MapReduce进阶:多MapReduce的链式模式
Posted Q-WHai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce进阶:多MapReduce的链式模式相关的知识,希望对你有一定的参考价值。
前言
我们不可能一直沉浸在 WordCount 的成功运行当中,就像之前学习 Java 或是其他编程语言不会着迷于 HelloWord 一样。
前面的 WordCount 程序只有一个 Mapper 和一个 Reducer 参与,也就是说只有一个 Job 参与。而一个 Job 在通常情况下是无法满足实际的开发需求,我们需要有更多的 Job 参与其中,并贡献自己的力量。在 MapReduce 模块中,有三个主要的模式:链式模型,并发模型和组合模型。
本文首先以最简单的链式模型作为切入,让你了解在 Hadoop 中,多个 MapReduce 是如何协作完成任务的。
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Q-WHai
发表日期: 2016年6月18日
本文链接:https://qwhai.blog.csdn.net/article/details/51706229
来源:CSDN
更多内容:分类 >> 大数据之 Hadoop
链式 MapReduce 模型
所谓链式模式,看名字就应该很好理解。这就是简单地把几个 Job 串联起来就可以了。模型图如下:
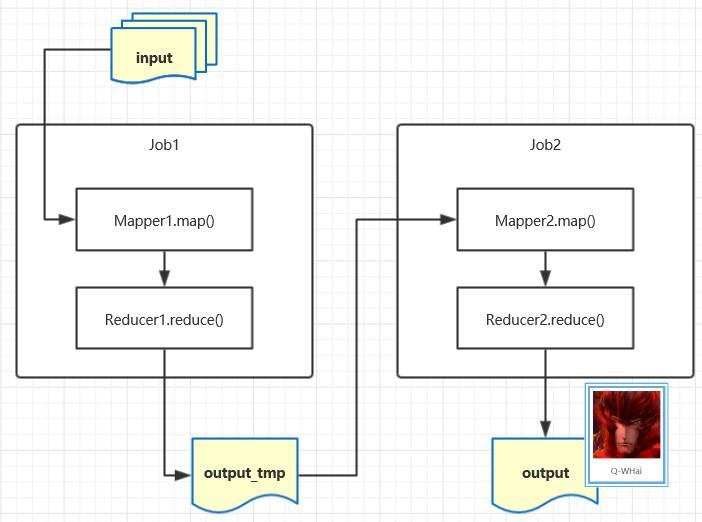
示例列举
假设有 4 个文件:
android
java
hadoop
python
内容分别为:
android
android fragment android
java android activity map array screen
activity
map
java
java
code java
eclipse java
java java code java
map java spring mysql jvm java
hadoop
map
reduce
ssh
mapreduce map reduce map reduce map reduce map reduce map reduce
python
python
pycharm
java dict java
承接之前 WordCount 的例子,这里我们要演示多 MapReduce 的操作,那么就不能只是 WordCount,所以,这里加入一个新的需求,将单词数以 5 个一组,分成 N 组。将同一组的单词写入同一行。
这样我们就不得不再添加一个新的 Job 来处理这个问题。
逻辑实现
在逻辑实现中,我们省略了第一个 Job,也就是 WordCount 这一个模块,如果你想要测试运行,可以先写好 WordCount 程序。
下面的两块内容,分别是词频分组的 Mapper 跟 Reducer,代码细节不是关键,且代码的难度不大。这里就不细述了。
FrequenciesMapper.java
public static class FrequenciesMapper extends Mapper<Object, Text, IntWritable, Text>
final int groupSize = 5;
@Override
protected void map(Object key, Text value, Mapper<Object, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException
StringTokenizer tokenizer = new StringTokenizer(value.toString());
String keyword = tokenizer.nextToken();
int wordCount = Integer.parseInt(tokenizer.nextToken());
int riseCount = (wordCount + groupSize) - (wordCount + groupSize) % groupSize;
Text valueText = new Text("[" + keyword + ":" + wordCount + "]");
context.write(new IntWritable(riseCount), valueText);
FrequenciesReducer.java
public static class FrequenciesReducer extends Reducer<IntWritable, Text, IntWritable, Text>
@Override
protected void reduce(IntWritable key, Iterable<Text> values,
Reducer<IntWritable, Text, IntWritable, Text>.Context context)
throws IOException, InterruptedException
if (null == values)
return;
boolean firstFlag = true;
StringBuffer buffer = new StringBuffer();
for (Text text : values)
buffer.append((firstFlag ? "" : ", ") + text.toString());
firstFlag = false;
context.write(key, new Text(buffer.toString()));
下面就是把两个不同的 Job 串联在一起的核心工作了。
ChainMRClient.java
public class ChainMRClient
private static String inputPath = "./input";
private static String outputPath = "./output";
public static void main(String[] args) throws Exception
ChainMRClient client = new ChainMRClient();
if (args.length == 2)
inputPath = args[0];
outputPath = args[1];
client.execute();
private void execute() throws Exception
String tmpOutputPath = outputPath + "_tmp";
runWordCountJob(inputPath, tmpOutputPath);
runFrequenciesJob(tmpOutputPath, outputPath);
private int runWordCountJob(String inputPath, String outputPath) throws Exception
Configuration configuration = new Configuration();
( ... 此处省略 N 行 ... )
return job.waitForCompletion(true) ? 0 : 1;
private int runFrequenciesJob(String inputPath, String outputPath) throws Exception
Configuration configuration = new Configuration();
( ... 此处省略 N 行 ... )
return job.waitForCompletion(true) ? 0 : 1;
省略部分可以参考之前的 WordCount 代码。
在上面的代码中,可以看到 execute() 方法中先计算了中间的输出目录。这样,第一个 Job 就可以将结果输出到这个目录下,而不是我们向程序传入的 outputPath 了;然后,再把这个中间输出目录作为第二个 Job 的输入目录。
因为是串联,所以只要把这两个 Job 放在代码中合适位置串联就可以了。
结果展示
中间结果
中间结果也就是前面的 WordCount 的结果,如下:
activity 2
android 3
array 1
code 2
dict 1
eclipse 1
fragment 1
java 11
jvm 1
map 9
mapreduce 1
mysql 1
pycharm 1
python 1
reduce 6
screen 1
spring 1
ssh 1
最终结果
可以看到在最终的结果里,单词已经被统计好词频,并进行了分组。如下:
5 [ssh:1], [spring:1], [screen:1], [python:1], [pycharm:1], [mysql:1], [mapreduce:1], [jvm:1], [fragment:1], [eclipse:1], [dict:1], [code:2], [array:1], [android:3], [activity:2]
10 [reduce:6], [map:9]
15 [java:11]
串联 Job
这里展示的就是刚刚运行成功的两个 Job。
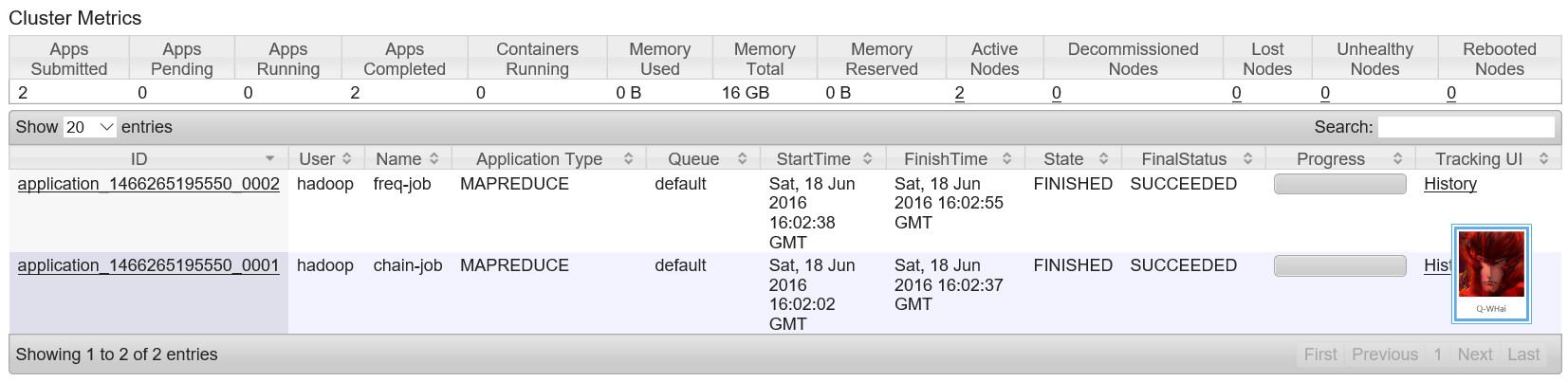
征集
如果你也需要使用ProcessOn这款在线绘图工具,可以使用如下邀请链接进行注册:
https://www.processon.com/i/56205c2ee4b0f6ed10838a6d
以上是关于MapReduce进阶:多MapReduce的链式模式的主要内容,如果未能解决你的问题,请参考以下文章