python 爬取 CSDN 用户粉丝总数粉丝用户名昵称和粉丝ID
Posted Love丶伊卡洛斯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬取 CSDN 用户粉丝总数粉丝用户名昵称和粉丝ID相关的知识,希望对你有一定的参考价值。
前言
python版本:python3.9.7
开发环境:Anaconda + pycharm
相关库:
实现逻辑讲解
1、获取总粉丝数
请求地址:https://blog.csdn.net/你的用户名/article/list/
用BeautifulSoup解析返回的html,检索id=“fanBox”,得到粉丝总数
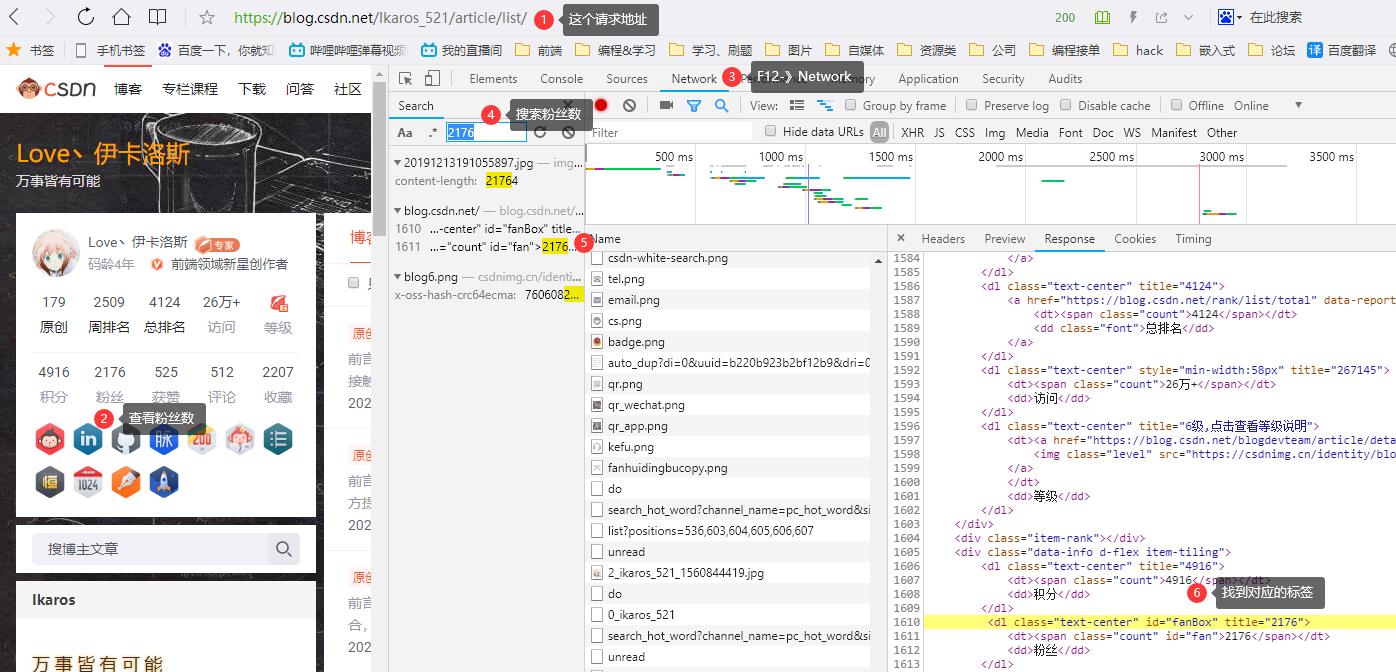
2、找到粉丝信息API
访问地址:https://blog.csdn.net/你的用户名?type=sub&subType=fans
粉丝信息API:https://blog.csdn.net/community/home-api/v2/get-fans-list?page=页数&pageSize=20&id=上一页最后一个粉丝的id&noMore=false&blogUsername=你的用户名
需要注意的就是id这个参数第一次传0,后面改为上一页的最后一个粉丝的id

3、解析返回的json串,存入数据库
sqlite数据库构建 CREATE TABLE IF NOT EXISTS user(username TEXT, nickname TEXT, id TEXT PRIMARY KEY)

