[hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 数据在mysq和hdfs之间的相互转换
Posted Aviva_ye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 数据在mysq和hdfs之间的相互转换相关的知识,希望对你有一定的参考价值。
P573 从mysql导入数据到hdfs
第一步:在mysql中创建待导入的数据
1、创建数据库并允许所有用户访问该数据库
mysql -h 192.168.200.250 -u root -p
CREATE DATABASE sqoop;
GRANT ALL PRIVILEGES ON *.* TO \'root\'@\'%\';
或 GRANT SELECT, INSERT, DELETE,UPDATE ON *.* TO \'root\'@\'%\';
FLUSH PRIVILEGES;
查看权限:select user,host,select_priv,insert_priv,update_priv,delete_priv from mysql.user;
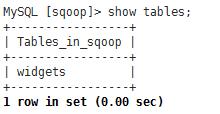
2、创建表widgets
CREATE TABLE widgets(id INT NOT NULL PRIMARY KEY AUTO_INCREMENT, widget_name VARCHAR(64) NOT NULL, price DECIMAL(10,2), design_date DATE, version INT, design_comment VARCHAR(100));
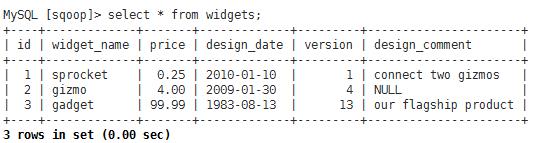
3、导入测试数据
INSERT INTO widgets VALUES(NULL,\'sprocket\',0.25,\'2010-01-10\',1,\'connect two gizmos\'); INSERT INTO widgets VALUES(NULL,\'gizmo\',4.00,\'2009-01-30\',4,NULL); INSERT INTO widgets VALUES(NULL,\'gadget\',99.99,\'1983-08-13\',13,\'our flagship product\');
第二步:执行sqoop导入命令
sqoop import --connect jdbc:mysql://192.168.200.250/sqoop --table widgets -m 1
缺少mysql连接器

先导入mysql的连接器包

再来执行

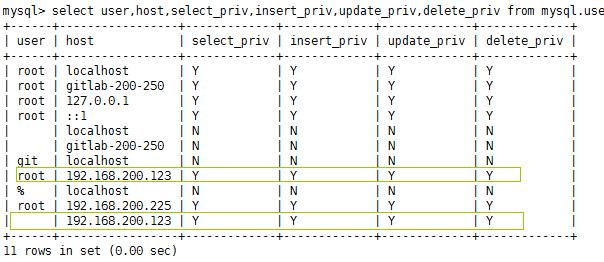
发现怎么也连接不上远程mysql数据库,需要授权如下:
GRANT ALL ON *.* TO \'\'@\'192.168.200.123\';
grant all privileges on *.* to ""@"192.168.200.123" identified by "密码";
FLUSH PRIVILEGES;
select user,host,select_priv,insert_priv,update_priv,delete_priv from mysql.user;
再来执行一下
还是不行的话,就只能是在sqoop命令中通过--username 和--password来显式的指定用户名和密码连接了
sqoop import --connect jdbc:mysql://192.168.200.250/sqoop --table widgets -m 1 -username root -password mysql密码
在yarn管理台查看到这个任务正在运行(RUNNING)http://hadoop-allinone-200-123.wdcloud.locl:8088/cluster

但是最终还是执行失败

失败原因:物理内存使用了156.8远小于分配的1GB,但是虚拟内存使用2.7超过了默认配置的2.1GB,解决方法:
在etc/hadoop/yarn-site.xml文件中,修改检查虚拟内存的属性为false,如下:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
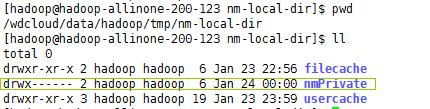
运行继续报错:

