学习笔记Hadoop(十五)—— MapReduce编程进阶
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Hadoop(十五)—— MapReduce编程进阶相关的知识,希望对你有一定的参考价值。
文章目录
一、输出文件格式及序列化文件生成
1.1、输出文件格式
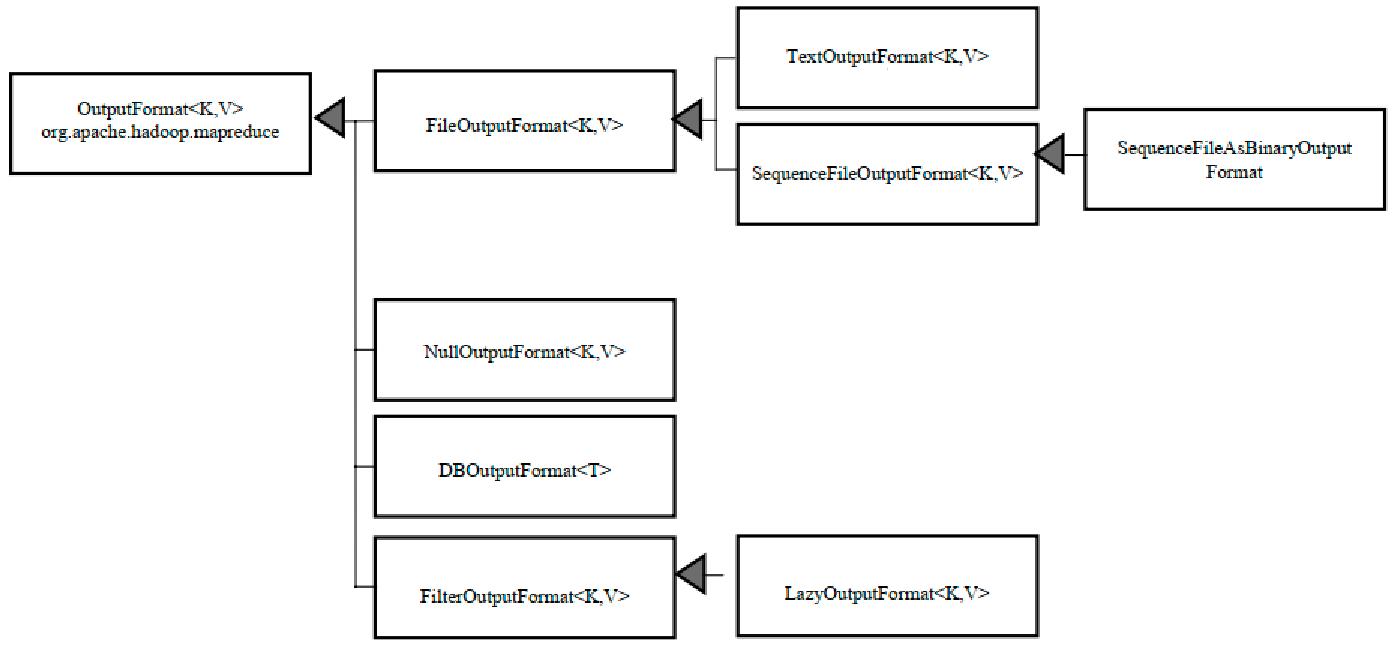
默认输出类型是:TextOutputFormat
1.2、设置输出SequenceFileOutputFormat文件格式
流程(Mapper、Reducer、Main、打包运行)
(参考SortByCountFirst程序)
Main函数

运行Job:

打包上传后,查看:
(master:8088)

(master:50070)

