万粉博主为CSDN增加粉丝数据分析模块硬核
Posted Jack·Kwok
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万粉博主为CSDN增加粉丝数据分析模块硬核相关的知识,希望对你有一定的参考价值。
万粉博主为CSDN增加粉丝数据分析模块【硬核】

1. 写在前面
截止2021年6月13日,我的CSDN个人账号终于突破1w粉丝啦!
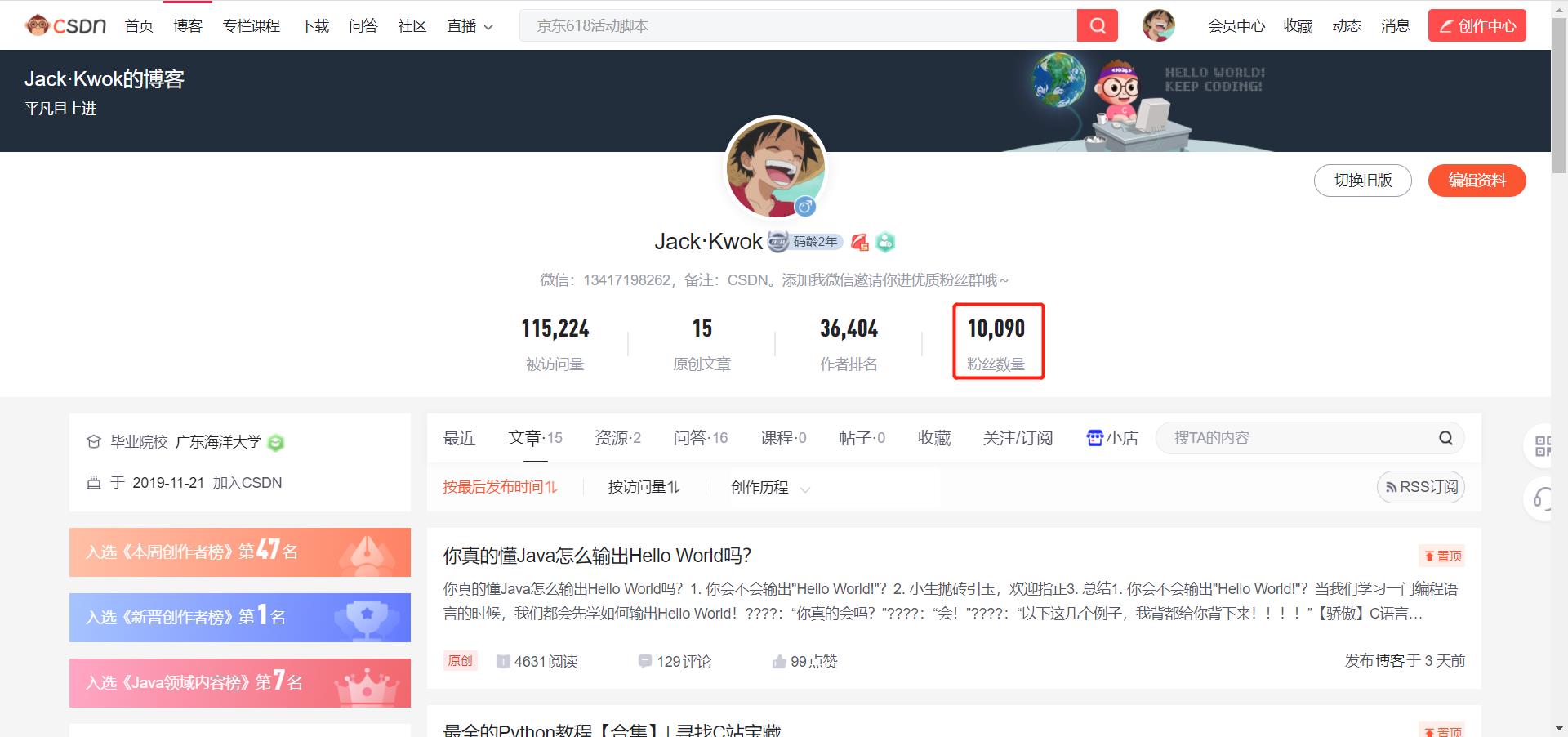
做为一个创作不到 一个月的博主来说,我知道我的作品还不多,但能够收获这么多粉丝真的很意外,小J会继续加油哒!既然今天突破1万粉丝,那么我就在想能不能做一点值得纪念的事情。于是我就有了一个想法——将1w个粉丝的基本信息存到一张表格里面。
2. 数据准备
2.1. 博客主页面
目标链接为本人博客主页的粉丝页面
https://blog.csdn.net/PaperJack?type=sub&subType=fans
通过对网页的分析,我们发现粉丝的信息就藏在这个下图这个url中,并且以分页的json格式数据返回给前端,每一页的数量为20,根据粉丝的总数动态分布页数。
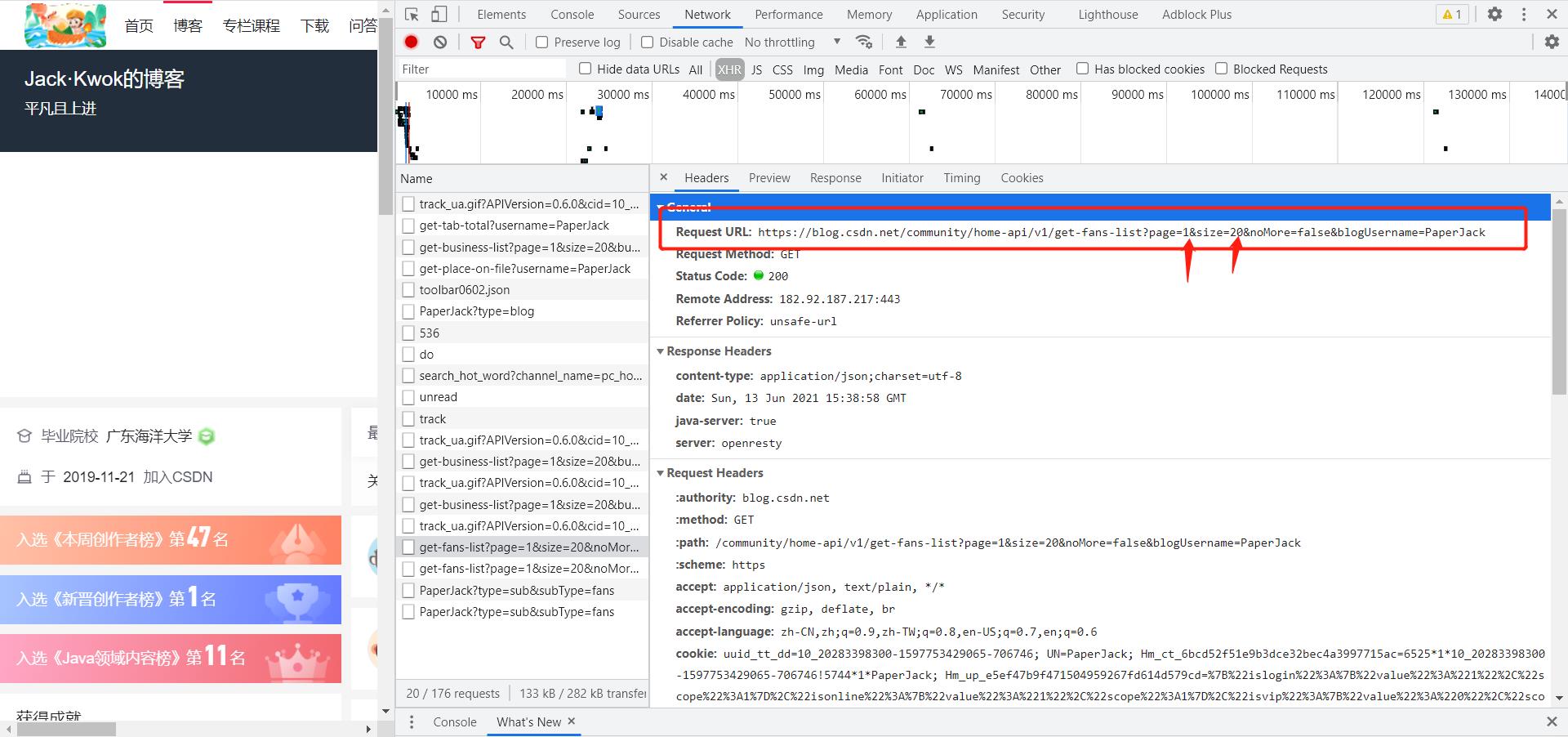
图中标出的数据即为我最新的一个粉丝的具体信息。
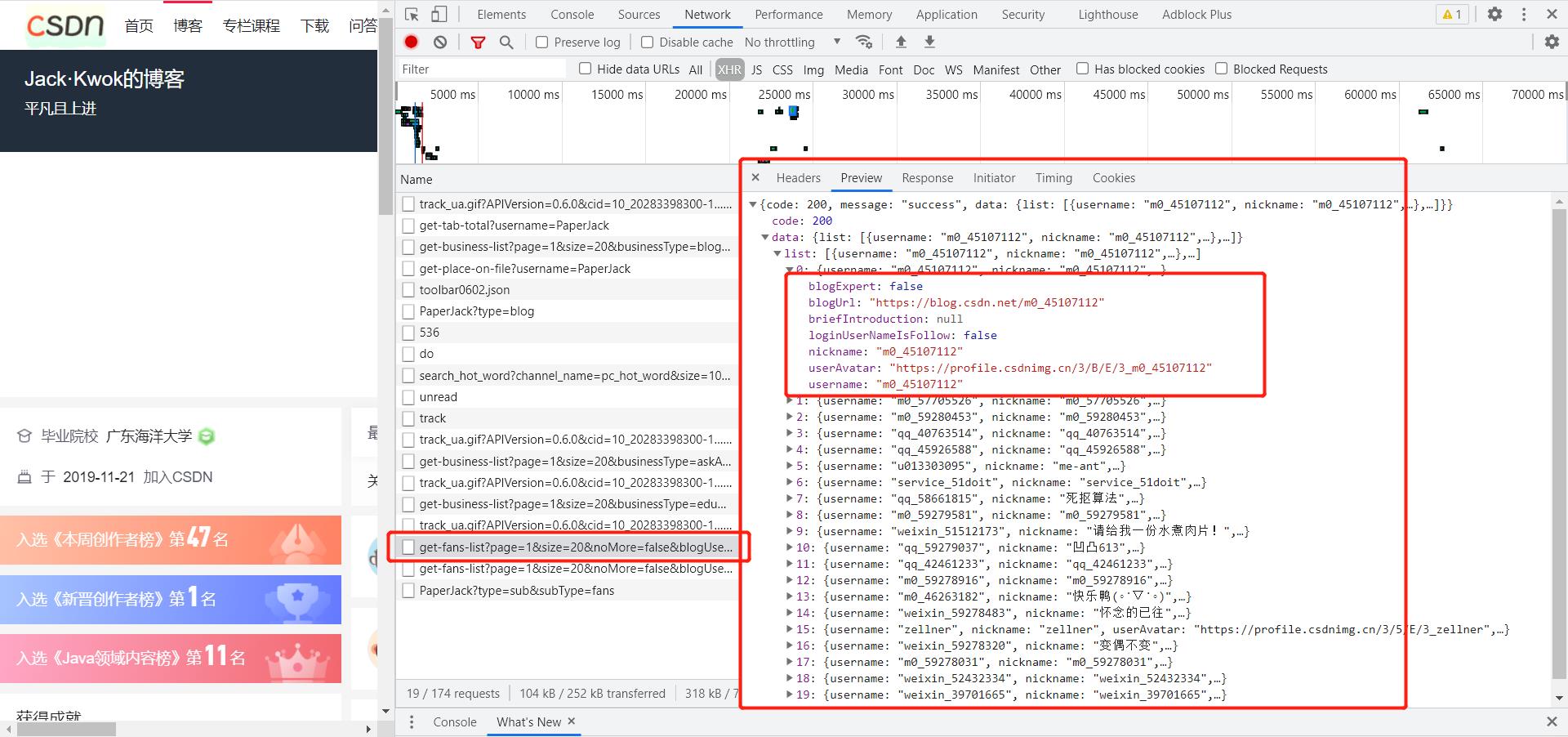
关于如何爬取信息以及如何将信息存储到Excel中,更加详细的过程可以查看我的一下文章
使用Python爬取一个网页并解析
(截止写该篇文章时已获得1w+浏览)
