Logstash:如何运用 Elastic Stack 结合 RSS feeds 告知可能性
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Logstash:如何运用 Elastic Stack 结合 RSS feeds 告知可能性相关的知识,希望对你有一定的参考价值。
作者:Jordyn Short,Dave Sanchez,Connie Crites

作为 Elasticians,我们有机会观察各种 Elastic 用例。 作为前 SOC 分析师,我们发现自己被安全用例所吸引。 我们一直在寻找利用 Elastic Stack 为 Elastic 和网络安全社区增加价值的方法。 我们一直在研究 — 筛选新闻文章、白皮书、数据库等。我们意识到我们花了很多时间访问相同的站点并且需要整合(呃!)。
下面,我们将详细介绍我们如何使用 RSS 提要、Logstash、Elasticsearch 和 Kibana 来摄取、整合、聚合、可视化和搜索感兴趣的网络安全内容,以及如何做到这一点。
【 相关文章:网络安全是一项数据挑战,更好的搜索技术是提高可见性和行动的关键 】
RSS feeds
有几种方法可以合并 RSS 提要。 许多馈送器和聚合器都是基于订阅的,但我们认为内容管理应该是免费的。 我们最初的冲动是,“让我们编写一个 Python 脚本,将数据发送到 Logstash,观察它流入 Elasticsearch,然后通过 Kibana 进行观察……” 当我们开始计划和研究时,我们找到了一个完全可以绕过 Python 脚本的解决方案:Logstash 管道的 RSS 输入插件。 那时,我们已经确定了开始构建基于 Elastic 的开源智能工具 (Elastic-based Open Source Inteligence - OSINT) 的所有必要要素。
我们项目的名称是 A Quick RSS Cybersecurity News Feed。 这些是它的组成部分:
- RSS 订阅
- Logstash 配置
- Elasticsearch 配置
- Kibana 可视化和仪表板

这些 RSS 提要目前包括:
- Dark Reading
- Zero Day Initiative
- Bleeping Computer
- The Hacker News
- The Register
- Krebs on Security
- US-CERT
- Cisco Talos
- KnowBe4
- Threatpost
- Malwarebytes
- Microsoft Security
我们可以通过如下的命令来下载代码:
git clone https://github.com/cyberimposters/rss-securityLogstash
这是我们的 Logstash 管道及其配置的概述。
安装
我们在如下的演示中,我们使用 pipeline.yml 文件的方式来部署 Logstash,而不是通过命令行将配置作为文件传递,因此我们对它的依赖减少了。我们可以参考文章 “如何安装 Elastic 栈中的 Logstash” 来安装 Logstash。我们需要修改 pipelines.yml 文件:
pipelines.yml
- pipeline.id: rss-feed
path.config: "/etc/logstash/conf.d/*.conf"
在下面,我们将创建一个叫做 rss-security-feed.conf 的文件。它将由如下的三个部分组成:
- input
- filter
- output
如上所示,我们需要把这个 rss-security-feed.conf 文件拷贝到 /etc/logstash/conf.d/ 目录下。在完成 rss-security-feed.conf 的设计后,我们需要使用如下的命令来启动 Logstash:
sudo service logstash restart如果你想查看 logstash 这个服务的日志,你可以使用如下的命令:
journalctl -u logstash如果你想清楚所有的 service 所生成的日志,你可以使用如下的命令:
