恒源云_训练一个专门捣乱的模型
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_训练一个专门捣乱的模型相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区(专注人工智能/深度学习云 GPU 服务器训练平台,官方体验网址:https://gpushare.com/center/)
原文作者 | Mathor
三位韩国人在EMNLP 2021 Findings上发表了一篇论文,名为Devil’s Advocate: Novel Boosting Ensemble Method from Psychological Findings for Text Classification,其中Devil’s Advocate有一部同名电影,翻译过来叫「魔鬼代言人」,他们主要挑战的是传统模型融合的方法,例如硬投票(Hard-Voting)、软投票(Soft Voting)、Bagging等。源码在HwiyeolJo/DevilsAdvocate
在群体决策过程中,大部分人会根据既定思维进行思考,而Devil’s Advocate是指那些提出的意见与大多数人不一致的那个人,Devil’s Advocate的存在可以激发群体的头脑风暴,打破固化思维。以上内容参考维基百科恶魔的代言人
ENSEMBLES
在具体讲解作者的方法前,先简单过一下常见的模型融合方法
Soft Voting
软投票是对不同模型的预测分数进行加权平均,例如有一个三分类问题,第一个模型对某个样本的预测概率为[0.2,0.1,0.7];第二个模型对该样本的预测概率为[0.2,0.6,0.2];第三个模型对该样本的预测概率为[0.1,0.7,0.2],假设三个模型的投票权重均为
1
3
\\frac13
31 ,则该样本最终的预测概率为
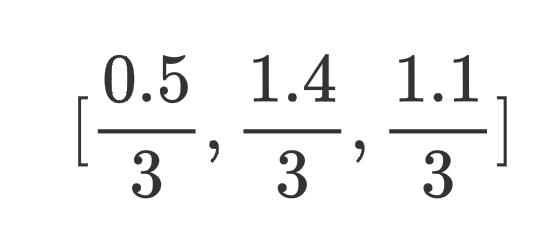
所以最终这个样本被预测为第2类。不过事实上很多时候模型有好有坏,所以我们的权重不一定是平均的,对于模型比较厉害的模型,我们会给他比较大的话语权(投票权重)
Hard Voting
硬投票可以看作是软投票的一个变种,还是以上面三个模型预测的概率分布为例。第一个模型预测样本为第2类,第二、三个模型都认为样本是第2类,根据少数服从多数原则,该样本就被认为是第2类
Bagging
Bagging方法的核心思想是「民主」。首先从训练集中有放回地随机采样一些样本,采样n次,训练出n个弱模型,利用这n个模型采用投票的方式得到分类结果,如果是回归问题则是计算模型输出的均值作为最后的结果
Boosting
Boosting的核心思想是「挑选精英」。Boosting与Bagging最本质的区别在于它对弱模型不是一致对待的,而是经过不停的考验和筛选来挑出「精英」,然后给精英更多的投票权,表现不好的模型则给较少的投票权
PROPOSED METHOD: DEVIL’S ADVOCATE
Training Norm and DevAdv models
无论你是用什么方法做模型融合,至少都需要2个以上的模型。作者提出的方法至少需要3个模型,这些模型会被分成两个阵营:Normal models
(
Norm
n
,
n
≥
2
)
(\\textNorm_n,n≥2)
(Normn,n≥2)、Devil’s Advocate model (DevAdv)
首先我们使用传统的Cross Entropy Loss训练
Norm
n
\\textNorm_n
Normn模型

其中,
Y
Norm
n
\\mathbfY_\\textNorm_n
YNormn是
Norm
n
\\textNorm_n
Normn模型的预测
Y
true
\\mathbfY_\\texttrue
Ytrue是真实标签。与训练
Norm
n
\\textNorm_n
Normn模型相反的是,我们需要随机生成与真实标签不相交的错误标签来训练DevAdv模型(不相交指的是没有任何一个样本的错误标签和真实标签相同),生成的错误标签为
Y
false
\\mathbfY_\\textfalse
Yfalse,DevAdv模型的损失函数定义如下:

由于DevAdv模型是用错误标签训练出来的,所以该模型充当了「魔鬼代言人」的角色,不同意其他模型的预测分布。特别地,我们可以通过检查 ) arg min ( Y DevAdv ) )\\arg \\min (\\mathbfY_\\textDevAdv) )argmin(YDevAdv)是否为真实标签来评估DevAdv模型的性能
注意上面的函数是 arg min \\arg \\min argmin,不是 arg max \\arg \\max argmax,因为求 arg max \\arg \\max argmax很明显预测结果大部分是 Y false \\mathbfY_\\textfalse Yfalse ,但如果真实类别被预测的概率为最小,即通过 arg min \\arg \\min argmin取到,我们就认为DevAdv非常会捣乱
Group Discussion: Fine-tuning
我看到这个标题的时候感觉很奇怪,这又不是预训练模型,怎么会有Fine-tuning阶段?仔细看了他们的代码之后才明白,他这个名字起的不好,不应该叫Fine-tuning,应该叫为Discussing或者Ensembles,即模型融合阶段。具体来说,之前我们已经把所有的模型都训练一遍了,接下来我们需要把DevAdv引入进来再训练一遍
Norm
n
\\textNorm_n
Normn模型。特别地,当前阶段只会更新
Norm
n
\\textNorm_n
Normn模型的参数,DevAdv模型的参数不会进行更新
给我一种感觉就像是:“DevAdv,你已经学会如何抬杠了,快去干扰 Norm n \\textNorm_n Normn他们的讨论吧”
对于
Norm
n
\\textNorm_n
Normn模型来说,此时的损失函数比较特殊
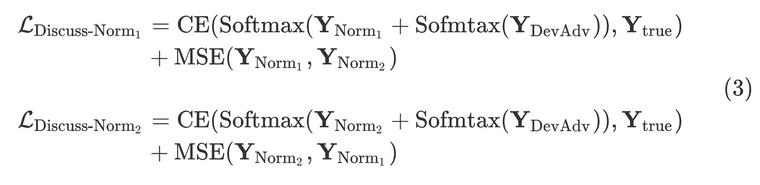
只有DevAdv模型的输出进行了归一化, Norm n \\textNorm_n Normn模型不进行归一化,目的是为了使得 Norm n \\textNorm_n Normn 预测的分布值远大于归一化的DevAdv的值。在CE Loss中,DevAdv模型阻止 Norm n \\textNorm_n Normn模型对真实标签进行正确拟合。但在「Discuss」过程中,即使有DevAdv模型的干扰, Norm n \\textNorm_n Normn模型最终也能正确预测真实标签,主要有以下几个原因:
- DevAdv模型在该阶段是不更新参数的,因此它相当于变成了一个固定的噪声生成器。 Norm n \\textNorm_n Normn模型的参数是会随着损失进行调整的,所以肯定效果会慢慢变好,这是可以预见的
- 非常特别的一点在于 MSE \\textMSE MSE损失。 Norm n \\textNorm_n Normn模型在「Discuss」的过程中会互相影响、学习其他Norm models的信息
最后,对测试集进行测试时,采用软投票的机制组合
Norm
n
\\textNorm_n
Normn 模型的结果。然后…然后就结束了吗?我们辛辛苦苦训练的DevAdv仅仅只是在「Discuss」阶段提供点噪声吗?来点作用啊DevAdv。仔细想一想,最开始在训练DevAdv模型的时候,我们评估它的指标是

我们将
Y
DevAdv
\\mathbfY_\\textDevAdv
YDevAdv内的值全部取负数,并将
arg
min
\\arg \\min
argmin改为
arg
max
\\arg \\max
argmax,它的结果仍然没变

但此时我们就可以让DevAdv一同参与到
Norm
n
\\textNorm_n
Normn模型的测试过程中了,其实就相当于三个模型共同进行软投票,此时预测结果为

