三分钟读懂BGP中RD与RT
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三分钟读懂BGP中RD与RT相关的知识,希望对你有一定的参考价值。
参考技术A
Route-Distinguisher(后简称"RD"), Route-Target(后简称"RT")经常出现在EVPN、MPLS VPN中,但它们是完全不同的两个概念,初学者往往难以区分两者的差异。学霸题:区分"RT""RD";有妙招:阅读RFC。两者相关的信息参杂在rfc4364,rfc4760,rfc6074,rfc4761,rfc4271,rfc7432等诸多标准之中。本文将结合具体的示例,简化RFC内容,让你3分钟秒懂"RT""RD"。
如下图所示拓补,用户A(蓝色)和用户B(绿色)在PE-1交换机和PE-2交换机下创建了各自对应的VPN(VRF)。
用户A在PE-1交换机下连的网段是192.168.1.0/24。用户B在交换机PE-1下连网段同样为192.168.1.0/24。在交换机内部,可以通过VPN(VRF)隔离两个路由域,保证即使不同用户创建了重叠的网段,也不会发生网络冲突。
在传统的BGP-4中并没有字段可以存储路由所处的VPN信息。这对在当前场景下如何存储、传递不同租户的拥有相同IP网段的路由信息,如何保证路由信息的唯一性带来了瓶颈。扩展的MP-BGP协议则引入了"RD",与IPv4地址共同构成VPN-IPv4地址解决该瓶颈。
若在VPN-A上配置"RD"为1:1,VPN-B上配置"RD"为2:2,则实际PE-1交换机BGP路由表中存储的信息应如下:
通过在路由条目前添加"RD"前缀,确保BGP 路由表中创建了全局唯一的路由信息,以此实现BGP对等体之间合理地交换路由条目。
RD有三种编码方式。
接踵而来的问题是: PE-2如何知道哪些路由条目属于用户A,哪些路由条目属于用户B?通过设置RD,仅仅确保了路由条目在BGP VPN-IPv4表中的唯一性。当前BGP表中存在的2条路由,看上去仅仅就是前缀信息。解决之道是:使用RT。RT近似于在路由条目上添加的标签。PE-1 为用户A的VPN-A设置 export RT 100:100;PE-2 为用户A的VPN-A设置 import RT 100:100。当PE-1更新VPN-A的路由信息是,输出的条目便添加RT 100:100标签,当 PE-2检视接收到的BGP VPN-IPv4信息条目时,挑出拥有100:100标签的路由条目,写入用户A的VPN中。
RT的编码规范与RD一致。
不得不说一句,规范是规范,具体取何值似乎也因人而异。虽然IETF一直在教人做事,但人往往又不按套路出牌!
图示拓补构建的EVPN VxLAN网络环境,Leaf交换机上与"RD""RT"相关的命令如下所示(以H3C为例)。"RD""RT"的配置存在于vsi及vpn-instance之中。
EVPN地址族是MP-BGP在L2VPN地址族下定义的新的子地址族。新增了5种路由消息。
其中最常用的Type 2 用来通告MAC地址和主机路由信息。Type 3 用来通告VTEP及其相关VXLAN信息,用以实现自动发现VTEP、自动建立VXLAN隧道和自动关联VXLAN与VXLAN隧道。Type 5 用来以IP前缀的形式通告BGP IPv4单播路由或BGP IPv6单播路由。配置中的"RD""RT"就用于控制以上类型路由的生成导出与接收导入。
三分钟读懂朴素贝叶斯算法