【干货】建议收藏!!全网最完整的Python操作Excel数据封装函数(截止写该篇文章时已获得955收藏)
2.2. 粉丝主页面(多个)
目标链接为本人博客主页粉丝的每一个主页
当我们爬取了主页面的粉丝数据的时候,我们缺少了粉丝数据中最为关键的一部分信息——粉丝的性别和码龄。这一部分信息对我个人而言是有用的,对CSDN的用户群体分析也是有一定的价值的(毕竟1万虽然不多,但也足够反应真实情况)。
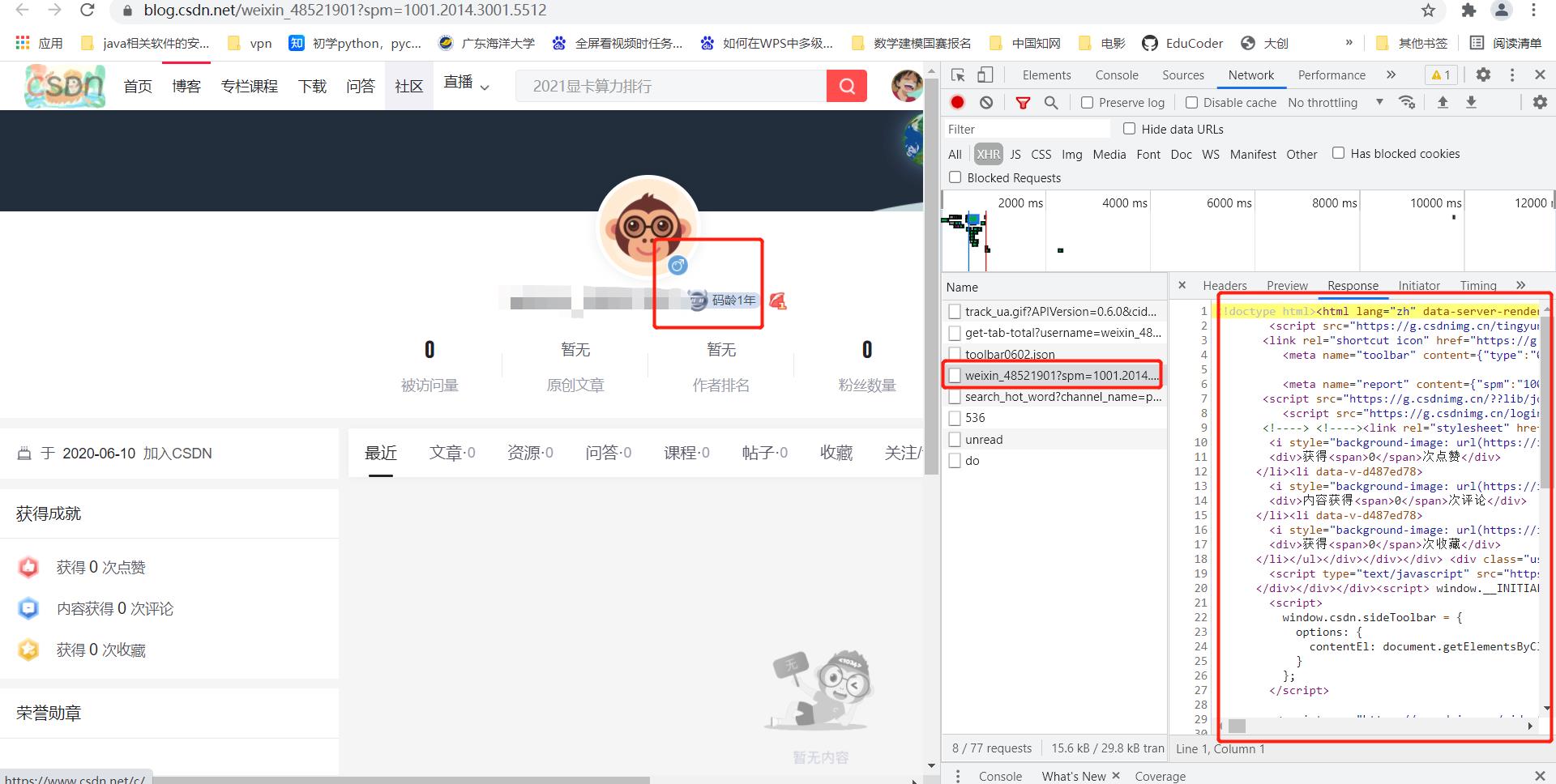
同样将数据爬取之后放到同一个Excel中
3. 代码展示
3.1. 爬取博客主页面粉丝数据
import openpyxl
import requests
from lxml import etree
def i_love_CSDN(CSDN_id, fans_nums):
# 目标Url
url = "https://blog.csdn.net/community/home-api/v1/get-fans-list"
# 模拟浏览器
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/89.0.4389.114 Safari/537.36"
}
# 根据粉丝数目设置总页数
if fans_nums % 20 == 0:
page_nums = fans_nums // 20
else:
page_nums = (fans_nums // 20) + 1
# 总数据
bli = []
# 单条数据
li = []
# 设置第一行的中文标题
li.append("是否为博客专家")
li.append("博客链接")
