关于爬虫爬不到数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于爬虫爬不到数据相关的知识,希望对你有一定的参考价值。
请大家帮我看下为什么这个代码爬不到数据啊?
# -*- coding: utf-8 -*-
import time
import re
import json
from start.loan import Loan
from scrapy.spider import Spider
from scrapy.selector import Selector
from start.items import LoanItem
class hepaiSpider(Spider):
name = "hepai"
allowed_domains = ["he-pai.cn"]
start_urls = [
"http://www.he-pai.cn/investmentDetail/investmentDetails/index.do"
]
def parse(self, response):
sel = Selector(response)
items = []
loan =Loan()
sites = sel.xpath("//div[@class='tabs_con']")
for site in sites:
item = LoanItem()
item['company_name'] = '合拍在线'
item['title'] = site.xpath("/table[@class='tzlb']/a/text()").extract()
item['rate'] = site.xpath("//table/tbody/tr/td[2]/text()").extract()
item['amount'] = site.xpath("//table/tboday/td[3]/text()").extract()
item['public_time'] = site.xpath("//table/tbody/td[4]/text()").extract()
item['process'] = site.xpath("//table/tbody/td[5]/div/div[1]/@style").extract()
item['period'] = site.xpath("//table/tbody/td[6]/text()").extract()
items.append(item)
return items;
---------------------------------------分割线-------------------------------------------------------------
crawl以后是这样子
6 14:00:30+0800 [hepai] DEBUG: Scraped from <200 http://www.he-pai.cn/investmentDetail/investmentDetails/index.do>
'amount': [],
'company_name': '\xe5\x90\x88\xe6\x8b\x8d\xe5\x9c\xa8\xe7\xba\xbf',
'period': [],
'process': [],
'public_time': [],
'rate': [],
'title': []
Python爬虫:为什么你爬取不到网页数据
前言:
之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:https://liuze.blog.csdn.net/article/details/105965562),但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发布一篇关于爬虫爬取不到数据文章,希望各位读者更加了解爬虫。

1. 最基础的爬虫
通常编写爬虫代码,使用如下三行代码就可以实现一个网页的基本访问了。
from urllib import request
rsp = request.urlopen(url='某某网站')
print(rsp.read().decode('编码'))
或者
import requests
rsp = requests.get(url='某某网站')
print(rsp.text)
但是,有的网站你使用上述方式访问时,有可能出现一下情况:
- 直接报错;
- 没有报错,但是给出相应的响应码,如403;
- 没有报错,但是输出信息没有在浏览器上看到的那么多(这有可能是网页使用了动态加载的原因)。
2. 添加请求头的爬虫
上述讲到的三种情况,怎样解决呢?基本方式是添加一个请求头(请求头的字段通常只需添加user-agent字段即可,用来模拟浏览器访问;然而有的网站用Python爬虫来访问时,可能还要添加其他字段,最好是把这个网页所有请求头字段信息全部添加上;有的网页全部请求头字段信息全部添加上,然而也访问不到数据,这种情况小编也没有什么好的解决办法,不知道使用selenium模块直接操控浏览器是否可以,没有试过)。
- 如用urllib模块来访问bilibili网站时会报错,如下:
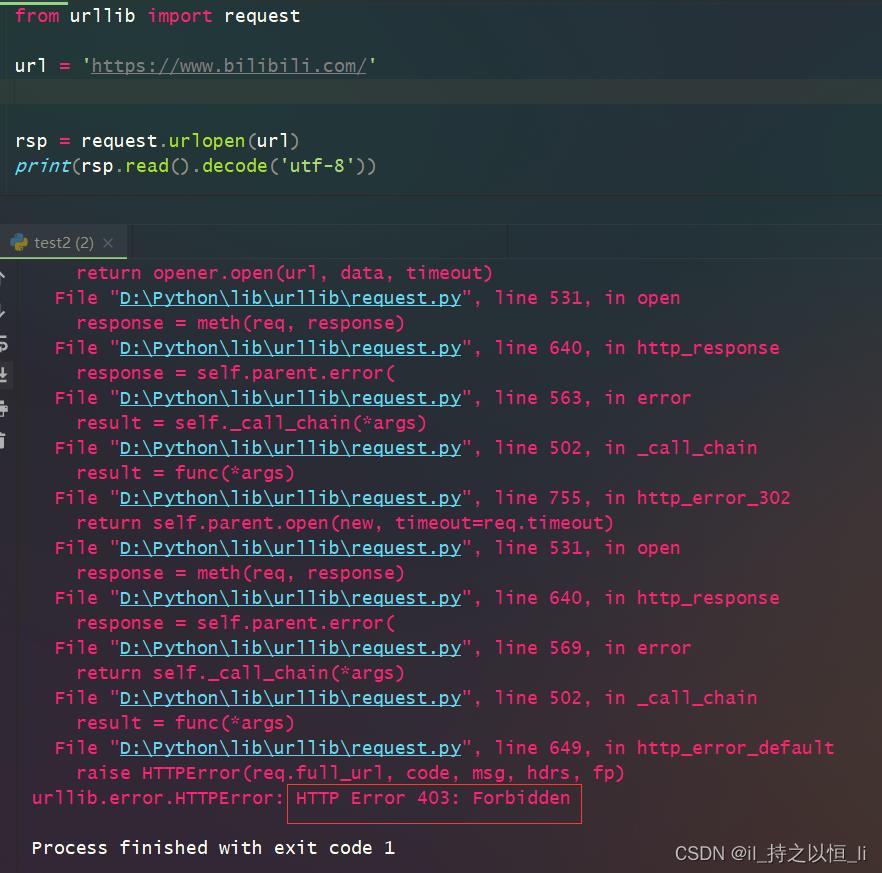
但是添加请求头之后,就可以正常访问了。
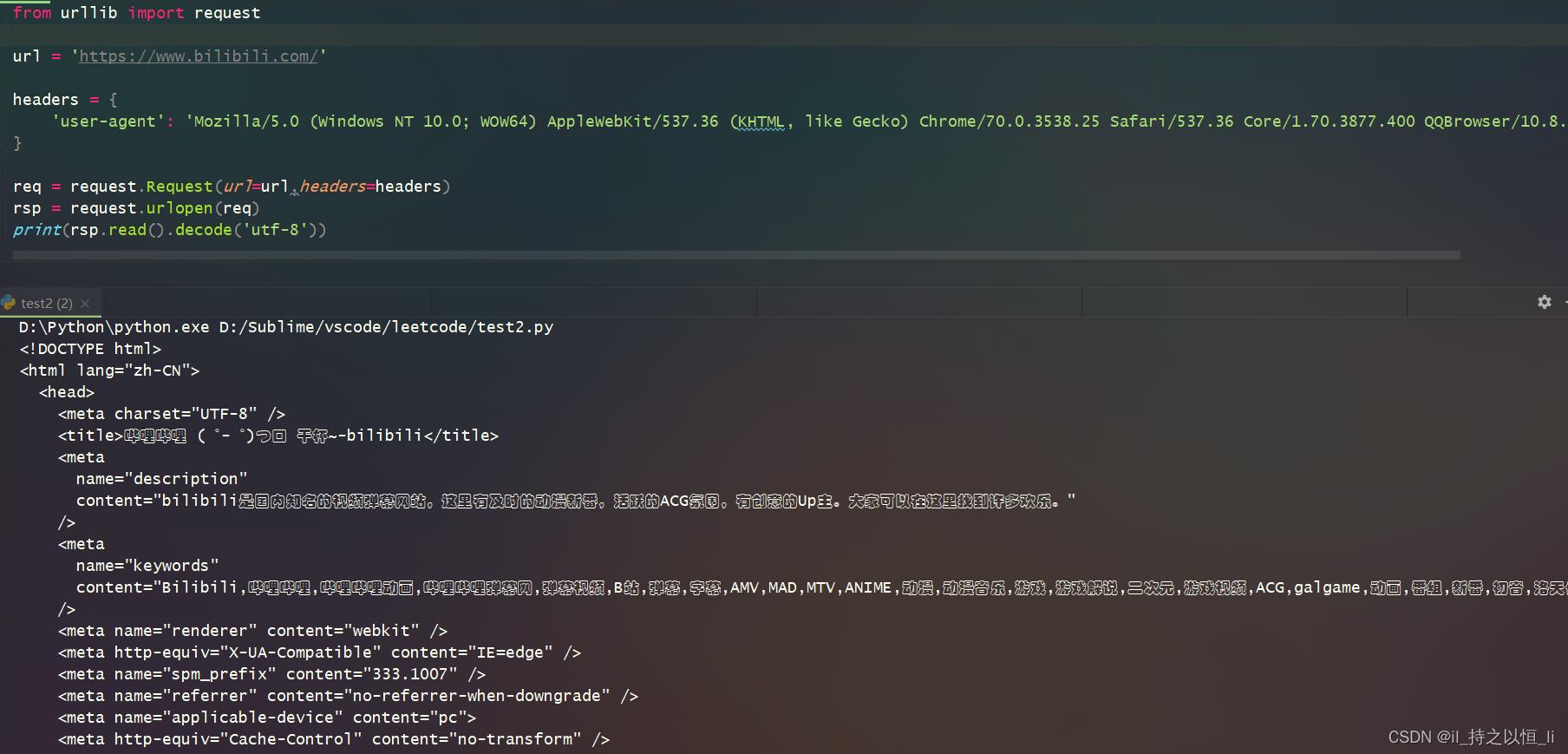
参考代码如下:
from urllib import request
url = 'https://www.bilibili.com/'
headers =
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4507.400'
req = request.Request(url=url,headers=headers)
rsp = request.urlopen(req)
print(rsp.read().decode('utf-8'))
- 如用urllib模块来访问百度网站时会出现如下情况:

很显然,这个网页不可能就这么点代码标签,添加一个请求头之后,如下:
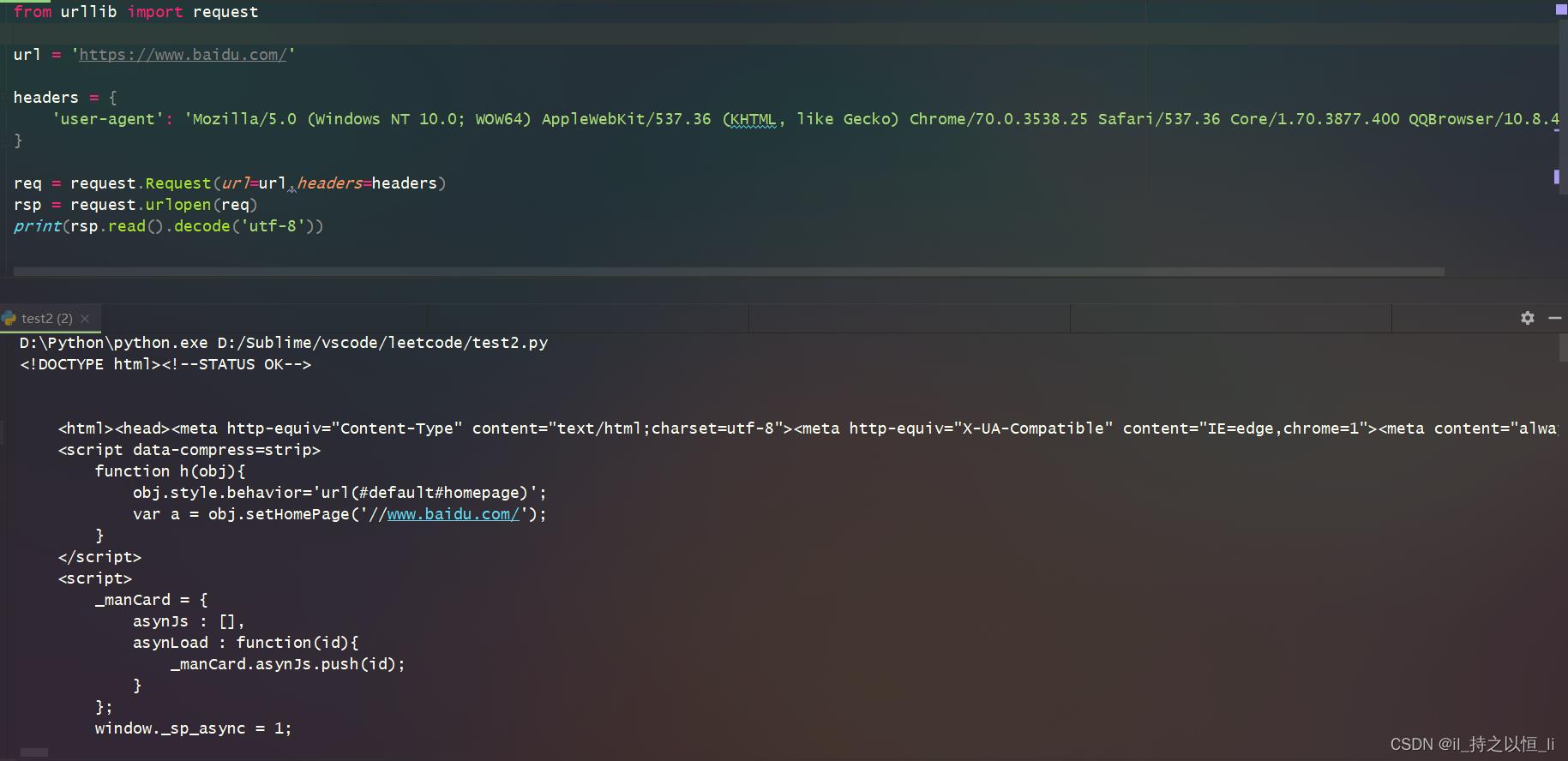
3. 动态网页加载的数据
提到动态网页,读者首先可以去看看小编的这篇文章:Python爬虫:什么是静态网页(数据),什么是动态网页(数据),小编学习过后端知识,大体知道为什么用上述方式访问不到相应的数据。why(大概是这样吧!也有可能讲的不对,希望读者指正[如果有错误的话],一般而言,我们用爬虫爬取得到的数据是当前网页已经完全加载的,然而动态网页使用了ajax技术,而执行者一段ajax代码好像是网页完全加载之后才执行的,因此你用爬虫爬取不到那部分数据。)
此时,你有两种解决方式:
- 找到这个ajax的相关网页链接,访问这个链接,从而得到相关数据;
- 直接使用selenium这个模块,操作浏览器访问。
如果读者使用第1种解决方式,有可能你访问的那个链接一些参数是加密的,这时你需要利用js断点(使用谷歌浏览器),找到那段加密参数加密之前的数据信息和相关的一些js加密函数,找到加密之前的数据信息的组合规则。关于js加密函数,如果简单的话,直接用Python模拟出加密效果即可;如果复杂的话,最好使用execjs或者其他Python模块下的一些方法去执行这些js加密函数。
上述关于使用第1种解决方式,小编过去做过的有Python爬虫爬取酷狗音乐、网易云音乐、斗鱼视频等。有兴趣的读者可以去看看小编的爬虫专栏,链接为:https://blog.csdn.net/qq_45404396/category_9687415.html,当然,有一些文章发表在博客园,博客主页为:https://www.cnblogs.com/liuze-2/
4. 总结
有的读者也许会问,如果我ip封掉了,怎样爬取网页数据,其实,使用相关ip代理即可,读者可以去看看小编的爬虫专栏,里面有讲ip代理的相关文章。另外,还有一些高大上的反爬措施,小编并不是很了解,就不在这一一赘述了,如果未来小编真的了解到了,到时候再在本文章后加上吧!
以上是关于关于爬虫爬不到数据的主要内容,如果未能解决你的问题,请参考以下文章