解决方法:这个目录没有权限
http://www.oschina.net/question/2288283_2134188?sort=time
保证使用hadoop用户启动集群(因为hadoop的集群的用户是hadoop),并为这个文件夹授权755
再来执行,姐们儿就不信了 。。。哒哒哒。。。终于成功了
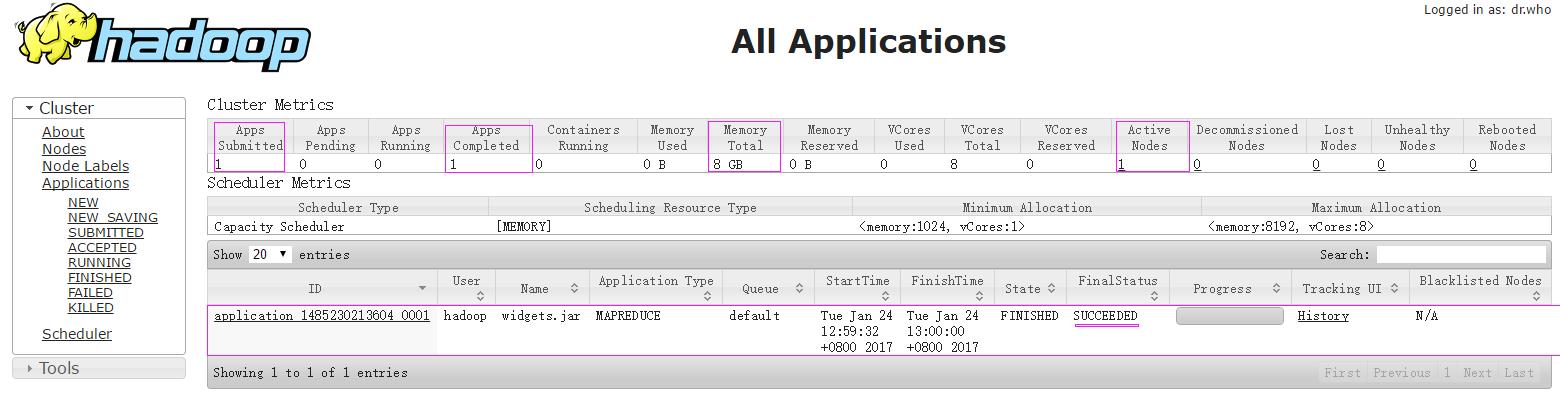
后台日志:
[hadoop@hadoop-allinone-200-123 sqoop-1.4.6]$ sqoop import --connect jdbc:mysql://192.168.200.250/sqoop --tabgets -m 1 -username root -password weidong Warning: /wdcloud/app/sqoop-1.4.6/../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /wdcloud/app/sqoop-1.4.6/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /wdcloud/app/sqoop-1.4.6/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /wdcloud/app/sqoop-1.4.6/../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 17/01/23 23:59:17 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 17/01/23 23:59:17 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider us instead. 17/01/23 23:59:18 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 17/01/23 23:59:18 INFO tool.CodeGenTool: Beginning code generation 17/01/23 23:59:18 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets` AS t LIMIT 1 17/01/23 23:59:18 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets` AS t LIMIT 1 17/01/23 23:59:18 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /wdcloud/app/hadoop-2.7.3 Note: /tmp/sqoop-hadoop/compile/591fd797fbbe57ce38b4492a1c9a0300/widgets.java uses or overrides a deprecated Note: Recompile with -Xlint:deprecation for details. 17/01/23 23:59:21 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/591fd797fbbe57ce381c9a0300/widgets.jar 17/01/23 23:59:21 WARN manager.MySQLManager: It looks like you are importing from mysql. 17/01/23 23:59:21 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 17/01/23 23:59:21 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 17/01/23 23:59:21 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 17/01/23 23:59:21 INFO mapreduce.ImportJobBase: Beginning import of widgets 17/01/23 23:59:21 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.joer.address 17/01/23 23:59:22 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 17/01/23 23:59:23 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job. 17/01/23 23:59:24 INFO client.RMProxy: Connecting to ResourceManager at hadoop-allinone-200-123.wdcloud.locl/8.200.123:8032 17/01/23 23:59:30 INFO db.DBInputFormat: Using read commited transaction isolation 17/01/23 23:59:30 INFO mapreduce.JobSubmitter: number of splits:1 17/01/23 23:59:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1485230213604_0001 17/01/23 23:59:32 INFO impl.YarnClientImpl: Submitted application application_1485230213604_0001 17/01/23 23:59:32 INFO mapreduce.Job: The url to track the job: http://hadoop-allinone-200-123.wdcloud.locl:80213604_0001/ 17/01/23 23:59:32 INFO mapreduce.Job: Running job: job_1485230213604_0001 17/01/23 23:59:50 INFO mapreduce.Job: Job job_1485230213604_0001 running in uber mode : false 17/01/23 23:59:50 INFO mapreduce.Job: map 0% reduce 0% 17/01/24 00:00:00 INFO mapreduce.Job: map 100% reduce 0% 17/01/24 00:00:01 INFO mapreduce.Job: Job job_1485230213604_0001 completed successfully 17/01/24 00:00:02 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=138186 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=129 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=7933 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=7933 Total vcore-milliseconds taken by all map tasks=7933 Total megabyte-milliseconds taken by all map tasks=8123392 Map-Reduce Framework Map input records=3 Map output records=3 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=59 CPU time spent (ms)=2210 Physical memory (bytes) snapshot=190287872 Virtual memory (bytes) snapshot=2924978176 Total committed heap usage (bytes)=220725248 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=129 17/01/24 00:00:02 INFO mapreduce.ImportJobBase: Transferred 129 bytes in 38.2028 seconds (3.3767 bytes/sec) 17/01/24 00:00:02 INFO mapreduce.ImportJobBase: Retrieved 3 records.
查看作业历史服务器以了解MR任务执行详情,发现查看不到,原因是因为没有启动作业历史服务器