li.append("博客自我简介")
li.append("我是否关注该用户")
li.append("昵称")
li.append("头像")
li.append("用户名")
bli.append(li)
# 循环访问每一页
for i in range(1,page_nums):
params = {
"page": i,
"size": 20,
"noMore": "false",
"blogUsername": CSDN_id
}
resp = requests.get(url, headers=headers, params=params)
js = resp.json()
infos = js['data']['list']
# 解析到访问后的数据
for info in infos:
li = []
blogExpert = info['blogExpert']
blogUrl = info['blogUrl']
briefIntroduction = info['briefIntroduction']
loginUserNameIsFollow = info['loginUserNameIsFollow']
nickname = info['nickname']
userAvatar = info['userAvatar']
username = info['username']
li.append(blogExpert)
li.append(blogUrl)
li.append(briefIntroduction)
li.append(loginUserNameIsFollow)
li.append(nickname)
li.append(userAvatar)
li.append(username)
bli.append(li)
# 打印测试数据
print(li)
return bli
# 写入Excel
def write_xlsx_excel(url, sheet_name, two_dimensional_data):
# 创建工作簿对象
workbook = openpyxl.Workbook()
# 创建工作表对象
sheet = workbook.active
# 设置该工作表的名字
sheet.title = sheet_name
# 遍历表格的每一行
for i in range(0, len(two_dimensional_data)):
# 遍历表格的每一列
for j in range(0, len(two_dimensional_data[i])):
# 写入数据(注意openpyxl的行和列是从1开始的,和我们平时的认知是一样的)
sheet.cell(row=i + 1, column=j + 1, value=str(two_dimensional_data[i][j]))
# 保存到指定位置
workbook.save(url)
print("写入成功")
if __name__ == '__main__':
# 参数为CSDN的ID和当前粉丝数量
bli = i_love_CSDN('PaperJack',10212)
# 参数为文件路径、表格名称和将要写入的数据
write_xlsx_excel("D:\\myfans.xlsx",'sheet1',bli)
# 提示操作成功
print("over...")
3.2. 爬取粉丝主页面粉丝数据
import openpyxl
import requests
from lxml import etree
def i_love_CSDN(CSDN_id, fans_nums):
# 目标Url
url = "https://blog.csdn.net/community/home-api/v1/get-fans-list"
# 模拟浏览器
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36"
}
# 根据粉丝数目设置总页数
if fans_nums % 20 == 0:
page_nums = fans_nums // 20
else:
page_nums = (fans_nums // 20) + 1
# 总数据
bli = []
# 单条数据
li = []
# 设置第一行的中文标题
li.append("是否为博客专家")
li.append("博客链接")
li.append("码龄")
li.append("性别")
li.append("博客自我简介")
li.append("我是否关注该用户")
li.append("昵称")
li.append("头像")
li.append("用户名")
bli.append(li)
# 循环访问每一页
for i in range(1,page_nums):
params = {
"page": i,
"size": 20,
"noMore": "false",
"blogUsername": CSDN_id
}
resp = requests.get(url, headers=headers, params=params)
js = resp.json()
infos = js['data']['list']
# 解析到访问后的数据
for info in infos:
li = []
blogExpert = info['blogExpert']
blogUrl = info['blogUrl']
resps = requests.get(blogUrl,headers = headers)
tree1 = etree.HTML(resps.text)
codeAge = tree1.xpath("/html/body/div[1]/div/div[1]/div/div/div/div/div/div[1]/div[2]/div[2]/div/div[2]/span/text()")[0]
gender = tree1.xpath("/html/body/div[1]/div/div[1]/div/div/div/div/div/div[1]/div[2]/div[1]/div[1]/i/@class")[0]
if gender == 'user-gender-male':
gender = '男'
elif gender == 'user-gender-female':
gender = '女'
else:
gender = "其他"
briefIntroduction = info['briefIntroduction']
loginUserNameIsFollow = info['loginUserNameIsFollow']
nickname = info['nickname']
userAvatar = info['userAvatar']
username = info['username']
li.append(blogExpert)
li.append(blogUrl)
li.append(codeAge)
li.append(gender)
li.append(briefIntroduction)
li.append(loginUserNameIsFollow)
li.append(nickname)
li.append(userAvatar)
li.append(username)
bli.append(li)
# 打印测试数据
print(li)
return bli
# 写入Excel
def write_xlsx_excel(url, sheet_name, two_dimensional_data):
# 创建工作簿对象
workbook = openpyxl.Workbook()
# 创建工作表对象
sheet = workbook.active
# 设置该工作表的名字
sheet.title = sheet_name
# 遍历表格的每一行
for i in range(0, len(two_dimensional_data)):
# 遍历表格的每一列
for j in range(0, len(two_dimensional_data[i])):
# 写入数据(注意openpyxl的行和列是从1开始的,和我们平时的认知是一样的)
sheet.cell(row=i + 1, column=j + 1, value=str(two_dimensional_data[i][j]))
# 保存到指定位置
workbook.save(url)
print("写入成功")
if __name__ == '__main__':
# 参数为CSDN的ID和当前粉丝数量
bli = i_love_CSDN('PaperJack',10246)
# 参数为文件路径、表格名称和将要写入的数据
write_xlsx_excel("D:\\myfans.xlsx",'sheet1',bli)
# 提示操作成功
print("over...")
4. 数据分析及可视化
主页面数据正在爬取的过程
添加了粉丝性别和码龄的爬取过程
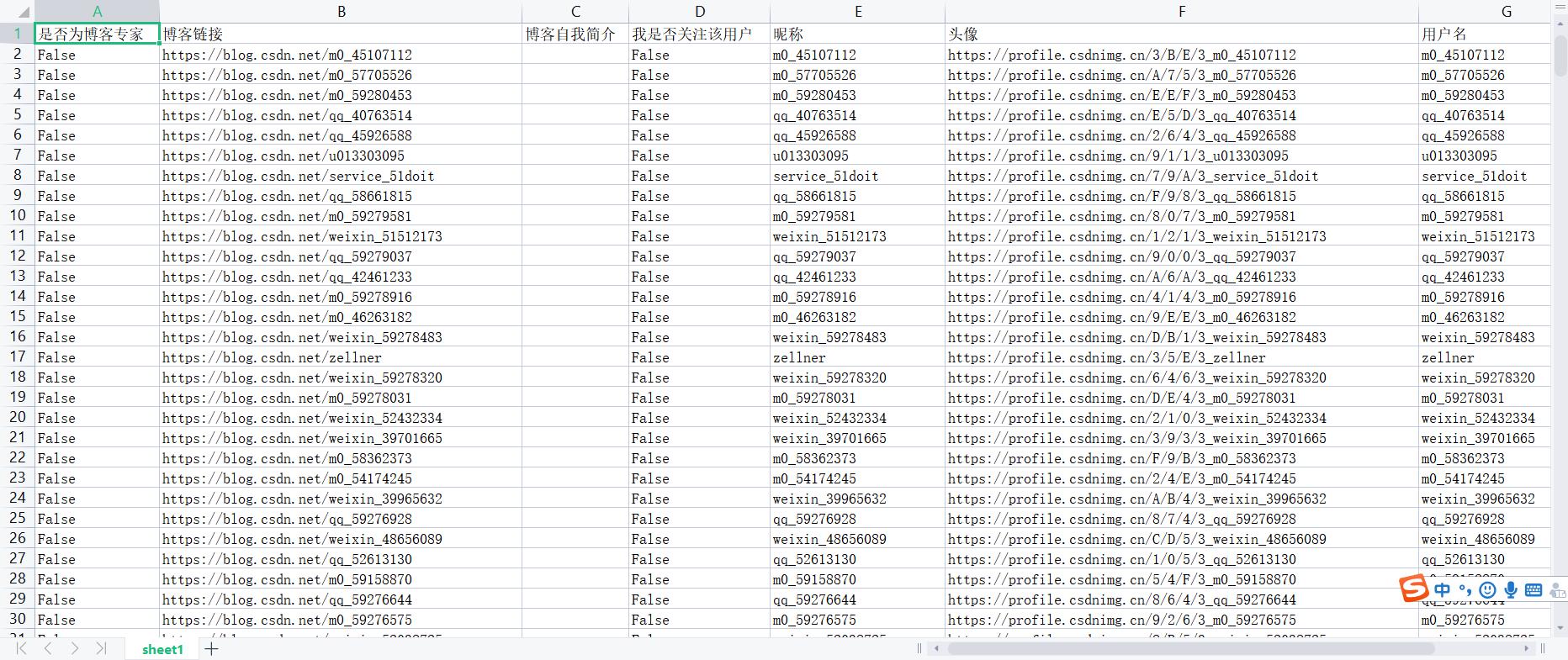
只有主页面数据的Excel文件截图
加入粉丝主页码龄和性别数据后的Excel文件截图
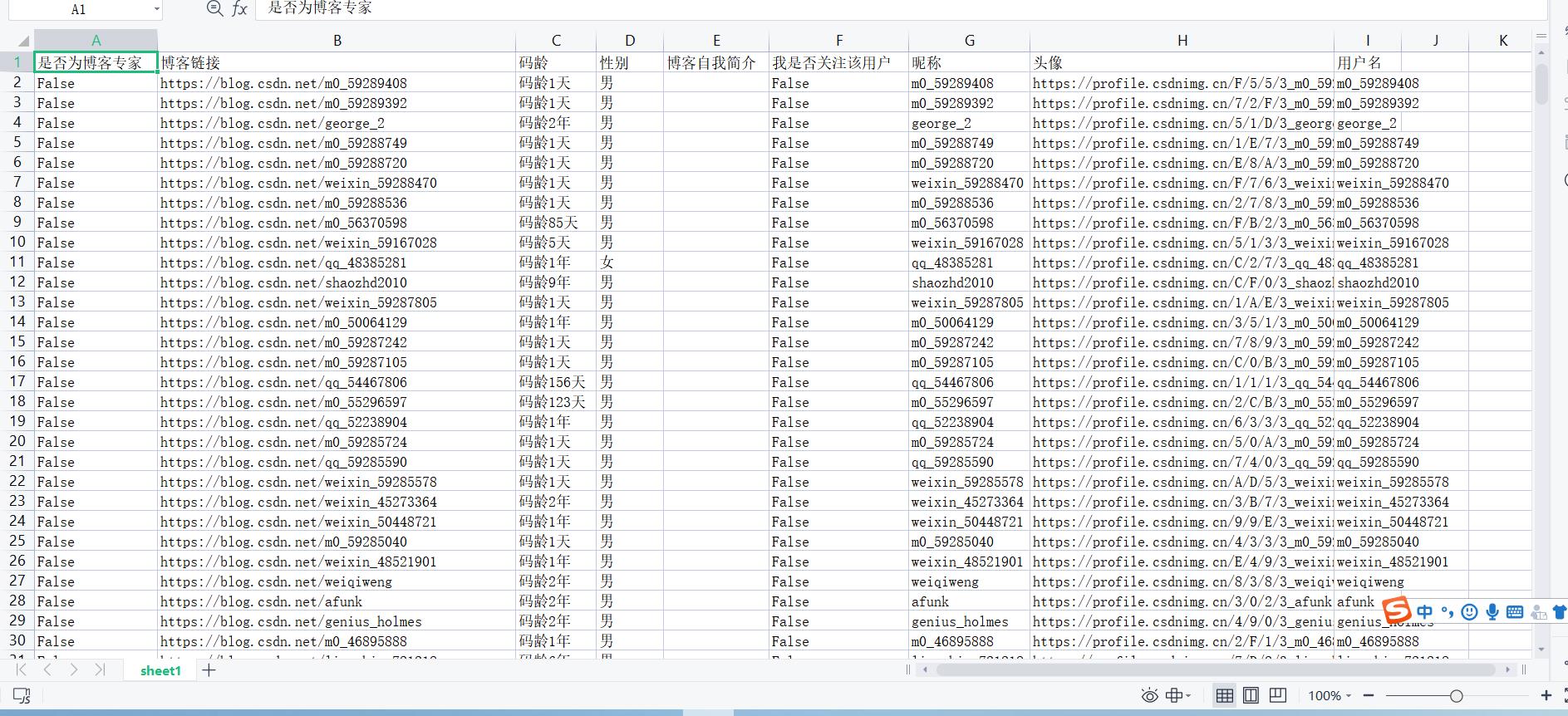
本来我是打算用Python继续分析数据,但现在数据已经完整的存到了Excel中,考虑到操作的方便性,我接下来将会直接在Excel中分析数据。
-
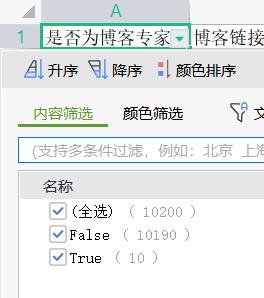