sudo journalctl --rotate
sudo journalctl --vacuum-time=1s在启动之前,我们需要按照如下的步骤来配置 Logstash 的配置文件 rss-security-feed.conf。
Input
RSS 输入插件:在插件输入部分,我们添加了以下内容:
- id:插件配置的唯一 ID。 当你有两个或多个相同类型的插件时,这特别有用。 如果你有多个 RSS 输入,添加一个命名 ID 将更容易监控 Logstash。 我们还为我们的 ID 设置了清晰、独特的名称,我们发现所有这些名称在故障排除和测试期间都特别有用。
- url:RSS/Atom 提要 URL。 如上图所示,我们选择使用多个 RSS 输入。
- interval:运行命令的间隔。 该值以秒为单位。 我们选择将时间间隔设置为 3600 秒(1 小时); 我们的决定纯粹是基于偏好。
- tags:为你的事件添加任意数量的任意标签。 我们将标签用于 Kibana 过滤目的。 同样,我们希望我们的标签简洁,以便我们可以清楚地区分我们选择的新闻提要。
input
rss
id => "zdi"
url => "https://www.zerodayinitiative.com/rss/published/"
interval => 3600
tags => ["zero day initative"]
rss
id => "dark_reading"
url => "https://www.darkreading.com/rss.xml"
interval => 3600
tags => ["dark reading"]
rss
id => "bleeping_computer"
url => "https://www.bleepingcomputer.com/feed/"
interval => 3600
tags => ["bleeping computer"]
rss
id => "hacker_news"
url => "https://feeds.feedburner.com/TheHackersNews"
interval => 3600
tags => ["hacker news"]
rss
id => "register"
url => "https://www.theregister.com/security/headlines.atom"
interval => 3600
tags => ["the register"]
rss
id => "krebs"
url => "https://krebsonsecurity.com/feed/"
interval => 3600
tags => ["krebs on security"]
rss
id => "cisa"
url => "https://www.cisa.gov/uscert/ncas/current-activity.xml"
interval => 3600
tags => ["cisa cybersecurity advisories"]
rss
id => "cisco_talos_threats"
url => "https://blog.talosintelligence.com/feeds/posts/default/-/threats"
interval => 3600
tags => ["talos"]
rss
id => "cisco_talos_vulnerabilities"
url => "https://blog.talosintelligence.com/feeds/posts/default/-/vulnerabilities"
interval => 3600
tags => ["talos"]
rss
id => "knowbe4"
url => "https://blog.knowbe4.com/rss.xml"
interval => 3600
tags => ["knowbe4"]
rss
id => "threatpost"
url => "https://threatpost.com/feed/"
interval => 3600