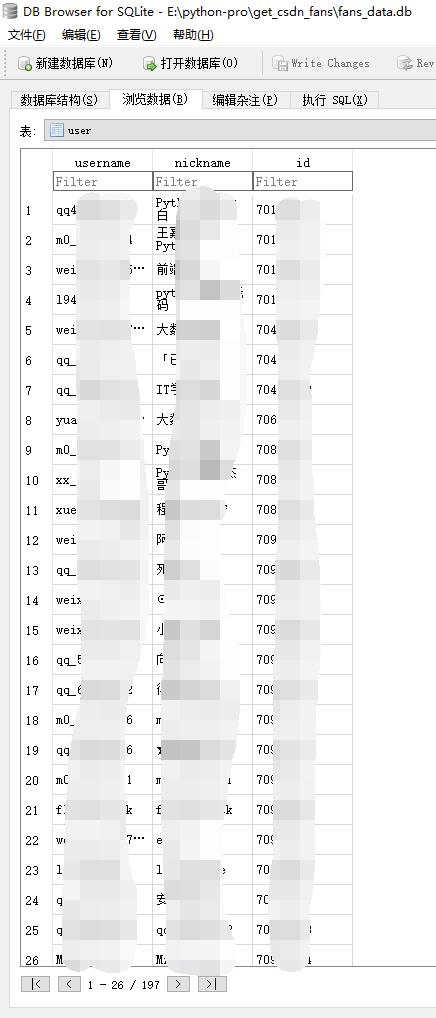
效果图

源码
# -*- coding: utf-8 -*-
import json
import time
import urllib.request
import urllib.parse
import sqlite3
from bs4 import BeautifulSoup
# https://blog.csdn.net/你的用户名?type=sub&subType=fans
# 获取抽奖类型
blogUsername = input("请输入你的博客名(个人主页链接后的字符串):")
referer = "https://blog.csdn.net/" + blogUsername + "?type=sub&subType=fans"
# 请求头
headers1 =
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'text/plain;charset=UTF-8',
'Referer': referer,
# 'origin': 'https://blog.csdn.net',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3875.400 QQBrowser/10.8.4492.400'
# 配置数据库
def config_db():
global con, cur
con = sqlite3.connect("fans_data.db")
cur = con.cursor()
# 创建表user
sql = "CREATE TABLE IF NOT EXISTS user(username TEXT, nickname TEXT, id TEXT PRIMARY KEY)"
cur.execute(sql)
# 清空表数据
sql = "delete from user"
cur.execute(sql)
# 获取粉丝列表
def get_fans_list(page, last_id):
# 根据API,传入对应参数
payload = 'page': page, 'pageSize': '20', 'id': last_id, 'noMore': 'false', 'blogUsername': blogUsername
data = urllib.parse.urlencode(payload)
# https://blog.csdn.net/community/home-api/v2/get-fans-list?page=0&pageSize=20&id=上一页最后一个粉丝的ID&noMore=false&blogUsername=你的用户名
_url = urllib.request.Request('https://blog.csdn.net/community/home-api/v2/get-fans-list?%s' % data,
headers=headers1)
response = urllib.request.urlopen(_url, None, 10)
ret = response.read().decode()
# print(ret)
json1 = json.loads(ret)
# 返回code 和 最后一位粉丝的id
return_data = 'code': json1["code"], 'id': 0
if json1["code"] == 200:
for i in range(len(json1["data"]["list"])):
temp_username = json1["data"]["list"][i]["username"]
temp_nickname = json1["data"]["list"][i]["nickname"]
temp_id = json1["data"]["list"][i]["id"]
return_data["id"] = temp_id
# 数据插入数据库
sql = "replace into user(username, nickname, id) values (?, ?, ?)"
cur.execute(sql, (temp_username, temp_nickname, temp_id))
con.commit()
else:
print('获取失败,code:' + str(json1["code"]))
return return_data
# 获取用户粉丝数,调用粉丝信息获取
def get_user_info():
print("开始获取粉丝数...")
# 请求文章页面 获取粉丝数
req = urllib.request.urlopen('https://blog.csdn.net/' + blogUsername + '/article/list/')
ret = req.read().decode()
# print(ret)
# 创建 beautifulsoup 对象
soup = BeautifulSoup(ret, features='html.parser')
# print(soup.select('#fanBox'))
# 根据id定位到粉丝数所在标签
fans_num = soup.select('#fanBox')[0]['title']
print('粉丝数:' + fans_num)
# 记录上一页最后一个粉丝的id
last_id = 0
# 根据粉丝数转页数进行循环
for i in range(int((int(fans_num) - 1) / 20) + 1):
print('开始获取第' + str(i + 1) + '页粉丝信息(20/页)...')
return_data = get_fans_list(i, last_id)
last_id = return_data["id"]
time.sleep(0.5)
# 配置数据库
config_db()
# 获取用户粉丝数,调用粉丝信息获取
get_user_info()
# 关闭游标
cur.close()
# 断开数据库连接
con.close()
print("\\n程序运行完毕!")
以上是关于python 爬取 CSDN 用户粉丝总数粉丝用户名昵称和粉丝ID的主要内容,如果未能解决你的问题,请参考以下文章
python 爬取 CSDN 用户粉丝总数粉丝用户名昵称和粉丝ID