Observability:如何使用 Elastic Agents 把微服务的数据摄入到 Elasticsearch 中
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Observability:如何使用 Elastic Agents 把微服务的数据摄入到 Elasticsearch 中相关的知识,希望对你有一定的参考价值。
在 Elastic Agents 出现之前,我们有很多方法来把微服务的数据摄入到 Elasticsearch 中。我们可以使用各种语言的 client API 直接写入到 Elasticsearch 中,我们也可以使用 Logstash 或者 Filebeat 来进行操作。我们可以阅读之前的文章:
在今天的的文章中,我将使用 Elastic 最新推荐的 Elastic Agents 的方法来做一个展示。在今天的展示中,我将使用 Custom HTTPJSON Input 集成来进行实现。我将使用 Elastic Stack 8.3.3 来进行展示。
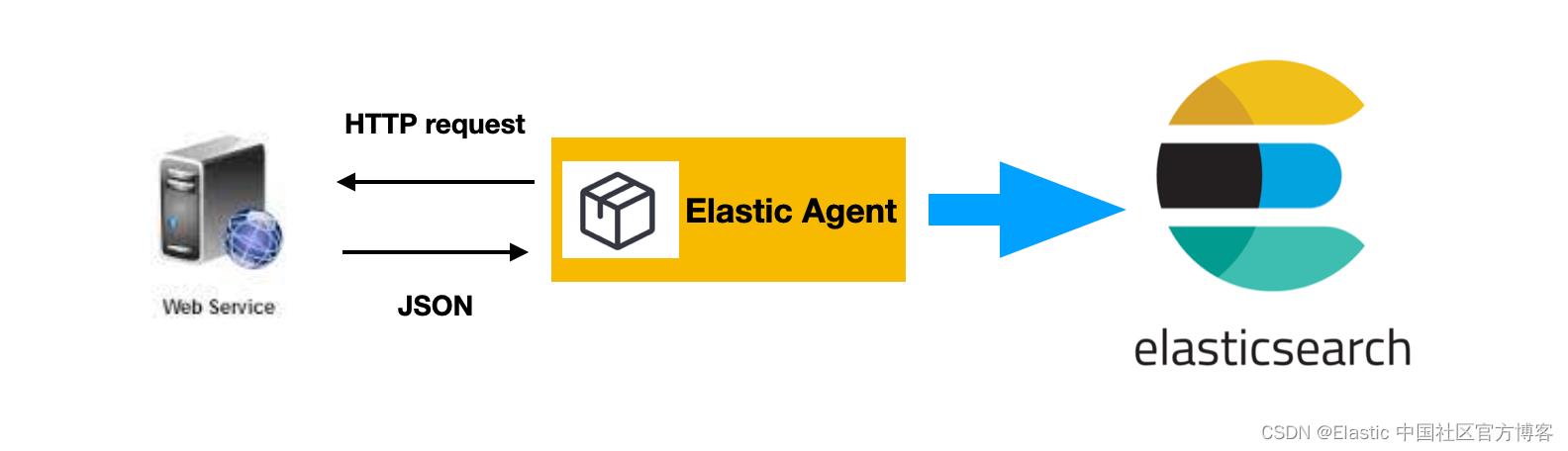
我将使用如下的配置来实现:
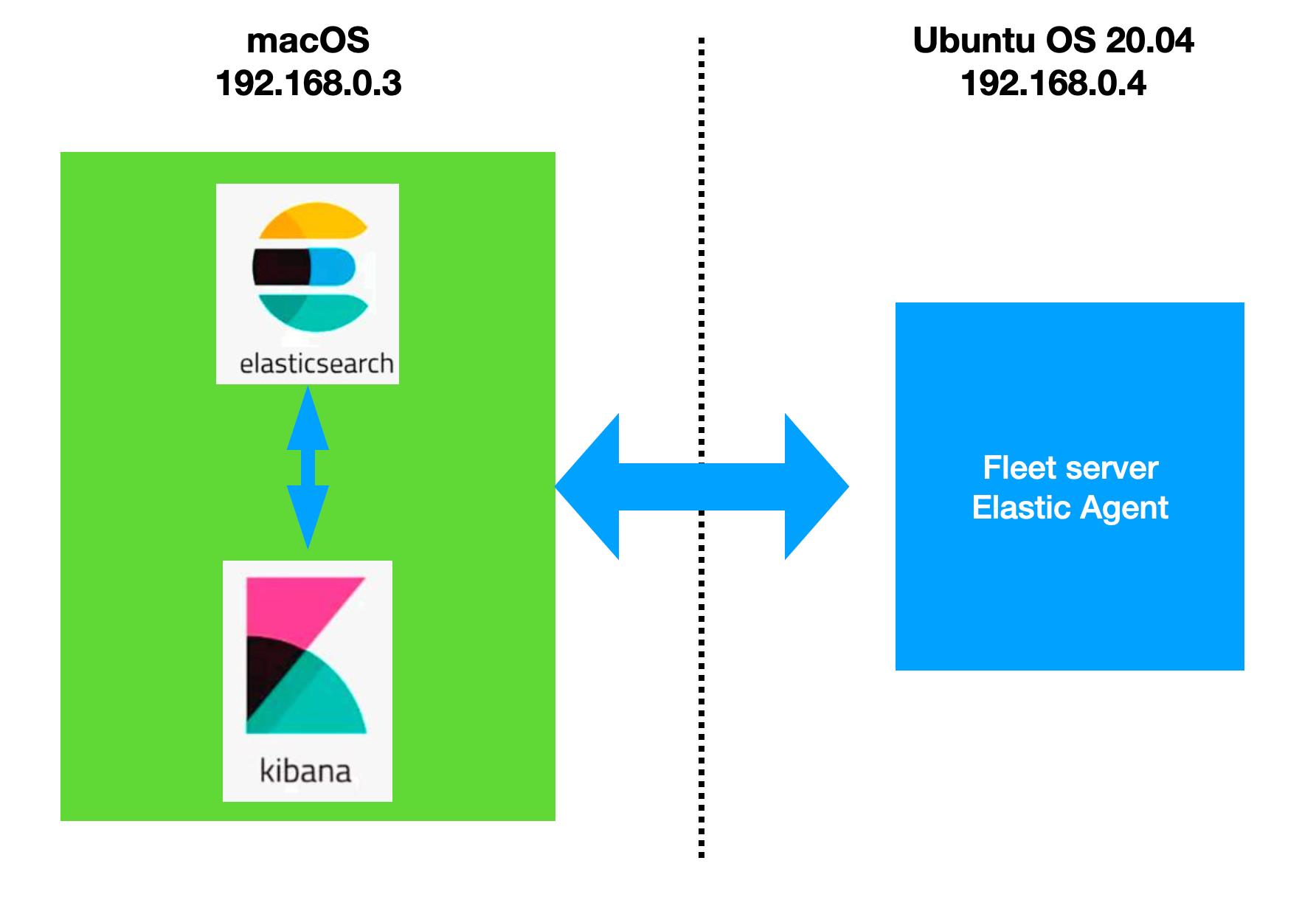
安装