tags => ["threatpost"]
rss
id => "troy_hunt"
url => "https://feeds.feedburner.com/TroyHunt"
interval => 3600
tags => ["troy hunt"]
rss
id => "malware_bytes"
url => "https://www.malwarebytes.com/blog/feed/index.xml"
interval => 3600
tags => ["malwarebytes"]
rss
id => "graham_cluley"
url => "https://feeds.feedburner.com/grahamcluley"
interval => 3600
tags => ["graham cluley"]
rss
id => "microsoft"
url => "https://www.microsoft.com/security/blog/feed/"
interval => 3600
tags => ["microsoft security"]
rss
id => "daily_swig"
url => "https://portswigger.net/daily-swig/rss"
interval => 3600
tags => ["daily swig"]
rss
id => "sophos"
url => "http://feeds.feedburner.com/NakedSecurity"
interval => 3600
tags => ["sophos"]
注意:需要安装 RSS 插件,因为它不是 logstash 包的一部分。 它可以通过运行如下的命令安装:
bin/logstash-plugin install logstash-input-rss如果你是在 Linux 下安装,那么你可以使用如下的命令来运行:
root@liuxgu:/usr/share/logstash# bin/logstash-plugin install logstash-input-rss
Using bundled JDK: /usr/share/logstash/jdk
Validating logstash-input-rss
Resolving mixin dependencies
Installing logstash-input-rss
Installation successful我们可以使用如下的命令来查看已经安装的插件:
./bin/logstash-plugin list --group input./bin/logstash-plugin list --group filter./bin/logstash-plugin list --group outputFilter
我们很快确定 Logstash 过滤是必要的,以避免摄取重复的文档。根据我们的配置,Logstash 每小时都会从 RSS 提要中提取信息。我们偶尔会得到一份新文件和几份副本。我们会说,“酷!一份提到 Zero Day 的文档!”一个小时后,我们就像,“甜心!这是我们一小时前看到的同一篇文章!” 这很丑陋,我们知道随着我们的前进,它会对我们的分析和研究产生负面影响。我们需要找到一种去重的方法。
我们最初为重复数据删除编写了一个 Python 脚本,该脚本有效但似乎有点大题小做了。进一步的研究将我们引向了 Alexander Marquardt 的博客,在 Elasticsearch 中对文档进行重复数据删除,这反过来又将我们引向了 Elastic 的 fingerprint filter plugin —— 一个更简单且同样有效的解决方案。
当事件插入 Elasticsearch 时,我们使用指纹过滤器插件创建一致的文档 ID。这种方法意味着可以更新现有文档而不是创建新文档。
filter
fingerprint
key => "1234ABCD"
method => "SHA256"
source => ["message"]
target => "[@metadata][generated_id]"
concatenate_sources => true