启动之:
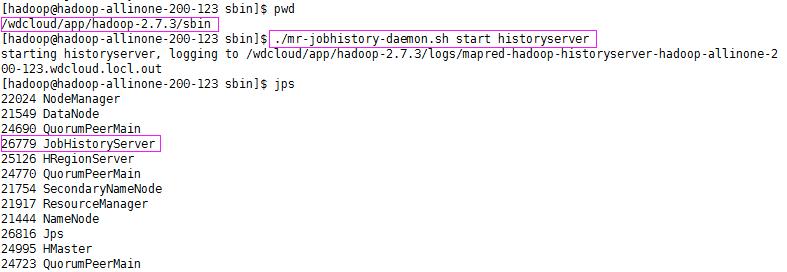
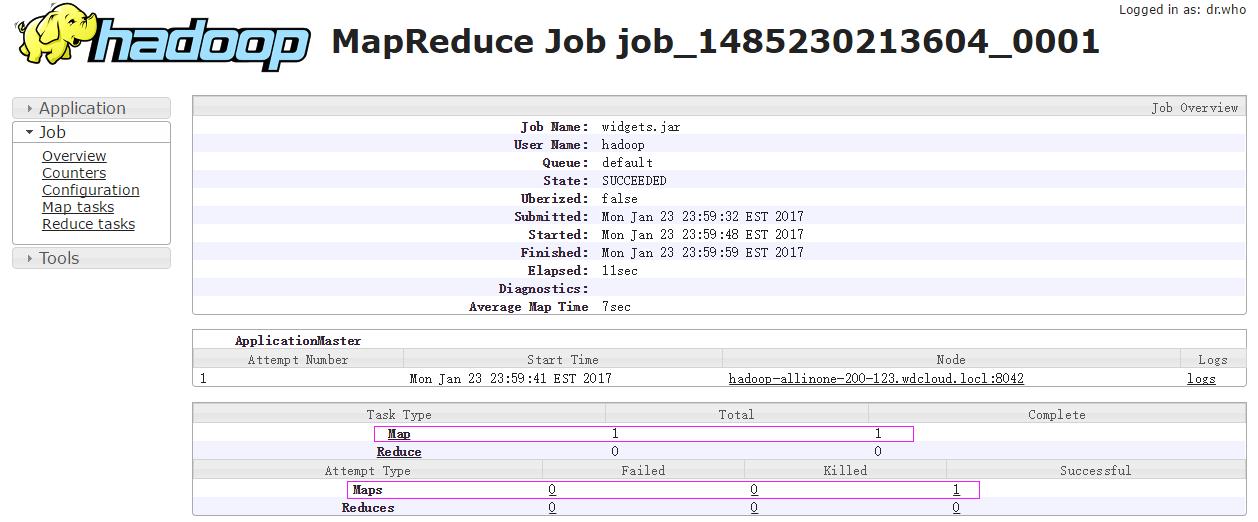
再来查看下,就可以看到作业历史记录了
http://hadoop-allinone-200-123.wdcloud.locl:19888/jobhistory/job/job_1485230213604_0001
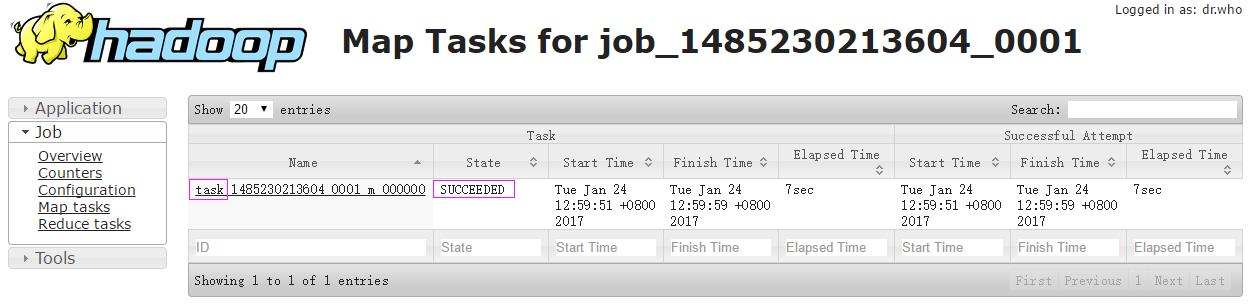
可以看到,sqoop导入数据到hdfs只有map任务而没有reduce任务,map任务数目为1,执行完成数目为1,成功数目为1 ,点击Map链接,查看详细
现在,看看是否真的已经导入了这个数据表
第三步:验证导入结果

