大数据分析工具详尽介绍&数据分析算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据分析工具详尽介绍&数据分析算法相关的知识,希望对你有一定的参考价值。
大数据分析工具详尽介绍&数据分析算法1、 HadoopHadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高
参考技术A 大数据分析工具详尽介绍&数据分析算法1、 Hadoop
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是 Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理 PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
⒈高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
⒉高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
⒊高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
⒋高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
Hadoop带有用 Java 语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
2、 HPCC
HPCC,High Performance Computing and Communications(高性能计算与通信)的缩写。1993年,由美国科学、工程、技术联邦协调理事会向国会提交了“重大挑战项目:高性能计算与 通信”的报告,也就是被称为HPCC计划的报告,即美国总统科学战略项目,其目的是通过加强研究与开发解决一批重要的科学与技术挑战问题。HPCC是美国 实施信息高速公路而上实施的计划,该计划的实施将耗资百亿美元,其主要目标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络传输性能,开发千兆 比特网络技术,扩展研究和教育机构及网络连接能力。
该项目主要由五部分组成:
1、高性能计算机系统(HPCS),内容包括今后几代计算机系统的研究、系统设计工具、先进的典型系统及原有系统的评价等;
2、先进软件技术与算法(ASTA),内容有巨大挑战问题的软件支撑、新算法设计、软件分支与工具、计算计算及高性能计算研究中心等;
3、国家科研与教育网格(NREN),内容有中接站及10亿位级传输的研究与开发;
4、基本研究与人类资源(BRHR),内容有基础研究、培训、教育及课程教材,被设计通过奖励调查者-开始的,长期 的调查在可升级的高性能计算中来增加创新意识流,通过提高教育和高性能的计算训练和通信来加大熟练的和训练有素的人员的联营,和来提供必需的基础架构来支 持这些调查和研究活动;
5、信息基础结构技术和应用(IITA ),目的在于保证美国在先进信息技术开发方面的领先地位。
3、 Storm
Storm是自由的开源软件,一个分布式的、容错的实时计算系统。Storm可以非常可靠的处理庞大的数据流,用于处理Hadoop的批量数据。Storm很简单,支持许多种编程语言,使用起来非常有趣。Storm由Twitter开源而来,其它知名的应用企业包括Groupon、淘宝、支付宝、阿里巴巴、乐元素、Admaster等等。
Storm有许多应用领域:实时分析、在线机器学习、不停顿的计算、分布式RPC(远过程调用协议,一种通过网络从远程计算机程序上请求服务)、 ETL(Extraction-Transformation-Loading的缩写,即数据抽取、转换和加载)等等。Storm的处理速度惊人:经测 试,每个节点每秒钟可以处理100万个数据元组。Storm是可扩展、容错,很容易设置和操作。
4、 Apache Drill
为了帮助企业用户寻找更为有效、加快Hadoop数据查询的方法,Apache软件基金会近日发起了一项名为“Drill”的开源项目。Apache Drill 实现了 Google’s Dremel.
据Hadoop厂商MapR Technologies公司产品经理Tomer Shiran介绍,“Drill”已经作为Apache孵化器项目来运作,将面向全球软件工程师持续推广。
该项目将会创建出开源版本的谷歌Dremel Hadoop工具(谷歌使用该工具来为Hadoop数据分析工具的互联网应用提速)。而“Drill”将有助于Hadoop用户实现更快查询海量数据集的目的。
“Drill”项目其实也是从谷歌的Dremel项目中获得灵感:该项目帮助谷歌实现海量数据集的分析处理,包括分析抓取Web文档、跟踪安装在android Market上的应用程序数据、分析垃圾邮件、分析谷歌分布式构建系统上的测试结果等等。
通过开发“Drill”Apache开源项目,组织机构将有望建立Drill所属的API接口和灵活强大的体系架构,从而帮助支持广泛的数据源、数据格式和查询语言。
5、 RapidMiner
RapidMiner是世界领先的数据挖掘解决方案,在一个非常大的程度上有着先进技术。它数据挖掘任务涉及范围广泛,包括各种数据艺术,能简化数据挖掘过程的设计和评价。
功能和特点
免费提供数据挖掘技术和库
100%用Java代码(可运行在操作系统)
数据挖掘过程简单,强大和直观
内部XML保证了标准化的格式来表示交换数据挖掘过程
可以用简单脚本语言自动进行大规模进程
多层次的数据视图,确保有效和透明的数据
图形用户界面的互动原型
命令行(批处理模式)自动大规模应用
Java API(应用编程接口)
简单的插件和推广机制
强大的可视化引擎,许多尖端的高维数据的可视化建模
400多个数据挖掘运营商支持
耶鲁大学已成功地应用在许多不同的应用领域,包括文本挖掘,多媒体挖掘,功能设计,数据流挖掘,集成开发的方法和分布式数据挖掘。
6、 Pentaho BI