if "the register" in [tags] or "talos" in [tags]
mutate
copy => "[updated]" => "[published]"
else
mutate
remove_field => [ "[message]", "[Feed]" ]
该插件引用 message 字段(在下图中显示为 event.original)作为 source。 提取文档时,会生成 SHA-256 哈希并填充文档 _id 。 如果随后通过 RSS 提要提取相同的消息,它不会创建新文档,而是更新匹配的文档。
我们发现的一个缺点是存在异常情况,其中重复 message 由于细微的变化而未被识别为重复消息。 像 “the” 这样的定冠词的出现可能会导致新消息被解释为不同,从而导致创建新文档。 我们目前正在测试 title 字段以替换 message 字段,以期修复异常值。
我们的项目还包含一个专门讨论我们在增强和更新此项目时遇到的问题的部分。下面是关于对上面的 filter 部分的讲解:
| 参数 | 描述 |
|---|---|
| key | 要使用的 fingerprint 方法。 值可以是以下任意值:SHA1、SHA256、SHA384、SHA512、MD5、MURMUR3、MURMUR3_128、IPV4_NETWORK、UUID、PUNCTUATION。 我们只是选择使用 Alexander Marquardt 的示例键,因为没有默认值,而且有点随意。 |
| method | 我们选择使用 SHA-256 是因为它通常与文件、消息和数据完整性验证相关联。 如果消息发生变化,则哈希值发生变化; 如果消息未更改,则哈希未更改。 |
| source | 其内容将用于创建 fingerprint 的源字段的名称。 我们选择使用 message 字段; message 字段中填充的数据本质上是文章的摘要。 我们认为 message 字段是一个安全的选择,但由于上述异常值,我们正在测试其他字段。 |
| target | 将存储生成的 fingerprint 的字段的名称。 我们将在输出部分对此进行更多讨论,但这是发送 SHA-256 哈希的地方,它充当我们的文档 _id 以减轻我们在初始测试阶段遇到的大量重复。 |
| concatenate_sources | 当设置为 true 并且方法不是 UUID 或 PUNCTUATION 时,插件会在进行 fingerprint 计算之前将源选项中给出的所有字段的名称和值连接成一个字符串(如旧的 checksum 和过滤器)。 我们需要这个。 我们没有尝试过,但我们得到了重复。 |
| mutate (copy) | 将现有字段复制到另一个字段。 我们注意到几个 RSS 提要在一个名为 updated 与 published 的字段中发布日期。 我们还认识到大多数将发布日期值发送到 published 字段。 多数人获胜,我们决定将 updated 的值复制到 published。 我们希望为可视化和仪表板保持指定时间字段的一致性。 |
| mutate (remove field) | 如果此过滤器成功,则从此事件中删除任意字段。 我们选择使用它,这纯粹是一个创造性的决定(哈!)。 我们不是保留多余字段的忠实拥护者。 我们是 Elasticians,我们的很多工作是数据验证和确保用户随时随地进行优化。 Feed 字段将我们重定向到不可读的内容,并且 message 字段本质上被复制到 event.original(每个 ECS),因此它本质上是重复的值(也就是不必要的)。 |
| conditionals (if and else) | 我们注意到 Cisco Talos 和 The Register 将其发布日期发送到字段 updated,而不是 published; 它们是异常值,因为大多数将发布日期发送到 published,因此我们创建了一个导致一致时间字段的条件。 |

Ouput
对于 output plugin,我们使用了 stdout、 dots codec 和 elasticsearch plugins。
output
stdout codec => dots