在进行下面的练习之前,我们必须安装好 Elasticsearch 及 Kibana。我们可以参考之前的文章:
我们按照上面的要求进行安装 Elasticsearch 及 Kibana。为了能够让 fleet 正常工作,内置的 API service 必须启动。我们必须为 Elasticsearch 的配置文件 config/elasticsearch.yml 文件配置:
xpack.security.authc.api_key.enabled: true配置完后,我们再重新启动 Elasticsearch。针对 Kibana,我们也需要做一个额外的配置。我们需要修改 config/kibana.yml 文件。在这个文件的最后面,添加如下的一行:
xpack.encryptedSavedObjects.encryptionKey: 'fhjskloppd678ehkdfdlliverpoolfcr'如果你不想使用上面的这个设置,你可以使用如下的方式来获得:
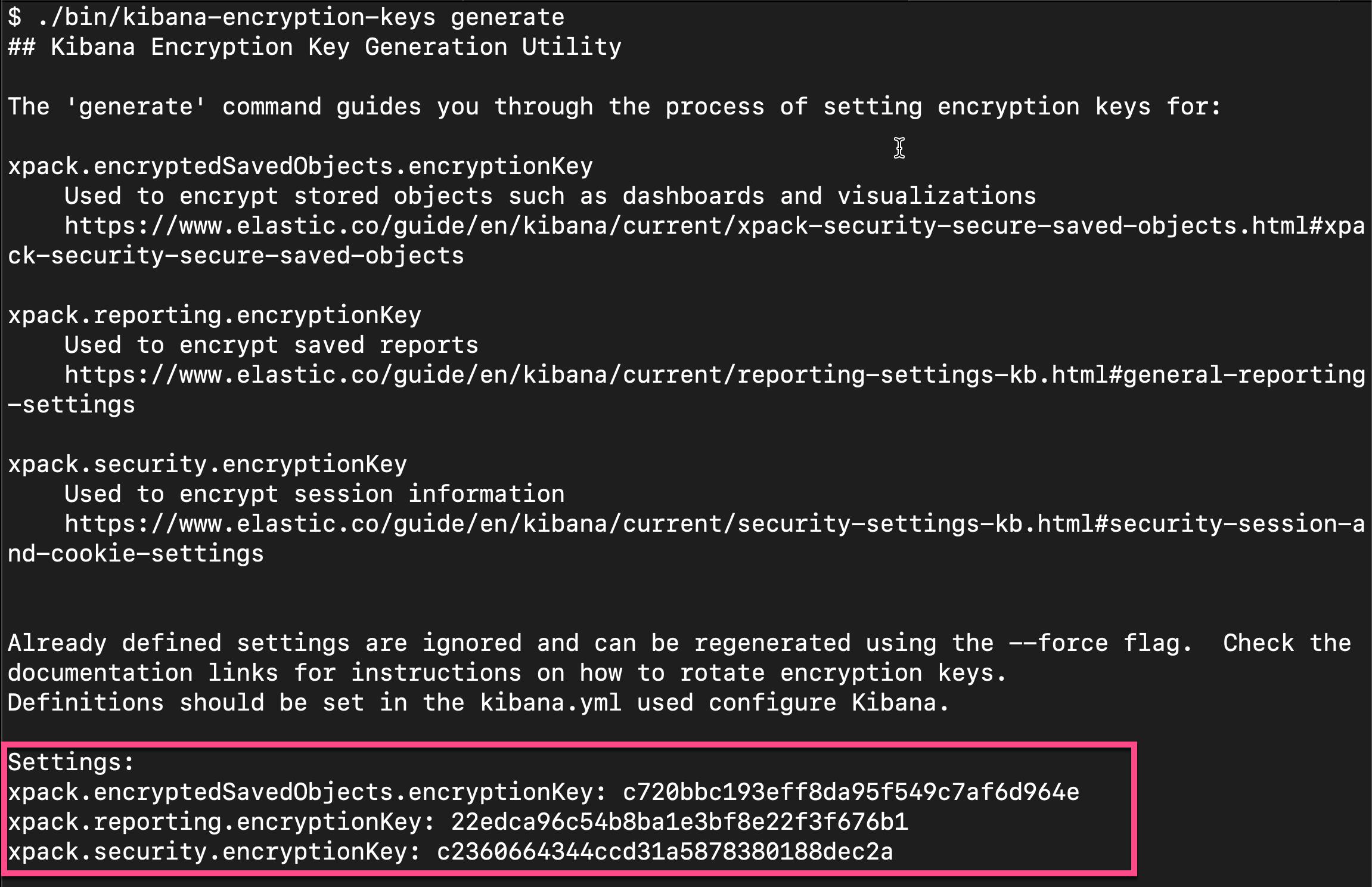
从上面的输出中,我们可以看出来,有三个输出的 key。我们可以把这三个同时拷贝,并添加到 config/kibana.yml 文件的后面。当然,我们也可以只拷贝其中的一个也可。我们再重新启动 Kibana。
