大数据分析方法解读以及相关工具介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据分析方法解读以及相关工具介绍相关的知识,希望对你有一定的参考价值。
大数据分析方法解读以及相关工具介绍 要知道,大数据已不再是数据大,最重要的现实就是对大数据进行分析,只有通过分析才能获取很多智能的
参考技术A 大数据分析方法解读以及相关工具介绍要知道,大数据已不再是数据大,最重要的现实就是对大数据进行分析,只有通过分析才能获取很多智能的,深入的,有价值的信息。
越来越多的应用涉及到大数据,这些大数据的属性,包括数量,速度,多样性等等都是呈现了大数据不断增长的复杂性,所以,大数据的分析方法在大数据领域就显得尤为重要,可以说是决定最终信息是否有价值的决定性因素。基于此,大数据分析方法理论有哪些呢?
大数据分析的五个基本方面
PredictiveAnalyticCapabilities(预测性分析能力)
数据挖掘可以让分析员更好的理解数据,而预测性分析可以让分析员根据可视化分析和数据挖掘的结果做出一些预测性的判断。
DataQualityandMasterDataManagement(数据质量和数据管理)
数据质量和数据管理是一些管理方面的最佳实践。通过标准化的流程和工具对数据进行处理可以保证一个预先定义好的高质量的分析结果。
AnalyticVisualizations(可视化分析)
不管是对数据分析专家还是普通用户,数据可视化是数据分析工具最基本的要求。可视化可以直观的展示数据,让数据自己说话,让观众听到结果。
SemanticEngines(语义引擎)
我们知道由于非结构化数据的多样性带来了数据分析的新的挑战,我们需要一系列的工具去解析,提取,分析数据。语义引擎需要被设计成能够从“文档”中智能提取信息。
DataMiningAlgorithms(数据挖掘算法)
可视化是给人看的,数据挖掘就是给机器看的。集群、分割、孤立点分析还有其他的算法让我们深入数据内部,挖掘价值。这些算法不仅要处理大数据的量,也要处理大数据的速度。
假如大数据真的是下一个重要的技术革新的话,我们最好把精力关注在大数据能给我们带来的好处,而不仅仅是挑战。
大数据处理
大数据处理数据时代理念的三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。具体的大数据处理方法其实有很多,但是根据长时间的实践,笔者总结了一个基本的大数据处理流程,并且这个流程应该能够对大家理顺大数据的处理有所帮助。整个处理流程可以概括为四步,分别是采集、导入和预处理、统计和分析,以及挖掘。
采集
大数据的采集是指利用多个数据库来接收发自客户端的数据,并且用户可以通过这些数据库来进行简单的查询和处理工作。比如,电商会使用传统的关系型数据库MySQL和Oracle等来存储每一笔事务数据,除此之外,Redis和MongoDB这样的NoSQL数据库也常用于数据的采集。
在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。
统计/分析
统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的海量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。
导入/预处理
虽然采集端本身会有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些来自前端的数据导入到一个集中的大型分布式数据库,或者分布式存储集群,并且可以在导入基础上做一些简单的清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足部分业务的实时计算需求。导入与预处理过程的特点和挑战主要是导入的数据量大,每秒钟的导入量经常会达到百兆,甚至千兆级别。
挖掘
与前面统计和分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数据上面进行基于各种算法的计算,从而起到预测的效果,从而实现一些高级别数据分析的需求。比较典型算法有用于聚类的K-Means、用于统计学习的SVM和用于分类的Naive Bayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于挖掘的算法很复杂,并且计算涉及的数据量和计算量都很大,还有,常用数据挖掘算法都以单线程为主。
大数据分析工具详解 IBM惠普微软工具在列
去年,IBM宣布以17亿美元收购数据分析公司Netezza;EMC继收购数据仓库软件厂商Greenplum后再次收购集群NAS厂商Isilon;Teradata收购了Aster Data 公司;随后,惠普收购实时分析平台Vertica等,这些收购事件指向的是同一个目标市场——大数据。是的,大数据时代已经来临,大家都在摩拳擦掌,抢占市场先机。
而在这里面,最耀眼的明星是hadoop,Hadoop已被公认为是新一代的大数据处理平台,EMC、IBM、Informatica、Microsoft以及Oracle都纷纷投入了Hadoop的怀抱。对于大数据来说,最重要的还是对于数据的分析,从里面寻找有价值的数据帮助企业作出更好的商业决策。下面,我们就来看以下八大关于大数据分析的工具。
EMC Greenplum统一分析平台(UAP)
Greenplum在2010年被EMC收购了其EMC Greenplum统一分析平台(UAP)是一款单一软件平台,数据团队和分析团队可以在该平台上无缝地共享信息、协作分析,没必要在不同的孤岛上工作,或者在不同的孤岛之间转移数据。正因为如此,UAP包括ECM Greenplum关系数据库、EMC Greenplum HD Hadoop发行版和EMC Greenplum Chorus。
EMC为大数据开发的硬件是模块化的EMC数据计算设备(DCA),它能够在一个设备里面运行并扩展Greenplum关系数据库和Greenplum HD节点。DCA提供了一个共享的指挥中心(Command Center)界面,让管理员可以监控、管理和配置Greenplum数据库和Hadoop系统性能及容量。随着Hadoop平台日趋成熟,预计分析功能会急剧增加。
IBM打组合拳提供BigInsights和BigCloud
几年前,IBM开始在其实验室尝试使用Hadoop,但是它在去年将相关产品和服务纳入到商业版IBM在去年5月推出了InfoSphere BigI云版本的 InfoSphere BigInsights使组织内的任何用户都可以做大数据分析。云上的BigInsights软件可以分析数据库里的结构化数据和非结构化数据,使决策者能够迅速将洞察转化为行动。
IBM随后又在10月通过其智慧云企业(SmartCloud Enterprise)基础架构,将BigInsights和BigSheets作为一项服务来提供。这项服务分基础版和企业版;一大卖点就是客户不必购买支持性硬件,也不需要IT专门知识,就可以学习和试用大数据处理和分析功能。据IBM声称,客户用不了30分钟就能搭建起Hadoop集群,并将数据转移到集群里面,数据处理费用是每个集群每小时60美分起价。
Informatica 9.1:将大数据的挑战转化为大机遇
Informatica公司在去年10月则更深入一步,当时它推出了HParser,这是一种针对Hadoop而优化的数据转换环境。据Informatica声称,软件支持灵活高效地处理Hadoop里面的任何文件格式,为Hadoop开发人员提供了即开即用的解析功能,以便处理复杂而多样的数据源,包括日志、文档、二进制数据或层次式数据,以及众多行业标准格式(如银行业的NACHA、支付业的SWIFT、金融数据业的FIX和保险业的ACORD)。正如数据库内处理技术加快了各种分析方法,Informatica同样将解析代码添加到Hadoop里面,以便充分利用所有这些处理功能,不久会添加其他的数据处理代码。
Informatica HParser是Informatica B2B Data Exchange家族产品及Informatica平台的最新补充,旨在满足从海量无结构数据中提取商业价值的日益增长的需求。去年, Informatica成功地推出了创新的Informatica 9.1 for Big Data,是全球第一个专门为大数据而构建的统一数据集成平台。
甲骨文大数据机——Oracle Big Data Appliance
甲骨文的Big Data Appliance集成系统包括Cloudera的Hadoop系统管理软件和支持服务Apache Hadoop 和Cloudera Manager。甲骨文视Big Data Appliance为包括Exadata、Exalogic和 Exalytics In-Memory Machine的“建造系统”。Oracle大数据机(Oracle Big Data Appliance),是一个软、硬件集成系统,在系统中融入了Cloudera的Distribution Including Apache Hadoop、Cloudera Manager和一个开源R。该大数据机采用Oracle Linux操作系统,并配备Oracle NoSQL数据库社区版本和Oracle HotSpot Java虚拟机。Big Data Appliance为全架构产品,每个架构864GB存储,216个CPU内核,648TBRAW存储,每秒40GB的InifiniBand连接。Big Data Appliance售价45万美元,每年硬软件支持费用为12%。
甲骨文Big Data Appliance与EMC Data Computing Appliance匹敌,IBM也曾推出数据分析软件平台InfoSphere BigInsights,微软也宣布在2012年发布Hadoop架构的SQL Server 2012大型数据处理平台。
统计分析方法以及统计软件详细介绍
统计分析方法有哪几种?下面我们将详细阐述,并介绍一些常用的统计分析软件。
一、指标对比分析法指标对比分析法
统计分析的八种方法一、指标对比分析法指标对比分析法,又称比较分析法,是统计分析中最常用的方法。是通过有关的指标对比来反映事物数量上差异和变化的方法。有比较才能鉴别。单独看一些指标,只能说明总体的某些数量特征,得不出什么结论性的认识;一经过比较,如与国外、外单位比,与历史数据比,与计划相比,就可以对规模大小、水平高低、速度快慢作出判断和评价。
指标分析对比分析方法可分为静态比较和动态比较分析。静态比较是同一时间条件下不同总体指标比较,如不同部门、不同地区、不同国家的比较,也叫横向比较;动态比较是同一总体条件不同时期指标数值的比较,也叫纵向比较。这两种方法既可单独使用,也可结合使用。进行对比分析时,可以单独使用总量指标或相对指标或平均指标,也可将它们结合起来进行对比。比较的结果可用相对数,如百分数、倍数、系数等,也可用相差的绝对数和相关的百分点(每1%为一个百分点)来表示,即将对比的指标相减。
二、分组分析法指标对比分析法
分组分析法指标对比分析法对比,但组成统计总体的各单位具有多种特征,这就使得在同一总体范围内的各单位之间产生了许多差别,统计分析不仅要对总体数量特征和数量关系进行分析,还要深入总体的内部进行分组分析。分组分析法就是根据统计分析的目的要求,把所研究的总体按照一个或者几个标志划分为若干个部分,加以整理,进行观察、分析,以揭示其内在的联系和规律性。
统计分组法的关键问题在于正确选择分组标值和划分各组界限。
三、时间数列及动态分析法
时间数列。是将同一指标在时间上变化和发展的一系列数值,按时间先后顺序排列,就形成时间数列,又称动态数列。它能反映社会经济现象的发展变动情况,通过时间数列的编制和分析,可以找出动态变化规律,为预测未来的发展趋势提供依据。时间数列可分为绝对数时间数列、相对数时间数列、平均数时间数列。
时间数列速度指标。根据绝对数时间数列可以计算的速度指标:有发展速度、增长速度、平均发展速度、平均增长速度。
动态分析法。在统计分析中,如果只有孤立的一个时期指标值,是很难作出判断的。如果编制了时间数列,就可以进行动态分析,反映其发展水平和速度的变化规律。
进行动态分析,要注意数列中各个指标具有的可比性。总体范围、指标计算方法、计算价格和计量单位,都应该前后一致。时间间隔一般也要一致,但也可以根据研究目的,采取不同的间隔期,如按历史时期分。为了消除时间间隔期不同而产生的指标数值不可比,可采用年平均数和年平均发展速度来编制动态数列。此外在统计上,许多综合指标是采用价值形态来反映实物总量,如国内生产总值、工业总产值、社会商品零售总额等计算不同年份的发展速度时,必须消除价格变动因素的影响,才能正确的反映实物量的变化。也就是说必须用可比价格(如用不变价或用价格指数调整)计算不同年份相同产品的价值,然后才能进行对比。
为了观察我国经济发展的波动轨迹,可将各年国内生产总值的发展速度编制时间数列,并据以绘制成曲线图,令人得到直观认识。
四、指数分析法
指数是指反映社会经济现象变动情况的相对数。有广义和狭义之分。根据指数所研究的范围不同可以有个体指数、类指数与总指数之分。
指数的作用:一是可以综合反映复杂的社会经济现象的总体数量变动的方向和程度;二是可以分析某种社会经济现象的总变动受各因素变动影响的程度,这是一种因素分析法。操作方法是:通过指数体系中的数量关系,假定其他因素不变,来观察某一因素的变动对总变动的影响。
用指数进行因素分析。因素分析就是将研究对象分解为各个因素,把研究对象的总体看成是各因素变动共同的结果,通过对各个因素的分析,对研究对象总变动中各项因素的影响程度进行测定。因素分析按其所研究的对象的统计指标不同可分为对总量指标的变动的因素分析,对平均指标变动的因素分析。
五、平衡分析法
平衡分析是研究社会经济现象数量变化对等关系的一种方法。它把对立统一的双方按其构成要素一一排列起来,给人以整体的概念,以便于全局来观察它们之间的平衡关系。平衡关系广泛存在于经济生活中,大至全国宏观经济运行,小至个人经济收支。平衡种类繁多,如财政平衡表、劳动力平衡表、能源平衡表、国际收支平衡表、投入产出平衡表,等等。平衡分析的作用:一是从数量对等关系上反映社会经济现象的平衡状况,分析各种比例关系相适应状况;二是揭示不平衡的因素和发展潜力;三是利用平衡关系可以从各项已知指标中推算未知的个别指标。
六、综合评价分析
社会经济分析现象往往是错综复杂的,社会经济运行状况是多种因素综合作用的结果,而且各个因素的变动方向和变动程度是不同的。如对宏观经济运行的评价,涉及生活、分配、流通、消费各个方面;对企业经济效益的评价,涉及人、财、物合理利用和市场销售状况。如果只用单一指标,就难以作出恰当的评价。
进行综合评价包括四个步骤:
1.确定评价指标体系,这是综合评价的基础和依据。要注意指标体系的全面性和系统性。
2.搜集数据,并对不同计量单位的指标数值进行同度量处理。可采用相对化处理、函数化处理、标准化处理等方法。
3.确定各指标的权数,以保证评价的科学性。根据各个指标所处的地位和对总体影响程度不同,需要对不同指标赋予不同的权数。
4.对指标进行汇总,计算综合分值,并据此作出综合评价。
七、景气分析
经济波动是客观存在的,是任何国家都难以完全避免的。如何避免大的经济波动,保持经济的稳定发展,一直是各国政府和经济之专家在宏观调控和决策中面临的重要课题,景气分析正是适应这一要求而产生和发展的。景气分析是一种综合评价分析,可分为宏观经济景气分析和企业景气调查分析。
宏观经济景气分析。是国家统计局20世纪80年代后期开始着手建立监测指标体系和评价方法,经过十多年时间和不断完善,已形成制度,定期提供景气分析报告,对宏观经济运行状态起到晴雨表和报警器的作用,便于国务院和有关部门及时采取宏观调控措施。以经常性的小调整,防止经济的大起大落。
企业景气调查分析。是全国的大中型各类企业中,采取抽样调查的方法,通过问卷的形式,让企业负责人回答有关情况判断和预期。内容分为两类:一是对宏观经济总体的判断和预期;一是对企业经营状况的判断和预期,如产品订单、原材料购进、价格、存货、就业、市场需求、固定资产投资等。
八、预测分析
宏观经济决策和微观经济决策,不仅需要了解经济运行中已经发生了的实际情况,而且更需要预见未来将发生的情况。根据已知的过去和现在推测未来,就是预测分析。
统计预测属于定量预测,是以数据分析为主,在预测中结合定性分析。统计预测的方法大致可分为两类:一类是主要根据指标时间数列自身变化与时间的依存关系进行预测,属于时间数列分析;另一类是根据指标之间相互影响的因果关系进行预测,属于回归分析。
预测分析的方法有回归分析法、滑动平均法、指数平滑法、周期(季节)变化分析和随机变化分析等。比较复杂的预测分析需要建立计量经济模型,求解模型中的参数又有许多方法。
mysql 5.7中的用户权限分配相关解读!
这篇文章主要介绍了MySQL中基本的用户和权限管理方法,包括各个权限所能操作的事务以及操作权限的一些常用命令语句,是MySQL入门学习中的基础知识,需要的朋友可以参考下
一、简介
各大帖子及文章都会讲到数据库的权限按最小权限为原则,这句话本身没有错,但是却是一句空话。因为最小权限,这个东西太抽象,很多时候你并弄不清楚具体他需要哪些权限。 现在很多mysql用着root账户在操作,并不是大家不知道用root权限太大不安全,而是很多人并不知道该给予什么样的权限既安全又能保证正常运行。所以,本文更多的是考虑这种情况下,我们该如何简单的配置一个安全的mysql。注:本文测试环境为mysql-5.7.11
二、Mysql权限介绍
mysql中存在4个控制权限的表,分别为user表,db表,tables_priv表,columns_priv表。
mysql权限表的验证过程为:
1.先从user表中的Host,User,Password这3个字段中判断连接的ip、用户名、密码是否存在,存在则通过验证。
2.通过身份认证后,进行权限分配,按照user,db,tables_priv,columns_priv的顺序进行验证。即先检查全局权限表user,如果user中对应的权限为Y,则此用户对所有数据库的权限都为Y,将不再检查db, tables_priv,columns_priv;如果为N,则到db表中检查此用户对应的具体数据库,并得到db中为Y的权限;如果db中为N,则检查tables_priv中此数据库对应的具体表,取得表中的权限Y,以此类推。
三、Mysql有哪些权限


四、mysql所有权限分类(方便记忆)

很明显总共28个权限
四、数据库层面(db表)的权限分析及分配建议
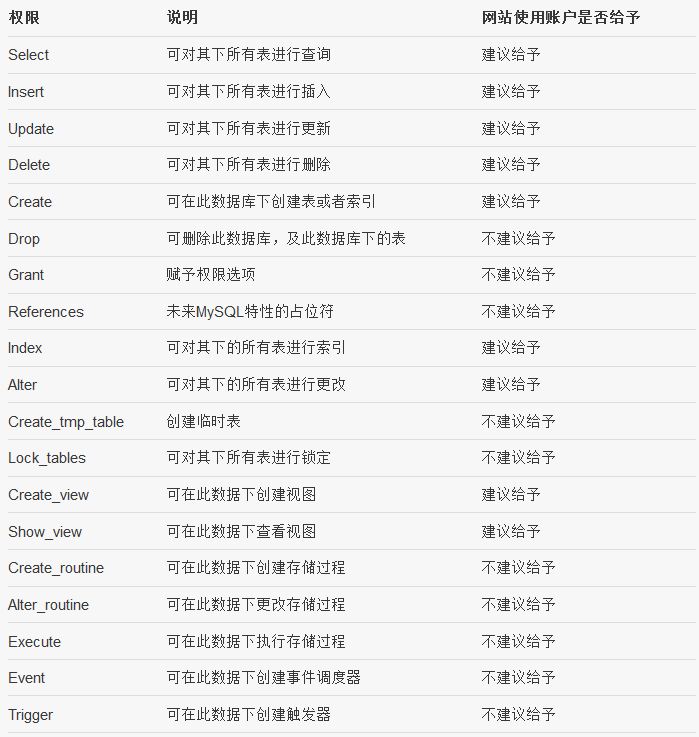
五、mysql安全配置方案
1 限制访问mysql端口的ip
windows可以通过windows防火墙或者ipsec来限制,linux下可以通过iptables来限制。
2 修改mysql的端口
windows下可以修改配置文件my.ini来实现,linux可以修改配置文件my.cnf来实现。
3 对所有用户设置强密码并严格指定对应账号的访问ip
mysql中可在user表中指定用户的访问可访问ip
4 root特权账号的处理
建议给root账号设置强密码,并指定只容许本地登录
5 日志的处理
如需要可开启查询日志,查询日志会记录登录和查询语句。
6 mysql进程运行账号
在windows下禁止使用local system来运行mysql账户,可以考虑使用network service或者自己新建一个账号,但是必须给与mysql程序所在目录的读取权限和data目录的读取和写入权限; 在linux下,新建一个mysql账号,并在安装的时候就指定mysql以mysql账户来运行,给与程序所在目录的读取权限,data所在目录的读取和写入权限。
7 mysql运行账号的磁盘权限
1)mysql运行账号需要给予程序所在目录的读取权限,以及data目录的读取和写入权限
2)不容许给予其他目录的写入和执行权限,特别是有网站的。
3)取消mysql运行账户对于cmd,sh等一些程序的执行权限。
8 网站使用的mysql账户的处理
新建一个账户,给予账户在所使用数据库的所有权限即可。这样既能保证网站对所对应的数据库的全部操作,也能保证账户不会因为权限过高而影响安全。给予单个数据库的所有权限的账户不会拥有super, process, file等管理权限的。 当然,如果能很明确是的知道,我的网站需要哪些权限,还是不要多给权限,因为很多时候发布者并不知道网站需要哪些权限,我才建议上面的配置。而且我指的通用的,具体到只有几台机器,不多的情况下,我个人建议还是给予只需要的权限,具体可参考上面的表格的建议。
9 删除无用数据库
test数据库对新建的账户默认有权限
六、mysql入侵提权分析及防止措施
一般来说,mysql的提权有这么几种方式:
1 udf提权
此方式的关键导入一个dll文件,个人认为只要合理控制了进程账户对目录的写入权限即可防止被导入dll文件;然后如果万一被攻破,此时只要进程账户的权限够低,也没办执行高危操作,如添加账户等。
2 写入启动文件
这种方式同上,还是要合理控制进程账户对目录的写入权限。
3 当root账户被泄露
如果没有合理管理root账户导致root账户被入侵,此时数据库信息肯定是没办法保证了。但是如果对进程账户的权限控制住,以及其对磁盘的权限控制,服务器还是能够保证不被沦陷的。
4 普通账户泄露(上述所说的,只对某个库有所有权限的账户)
此处说的普通账户指网站使用的账户,我给的一个比较方便的建议是直接给予特定库的所有权限。账户泄露包括存在注入及web服务器被入侵后直接拿到数据库账户密码。
此时,对应的那个数据库数据不保,但是不会威胁到其他数据库。而且这里的普通账户无file权限,所有不能导出文件到磁盘,当然此时还是会对进程的账户的权限严格控制。
普通账户给予什么样的权限可以见上表,实在不会就直接给予一个库的所有权限。
七、安全配置需要的常用命令
1.新建一个用户并给予相应数据库的权限
1 grant select,insert,update,delete,create,drop privileges on database.* to user@localhost identified by \'passwd\';
1 grant all privileges on database.* to user@localhost identified by \'passwd\';
2.刷新权限
1 flush privileges;
(这里我需要着重的强调一下,如果使用delete对数据库用户删除后需要执行一遍刷新flush privileges;否则会报有1396错误;建议还是使用drop等相关命令进行做删除用户操作。)
3.显示授权
1 show grants;
4.移除授权
1 revoke delete on *.* from \'jack\'@\'localhost\';
5.删除用户
1 drop user \'jack\'@\'localhost\';
6.给用户改名
1 rename user \'jack\'@\'%\' to \'jim\'@\'%\';
7.给用户改密码
1 SET authentication_string FOR \'root\'@\'localhost\' = authentication_string (\'123456\');
8.删除数据库
1 drop database test;
9.从数据库导出文件
1 select * from a into outfile "~/abc.sql"
以上是关于大数据分析方法解读以及相关工具介绍的主要内容,如果未能解决你的问题,请参考以下文章