elasticsearch
index => "rss-feed"
document_id => "%[@metadata][generated_id]"
hosts => ["localhost"]
在上面,它是针对没有安全设置的 Elasticsearch 集群发送信息。如果你的机器带有基本安全及 HTTPS 配置,那么你需要阅读我之前的文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。 为了配置能够向含有 HTTPS 配置的集群发送信息,我们可以使用如下的这个配置:
root@liuxgu:/etc/logstash/conf.d# pwd
/etc/logstash/conf.d
root@liuxgu:/etc/logstash/conf.d# ls
rss-security-feed.conf truststore.p12在上面,我们的 truststore.p12 是由文章 “Logstash:如何连接到带有 HTTPS 访问的集群” 中的方法所生成的。rss-security-feed.conf 的内容如下:
input
rss
id => "zdi"
url => "https://www.zerodayinitiative.com/rss/published/"
interval => 3600
tags => ["zero day initative"]
rss
id => "dark_reading"
url => "https://www.darkreading.com/rss.xml"
interval => 3600
tags => ["dark reading"]
rss
id => "bleeping_computer"
url => "https://www.bleepingcomputer.com/feed/"
interval => 3600
tags => ["bleeping computer"]
rss
id => "hacker_news"
url => "https://feeds.feedburner.com/TheHackersNews"
interval => 3600
tags => ["hacker news"]
rss
id => "register"
url => "https://www.theregister.com/security/headlines.atom"
interval => 3600
tags => ["the register"]
rss
id => "krebs"
url => "https://krebsonsecurity.com/feed/"
interval => 3600
tags => ["krebs on security"]
rss
id => "cisa"
url => "https://www.cisa.gov/uscert/ncas/current-activity.xml"
interval => 3600
tags => ["cisa cybersecurity advisories"]
rss
id => "cisco_talos_threats"
url => "https://blog.talosintelligence.com/feeds/posts/default/-/threats"
interval => 3600
tags => ["talos"]
rss
id => "cisco_talos_vulnerabilities"
url => "https://blog.talosintelligence.com/feeds/posts/default/-/vulnerabilities"
interval => 3600
tags => ["talos"]
rss
id => "knowbe4"
url => "https://blog.knowbe4.com/rss.xml"
interval => 3600
tags => ["knowbe4"]
rss
id => "threatpost"
url => "https://threatpost.com/feed/"