(终端查看:hdfs dfs -text sortbycountfirstseq_output00/part-r-00000 | head -2)
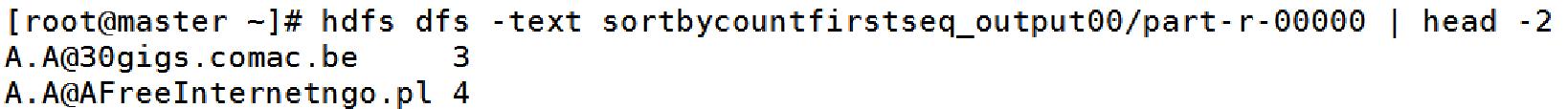
二、输入文件格式及序列化文件读取
2.1、输入数据文件类型
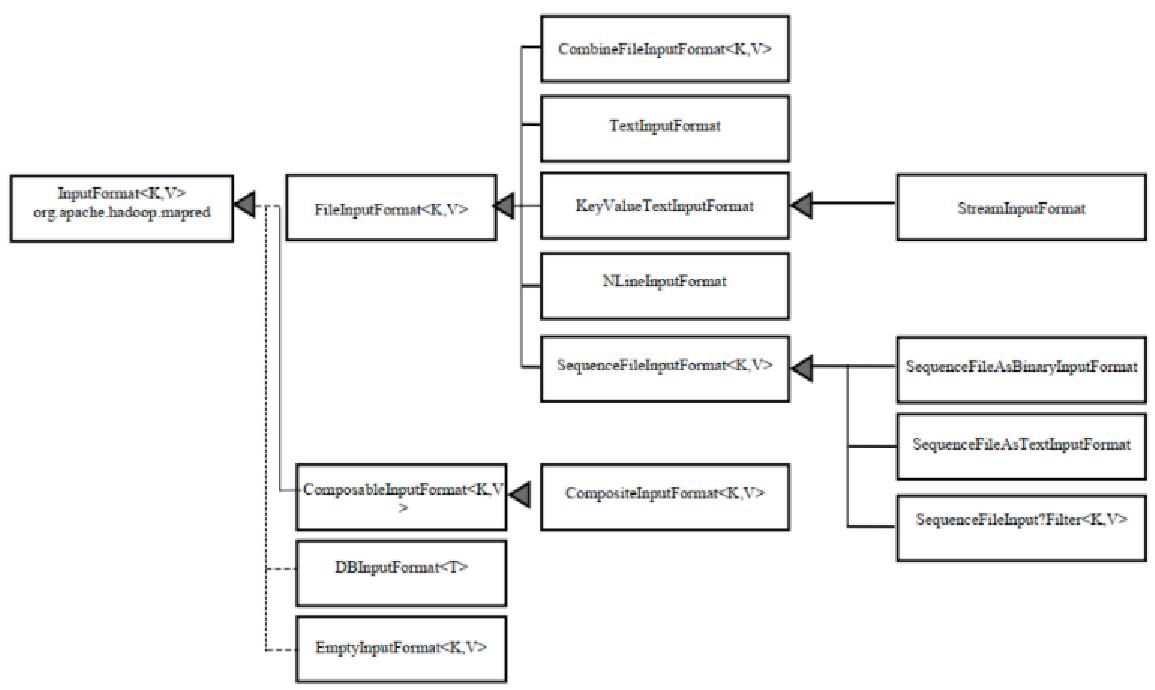
默认输入类型是:TextInputFormat
2.2、设置输入SequenceFileInputFormat文件格式
流程(Mapper、Reducer、Main、打包运行)
(参考SortByCountSecond程序)
Mapper函数

Main函数

结果查看:



三、使用Partitioner优化程序
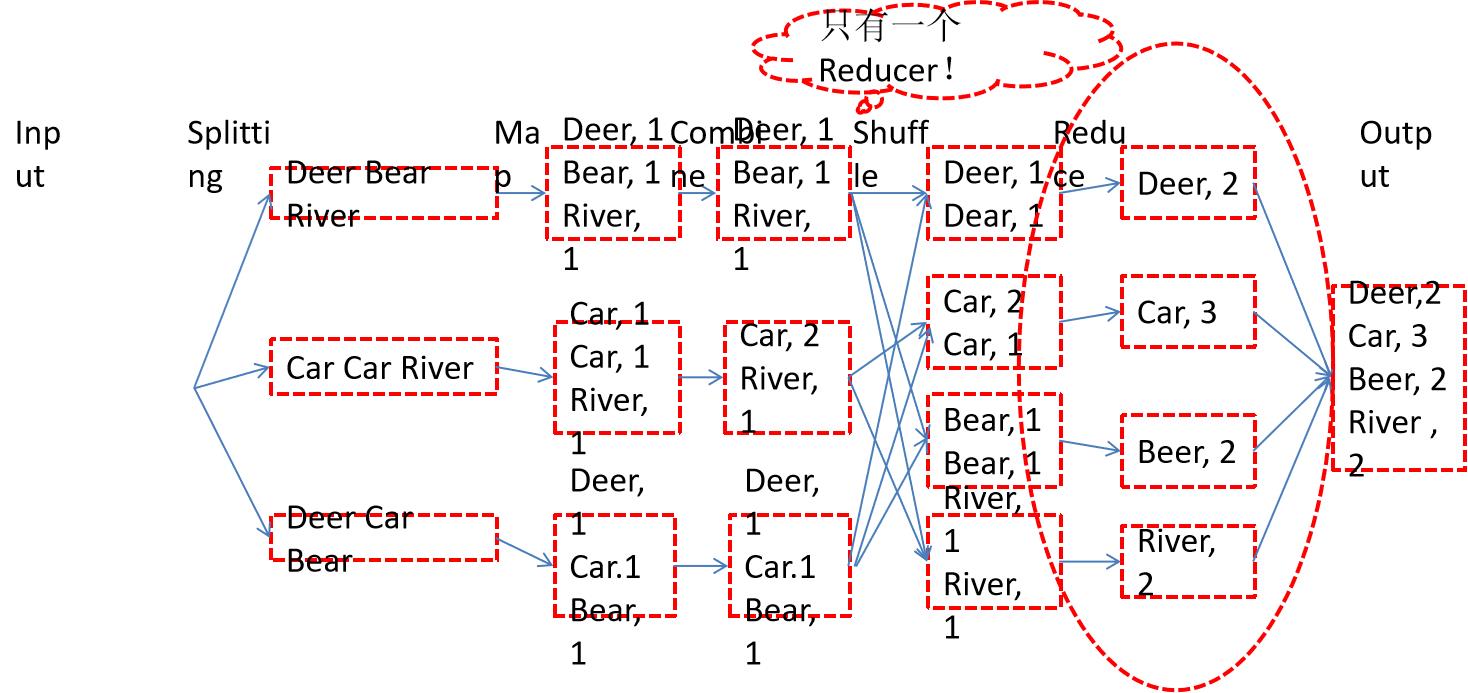
只有一个reducer的话,Partitioner是没有用处的
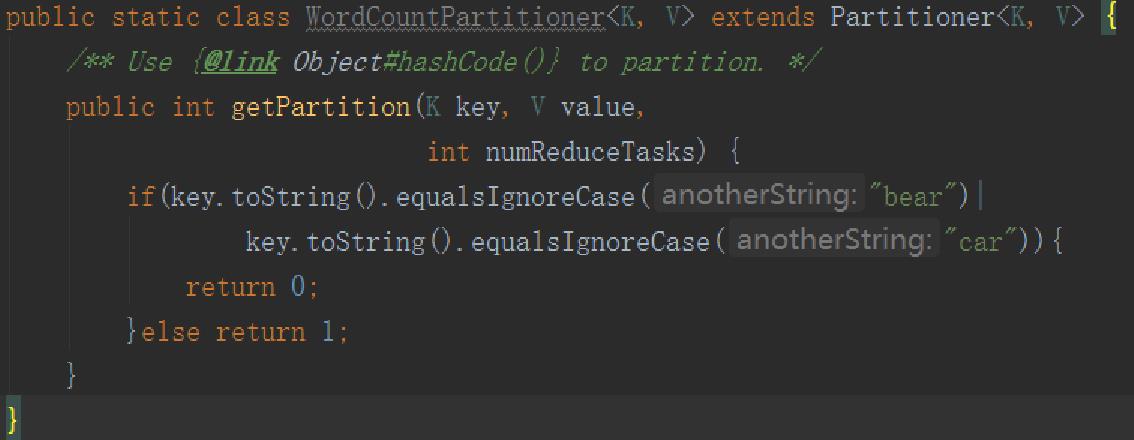
3.1、自定义单词计数
Partitioner
(添加,可以查找HashPartitioner.java找完后修改)
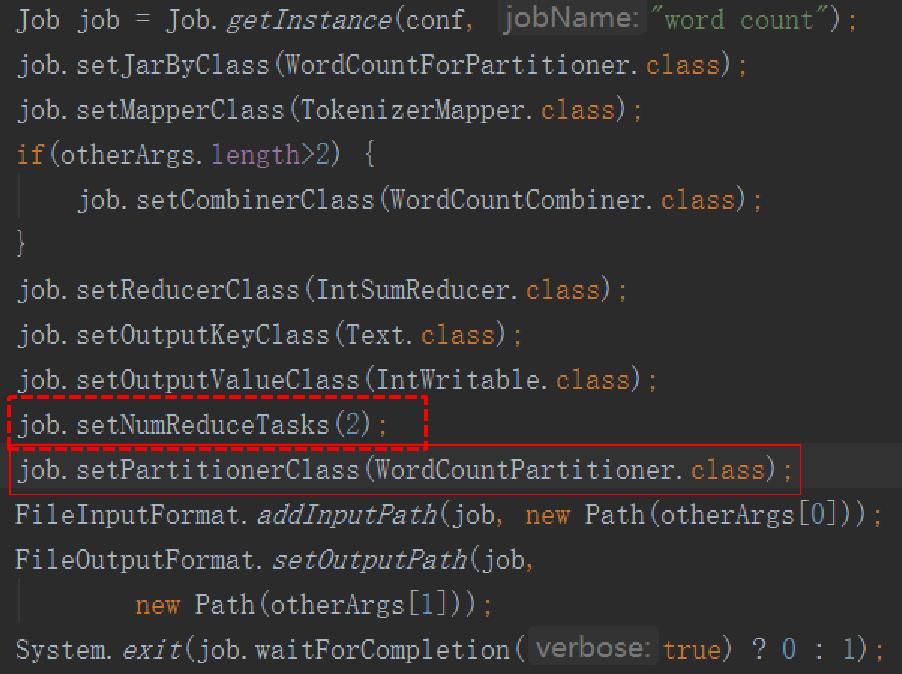
Main函数
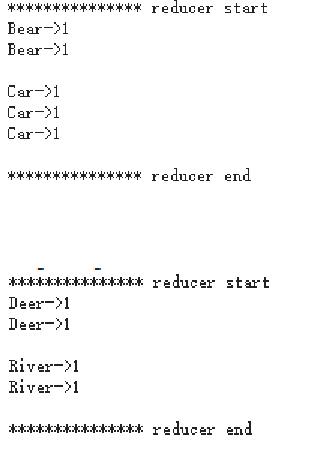
查看结果
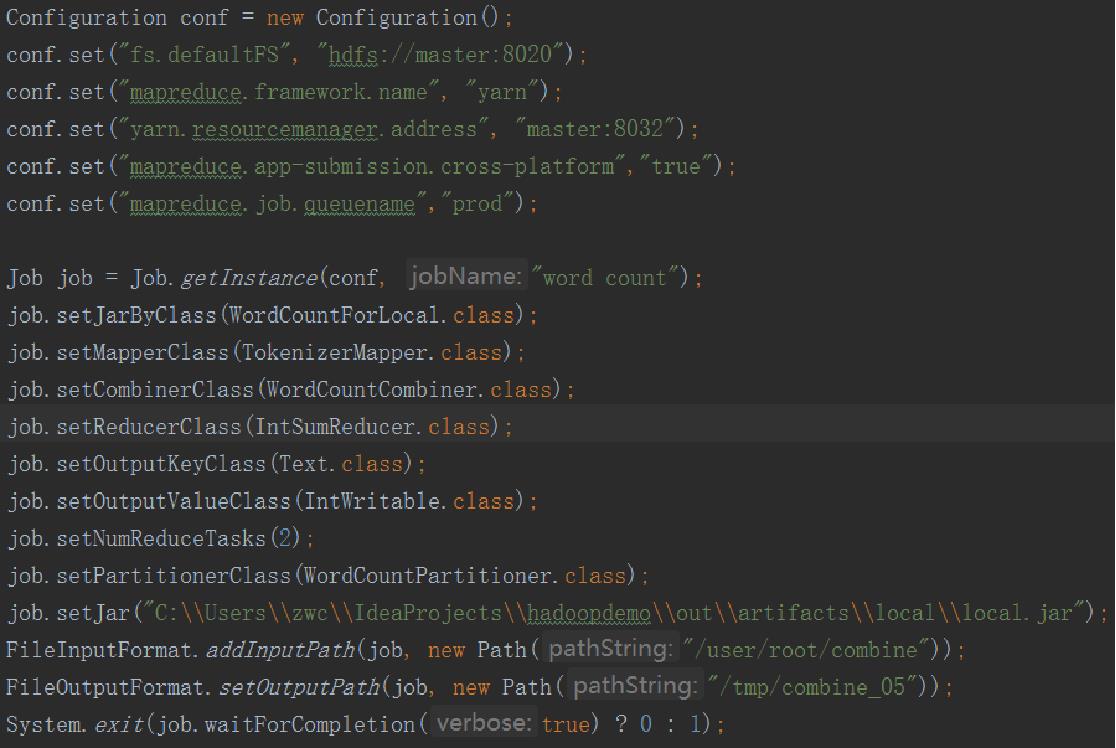
四、本地提交MapReduce程序
4.1、自定义单词计数
Main 函数
可能出现的问题及解决方法:
1、问题:

解决:修改权限

2、问题:
任务提交仍然失败!
(日志)

解决:添加文件

以上是关于学习笔记Hadoop(十五)—— MapReduce编程进阶的主要内容,如果未能解决你的问题,请参考以下文章
[hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
[hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 数据在mysq和hdfs之间的相互转换