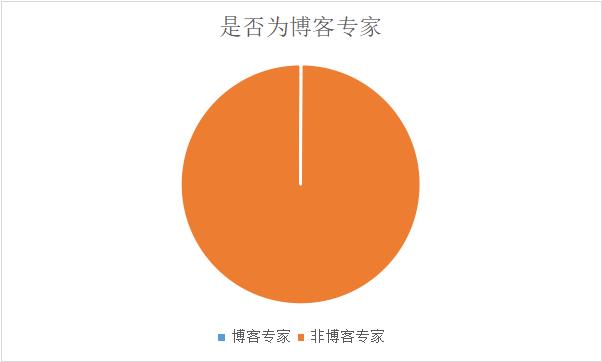
在我的粉丝群体中,有10个博客专家
-
在我的粉丝中
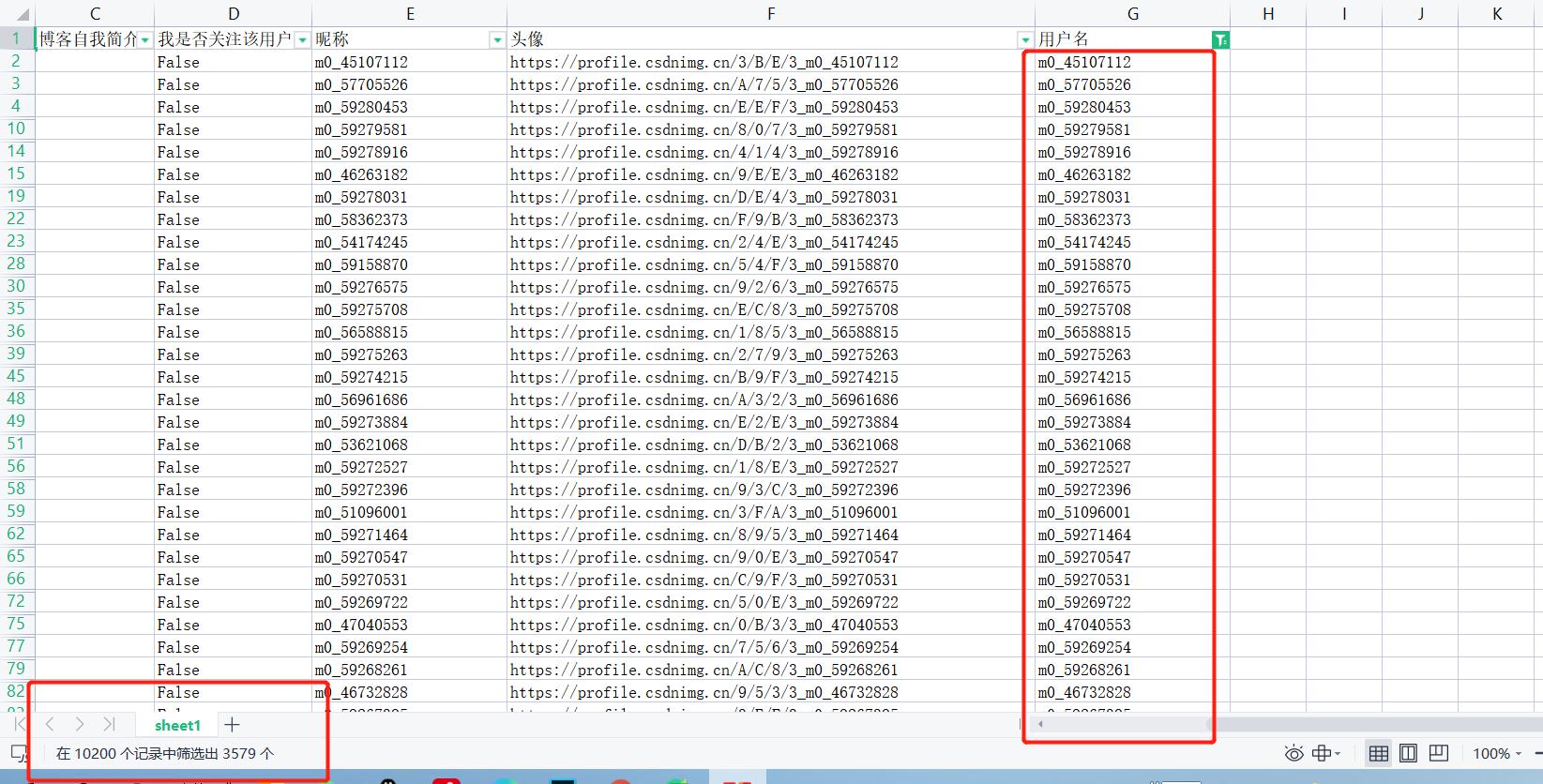
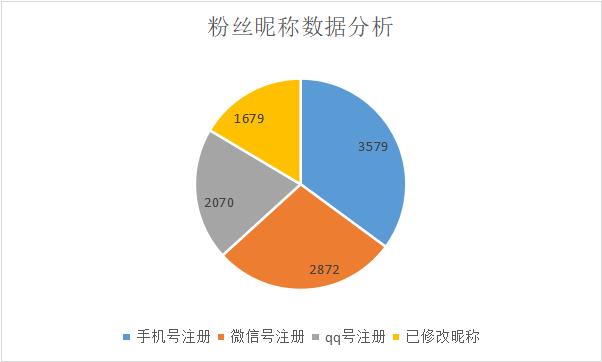
有3579个以m0_开头作为昵称的粉丝;
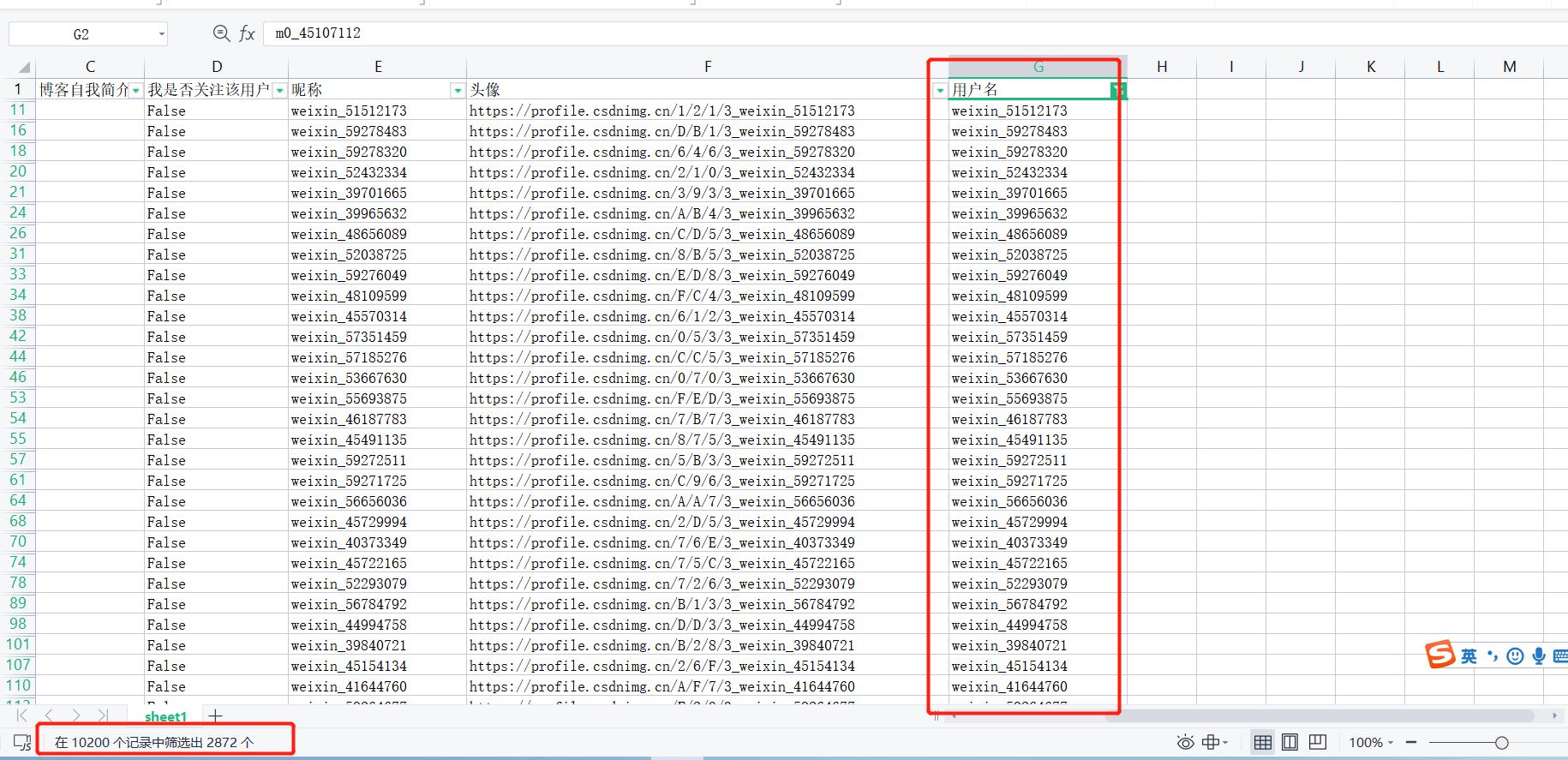
有2872个以weixin_开头作为昵称的粉丝;
有2070个以qq_开头作为昵称的粉丝;
有1679个以自定义昵称的粉丝;
有8521个没有修改昵称的粉丝。
从这里我们也可以大概分析到:CSDN的新注册用户中,有约16.46%的用户会更改自己的昵称(忽略我粉丝中占极小部分的熟人);有42.00%的用户通过手机注册,33.70%的用户通过微信注册,有24.29%的用户通过QQ注册。
-
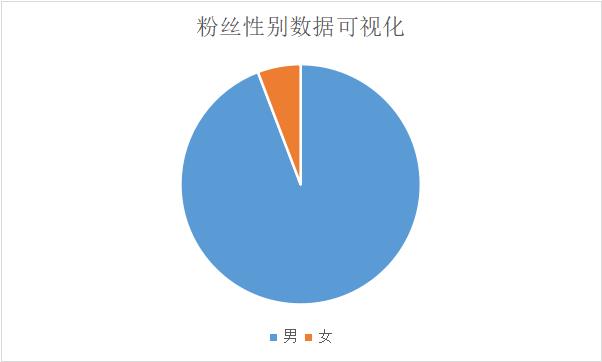
在我加入粉丝主页数据进行分析的时候,我的粉丝数量也在增加,因此Excel粉丝的总数变为10164,其中男性粉丝有9576人,女性粉丝有588人。男生人数:女生人数 = 94.2%:5.8%
-
对于博客码龄(也就是从注册账号的那天开始),既有超过10年码龄的重量级博主,也有刚刚注册的7-8天的新人博主。
5. 总结
我认为我爬取的一万个粉丝的数据完全可以撑起一个完整的CSDN粉丝数据分析的模块;进一步讲,一万个数据虽然只是全站用户的凤毛麟角,但这个数据量分析出来的很多结果也可以反映目前CSDN全站的数据,例如:用户男女比例、用户使用不同社交软件注册的比例,用户修改昵称的比例(一定程度反映活跃度)等等。
本文对数据的获取仅仅是为了提高小伙伴们对爬虫的兴趣,体会到爬虫在生活中的一些使用场景。对于爬取之后的完整数据,如果小伙伴们感兴趣的话,欢迎在CSDN上私信我,我可以将完整的Excel数据提供给你。
以上是关于万粉博主为CSDN增加粉丝数据分析模块硬核的主要内容,如果未能解决你的问题,请参考以下文章