interval => 3600
tags => ["threatpost"]
rss
id => "troy_hunt"
url => "https://feeds.feedburner.com/TroyHunt"
interval => 3600
tags => ["troy hunt"]
rss
id => "malware_bytes"
url => "https://www.malwarebytes.com/blog/feed/index.xml"
interval => 3600
tags => ["malwarebytes"]
rss
id => "graham_cluley"
url => "https://feeds.feedburner.com/grahamcluley"
interval => 3600
tags => ["graham cluley"]
rss
id => "microsoft"
url => "https://www.microsoft.com/security/blog/feed/"
interval => 3600
tags => ["microsoft security"]
rss
id => "daily_swig"
url => "https://portswigger.net/daily-swig/rss"
interval => 3600
tags => ["daily swig"]
rss
id => "sophos"
url => "http://feeds.feedburner.com/NakedSecurity"
interval => 3600
tags => ["sophos"]
filter
fingerprint
key => "1234ABCD"
method => "SHA256"
source => ["message"]
target => "[@metadata][generated_id]"
concatenate_sources => true
if "the register" in [tags] or "talos" in [tags]
mutate
copy => "[updated]" => "[published]"
else
mutate
remove_field => [ "[message]", "[Feed]" ]
output
stdout codec => dots
elasticsearch
index => "rss-feed"
document_id => "%[@metadata][generated_id]"
hosts => ["https://192.168.0.3:9200"]
user => "elastic"
password => "+55gU0JB1kxTFX3eJeEZ"
ssl_certificate_verification => true
truststore => "/etc/logstash/conf.d/truststore.p12"
truststore_password => "password"
在上面,我们在 hosts 中定义了 Elasticsearch 集群的终端地址。我们需要根据自己的配置进行相应的修改。
关于这个部分的说明如下:
| 参数 | 描述 |
|---|---|
| stdout(dots codec) | 此编解码器生成一个点 (.) 来表示它处理的每个事件。 这通常与标准输出一起使用,以在终端上提供反馈。 在我们进行故障排除时,stdout 非常有用,但现在我们使用的是 pipelines.yml,而不是通过命令行将配置作为文件传递,因此我们对它的依赖减少了。 |
| elasticsearch | Elasticsearch 输出插件可以在 Elasticsearch 中存储时间序列数据集和非时间序列数据。 我们正在使用它来搜索我们的网络安全新闻内容。 |
| index | 要将事件写入的索引。 我们选择将我们的索引命名为 rss-feed 是因为我们希望让事情尽可能简单和具有描述性。 |