我们常常遇到这样的场景。与友人聊天时,一开始可能不知道他要说什么,但是他说了一句话之后,你就能猜到接下来他要讲什么内容。友人给的信息越多,我们越能够推断出他想表达的含义,这也是贝叶斯定理所阐述的思考方式。贝叶斯定理得以广泛应用是因为它符合人类认知事物的自然规律。我们并非生下来就知道一切事情的内在的规律,大多数时候,我们面对的是信息不充分、不确定的情况,这个时候我们只能在有限资源的情况下,作出决定,再根据后续的发展进行修正。
01
朴素贝叶斯登场
贝叶斯分类是一类分类算法的总称,这类算法均以“贝叶斯定理”为基础,以“特征条件独立假设”为前提。而朴素贝叶斯分类是贝叶斯分类中最常见的一种分类方法,同时它也是最经典的机器学习算法之一。在很多场景下处理问题直接又高效,因此在很多领域有着广泛的应用,如垃圾邮件过滤、文本分类与拼写纠错等,同时对于产品经理来说没,贝叶斯分类法是一个很好的研究自然语言处理问题的切入点。
朴素贝叶斯分类是一种十分简单的分类算法,说它十分简单是因为它的解决思路非常简单。即对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。举个形象的例子,若我们走在街上看到一个黑皮肤的外国友人,让你来猜这位外国友人来自哪里。十有八九你会猜是从非洲来的,因为黑皮肤人种中非洲人的占比最多,虽然黑皮肤的外国人也有可能是美洲人或者是亚洲人。但是在没有其它可用信息帮助我们判断的情况下,我们会选择可能出现的概率最高的类别,这就是朴素贝叶斯的基本思想。
值得注意的是,朴素贝叶斯分类并非是瞎猜,也并非没有任何理论依据。它是以贝叶斯理论和特征条件独立假设为基础的分类算法。想要弄明白算法的原理,首先需要理解什么是“特征条件独立假设”以及“贝叶斯定理”,而贝叶斯定理又牵涉到“先验概率”、“后验概率”及“条件概率”的概念,如下图所示,虽然概念比较多但是都比较容易理解,下面我们逐个详细介绍。
特征条件独立假设是贝叶斯分类的基础,意思是假定该样本中每个特征与其他特征之间都不相关。例如在预测信用卡客户逾期的例子中,我们会通过客户的月收入、信用卡额度、房车情况等不同方面的特征综合判断。两件看似不相关的事情实际上可能存在内在联系,就像蝴蝶效应一样。普遍情况下,银行批给收入较高的客户的信用卡额度也比较高。同时收入高也代表这个客户更有能力购买房产,所以这些特征之间存在一定的依赖关系,某些特征是由其他特征决定的。然而在朴素贝叶斯算法中,我们会忽略这种特征之间的内在关系,直接认为客户的月收入、房产与信用卡额度之间没有任何关系,三者是各自独立的特征。
接下来我们重点讲解什么是“理论概率”与“条件概率”,以及“先验概率”与“后验概率”之间的区别。
02
真假概率
首先我们进行一个小实验。假设将一枚质地均匀的硬币抛向空中,理论上,因为硬币的正反面质地均匀,落地时正面朝上或反面朝上的概率都是50%。这个概率不会随着抛掷次数的增减而变化,哪怕抛了10次结果都是正面朝上,下一次是正面朝上的概率仍然是50%。
但在实际测试中,如果我们抛100次硬币,正面朝上和反面朝上的次数通常不会恰好都是50次。有可能出现40次正面朝上和60次反面朝上的情况,也有可能出现35次正面朝上和65次反面朝上的情况。只有我们一直抛,抛了成千上万次,硬币正面朝上与反面朝上的次数才会逐渐趋向于相等。
因此,我们说“正面朝上和反面朝上各有50%的概率”这句话所指的概率是理论上的客观概率。只有当抛掷次数接近无数次时,才会达到这种理想中的概率。在理论概率下,尽管抛10次硬币,前面5次都是正面朝上,第6次是反面朝上的概率仍然是50%。但是在实际中,抛过硬币的人都有这样的感觉,如果出现连续5次正面朝上的情况,下一次是反面朝上的可能性极大,大到什么程度?有没有什么方法可以求出实际的概率呢?