可以看到 widgets 表的数据已经导入到了HDFS中
除了导入数据到HDFS中,sqoop在导入时还生成导入源代码.java .jar和.class文件
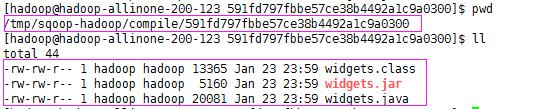
如果只想生成代码而不导入数据,执行以下命令:
sqoop codegen --connect uri --table 表 --class-name 生成的类名称
第四步:追加数据
--direct:能更快速的从表中读取数据,需要数据库支持,如mysql使用外部工具mysqldump
--append:使用追加数据模式来导入数据
现在,我们在mysql中新插入了一条数据
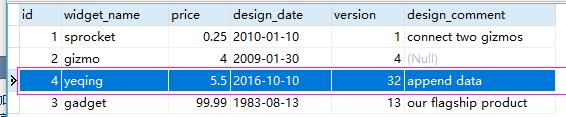
来执行追加命令
sqoop import --connect jdbc:mysql://192.168.200.250/sqoop --table widgets -m 1 -username root -password weidong --direct --append
执行成功

查看下HDFS中的数据
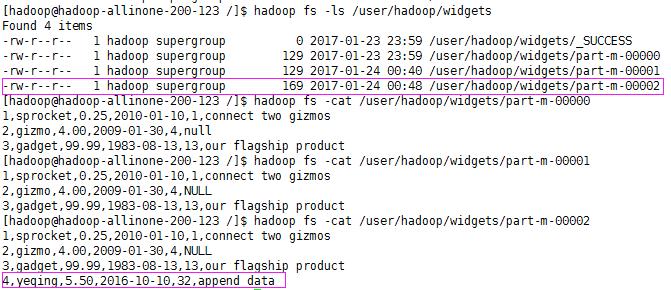
可以看到,已经追加成功
第五步:将HDFS中的数据导出到mysql
复制表widgets为widgets_copy并清空widgets_copy表数据
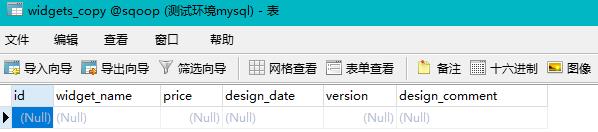
执行导出命令
当将密码写在命令行,会为安全造成影响,这时,可以使用参数-P取代 --password
在任务执行时动态的输入密码
Setting your password on the command-line is insecure. Consider using -P instead.
所以命令如下:
sqoop export
--connect jdbc:mysql://192.168.200.250/sqoop
-m 1
--table widgets_copy
--export-dir widgets/part-m-00002
--username root
-P
Enter password:不会回显字符
成功执行日志信息
[hadoop@hadoop-allinone-200-123 /]$ sqoop export --connect jdbc:mysql://192.168.200.250/sqoop -m 1 --table widgets_copy --export-dir widgets/part-m-00002 --username root -P17/01/24 01:04:19 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 Enter password: 17/01/24 01:04:22 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 17/01/24 01:04:22 INFO tool.CodeGenTool: Beginning code generation 17/01/24 01:04:23 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets_copy` AS t LIMIT 1 17/01/24 01:04:23 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets_copy` AS t LIMIT 1 17/01/24 01:04:23 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /wdcloud/app/hadoop-2.7.3 Note: /tmp/sqoop-hadoop/compile/c66df558e872801e493fbc78458e6914/widgets_copy.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 17/01/24 01:04:26 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/c66df558e872801e493fbc78458e6914/widgets_copy.jar 17/01/24 01:04:26 INFO mapreduce.ExportJobBase: Beginning export of widgets_copy 17/01/24 01:04:26 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address 17/01/24 01:04:26 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 17/01/24 01:04:28 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative 17/01/24 01:04:28 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative 17/01/24 01:04:28 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 17/01/24 01:04:28 INFO client.RMProxy: Connecting to ResourceManager at hadoop-allinone-200-123.wdcloud.locl/192.168.200.123:8032 17/01/24 01:04:30 WARN