| document_id | 索引的文档 ID。 用于覆盖 Elasticsearch 中具有相同 ID 的现有条目。 我们需要使用 document_id,因为这是从fingerprint 过滤器插件中设置 SHA-256 哈希值的地方,以防止重复文档。 |
| hosts | 设置远程实例的主机。 我们利用此设置将数据路由到我们的 Elasticsearch 实例。 |
Elasticsearch
我们将所有 RSS 文档发送到 Elasticsearch,这让我们有机会执行近乎实时的搜索和分析。 在初始测试阶段,我们利用了 Elasticsearch 的动态映射功能,因此我们可以快速开始探索数据。 RSS 数据生成的字段不多,字段名称也比较一致,所以我们并不太担心映射爆炸或字段过多的情况。
当我们检查数据和字段时,我们发现,正如预期的那样,字符串字段被分配了多种数据类型:text 和 keyword。 结果,我们看到两个名称不同的字段包含相同的数据:
author: John Smith
author.keyword: John Smith
我们创建了 component templates 和 index templates来控制具有多种数据类型的重复字段的创建。 我们使用 component templates 来显式创建映射,因为 component templates 是模块化的,可以重复用于各种索引模板。 我们也可以仅通过 index templates 来设置映射,因为我们不太可能将这些特定映射用于任何其他数据集。 我们选择添加 component templates 以提高整体效率和优化。
PUT _component_template/rss-feed
"template":
"settings":
"index":
"number_of_replicas": "0"
,
"mappings":
"properties":
"event.original":
"type": "text"
,
"author":
"type": "keyword"
,
"link":
"type": "keyword"
,
"published":
"type": "date"
,
"title":
"type": "keyword"
,
"updated":
"type": "date"
,
"@version":
"type": "keyword"
,
"tags":
"type": "keyword"
我们不会用太多细节让你厌烦,但想强调几点:
- 我们将 keyword 数据类型用于我们想要的任何字段 1) 用于聚合和 2) 我们不一定认为需要全文搜索功能。
- 我们确实根据 Elastic Common Schema (ECS) 定义和设置,把 event.original 字段原本的 keyword 数据类型更改为 text 类型 。 我们想通过 event.original 字段利用全文搜索来创建某些过滤器。 如上所述,我们选择删除 message 字段, 我们的决定纯粹是基于个人喜好。
我们创建的 index template 非常基础。 我们将索引模式设置为 rss*,因此我们创建的任何索引(在这种情况下,我们创建了 rss-feed,如在 Logstash 输出中的索引设置中看到的那样 (index => rss-feed)),前缀为 rss 将继承相关的设置 使用我们创建的 component template 和 index template。
PUT _index_template/rss-feed
"index_patterns": [
"rss*"
],
"composed_of": [
"rss-feed"
]
使用 index template 和 component template,我们能够有效地删除以 .keyword 结尾的六个字段,并将数据映射到对我们的用例更有效的类型。
在配置完上面的 index template 后,我们可以开始启动 Logstash 里。我们在 Linux 的 terminal 中打入如下的命令:
service logstash restart我们使用如下的命令来检查 Logstash 的运行状态:
service logstash status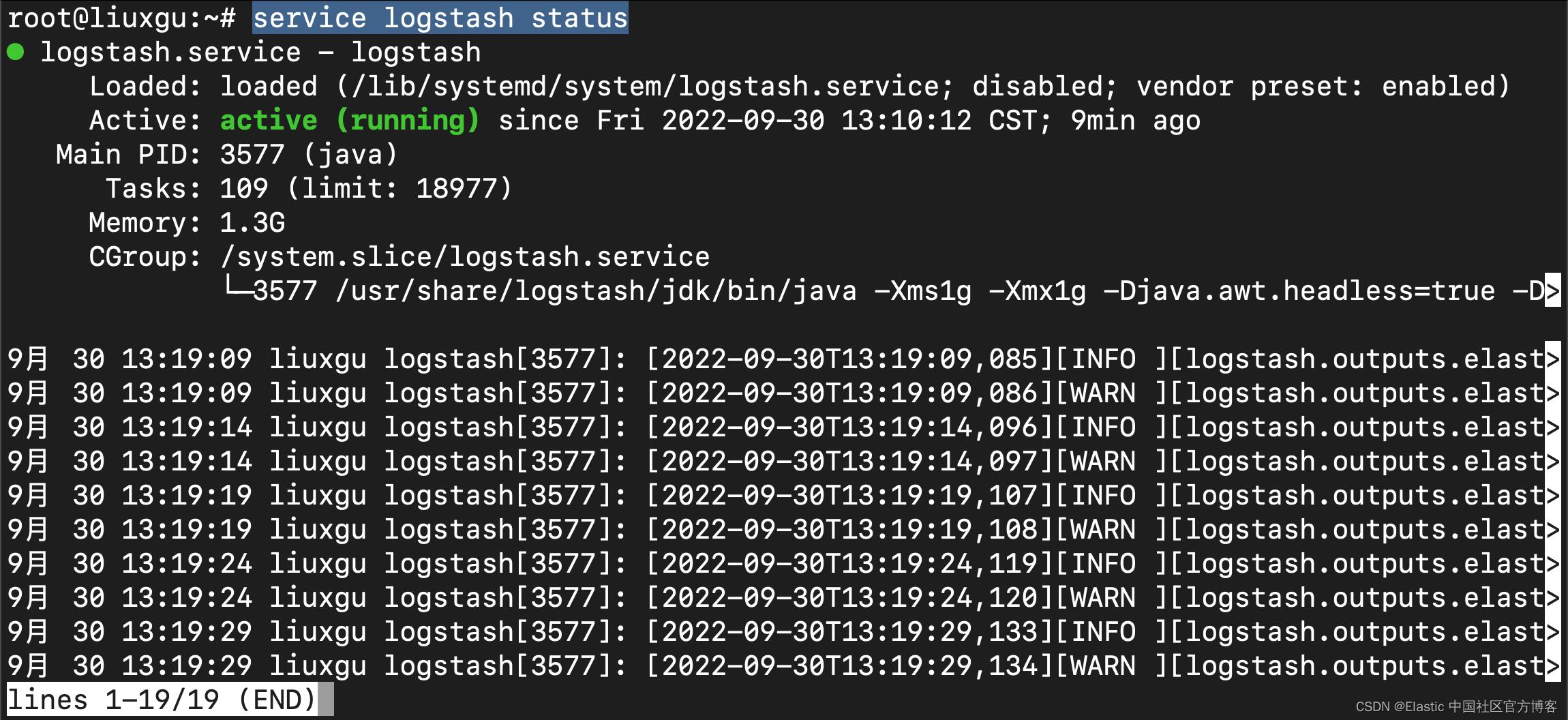