为了解决这个问题,一位名叫托马斯·贝叶斯(ThomasBayes)的数学家发明了一种方法用于计算“在已知条件下,另外一个事件发生”的概率。该方法要求我们先预估一个主观的先验概率,再根据后续观察到的结果进行调整,随着调整次数的增加,真实的概率会越来越精确。这句话怎么理解呢?我们通过一个坐地铁的例子解释这句话的含义。
深圳地铁一号线从车公庙出发至终点站共有18站,每天早上小林要从车公庙出发经过5个站到高新园上班,如下图所示:
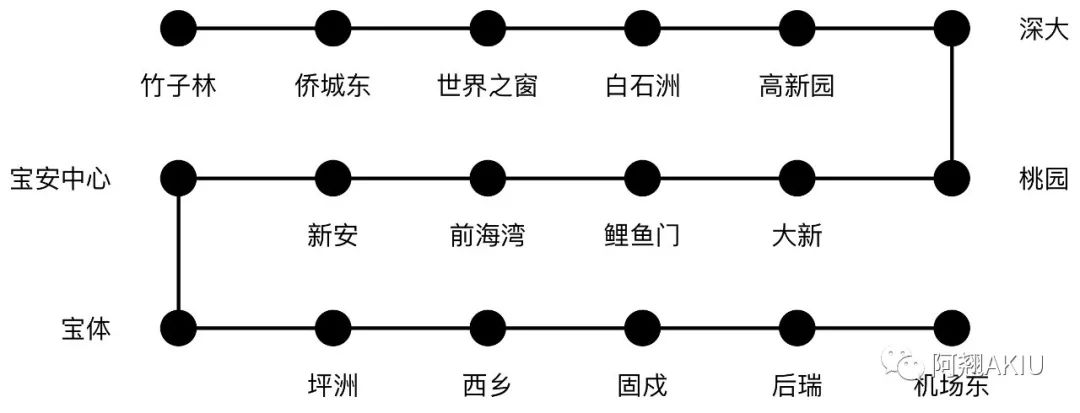
某天早高峰,小林被站立的人群遮挡住视线并且戴着耳机听不到报站的内容,因此他不知道列车是否到达高新园站。如果下一站列车到站时,他直接出站,理论上他正好到高新园站的概率只有1/18,出对站的概率非常小。这时候小林恰巧在人群中看到一个同事,他正走出站台。小林心想,尽管不知道这个同事要去哪里,但在早高峰时段,同事去公司的概率显然更高。因此在获得这个有效信息后,小林跟随出站,正好到达高新园站。这种思考方式就是贝叶斯定理所阐述的思考方式。
03
引入贝叶斯定理
在概率论与统计学中,贝叶斯定理描述了一个事件发生的可能性,这个可能性是基于事先掌握了一些与该事件相关的情况从而推测的。假设癌症是否会发病与每个人的年龄有关,如果使用贝叶斯定理,当我们知道一个人的年龄,可以用于更准确地评估他得癌症是否会发病的概率。也就是说,贝叶斯理论是指根据一个已发生事件的概率,计算另一个事件的发生概率。从数学上贝叶斯理论可以表示为:
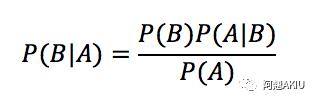
P(B)表示发生B事件的概率,即小林到高新园站的概率;
P(A)表示发生A事件的概率,即小林的同事出站的概率;
P(B|A)表示在A事件已经发生的情况下B事件会发生的概率,即同事出站的时候,小林正好到高新园站的概率;
P(A|B)表示在B事件已经发生的情况下A事件会发生的概率,即小林到达高新园站,同事出站的概率;
这时候我们再来看贝叶斯定理,这个公式说明了两个互换的条件概率之间的关系,它们通过联合概率关联起来。在这种情况下,若知道P(A|B) 的值,就能够计算P(B|A)的值。因此贝叶斯公式实际上阐述了这么一个事情,如下图所示:
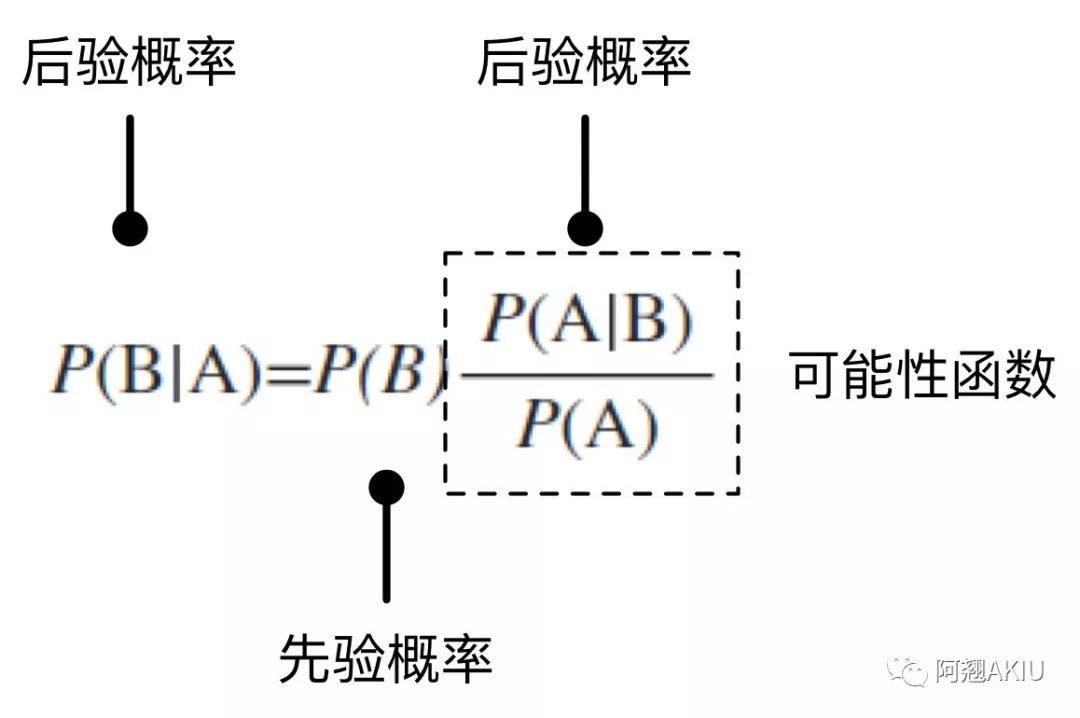
我们可以用文氏图可以加深对贝叶斯定理的理解,如下图所示:
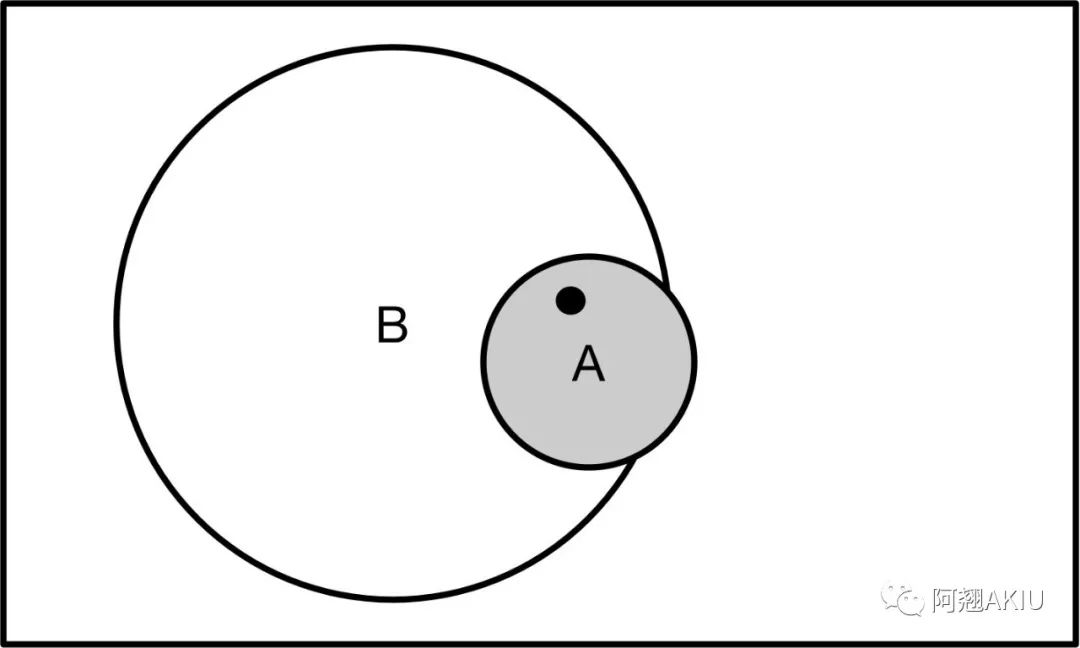
上述例子中小林刚好在早高峰时段看到同事出站,代表出现了新的信息。就像是上图中已知黑点已经落入A区域了,由于A区域大部分区域与B区域相交,因此推断黑点也在B区域的概率会变大。我们想获得的结果其实是P(B|A),即我们想知道,在考虑了一些现有的因素后,这个随机事件会以多大概率出现。参考这个概率结果,在很多事情上我们可以有针对性地作出决策。
我们需要同时知道P(B)、P(A|B)与P(A)才能算出目标值P(B|A),但是P(A)的值似乎比较难求。仔细想一想,P(A)与P(B)之间似乎没有任何关联,两者本身就是独立事件,无论P(B)的值是大还是小,P(A)都是固定的分母。也就是说我们计算P(A)各种取值的可能性并不会对各结果的相对大小产生影响,因此可以忽略P(A)的取值。假设P(A)的取值为m,P(B)的可能取值为b1、b2或者是b3,已知:
且由于P(b1|A)、P(b2|A)与P(b3|A)三者之和一定为1,因此可以得出ox+py+qz=m。即使m的值不知道也没关系,因为ox,py,qz的值都是可以计算出来的,m自然也就知道了。剩下的工作就是计算P(B)、P(A|B),而这两个概率必须要通过我们手上有的数据集来进行估计。
关于贝叶斯算法有一段小插曲。贝叶斯算法被发明后,曾有接近200年的时间无人问津。因为经典统计学在当时完全能够解决客观上能够解释的简单概率问题,而且相比需要靠主观判断的贝叶斯算法,显然当时的人们更愿意接受建立在客观事实上的经典统计学,他们更愿意接受一个硬币无论抛多少次后正反面朝上的概率都是50%的事实。
但我们生活中还存在很多无法预知概率的复杂问题,例如台风侵袭、地震规律等等。经典统计学在面对复杂问题时,往往无法获得足够多的样本数据,导致其无法推断总体规律。总不能说每天预测台风来的概率都是50%,只有来或者不来两种情况。数据的稀疏性令贝叶斯定理频频碰壁,随着近代计算机技术的飞速发展后,数据的大量运算不再是困难的事情,贝叶斯算法这才被人们重新重视起来。
04
贝叶斯定理有什么用
讲到这里部分读者可能会问,虽然贝叶斯定理模拟了人类思考的过程,但是它又能够帮助我们解决什么样的问题呢?我们先来看一个几乎是讲到贝叶斯定理时必定会提到的经典案例。
在疾病检测领域,假设某种疾病在所有人群中的感染率是0.1%,医院现有的技术对于该疾病检测准确率能够达到99%。也就是说,在已知某人已经患病情况下,有99%的可能性检查出阳性;而正常人去检查有99%的可能性是正常的,如果从人群中随机抽一个人去检测,医院给出的检测结果为阳性,这个人实际得病的概率是多少?
也许很多读者都会脱口而出 "99%"。但真实的得病概率其实远低于此,原因在于很多读者将先验概率和后验概率搞混了。如果用A表示这个人患有该疾病,用B表示医院检测的结果是阳性,那么 P(B|A)=99%表示的是“已知一个人已经得病的情况下医院检测出阳性的概率”,而我们现在问的是“对于随机抽取的这个人,已知检测结果为阳性的情况下这个人患病的概率”,即P(A|B),通过计算可得P(A|B)=9%。所以即使被医院检测为阳性,实际患病的概率其实还不到10%,有很大可能是假阳性。因此需要通过复诊,引入新的信息,才有更大的把握确诊。通过以上例子可以看出,生活中我们经常会把先验概率与后验概率弄混淆,从而得出错误的判断,贝叶斯定理正是帮我们理清概率的先后条件之间的逻辑关系,并得到更精确的概率。
实际上,这个定理所阐述的核心思想对产品经理的思考方式也有很大的启发,一方面是我们要搞清楚需求场景中的先验概率是什么?
后验概率是什么?
不要被数据的表象蒙蔽了双眼;
另一方面我们可以借助贝叶斯定理搭建一个思考的框架,在这个框架中需要不断的调整我们对某事物的看法,在经过一系列的新的事情被证实后,才形成比较稳定、正确的看法。
当我们的脑子里有新想法出现时,大多数情况下,我们只能根据经验大概判断某个产品靠谱不靠谱。投入到市场中反响有多大没有人能够说清楚,因此很多时候我们需要尝试,需要做一个简单的版本投入到市场上快速验证自己的想法,然后不断想办法获得“事件B”,不断增加新产品的成功率,这样我们的产品才有可能获得成功。因此“小步快跑,快速迭代”才是提升容错率最好的办法。
(1)以上内容是《产品经理进阶:100个案例搞懂人工智能》第六章的节选,如果你对这本书有兴趣,可以直接点击下方阅读原文,或在京东、当当等商城直接搜索书名。
(2)上一期送书活动已开奖,请 Anna晴、Niko、Wo、高文静、阿震 这五位同学主动联系我领书。后续还会有不定期的送书活动。
以上是关于三分钟读懂BGP中RD与RT的主要内容,如果未能解决你的问题,请参考以下文章
关于mpls-bgp中RD和RT的问题,求解
三分钟读懂热门 NFT卡牌游戏Xpanda
三分钟读懂Solar Period链游
三分钟读懂:云计算与虚拟化的关系
mybatis中resultMap和resultType区别,三分钟读懂
三分钟读懂朴素贝叶斯算法