hdfs.DFSClient: Caught exception java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1281) at java.lang.Thread.join(Thread.java:1355) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:609) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:370) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:546) 17/01/24 01:04:32 INFO input.FileInputFormat: Total input paths to process : 1(仅处理一个路径的数据导出) 17/01/24 01:04:32 INFO input.FileInputFormat: Total input paths to process : 1 17/01/24 01:04:32 INFO mapreduce.JobSubmitter: number of splits:1 17/01/24 01:04:32 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative 17/01/24 01:04:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1485230213604_0005 17/01/24 01:04:34 INFO impl.YarnClientImpl: Submitted application application_1485230213604_0005 17/01/24 01:04:34 INFO mapreduce.Job: The url to track the job: http://hadoop-allinone-200-123.wdcloud.locl:8088/proxy/application_1485230213604_0005/ 17/01/24 01:04:34 INFO mapreduce.Job: Running job: job_1485230213604_0005 17/01/24 01:04:46 INFO mapreduce.Job: Job job_1485230213604_0005 running in uber mode : false 17/01/24 01:04:46 INFO mapreduce.Job: map 0% reduce 0% 17/01/24 01:04:57 INFO mapreduce.Job: map 100% reduce 0% 17/01/24 01:04:58 INFO mapreduce.Job: Job job_1485230213604_0005 completed successfully 17/01/24 01:04:59 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=137897 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=334 HDFS: Number of bytes written=0 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=0 Job Counters Launched map tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=7444 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=7444 Total vcore-milliseconds taken by all map tasks=7444 Total megabyte-milliseconds taken by all map tasks=7622656 Map-Reduce Framework Map input records=4 Map output records=4 Input split bytes=162 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=149 CPU time spent (ms)=2890 Physical memory (bytes) snapshot=184639488 Virtual memory (bytes) snapshot=2923687936 Total committed heap usage (bytes)=155713536 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=0 17/01/24 01:04:59 INFO mapreduce.ExportJobBase: Transferred 334 bytes in 30.6866 seconds (10.8842 bytes/sec) 17/01/24 01:04:59 INFO mapreduce.ExportJobBase: Exported 4 records.(导出了4条记录)
可以看见,mysql表已导入数据
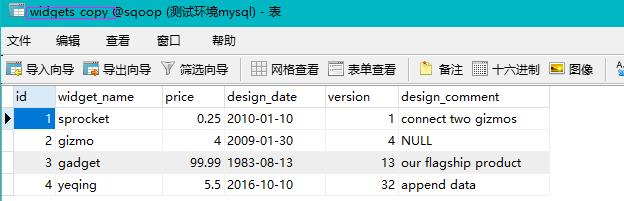
至此,mysql和hdfs相互的数据导入导出就完毕了
以上是关于[hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 数据在mysq和hdfs之间的相互转换的主要内容,如果未能解决你的问题,请参考以下文章