两个模块的细节
CS-Former
CS-former由五个卷积块和N个Spatial Encoder组成

输入:首先把视频序列分成U段,接下来从每段序列中间取V帧,最终共输入U*V帧
输入帧首先通过四个卷积块来提取特征映射图,接下来将一个通道数为C的特征映射图组在通道维度上拉成一组序列,如上图所示,加上位置嵌入后,送入编码器,自注意机制的计算如下所示:

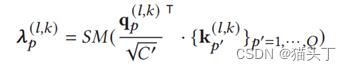
可以将四个卷积块的作用看做是提取局部特征,Spatial Encoder用于提取全局特征,可以看到从Spatial Encoder出来之后又连上一个卷积块,该卷积块的作用相当于对特征进行提炼。
T-Former
每一帧经过CS-Former都会得到一个特征表示,一组帧经过CS-Former会得到一个序列,为了最后的分类,我们增加一个Class Token,如图所示。接下来,加上一个Temporal Positional Embedding来表示时间顺序。
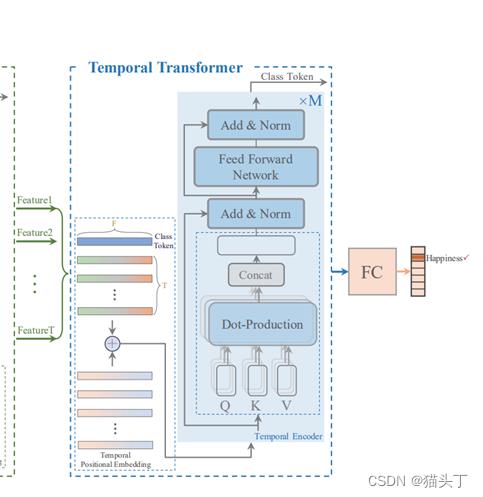 Temporal Encoder的计算流程,如下所示:
Temporal Encoder的计算流程,如下所示:


整个模型就是这样,接下来就是实验部分了,放上一些实验结果图:


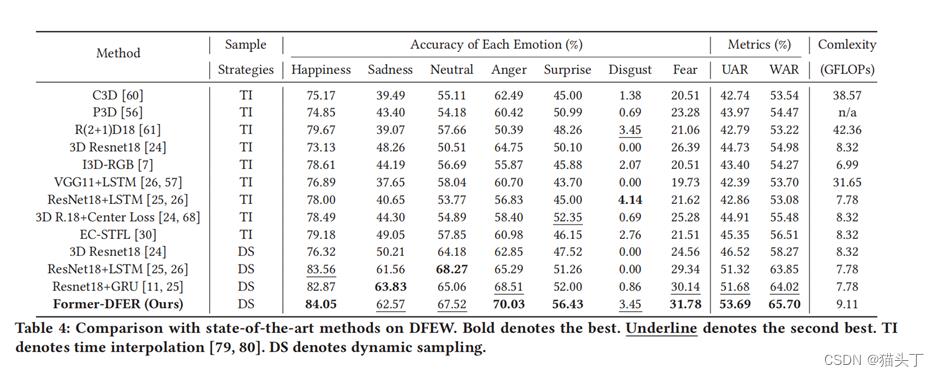

以上是关于菜鸡读论文Former-DFER: Dynamic Facial Expression Recognition Transformer的主要内容,如果未能解决你的问题,请参考以下文章
菜鸡读论文Face2Exp: Combating Data Biases for Facial Expression Recognition
菜鸡读论文Face2Exp: Combating Data Biases for Facial Expression Recognition
菜鸡读论文AU-assisted Graph Attention Convolutional Network for Micro-Expression Recognition
菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition
菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition