恒源云(GPUSHARE)_替代MLM的预训练任务,真的超简单吗?
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云(GPUSHARE)_替代MLM的预训练任务,真的超简单吗?相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区
原文地址 | 简单到令人沮丧的替代MLM的预训练任务?
原文作者 | Mathor
看了这么多篇社区大佬Mathor的文章,就在刚刚,我居然发现大佬居然、大概、可能、也许在diss某个训练说法!
哇哦,amazing!这么神奇的吗?
我这小八卦之心,熊熊燃起了啊!这到底是个啥子神奇的模型训练方法?
大伙也别急惹,让我完整的copy大佬的文章,然后一起一睹究竟!
正文开始
EMNLP2021有一篇论文标题名为Frustratingly Simple Pretraining Alternatives to Masked Language Modeling,翻译过来就是「简单到令人沮丧的替代MLM的预训练任务」。但我给它加了个问号,因为我觉得首先作者提出的这些方法,对于模型来说太难了,即便是让我去做他所提出的这些预训练任务,我都不一定做得出来。其次是从结果来看效果似乎一般般
如下图所示,具体来说作者提出了4中用于替代MLM的预训练任务,分别是Shuffle、Random、Shuffle+Random、Token Type、First Char
PRETRAINING TASKS
Shuffle
作者提到这个方法的灵感来源于ELECTRA。具体来说,一个句子中有15%的token将会被随机调换顺序,然后模型需要做一个token级别的2分类问题,对于每一个位置预测该token是否被调换了位置。这个预训练任务的好处是,模型可以通过学习区分上下文中是否有token被打乱,从而获得句法和语义知识
对于Shuffle任务来说,其损失函数为简单的Cross-Entropy Loss:
其中 N N N表示一个样本的token数量, y i y_i yi和 p ( x i ) p(x_i) p(xi)都是向量,并且 p ( x i ) p(x_i) p(xi)表示第 i i i个token被预测是否打乱的概率
Random Word Detection (Random)
从词汇表 (Vocabulary)中随机挑选一些词,替换输入句子中15%的token,即便替换后整个句子语法不连贯也无所谓。它本质上同样是一个2分类问题,对于每一个位置预测该token是否被替换过,损失函数同公式(1)
Manipulated Word Detection (Shuffle + Random)
这个任务其实就是将Shuffle和Random任务结合起来,组成了一个更困难的任务。这里我是真的蚌埠住了,Shuffle、Random任务分别让我去判断我可能分辨出来,但是他俩相结合之后我真的就不一定能做出准确的判断了。作者可能也考虑到了这一点,因此分别将Shuffle和Random的比例调低至10%,同时要注意的是这两个任务是不重叠的,也就是不会存在某个token已经被Shuffle之后又被Random。现在这个任务是一个3分类问题。它的损失函数同样基于Cross-Entropy Loss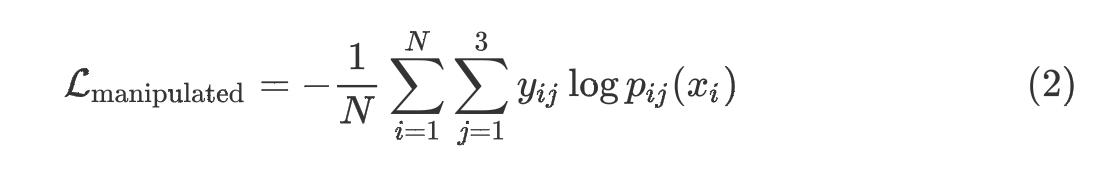
其中 j j j遍历Shuffle( j = 1 j=1 j=1)、Random( j = 2 j=2 j=2)、orignal( j = 3 j=3 j=3)这三个标签, p i j p_ij pij表示第 i i i个token对于第 j j j个标签的概率, y i j y_ij yij和 p i j p_ij pij都是具体的实数, p i p_i pi是一个三维的向量
Masked Token Type Classification (Token Type)
这个任务是一个4分类问题,判断当前位置的token是否为停用词(stop word)、数字、标点符号或正文内容。具体来说,作者使用NLTK工具来判断一个token是否为停用词,并且只要不属于前三种类别,那么当前token就属于正文内容类别。特别地,选取15%的token,将它们替换为[MASK]这个特殊token,至于为什么这么做,我想应该是:直接对某个token进行预测,实在是太容易了,为了加大难度,我们应该让模型先预测出这里是什么token,然后再预测其属于什么类别。它的损失函数同样是Cross-Entropy Loss
Masked First Character Prediction (First Char)
最后,作者提出了一个简单版的MLM任务。原本MLM任务对于某个位置需要做一个∣V∣|V|∣V∣分类问题,也就是说你需要对一个Vocabulary大小的向量进行Softmax,这个任务实际上是很困难的,因为候选集合实在是太大了,而且还可能存在过拟合的风险。作者提出的最后一个任务,只需要预测当前位置所对应token的第一个字符,这样任务就转变为了29分类问题。具体来说,26个英文字母、一个代表数字的标记、一个代表标签符号的标记、一个代表其他类别的标记,加起来总共有29种类别。同样,有15%的token会被替换为[MASK],然后进行预测
RESULTS
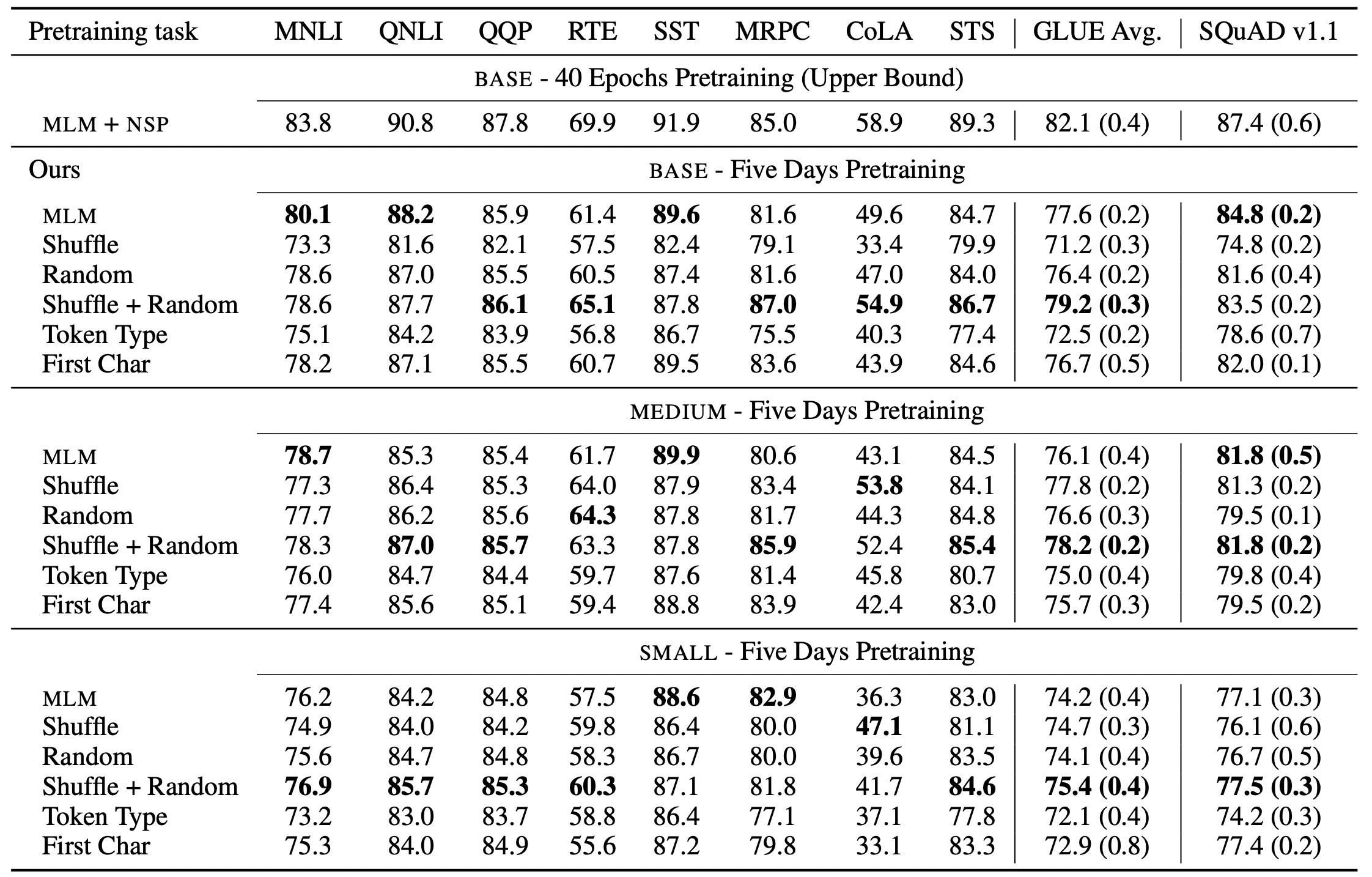
结果如上图,大家直接看就行了。实际上他们的结果有些一言难尽,不过作者也提到,如果训练时间和Baseline一样长,他们是有信心超过Baseline的。那我就有疑问了,为什么你不多训练一会儿呢,是为了赶EMNLP的DDL吗?
个人总结
本文主要创新点是作者提出了可以替代MLM的5个新的预训练任务,因为MLM是token级别的,所以这5个任务也是token级别的。明年EMNLP会不会有人提出sentence级别的,用于替代NSP/SOP的预训练任务呢?另外有一点要吐槽的是这篇论文的标题:Frustratingly Simple xxxx,简单到令人沮丧的xxxx,这种标题在我印象中已经看到好几次了,有一种标题党的感觉
哈哈哈哈,我心中的大佬发话了,标题党不可以。
以上是关于恒源云(GPUSHARE)_替代MLM的预训练任务,真的超简单吗?的主要内容,如果未能解决你的问题,请参考以下文章
恒源云(Gpushare)_自动化训练小技巧白送给你,不要吗?