Pentaho BI 平台不同于传统的BI 产品,它是一个以流程为中心的,面向解决方案(Solution)的框架。其目的在于将一系列企业级BI产品、开源软件、API等等组件集成起来,方便商务智能应用的开发。它的出现,使得一系列的面向商务智能的独立产品如Jfree、Quartz等等,能够集成在一起,构成一项项复杂的、完整的商务智能解决方案。
Pentaho BI 平台,Pentaho Open BI 套件的核心架构和基础,是以流程为中心的,因为其中枢控制器是一个工作流引擎。工作流引擎使用流程定义来定义在BI 平台上执行的商业智能流程。流程可以很容易的被定制,也可以添加新的流程。BI 平台包含组件和报表,用以分析这些流程的性能。目前,Pentaho的主要组成元素包括报表生成、分析、数据挖掘和工作流管理等等。这些组件通过 J2EE、WebService、SOAP、HTTP、Java、javascript、Portals等技术集成到Pentaho平台中来。 Pentaho的发行,主要以Pentaho SDK的形式进行。
Pentaho SDK共包含五个部分:Pentaho平台、Pentaho示例数据库、可独立运行的Pentaho平台、Pentaho解决方案示例和一个预先配制好的 Pentaho网络服务器。其中Pentaho平台是Pentaho平台最主要的部分,囊括了Pentaho平台源代码的主体;Pentaho数据库为 Pentaho平台的正常运行提供的数据服务,包括配置信息、Solution相关的信息等等,对于Pentaho平台来说它不是必须的,通过配置是可以用其它数据库服务取代的;可独立运行的Pentaho平台是Pentaho平台的独立运行模式的示例,它演示了如何使Pentaho平台在没有应用服务器支持的情况下独立运行;
Pentaho解决方案示例是一个Eclipse工程,用来演示如何为Pentaho平台开发相关的商业智能解决方案。
Pentaho BI 平台构建于服务器,引擎和组件的基础之上。这些提供了系统的J2EE 服务器,安全,portal,工作流,规则引擎,图表,协作,内容管理,数据集成,分析和建模功能。这些组件的大部分是基于标准的,可使用其他产品替换之。
7、 SAS Enterprise Miner
§ 支持整个数据挖掘过程的完备工具集
§ 易用的图形界面,适合不同类型的用户快速建模
§ 强大的模型管理和评估功能
§ 快速便捷的模型发布机制, 促进业务闭环形成
数据分析算法
大数据分析主要依靠机器学习和大规模计算。机器学习包括监督学习、非监督学习、强化学习等,而监督学习又包括分类学习、回归学习、排序学习、匹配学习等(见图1)。分类是最常见的机器学习应用问题,比如垃圾邮件过滤、人脸检测、用户画像、文本情感分析、网页归类等,本质上都是分类问题。分类学习也是机器学习领域,研究最彻底、使用最广泛的一个分支。
最近、Fernández-Delgado等人在JMLR(Journal of Machine Learning Research,机器学习顶级期刊)杂志发表了一篇有趣的论文。他们让179种不同的分类学习方法(分类学习算法)在UCI 121个数据集上进行了“大比武”(UCI是机器学习公用数据集,每个数据集的规模都不大)。结果发现Random Forest(随机森林)和SVM(支持向量机)名列第一、第二名,但两者差异不大。在84.3%的数据上、Random Forest压倒了其它90%的方法。也就是说,在大多数情况下,只用Random Forest 或 SVM事情就搞定了。
KNN
K最近邻算法。给定一些已经训练好的数据,输入一个新的测试数据点,计算包含于此测试数据点的最近的点的分类情况,哪个分类的类型占多数,则此测试点的分类与此相同,所以在这里,有的时候可以复制不同的分类点不同的权重。近的点的权重大点,远的点自然就小点。详细介绍链接
Naive Bayes
朴素贝叶斯算法。朴素贝叶斯算法是贝叶斯算法里面一种比较简单的分类算法,用到了一个比较重要的贝叶斯定理,用一句简单的话概括就是条件概率的相互转换推导。详细介绍链接
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。通俗来说,就好比这么个道理,你在街上看到一个黑人,我问你你猜这哥们哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。
SVM
支持向量机算法。支持向量机算法是一种对线性和非线性数据进行分类的方法,非线性数据进行分类的时候可以通过核函数转为线性的情况再处理。其中的一个关键的步骤是搜索最大边缘超平面。详细介绍链接
Apriori
Apriori算法是关联规则挖掘算法,通过连接和剪枝运算挖掘出频繁项集,然后根据频繁项集得到关联规则,关联规则的导出需要满足最小置信度的要求。详细介绍链接
PageRank
网页重要性/排名算法。PageRank算法最早产生于Google,核心思想是通过网页的入链数作为一个网页好快的判定标准,如果1个网页内部包含了多个指向外部的链接,则PR值将会被均分,PageRank算法也会遭到LinkSpan攻击。详细介绍链接
RandomForest
随机森林算法。算法思想是决策树+boosting.决策树采用的是CART分类回归数,通过组合各个决策树的弱分类器,构成一个最终的强分类器,在构造决策树的时候采取随机数量的样本数和随机的部分属性进行子决策树的构建,避免了过分拟合的现象发生。详细介绍链接
Artificial Neural Network
“神经网络”这个词实际是来自于生物学,而我们所指的神经网络正确的名称应该是“人工神经网络(ANNs)”。
人工神经网络也具有初步的自适应与自组织能力。在学习或训练过程中改变突触权重值,以适应周围环境的要求。同一网络因学习方式及内容不同可具有不同的功能。人工神经网络是一个具有学习能力的系统,可以发展知识,以致超过设计者原有的知识水平。通常,它的学习训练方式可分为两种,一种是有监督或称有导师的学习,这时利用给定的样本标准进行分类或模仿;另一种是无监督学习或称无为导师学习,这时,只规定学习方式或某些规则,则具体的学习内容随系统所处环境 (即输入信号情况)而异,系统可以自动发现环境特征和规律性,具有更近似人脑的功能。
一文详尽之支持向量机算法!
寄语:本文介绍了SVM的理论,细致说明了“间隔”和“超平面”两个概念;随后,阐述了如何最大化间隔并区分了软硬间隔SVM;同时,介绍了SVC问题的应用。最后,用SVM乳腺癌诊断经典数据集,对SVM进行了深入的理解。
下图为SVM的分类效果显示,可以发现,不管是线性还是非线性,SVM均表现良好。
学习框架
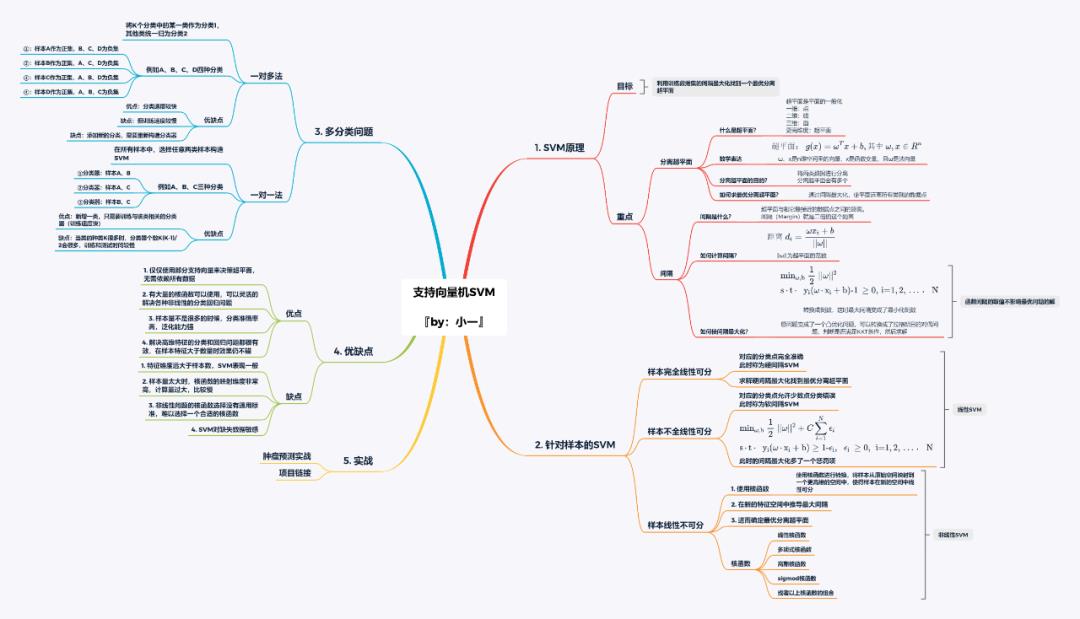
后台回复 SVM 可下载SVM学习框架高清导图
SVM理论
支持向量机(Support Vector Machine:SVM)的目的是用训练数据集的间隔最大化找到一个最优分离超平面。
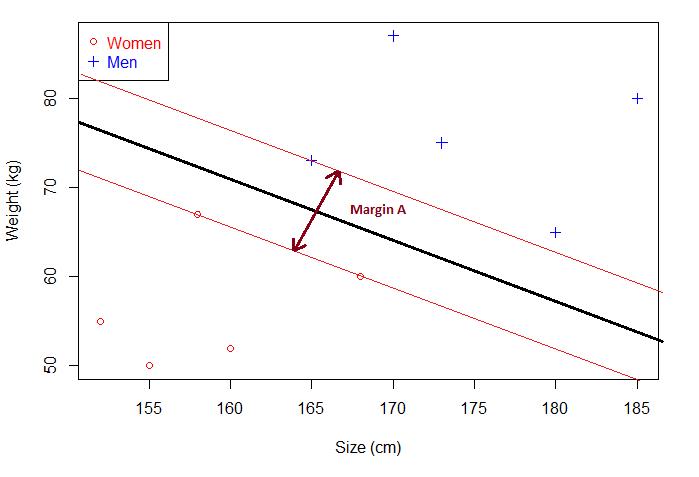
下边用一个例子来理解下间隔和分离超平面两个概念。现在有一些人的身高和体重数据,将它们绘制成散点图,是这样的:
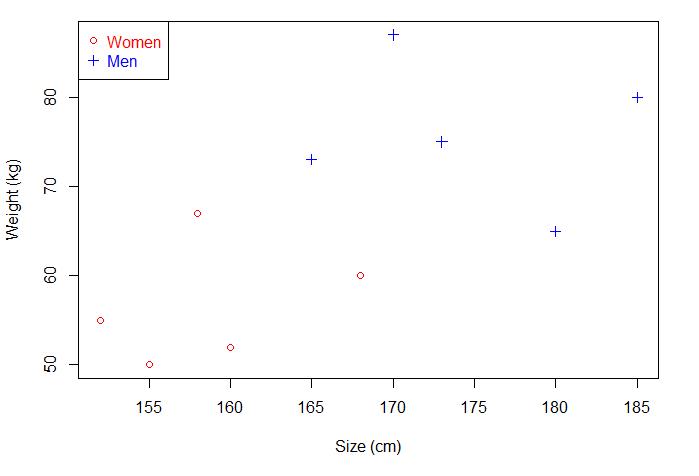
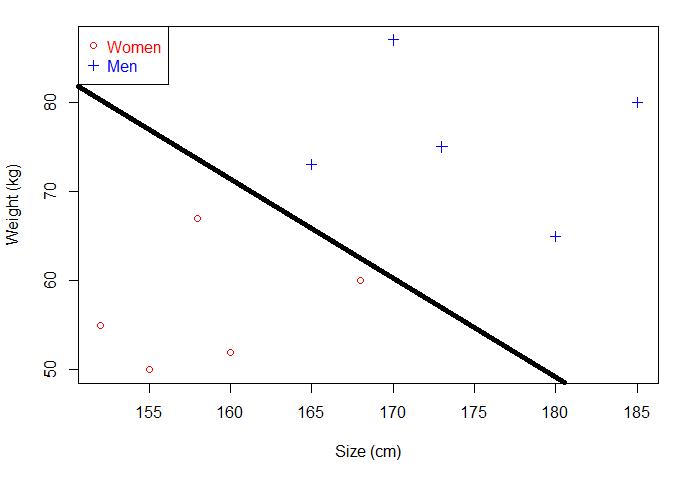
如果现在给你一个未知男女的身高和体重,你能分辨出性别吗?直接将已知的点划分为两部分,这个点落在哪一部分就对应相应的性别。那就可以画一条直线,直线以上是男生,直线以下是女生。
问题来了,现在这个是一个二维平面,可以画直线,如果是三维的呢?该怎么画?我们知道一维平面是点,二维平面是线,三维平面是面。
对的,那么注意,今天的第一个概念:超平面是平面的一般化:
在一维的平面中,它是点
在二维的平面中,它是线
在三维的平面中,它是面
在更高的维度中,我们称之为超平面
注意:后面的直线、平面都直接叫超平面了。
继续刚才的问题,我们刚才是通过一个分离超平面分出了男和女,这个超平面唯一吗?很明显,并不唯一,这样的超平面有若干个。
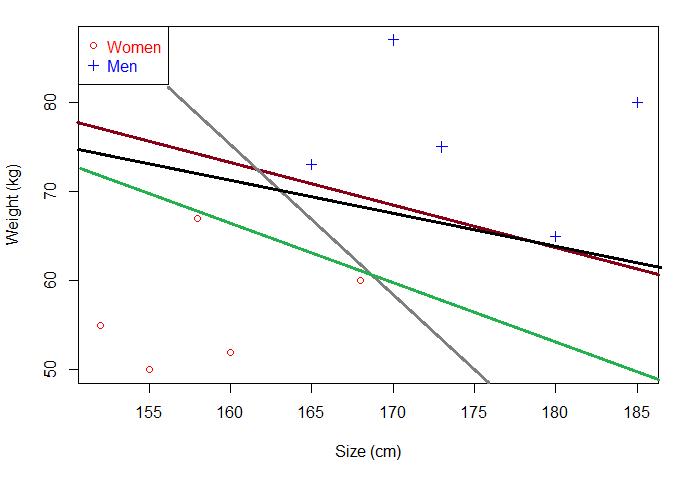
那么问题来了,既然有若干个,那肯定要最好的,这里最好的叫最优分离超平面。如何在众多分离超平面中选择一个最优分离超平面?下面这两个分离超平面,你选哪个?绿色的还是黑色的?
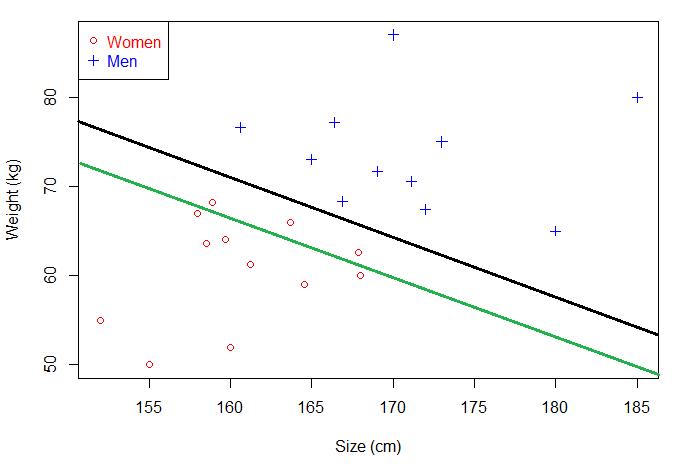
对,当然是黑色的,可是原理是什么?很简单,原理有两个,分别是:
正确的对训练数据进行分类
对未知数据也能很好的分类
黑色的分离超平面能够对训练数据很好的分类,当新增未知数据时,黑色的分离超平面泛化能力也强于绿色。深究一下,为什么黑色的要强于绿色?原理又是什么?
其实很简单:最优分离超平面其实是和两侧样本点有关,而且只和这些点有关。怎么理解这句话呢,我们看张图:
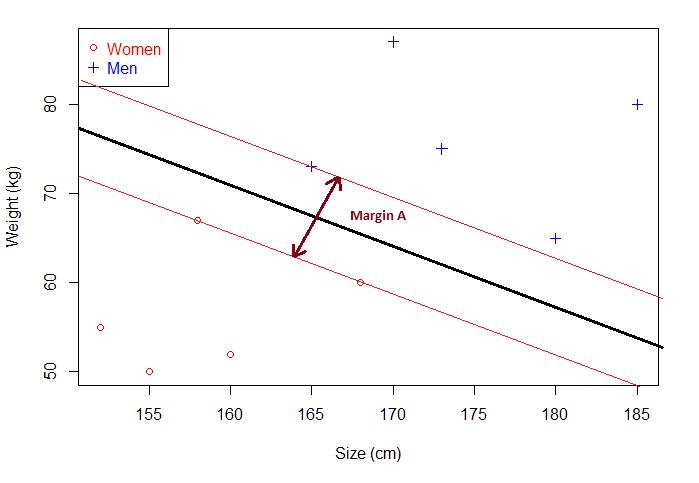
其中当间隔达到最大,两侧样本点的距离相等的超平面为最优分离超平面。注意,今天的第二个概念:对应上图,Margin对应的就是最优分离超平面的间隔,此时的间隔达到最大。
一般来说,间隔中间是无点区域,里面不会有任何点(理想状态下)。给定一个超平面,我们可以就算出这个超平面与和它最接近的数据点之间的距离。那么间隔(Margin)就是二倍的这个距离。
如果还是不理解为什么这个分离超平面就是最优分离超平面,那你在看这张图。
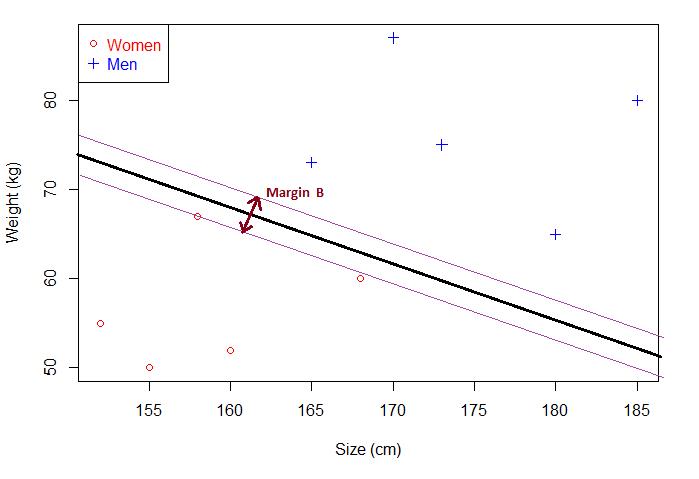 在这张图里面间隔MarginB小于上张图的MarginA。当出现新的未知点,MarginB分离超平面的泛化能力不如MarginA,用MarginB的分离超平面去分类,错误率大于MarginA
在这张图里面间隔MarginB小于上张图的MarginA。当出现新的未知点,MarginB分离超平面的泛化能力不如MarginA,用MarginB的分离超平面去分类,错误率大于MarginA
总结一下
支持向量机是为了通过间隔最大化找到一个最优分离超平面。在决定分离超平面的时候,只有极限位置的那两个点有用,其他点根本没有大作用,因为只要极限位置离得超平面的距离最大,就是最优的分离超平面了。
如何确定最大化间隔
如果我们能够确定两个平行超平面,那么两个超平面之间的最大距离就是最大化间隔。看个图你就都明白了:
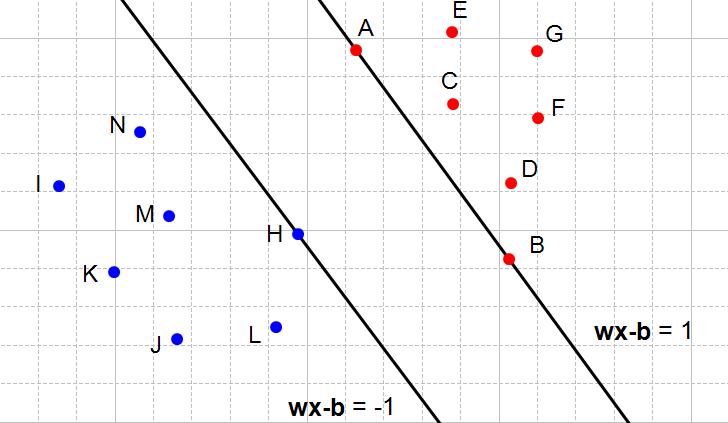
找到两个平行超平面,可以划分数据集并且两平面之间没有数据点
最大化上述两个超平面
1. 确定两个平行超平面
怎么确定两个平行超平面?我们知道一条直线的数学方程是:y-ax+b=0,而超平面会被定义成类似的形式:
推广到n维空间,则超平面方程中的w、x分别为:
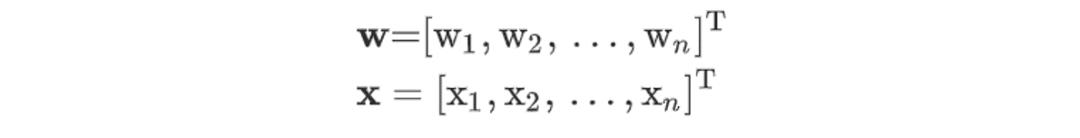 如何确保两超平面之间没有数据点?我们的目的是通过两个平行超平面对数据进行分类,那我们可以这样定义两个超平面。
如何确保两超平面之间没有数据点?我们的目的是通过两个平行超平面对数据进行分类,那我们可以这样定义两个超平面。
也就是这张图:所有的红点都是1类,所有的蓝点都是−1类。
不等式两边同时乘以 yi,-1类的超平面yi=-1,要改变不等式符号,合并后得
2. 确定间隔
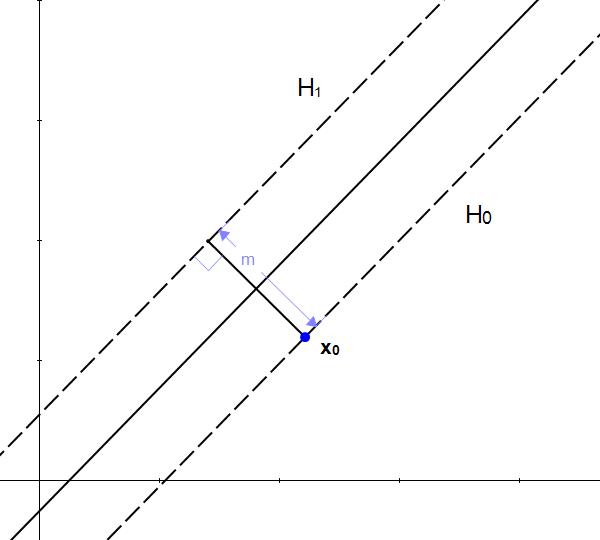
如何求两个平行超平面的间隔呢?我们可以先做这样一个假设:
是满足约束 的超平面
-
是满足约束 的超平面 -
是 上的一点
则 到平面 的垂直距离 就是我们要的间隔。
3. 确定目标
我们的间隔最大化,最后就成了这样一个问题:
上面的最优超平面问题是一个凸优化问题,可以转换成了拉格朗日的对偶问题,判断是否满足KKT条件,然后求解。上一句话包含的知识是整个SVM的核心,涉及到大量的公式推导。
此处略过推导的步骤,若想了解推导过程可直接百度。你只需要知道它的目的就是为了找出一个最优分离超平面。就假设我们已经解出了最大间隔,找到了最优分离超平面,它是这样的:
除去上面我们对最大间隔的推导计算,剩下的部分其实是不难理解的。从上面过程,我们可以发现,其实最终分类超平面的确定依赖于部分极限位置的样本点,这叫做支持向量。
由于支持向量在确定分离超平面中起着决定性作用,所有将这类模型叫做支持向量机。
我们在上面图中的点都是线性可分的,也就是一条线(或一个超平面)可以很容易的分开的。但是实际情况不都是这样,比如有的女生身高比男生高,有的男生体重比女生都轻,像这种存在噪声点分类,应该怎么处理?
针对样本的SVM
1. 硬间隔线性SVM
上面例子中提到的样本点都是线性可分的,我们就可以通过分类将样本点完全分类准确,不存在分类错误的情况,这种叫硬间隔,这类模型叫做硬间隔线性SVM。
2. 软间隔线性SVM
同样的,可以通过分类将样本点不完全分类准确,存在少部分分类错误的情况,这叫软间隔,这类模型叫做软间隔线性SVM。
不一样的是,因为有分类错误的样本点,但我们仍需要将错误降至最低,所有需要添加一个惩罚项来进行浮动,所有此时求解的最大间隔就变成了这样:
视频中是将平面中的样本点映射到三维空间中,使用一个平面将样本线性可分。
所以我们需要一种方法,可以将样本从原始空间映射到一个更高纬的空间中,使得样本在新的空间中线性可分,即:核函数。在非线性SVM中,核函数的选择关系到SVM的分类效果。
幸好的是,我们有多种核函数:线性核函数、多项式核函数、高斯核函数、sigmoid核函数等等,甚至你还可以将这些核函数进行组合,以达到最优线性可分的效果
核函数了解到应该就差不多了,具体的实现我们在下一节的实战再说。
多分类SVM
前面提到的所有例子最终都指向了二分类,现实中可不止有二分类,更多的是多分类问题。那么多分类应该怎么分呢?有两种方法:一对多和一对一。
1. 一对多法
一对多法讲究的是将所有的分类分成两类:一类只包含一个分类,另一类包含剩下的所有分类
举个例子:现在有A、B、C、D四种分类,根据一对多法可以这样分:
①:样本A作为正集,B、C、D为负集
②:样本B作为正集,A、C、D为负集
③:样本C作为正集,A、B、D为负集
④:样本D作为正集,A、B、C为负集
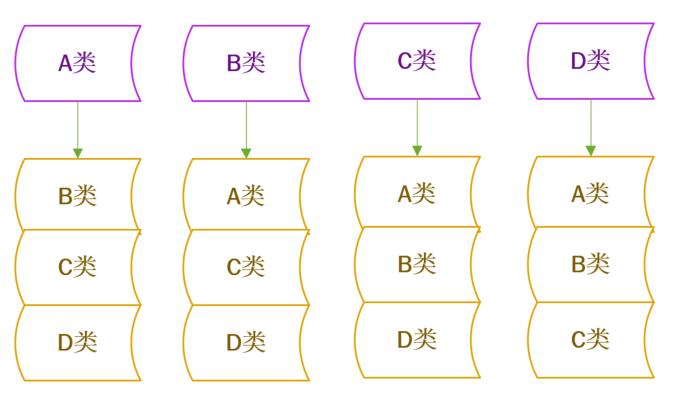
该方法分类速度较快,但训练速度较慢,添加新的分类,需要重新构造分类器。
2. 一对一法
一对一法讲究的是从所有分类中只取出两类,一个为正类一个为父类
再举个例子:现在有A、B、C三种分类,根据一对一法可以这样分:
①分类器:样本A、B
②分类器:样本A、C
③分类器:样本B、C
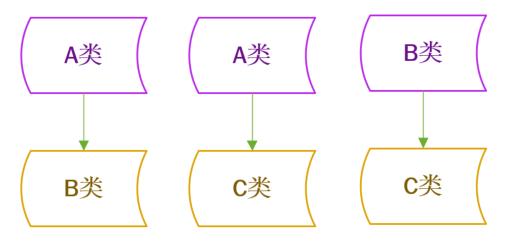
该方法的优点是:当新增一类时,只需要训练与该类相关的分类器即可,训练速度较快。缺点是:当类的种类K很多时,分类器个数K(K-1)/2会很多,训练和测试时间较慢。
SVC,Support Vector Classification
我们知道针对样本有线性SVM和非线性SVM。同样的在sklearn中提供的这两种的实现,分别是:LinearSVC和SVC。
SVC : Support Vector Classification 用支持向量机处理分类问题
SVR : Support Vector Regression 用支持向量机处理回归问题
1. SVC和LinearSVC
LinearSVC是线性分类器,用于处理线性分类的数据,且只能使用线性核函数。SVC是非线性分类器,即可以使用线性核函数进行线性划分,也可以使用高维核函数进行非线性划分。
2. SVM的使用
在sklearn 中,一句话调用SVM,
from sklearn import svm主要说一下SVC的创建,因为它的参数比较重要
model = svm.SVC(kernel='rbf', C=1.0, gamma=0.001)分别解释一下三个重要参数:
kernel代表核函数的选择,有四种选择,默认rbf(即高斯核函数)
参数C代表目标函数的惩罚系数,默认情况下为 1.0
参数gamma代表核函数的系数,默认为样本特征数的倒数
其中kernel代表的四种核函数分别是:
linear:线性核函数,在数据线性可分的情况下使用的
poly:多项式核函数,可以将数据从低维空间映射到高维空间
rbf:高斯核函数,同样可以将样本映射到高维空间,但所需的参数较少,通常性能不错
sigmoid:sigmoid核函数,常用在神经网络的映射中
SVM的使用就介绍这么多,来实战测试一下。
经典数据集实战
1. 数据集
SVM的经典数据集:乳腺癌诊断。医疗人员采集了患者乳腺肿块经过细针穿刺 (FNA) 后的数字化图像,并且对这些数字图像进行了特征提取,这些特征可以描述图像中的细胞核呈现。通过这些特征可以将肿瘤分成良性和恶性。
本次数据一共569条、32个字段,先来看一下具体数据字段吧:
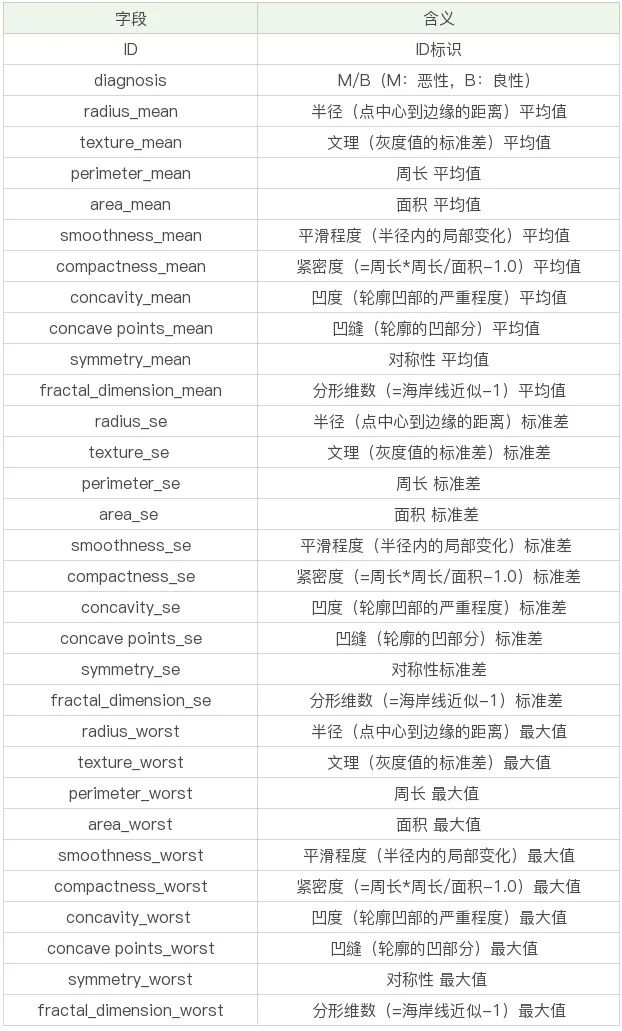
其中mean结尾的代表平均值、se结尾的代表标准差、worst结尾代表最坏值(这里具体指肿瘤的特征最大值)。所有其实主要有10个特征字段,一个id字段,一个预测类别字段。我们的目的是通过给出的特征字段来预测肿瘤是良性还是恶性。
2. 数据EDA
EDA:Exploratory Data Analysis探索性数据分析,先来看数据的分布情况:
df_data.info()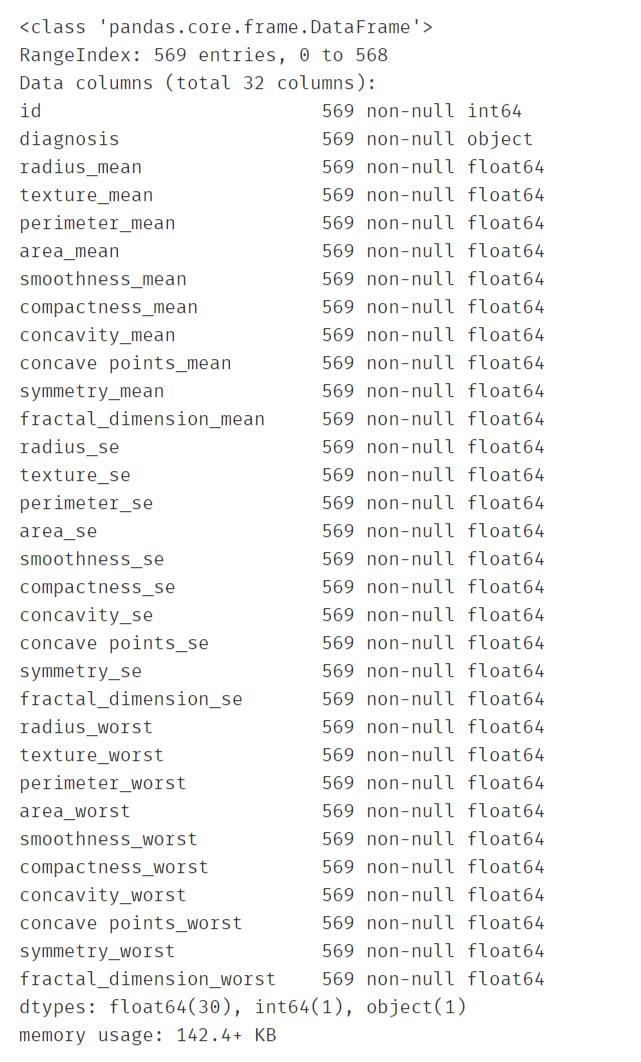
一共569条、32个字段。32个字段中1个object类型,一个int型id,剩下的都是float 类型。另外:数据中不存在缺失值。
大胆猜测一下,object类型可能是类别型数据,即最终的预测类型,需要进行处理,先记下。再来看连续型数据的统计数据:
df_data.describe()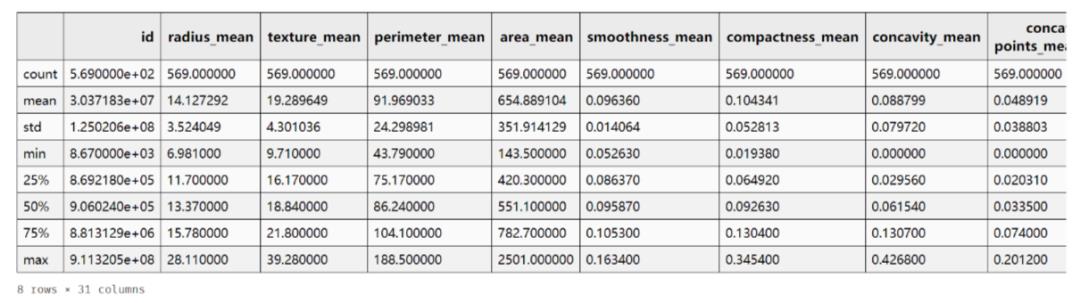
好像也没啥问题(其实因为这个数据本身比较规整),可直接开始特征工程吧。
3. 特征工程
首先就是将类别数据连续化
"""2. 类别特征向量化"""le = preprocessing.LabelEncoder()le.fit(df_data['diagnosis'])df_data['diagnosis'] = le.transform(df_data['diagnosis'])
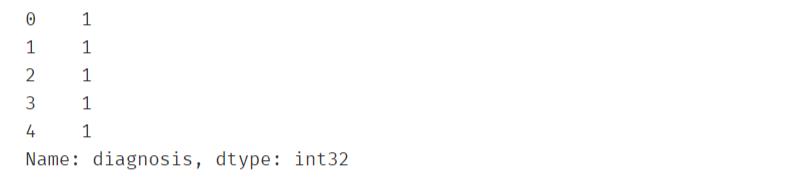
再来观察每一个特征的三个指标:均值、标准差和最大值。优先选择均值,最能体现该指特征的整体情况。
"""3. 提取特征"""# 提取所有mean 字段和label字段df_data_X = df_data.filter(regex='_mean')df_data_y = df_data['diagnosis']
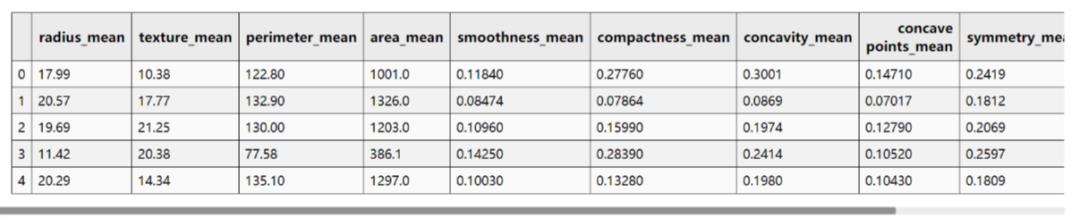
现在还有十个特征,我们通过热力图来看一下特征之间的关系。