RESULTS
这本质是一个模型融合的方法,理论上来说所有模型都是适用的。首先我们看一下消融研究
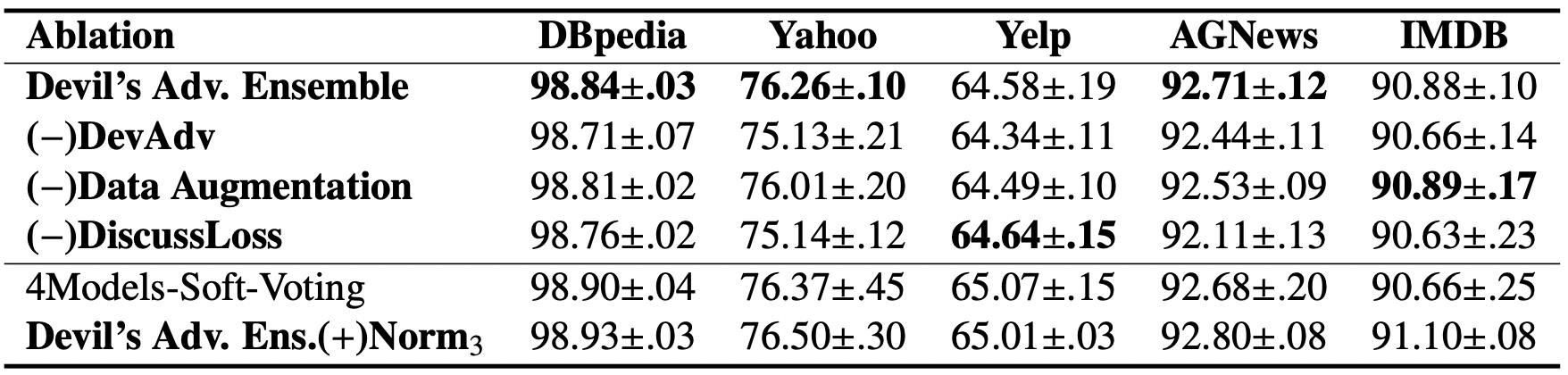
其中比较重要的去掉了DiscussLoss的部分,何谓DiscussLoss,其实就是 Norm n \\textNorm_n Normn模型相互讨论的阶段,即 MSE \\textMSE MSE损失。去掉这部分后,除了Yelp数据集有些反常居然上升了,其他的都有不同程度的下降。同时作者证明他们的方法可以使用超过3个模型的情况,例如最后一行,他们使用了4个模型,其中有3个正常模型,一个DevAdv,效果虽然不如使用3个模型的情况(第一行),但是比常规的软投票还是要好一些,特别地,此时他们使用KL散度来替代MSE损失
接着作者分别采用TextCNN和基于Transformers的模型(论文里就没写到底用的是BERT还是RoBERTa等,如果直接用transformer不太可能,seq2seq的模型如何做分类?)做了一组实验

基本上作者所提出的方法都要比软投票好一些,不过我特别好奇的是硬投票,以及其他的一些模型融合方法为什么不对比下呢?
个人总结
首先我要吐槽的是作者的美感,原论文中的数学公式写的非常丑,基本上感觉是直接用\\text框住然后乱写一通,这里截个图给大家感受下

其次是上图中我红框框出来的部分(下面没有用红框框住的公式也一样),我觉得它这个公式写错了,漏了个 Softmax \\textSoftmax Softmax,可以对比我这篇文章里的公式和他论文中的公式。最后是我觉得比较有意思的地方,因为单看「Discuss」的过程,DevAdv在里面充当的只是捣乱的角色,那为什么我不可以直接采样一个服从 N ( 0 , σ 2 ) \\mathcalN(0, \\sigma^2) N(0,σ2)的向量分布呢,用这个分布直接替换掉 Y DevAdv \\mathbfY_\\textDevAdv YDevAdv ,直到我看到了公式(6),我才明白DevAdv不仅仅是充当一个噪声生成器,实际上在最后Inference阶段,它也可以一起参与进来,而这一点是单纯采样一个向量分布所无法做到的。作者在他的文章中并没有做鲁棒性测试,实际上我觉得引入Devil’s model误导模型训练的过程是可以增加模型的鲁棒性的
以上是关于恒源云_训练一个专门捣乱的模型的主要内容,如果未能解决你的问题,请参考以下文章