如何使用ABBYY软件校正不能完全识别的表格
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用ABBYY软件校正不能完全识别的表格相关的知识,希望对你有一定的参考价值。
参考技术A 尽管ABBYY FineReader PDF 15是一个识别度极高的OCR文字识别工具,但它在识别图片、PDF文件的时候还是会存在一定的遗漏和错误。其中,在识别表格的时候,有某些表格并不能完全识别出来。对于这种情况,很多小伙伴把识别的文件转换为Word文件后,再在Word软件中修改,这使工作量变得巨大。实际上,在ABBYY的OCR编辑器中,通过调整对表格区域的识别,可以使表格的识别度达致百分百。下面我通过一个实际的案例,讲述如何调整不能完全识别的表格。
首先,使用ABBYY FineReader PDF 15软件打开一个通过扫描纸质表格生成的PDF文件。由于纸质表格的清晰度并不高,使到扫描形成的PDF文件的效果也不是很好,这会令ABBYY的OCR编辑器识别发生错误,这在实际使用中普遍发生的问题。
点击“识别”按钮,选择“识别并在OCR编辑器中验证”。
待识别结束后,在OCR编辑器界面中,检查右侧副本文件,发现表格并没有完全识别出来。例如:“登记号”左侧少了一条竖线;“非户籍学生……”缺失了左右两条竖线以及下面“签名”部分的表格都没有识别出来。此时注意,“保存格式”一定要选择“精确到副本”。
在左侧源文件上,删除处于表格内的文本框,在工具栏上点击“制表格区域”,通过调整、添加表格区域,重新对表格设置新的绘制表格区域。在设置的过程中,注意竖线对齐和横线重叠,避免识别后的表格边框出现不对齐以及粗细不一致的问题。
在源文件上重新绘制表格区域后,点击“识别页面”,对源文件进行重新识别。识别结束后,再次检查表格,发现副本的表格与原表格一致。
然后点击“验证”按钮,对识别错误的内容进行修改。错误修正后,源文件整个识别过程就完成了。
最后,把识别的文件保存为Word文档,实现了把扫描得到的表格转变为Word格式的电子文件。
总结
由于原纸质文件的清晰度以及扫描精度,都会导致形成的PDF文件里的内容模糊,从而令ABBYY FineReader PDF 15软件的OCR文字识别软件不能完全识别出表格的线条,使到表格产生缺失。但通过重新绘制表格区域后,再次识别基本就能获得完整的表格。
磁盘此卷不包含可识别的文件系统资料如何寻回
D盘打不开此卷不包含可识别的文件系统,是因为这个I盘的文件系统内部结构损坏导致的。要恢复里面的数据就必须要注意,这个盘不能格式化,否则数据会进一步损坏。具体的恢复方法看正文
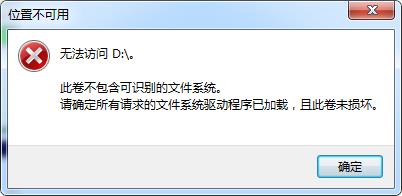
工具/软件:AuroraDataRecovery
步骤1:先下载并解压软件打开后,直接双击需要恢复的分区,接着右击软件图标选择《以管理员身份运行》
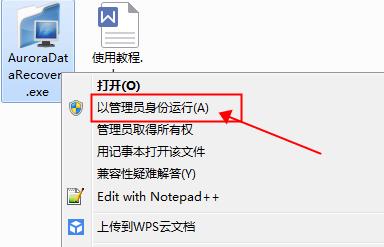
步骤2:软件打开后,直接双击需要恢复数据的盘

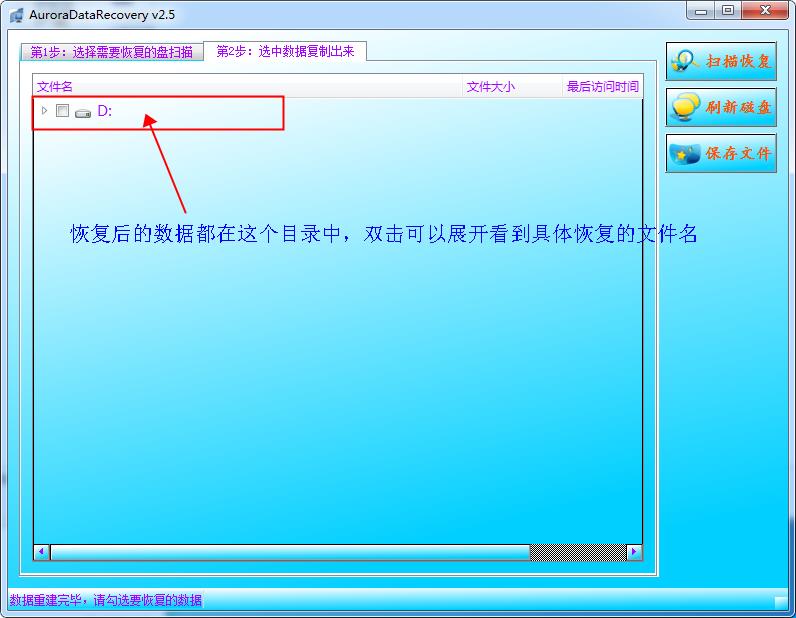
步骤3:软件找到文件后,会放到与要恢复盘卷标名相同的目录中
步骤4:勾选所有需要恢复的数据,接着点右上角的保存,《文件保存》按钮,将勾选的文件拷贝出来。
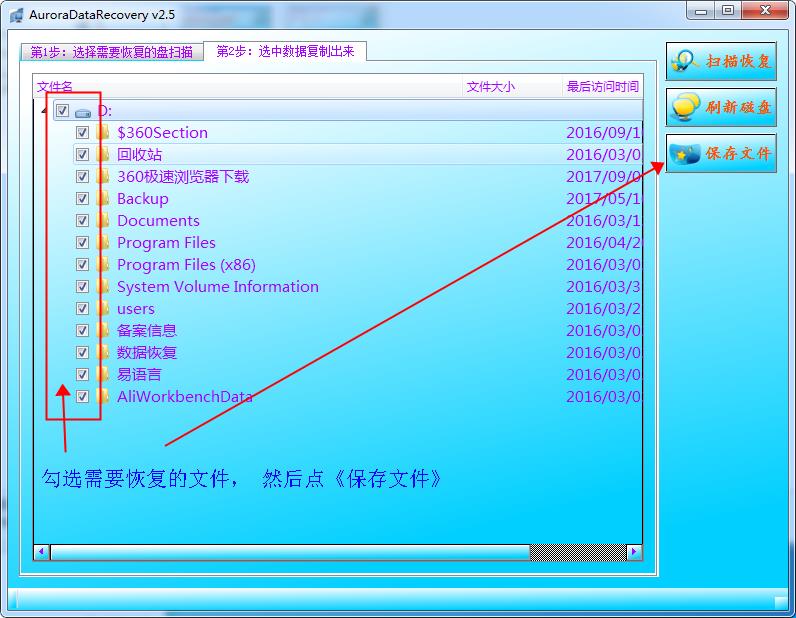
步骤5:等软件将数据COPY完成就完毕了 。
注意事项1:此卷不包含可识别的文件系统恢复出来的数据需要暂时保存到其它盘里。
注意事项2:想要恢复磁盘此卷不包含可识别的文件系统需要注意,一定要先恢复数据再格式化。
以上是关于如何使用ABBYY软件校正不能完全识别的表格的主要内容,如果未能解决你的问题,请参考以下文章
如何使用自定义表格视图单元格中识别的点击手势从 UILabel 呈现视图控制器?