上面显示 logstash 服务在正常运行。我们可以使用如下的命令来检查这个服务的输出日志,以确保它没有任何的错误出现:
journalctl -u logstash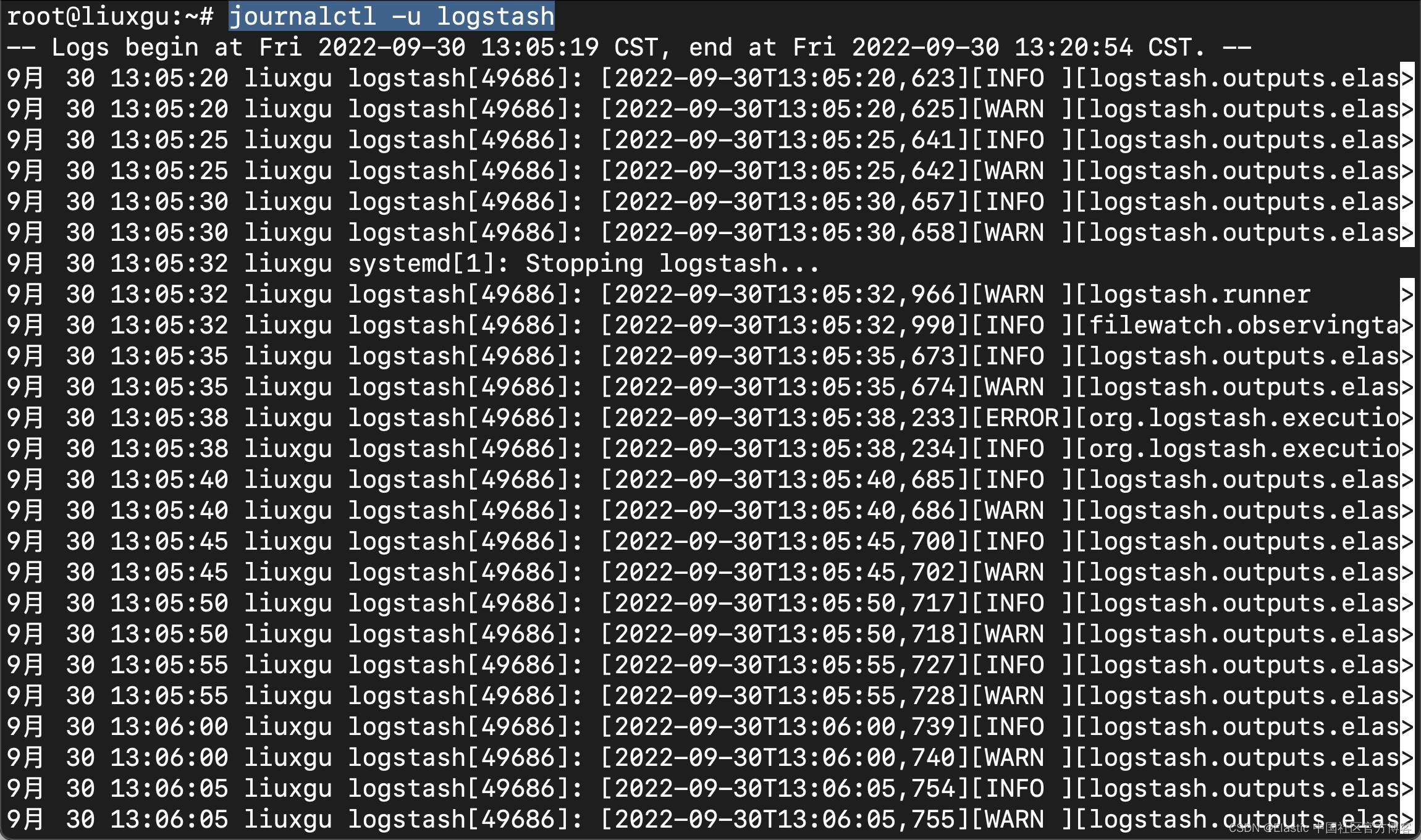
如果我们没有看到任何的错误出现,那么它表明我们的 logstash 服务是正常的。
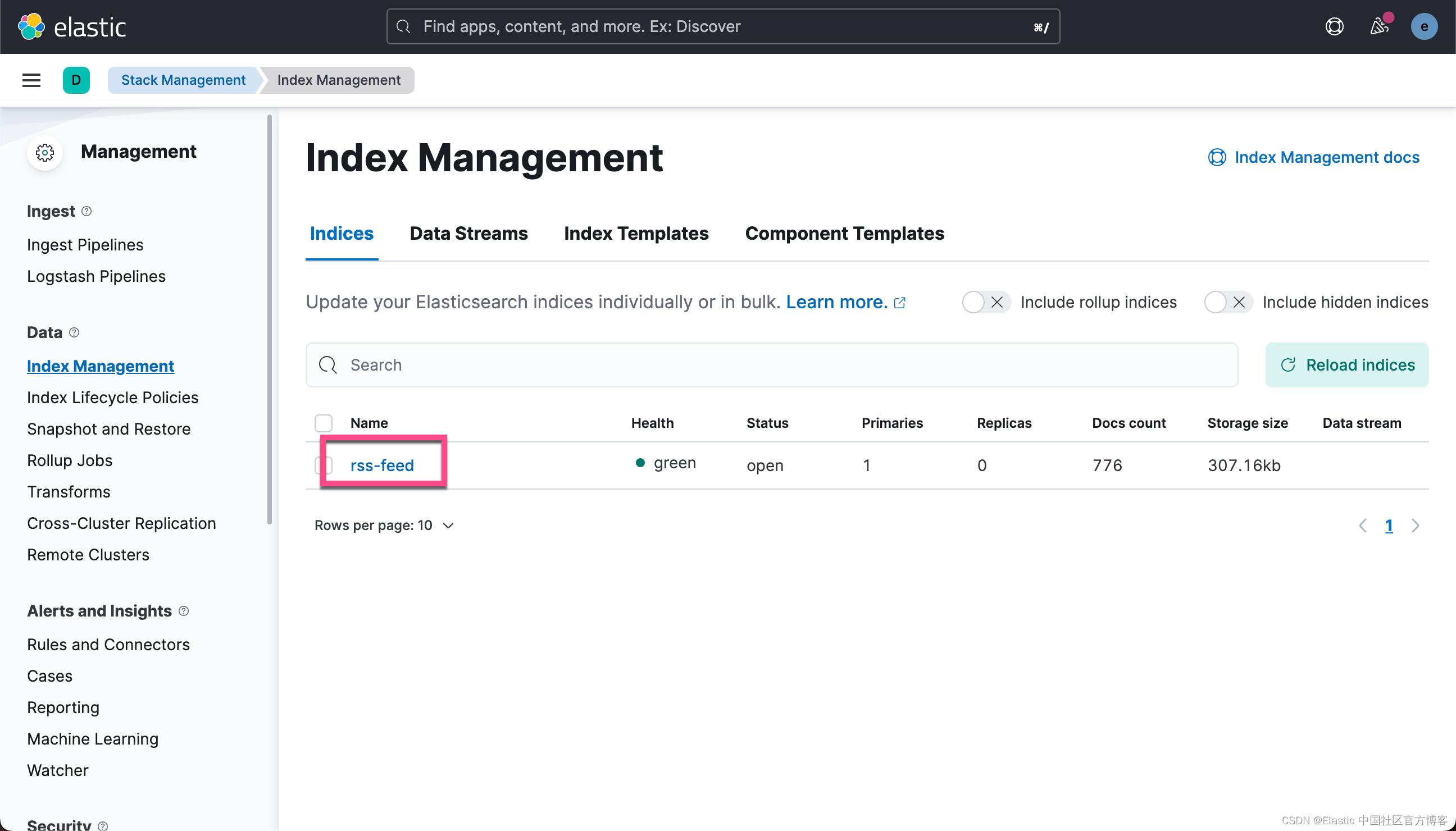
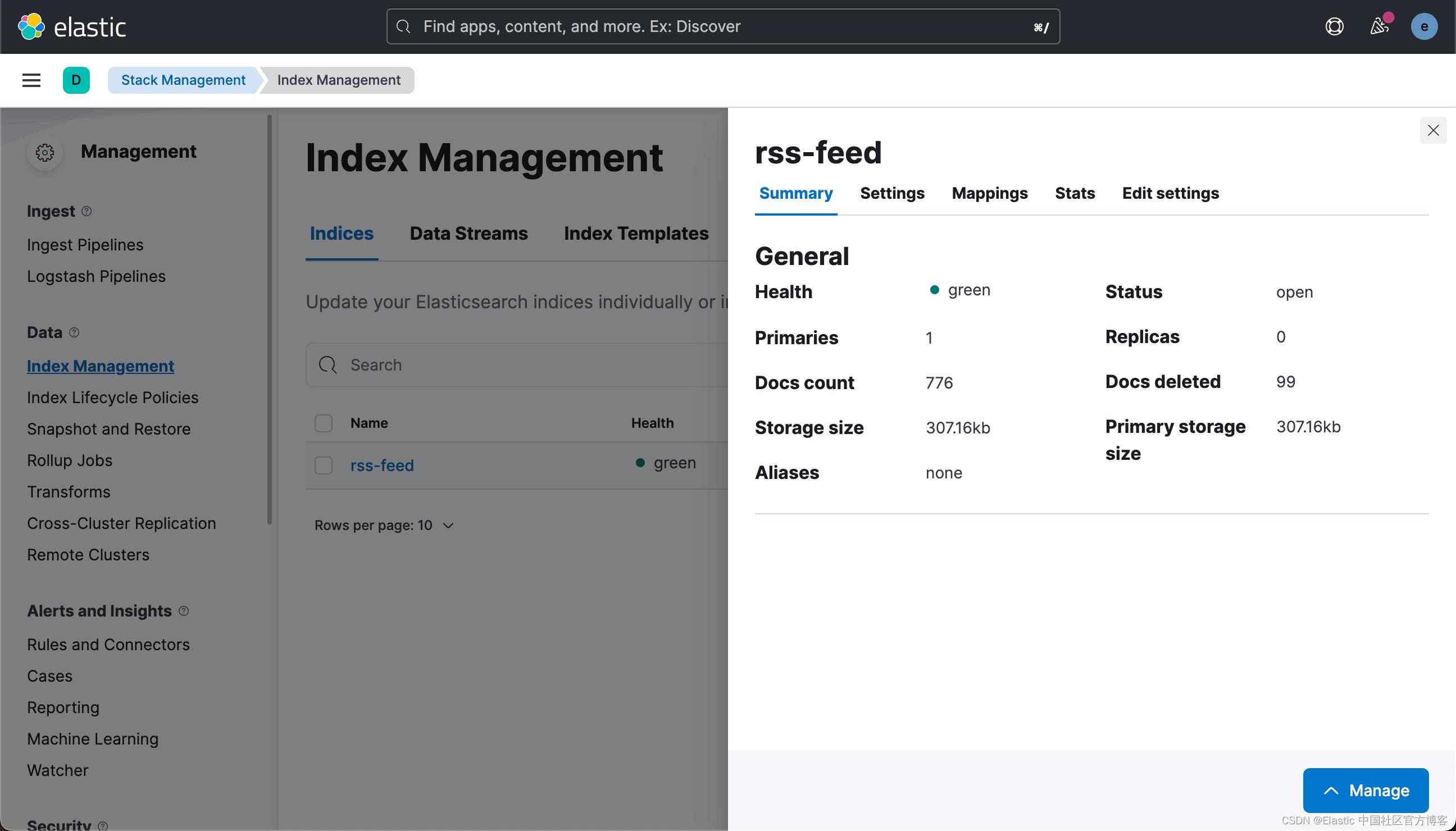
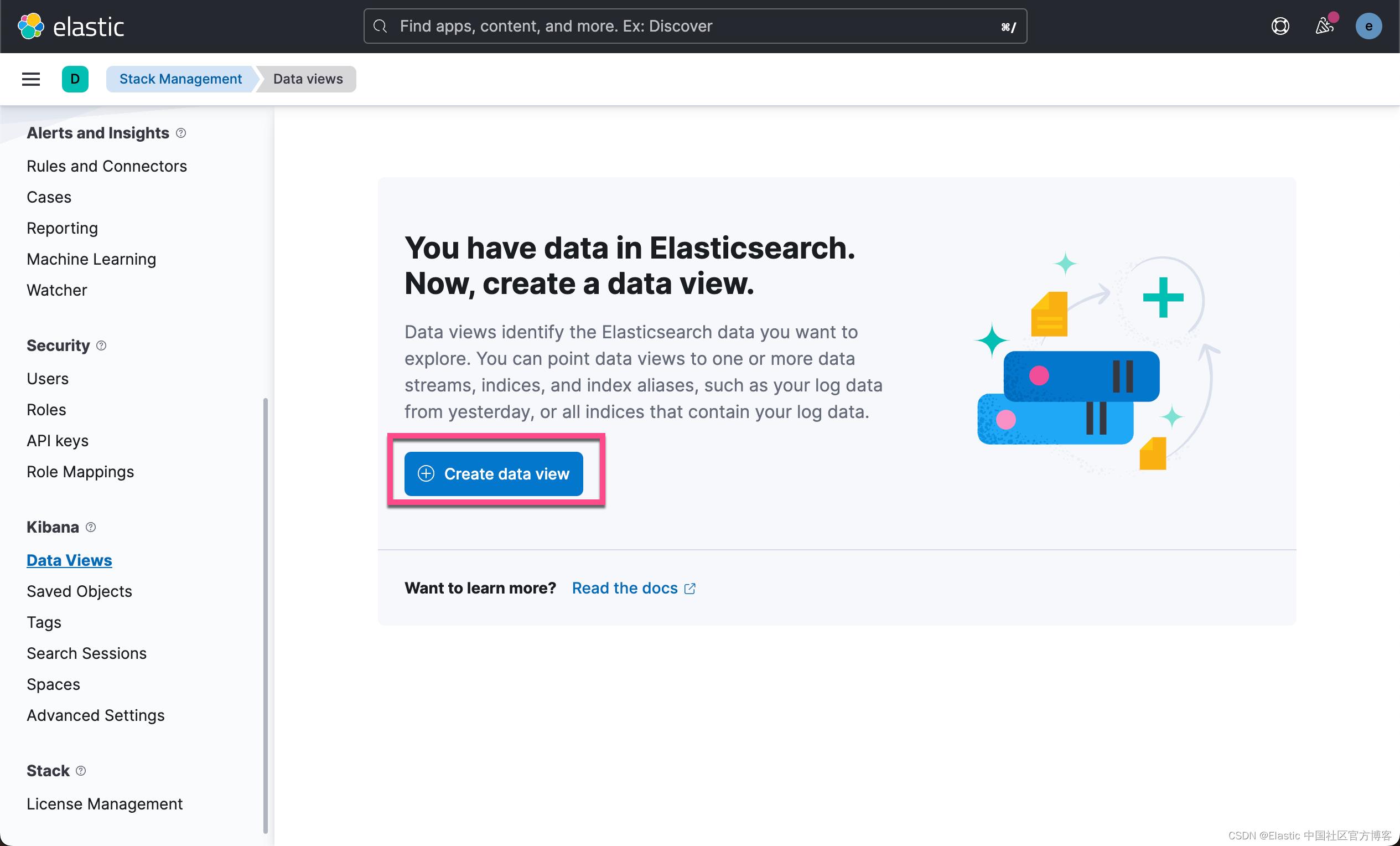
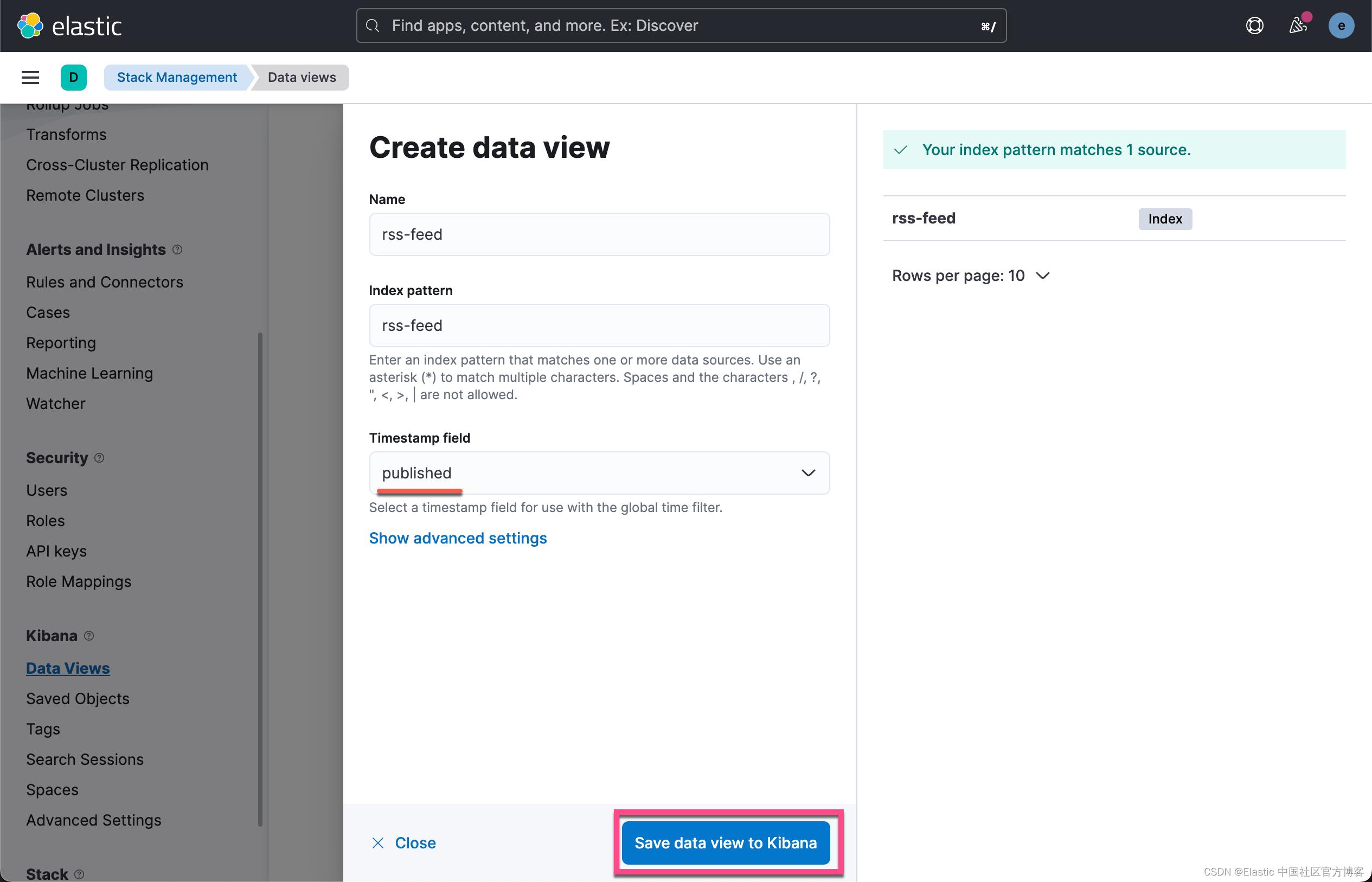
我们可以为这个索引创建一个 Data View:

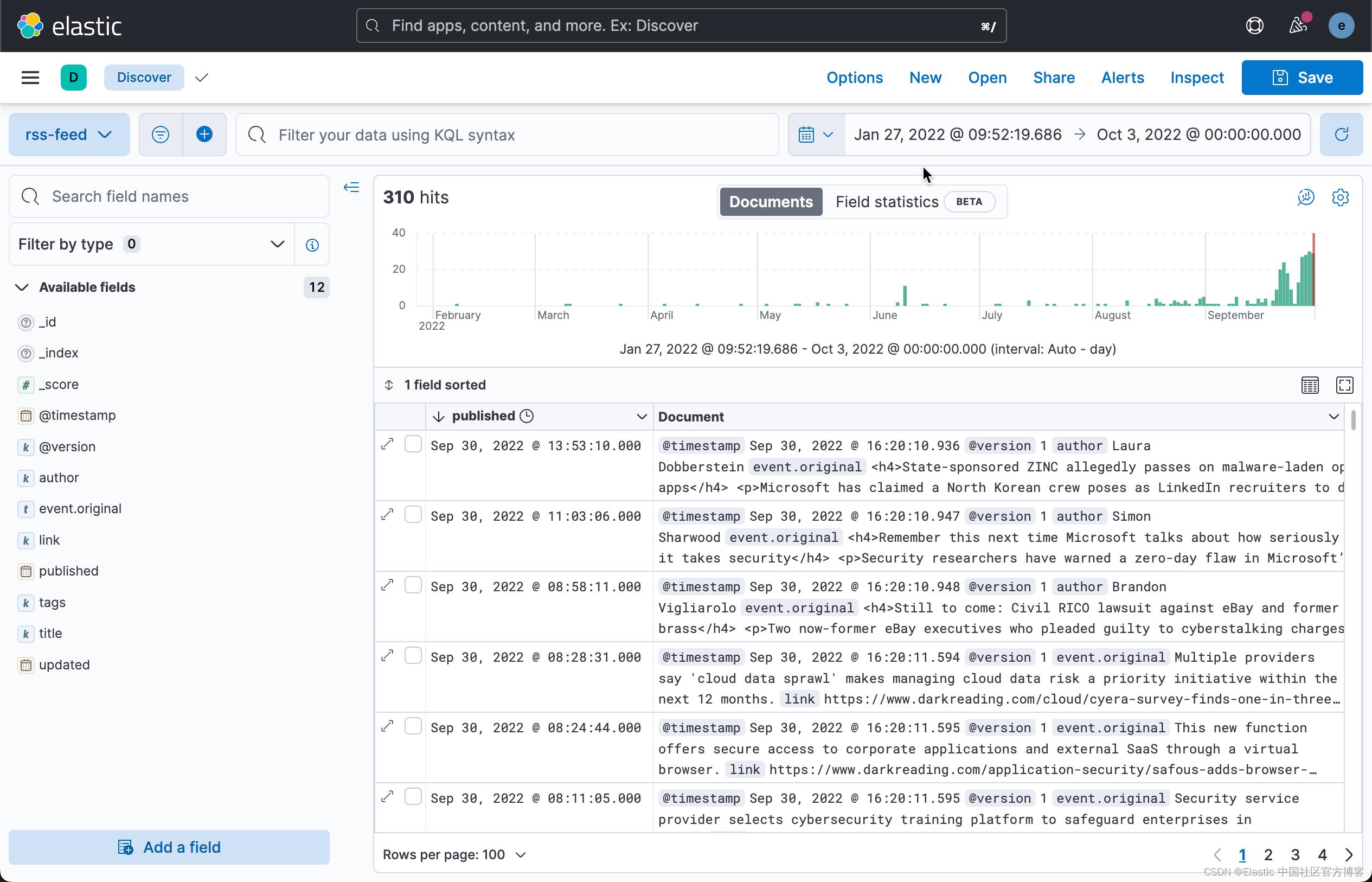
经过一段时间的运行,我们可以查看收集到的文档个数:
GET rss-feed/_count
"count": 310,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
上面显示有 310 个文档已经被收集到了。
Kibana
Kibana 是我们最喜欢的部分。 作为前 SOC 分析师,我们享受 Kibana 通过 Discover 以及可视化和仪表板提供的分析功能。 在这里,我们可以审查和筛选正在摄取的网络安全内容。
注意:一下的这些可视化图是基于之前的数据所做的展示。它们和上面展示的 310 数据集是不同的数据。
我们决定使用 Lens 和基于聚合的可视化组合来创建仪表板:
- 显示在特定时间跨度内摄取的文章、博客等数量的指标

- 条形图显示在特定时间跨度内发布和摄取的博客、文章等的数量

- TSVB 展示了与 Microsoft、Python、Linux、Java 等常见软件和技术相关的趋势。

- 表聚合允许我们按 title、author 和 source/feeds 查看和过滤
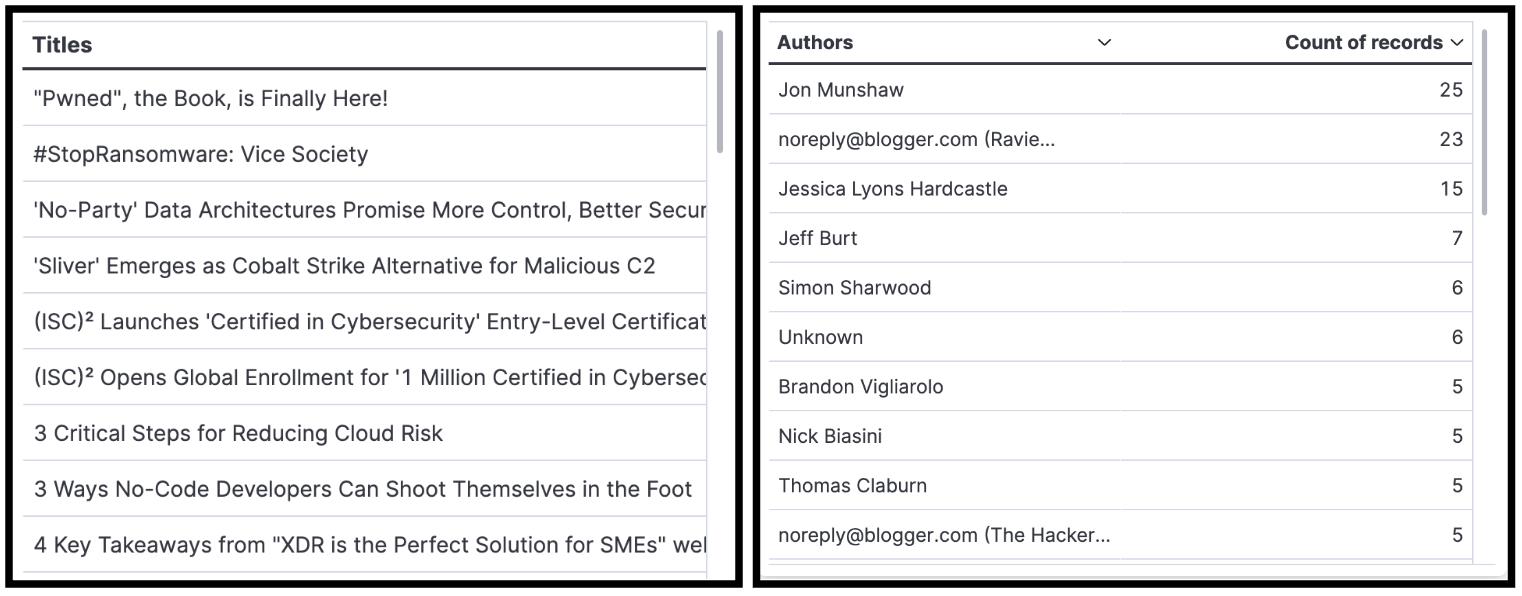
- Treemap 使我们能够按 title 跟踪重复的异常值。 所有百分比都应该相同。 如果其中一个高于其他,则意味着我们抓到了一份重复的文件。 这一直在帮助我们进行故障排除工作。
- Saved search 使我们能够查看完整文档并单击/导航到与文档关联的文章。 我们将 rss-feed 数据视图中的 link 字段更新为 Url 格式,以便我们能够单击并被重定向到文章。
所有 Daved Objects(数据视图、保存的搜索、可视化、仪表板等)都可以通过我们在 GitHub 上的项目进行访问和导入,或者你可以创建自己的对象并向我们提供反馈。
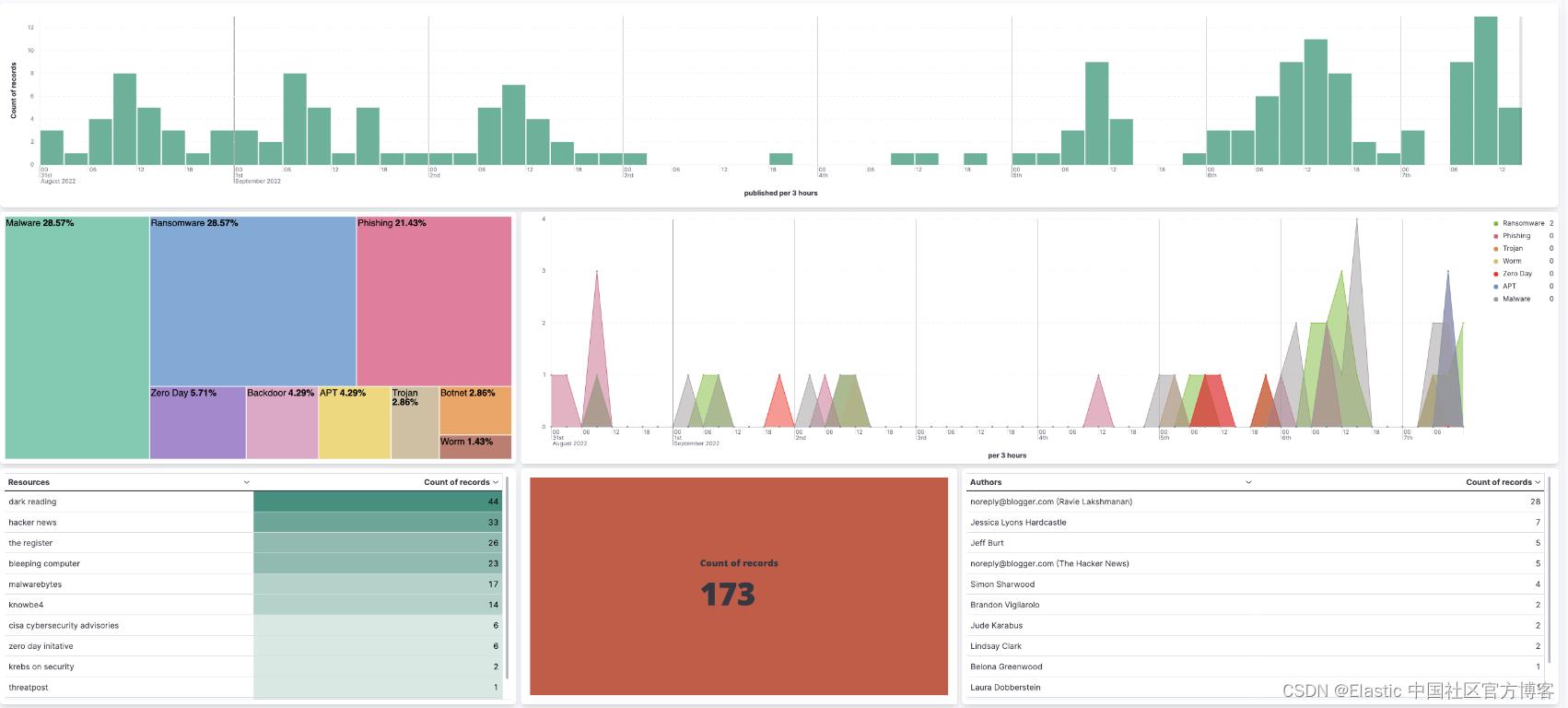
聚合多个新闻文章来源的能力增加了巨大的价值。 该工具与其他 OSINT 工具相结合,可用于缩小在野外看到的潜在攻击的详细信息,并有助于缩短研究时间。 如果你需要快速查找攻击文章或一组恶意软件的特定归属,可以在一个地方进行搜索。 将数据放在一个地方也会隐藏你正在进行的调查。 如果你正在积极搜索文章或攻击,则可以跟踪该活动。 当你提取所有文章时,你的活动被缩小或跟踪的可能性较小,并且你的调查变得更加隐秘。
结论
我们的 A Quick RSS Cybersecurity News Feed 项目使用户能够摄取感兴趣的网络安全内容、整合、聚合、可视化和搜索。 我们很高兴向 OSINT 社区介绍这个解决方案,我们期待维护和增强它。
以上是关于Logstash:如何运用 Elastic Stack 结合 RSS feeds 告知可能性的主要内容,如果未能解决你的问题,请参考以下文章
Observability:如何使用 Elastic Agents 把微服务的数据摄入到 Elasticsearch 中
Elastic:运用 Elastic Maps 实时跟踪,可视化资产分布及地理围栏告警
Elastic:通过 Logstash 或 Kafka 使用 Metricbeat 监控 Elastic Stack