#热力图查看特征之间的关系sns.heatmap(df_data[df_data_X.columns].corr(), linewidths=0.1, vmax=1.0, square=True,cmap=sns.color_palette('RdBu', n_colors=256),linecolor='white', annot=True)plt.title('the feature of corr')plt.show()
热力图是这样的:
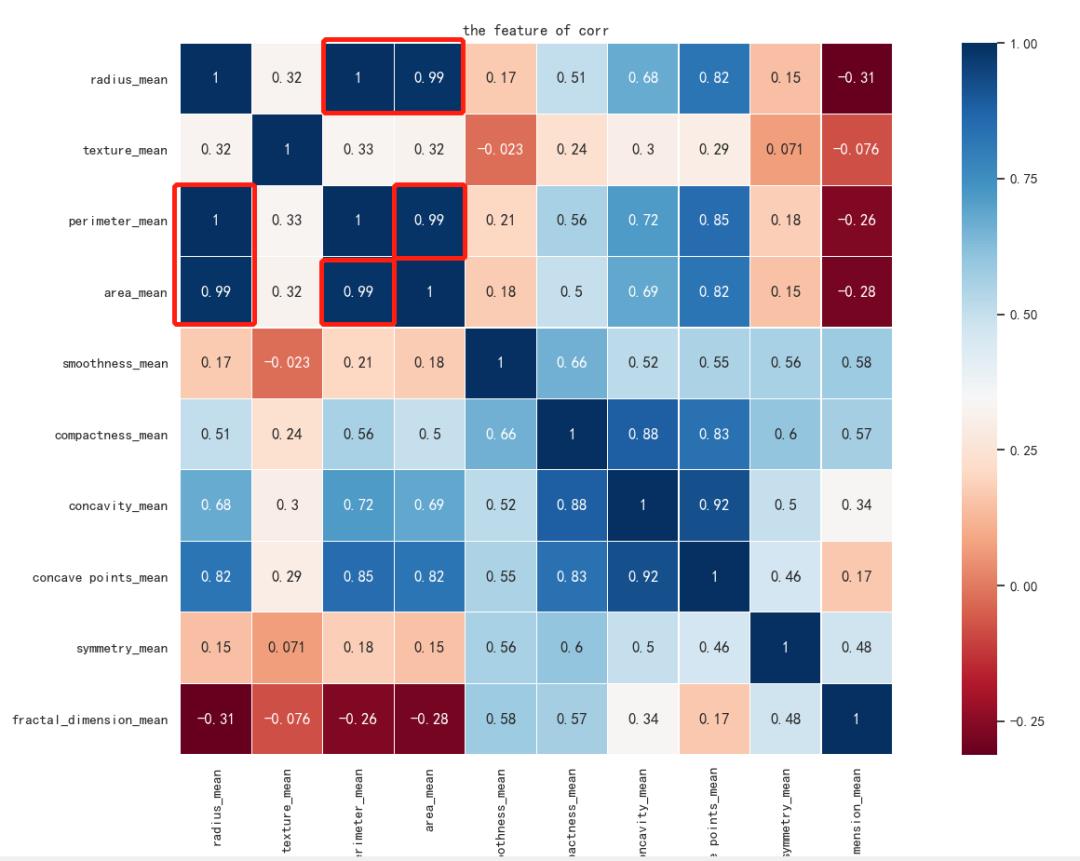
最后一步,因为是连续数值,最好对其进行标准化。标准化之后的数据是这样的:
df_data_X = df_data_X.drop(['radius_mean', 'area_mean'], axis=1)"""5. 进行特征归一化/缩放"""scaler = preprocessing.StandardScaler()df_data_X = scaler.fit_transform(df_data_X)return df_data_X, df_data_y

4. 训练模型
上面已经做好了特征工程,直接塞进模型看看效果怎么样。因为并不知道数据样本到底是否线性可分,所有我们都来试一下两种算法。先来看看LinearSVC 的效果
"""1.1. 第一种模型验证方法"""# 切分数据集X_train, X_test, y_train, y_test = train_test_split(data_X, data_y, test_size=0.2)# 创建SVM分类器model = svm.LinearSVC()# 用训练集做训练model.fit(X_train, y_train)# 用测试集做预测pred_label = model.predict(X_test)print('准确率: ', metrics.accuracy_score(pred_label, y_test))

效果很好,简直好的不行,在此,并没有考虑准确率。
ok,还有SVC的效果。因为SVC需要设置参数,直接通过网格搜索让机器自己找到最优参数,效果更好。
"""2. 通过网格搜索寻找最优参数"""parameters = {'gamma': np.linspace(0.0001, 0.1),'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],}model = svm.SVC()grid_model = GridSearchCV(model, parameters, cv=10, return_train_score=True)grid_model.fit(X_train, y_train)# 用测试集做预测pred_label = grid_model.predict(X_test)print('准确率: ', metrics.accuracy_score(pred_label, y_test))# 输出模型的最优参数print(grid_model.best_params_)
可以看出,最终模型还是选择rbf高斯核函数,果然实至名归。主要是通过数据EDA+特征工程完成了数据方面的工作,然后通过交叉验证+网格搜索确定了最优模型和最优参数。
延伸阅读
【1】模型评估:
【2】逻辑回归:
【3】K-means:
【4】EM算法:
【5】CatBoost:
“为沉迷学习点赞↓
以上是关于大数据分析工具详尽介绍&数据分析算法的主要内容,如果未能解决你的问题,请参考以下文章