这样我们对 Elasticsearch 及 Kibana 的配置就完成。 针对 Elastic Stack 8.0 以前的版本安装,请阅读我之前的文章 “Observability:如何在最新的 Elastic Stack 中使用 Fleet 摄入 system 日志及指标”。
除此之外,Kibana 需要 Internet 连接才能从 Elastic Package Registry 下载集成包。 确保 Kibana 服务器可以连接到https://epr.elastic.co 的端口 443 上 。如果你的环境有网络流量限制,有一些方法可以解决此要求。 有关详细信息,请参阅气隙环境。
目前,Fleet 只能被具有 superuser role 的用户所使用。
配置 Fleet
使用 Kibana 中的 Fleet 将日志、指标和安全数据导入 Elastic Stack。第一次使用 Fleet 时,你可能需要对其进行设置并添加 Fleet Server。在做配置之前,我们首先来查看一下有没有任何的 integration 被安装:
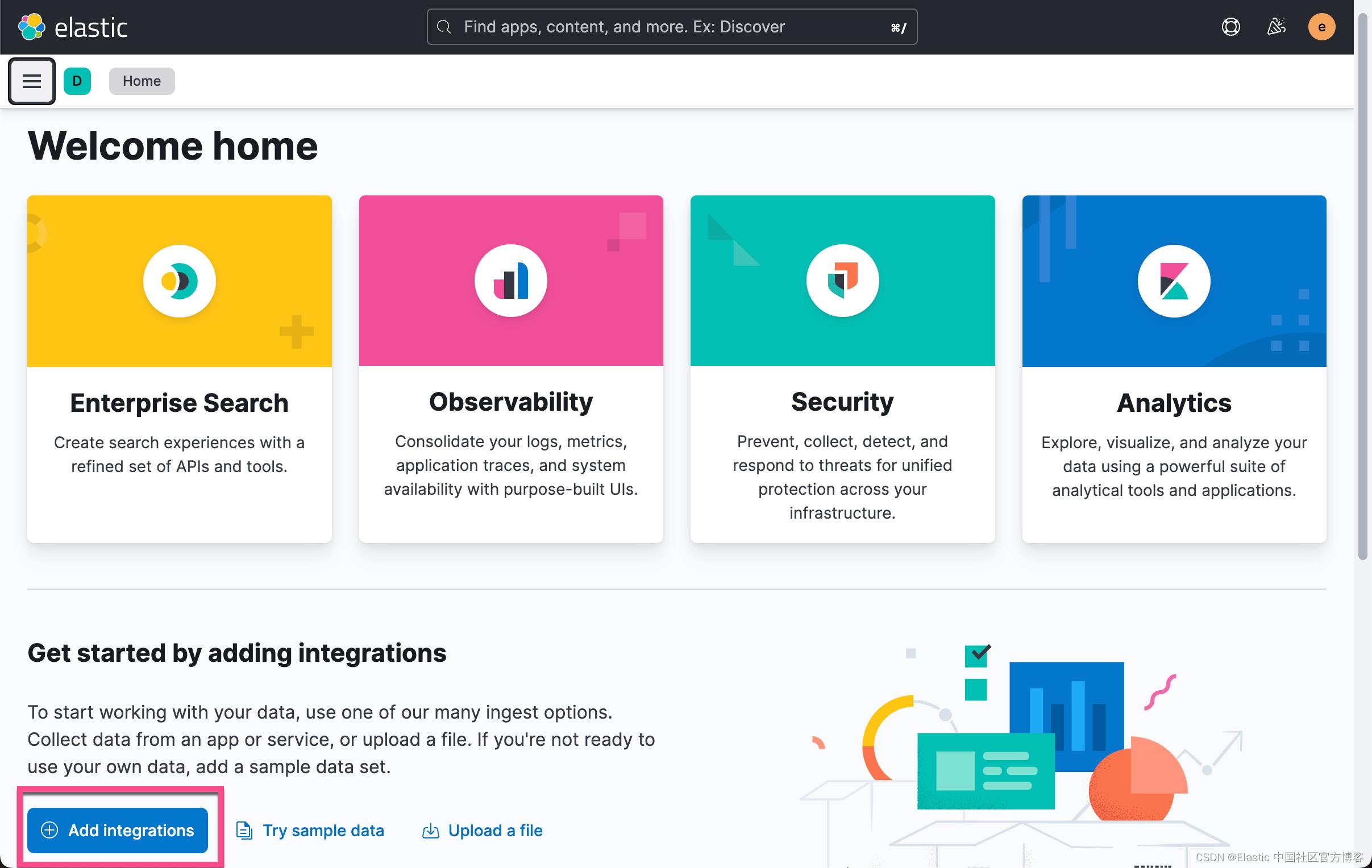
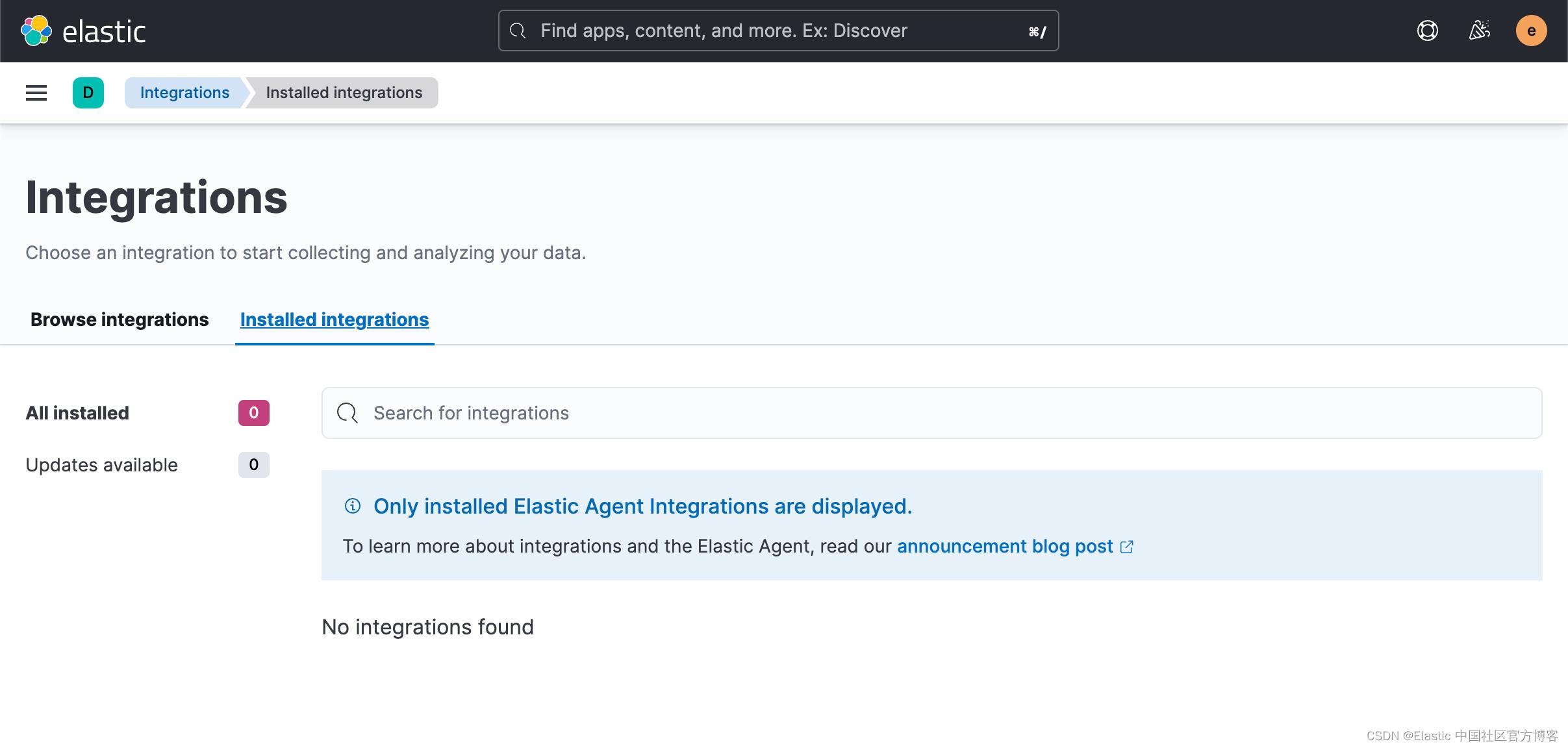 从上面我们可以看出来没有任何安装的 integrations。
从上面我们可以看出来没有任何安装的 integrations。
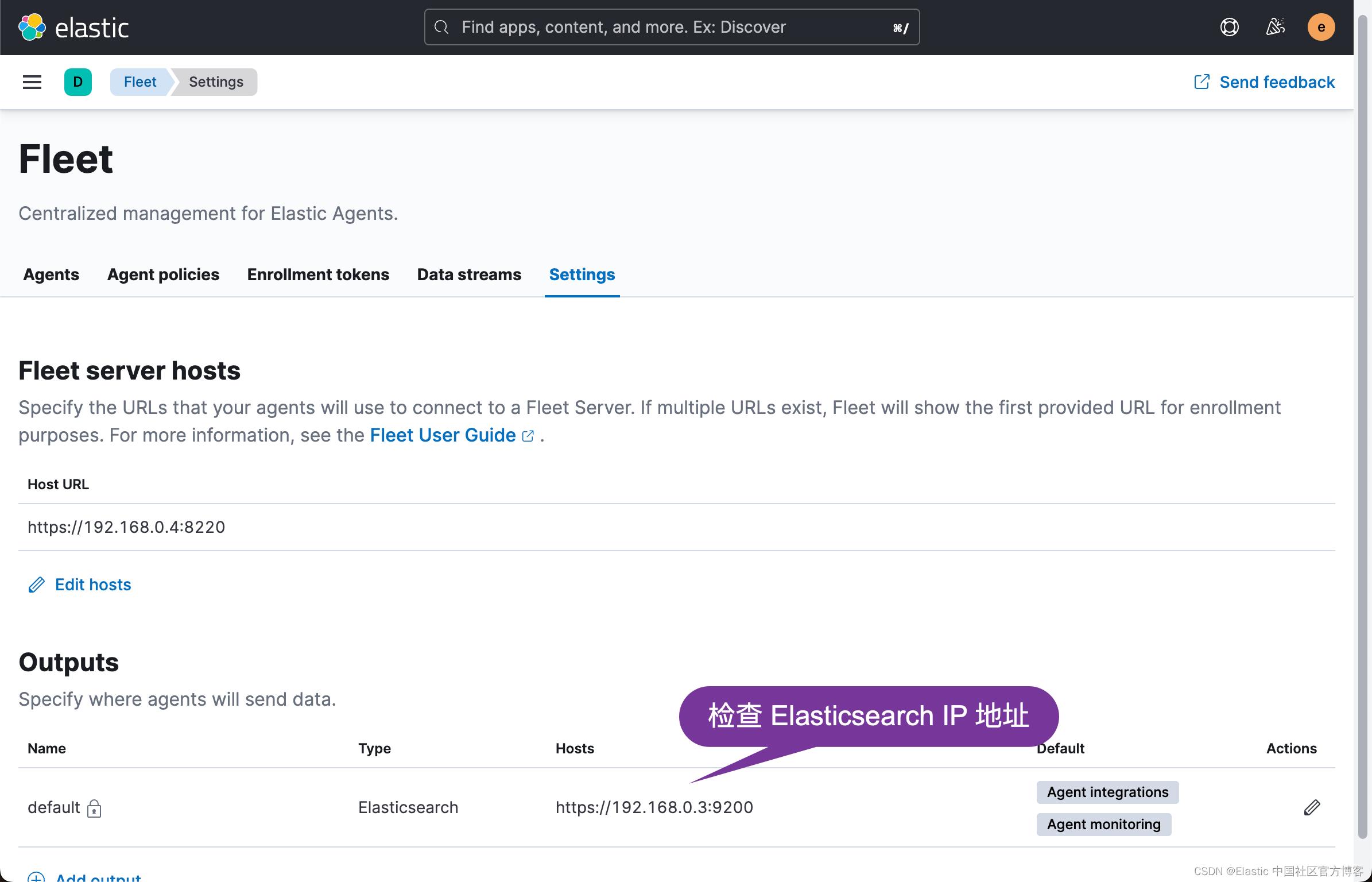
我们打开 Fleet 页面:
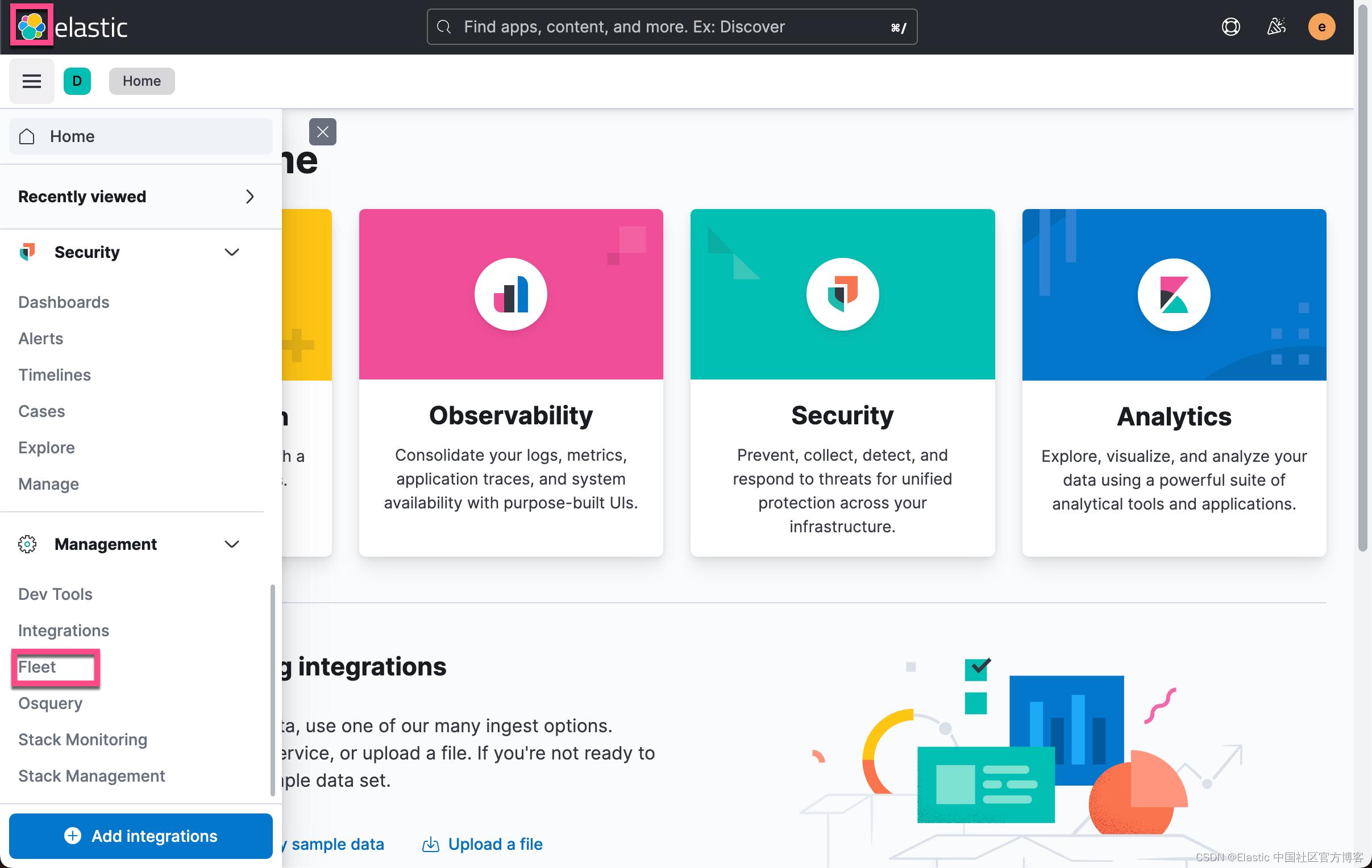
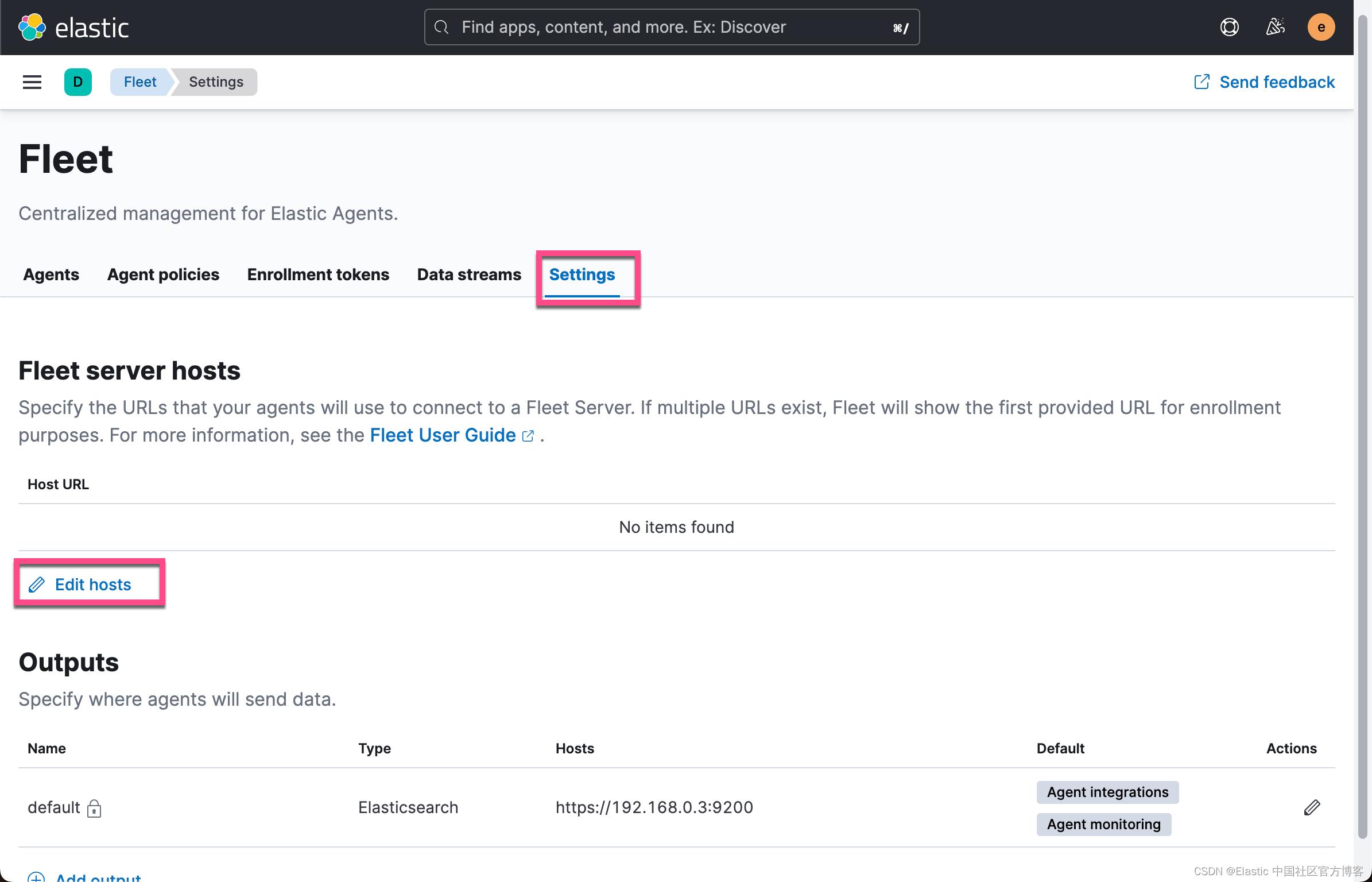
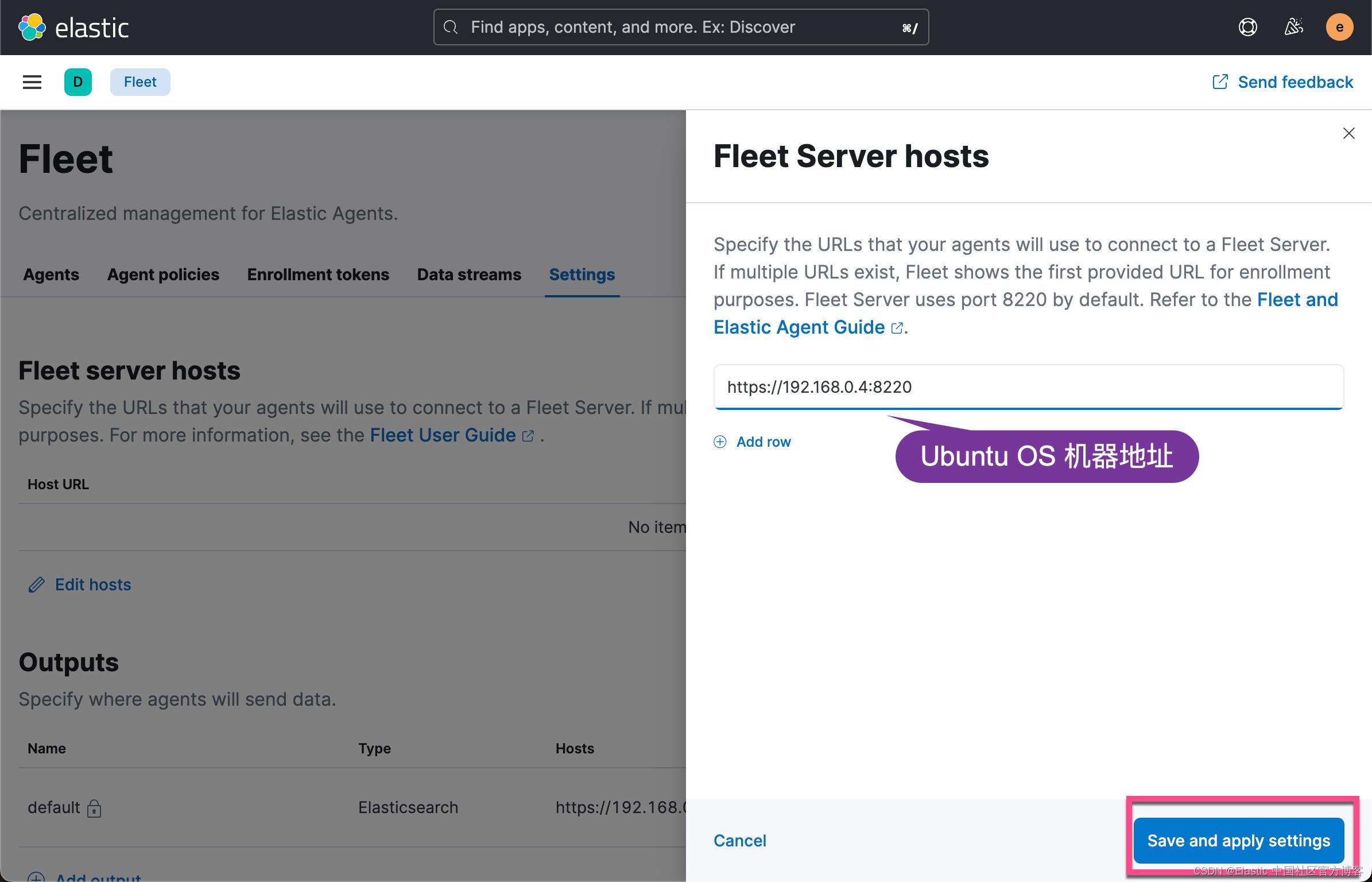
我们接下来添加 Agent:
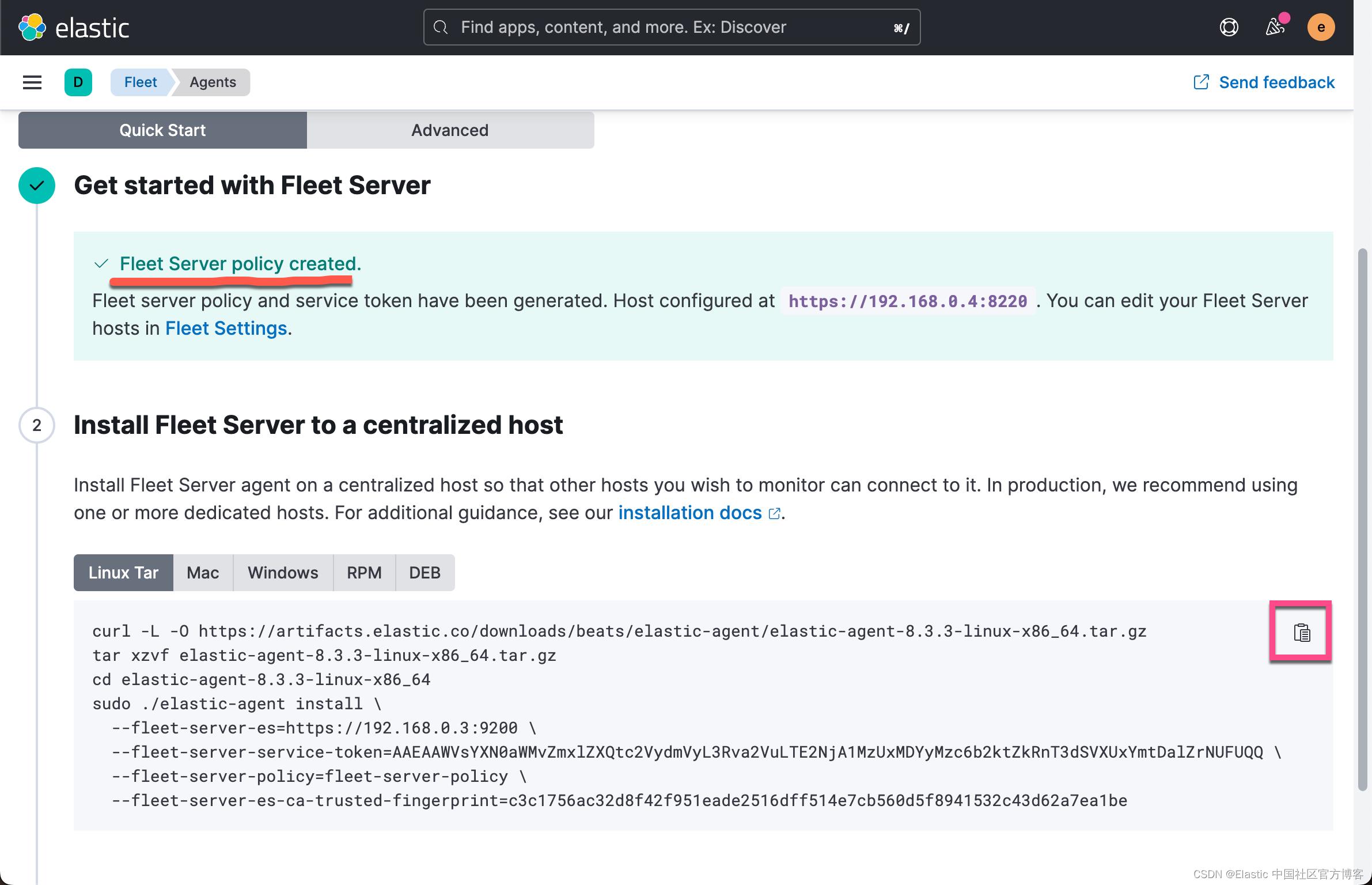 上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。
上面显示我们的 Fleet Sever policy 被成功地创建了。我们需要把我们的 Fleet Server 安装到 Ubuntu OS 机器上。
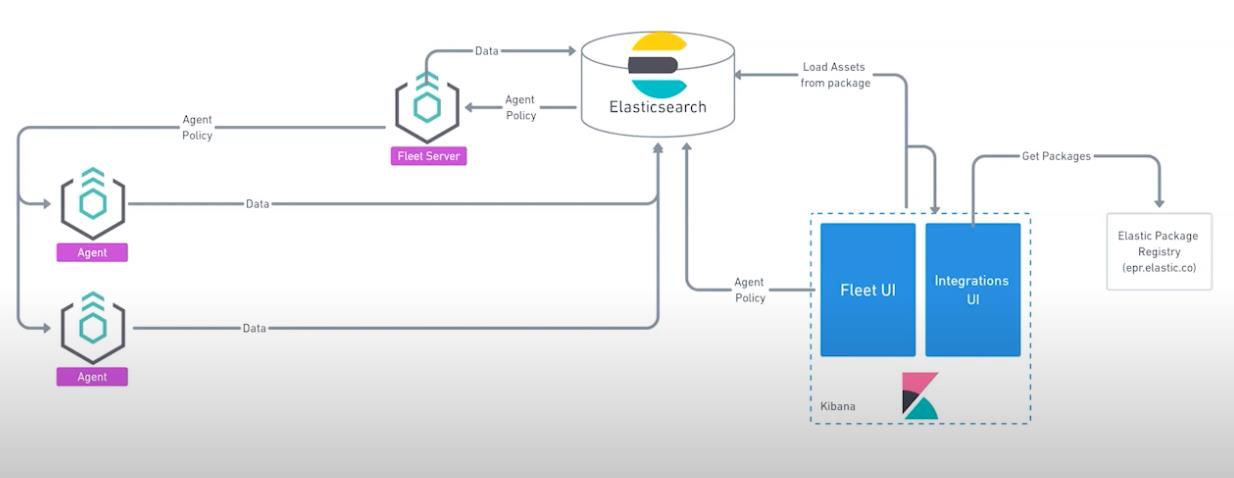
我们的目标机器是 Linux OS。我们点击上面的拷贝按钮,并在 Linux OS 上进行安装:
curl -L -O https://artifacts.elastic.co/downloads/beats/elastic-agent/elastic-agent-8.3.3-linux-x86_64.tar.gz
tar xzvf elastic-agent-8.3.3-linux-x86_64.tar.gz
cd elastic-agent-8.3.3-linux-x86_64
sudo ./elastic-agent install \\
--fleet-server-es=https://192.168.0.3:9200 \\
--fleet-server-service-token=AAEAAWVsYXN0aWMvZmxlZXQtc2VydmVyL3Rva2VuLTE2NjA1MzUxMDYyMzc6b2ktZkRnT3dSVXUxYmtDalZrNUFUQQ \\
--fleet-server-policy=fleet-server-policy \\
--fleet-server-es-ca-trusted-fingerprint=c3c1756ac32d8f42f951eade2516dff514e7cb560d5f8941532c43d62a7ea1be我们按照 Kibana 中的提示来安装:

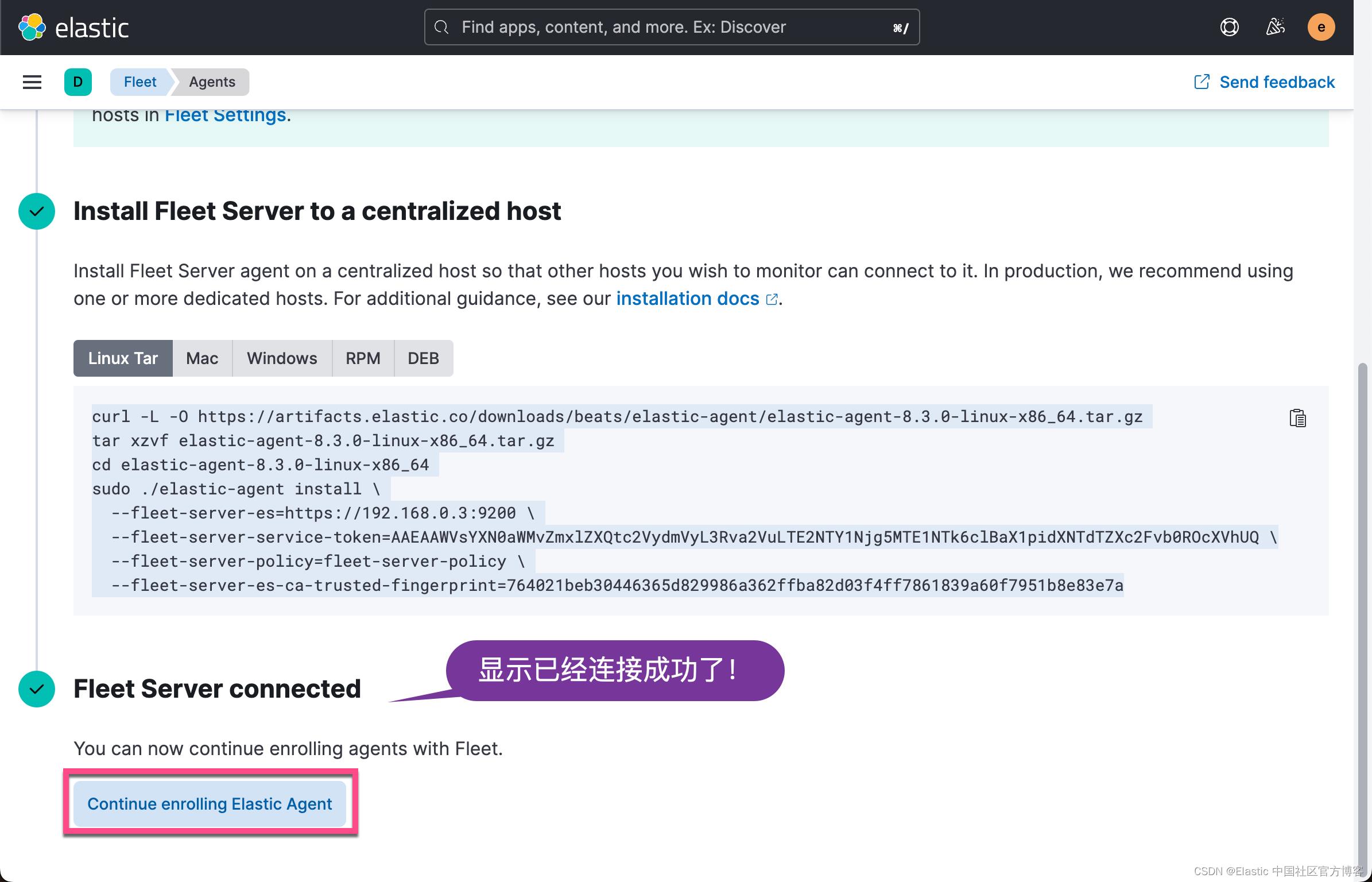
等过一段时间,我们可以看到这个运用于 192.168.0.4 机器上的 Agents 的状态也变为 healthy:
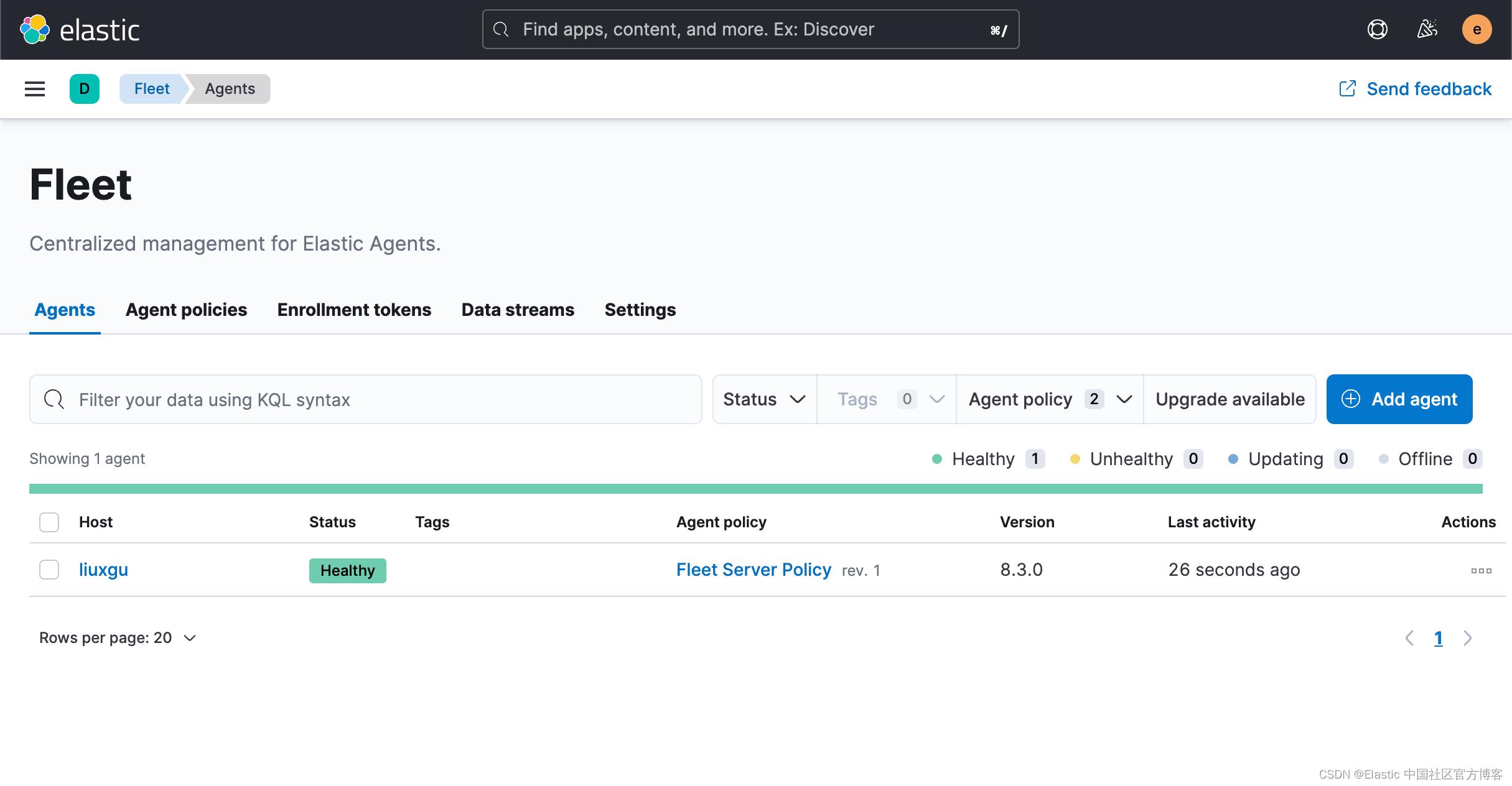
由于我们的 Elastic Agent 和 Fleet Server 是在一个服务器上运行的,所以,我们直接在 Fleet Server Policy 里添加我们想要的 integration。如果你的 Elastic Agent 可以运行于另外的一个机器上,而不和 Fleet Server 在同一个机器上,你可以创建一个新的 policy,比如 logs。然后让 agent 赋予给这个 新创建的 policy。
我们直接在这个 Fleet Server Policy 里添加一个叫做 Custom HTTPJson input 的集成:
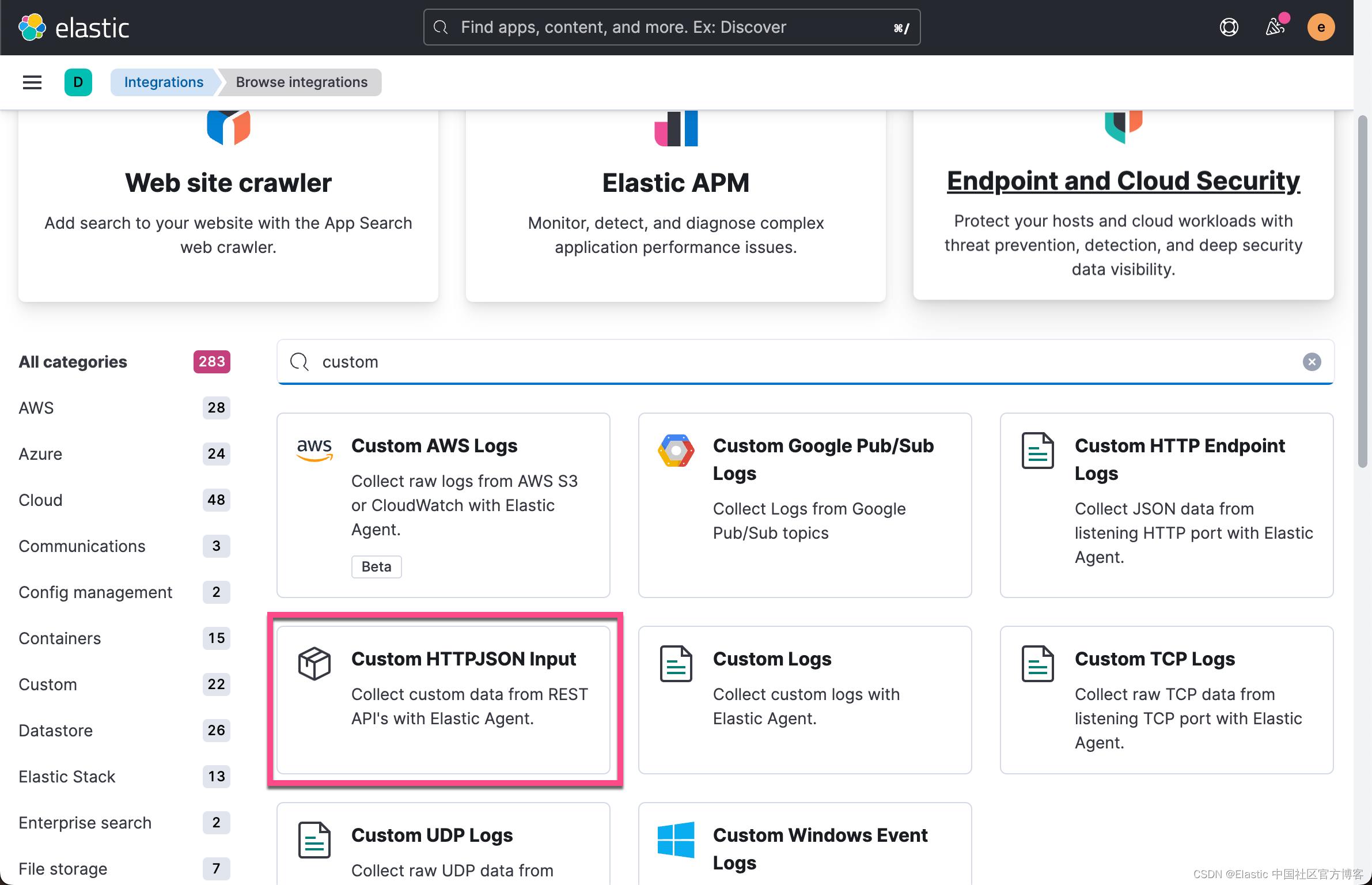
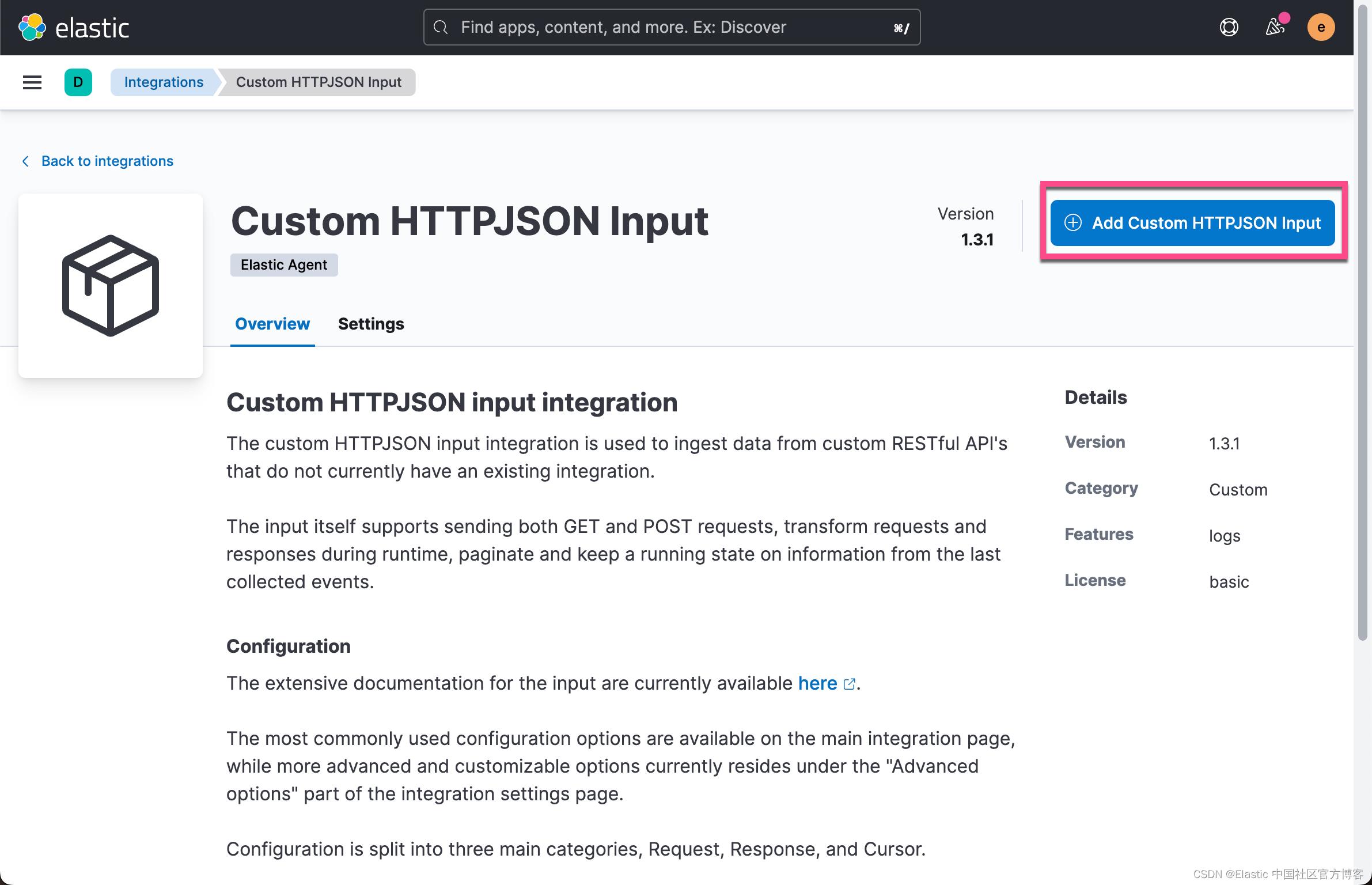
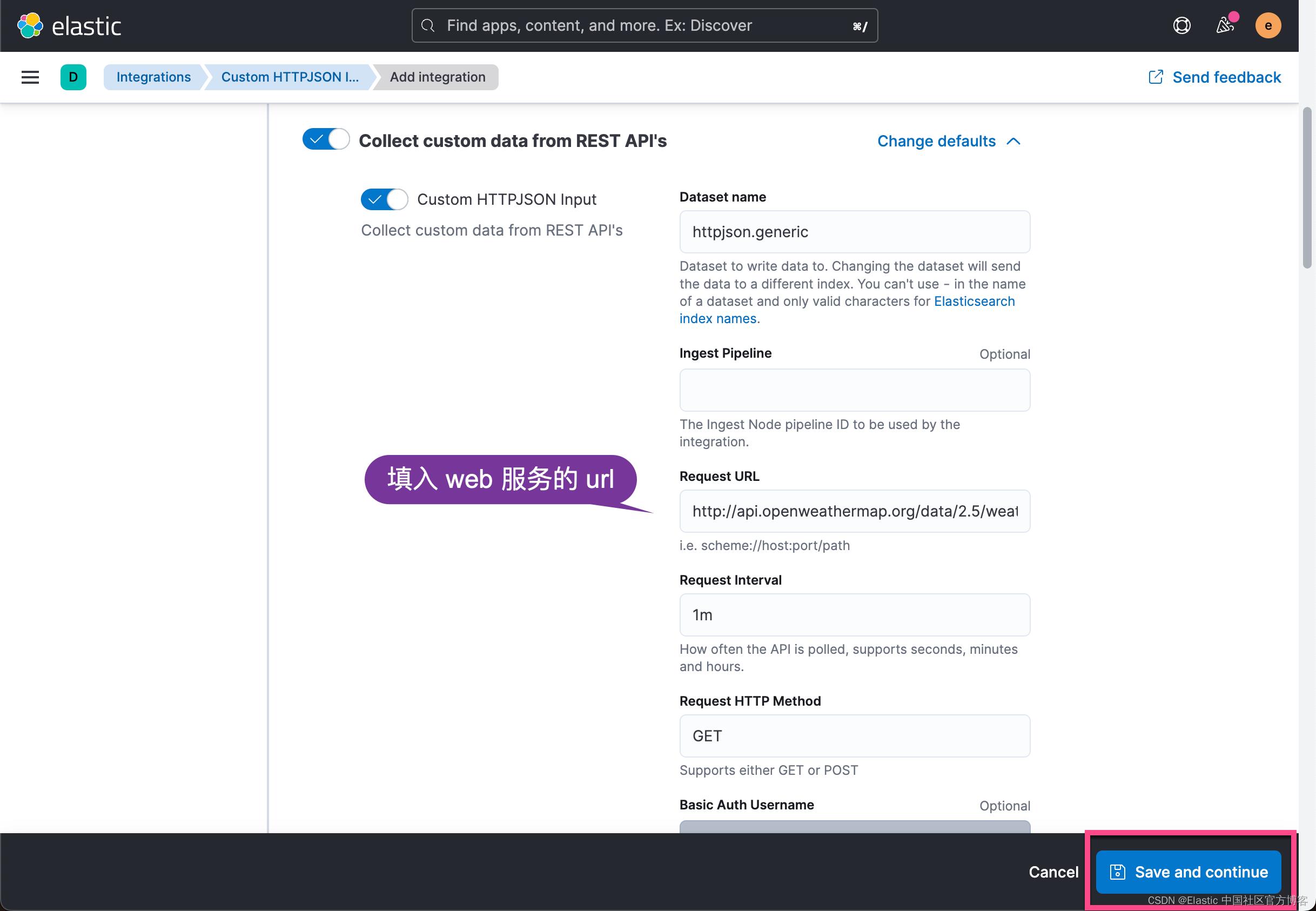
请主要上面显示的 httpjson.generic dataset 名称。更多命名规则请阅读文章 “Elastic data stream 命名方案介绍”。为了说明问题,我在上面在 Request URL 中填入如下的地址:
http://api.openweathermap.org/data/2.5/weather?q=London,uk&APPID=7dbe7341764f682c2242e744c4f167b0&units=metriccurl -XGET "http://api.openweathermap.org/data/2.5/weather?q=London,uk&APPID=7dbe7341764f682c2242e744c4f167b0&units=metric" -H "Content-Type: application/json" | jq$ curl -XGET "http://api.openweathermap.org/data/2.5/weather?q=London,uk&APPID=7dbe7341764f682c2242e744c4f167b0&units=metric" -H "Content-Type: application/json" | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 475 100 475 0 0 508 0 --:--:-- --:--:-- --:--:-- 508
"coord":
"lon": -0.1257,
"lat": 51.5085
,
"weather": [
"id": 804,
"main": "Clouds",
"description": "overcast clouds",
"icon": "04n"
],
"base": "stations",
"main":
"temp": 19.45,
"feels_like": 18.97,
"temp_min": 15.43,
"temp_max": 21.72,
"pressure": 1001,
"humidity": 58
,
"visibility": 10000,
"wind":
"speed": 2.06,
"deg": 210
,
"clouds":
"all": 100
,
"dt": 1660536293,
"sys":
"type": 2,
"id": 2075535,
"country": "GB",
"sunrise": 1660538751,
"sunset": 1660591466
,
"timezone": 3600,
"id": 2643743,
"name": "London",
"cod": 200
这是一个在 openweathermap 的网站上请求天气的 web 服务:
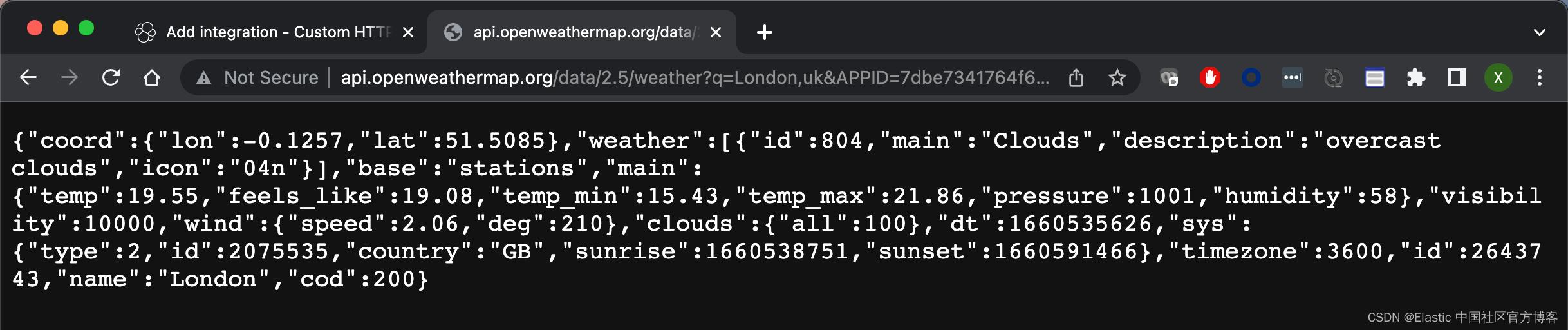
点击上面的 Save and continue 按钮:
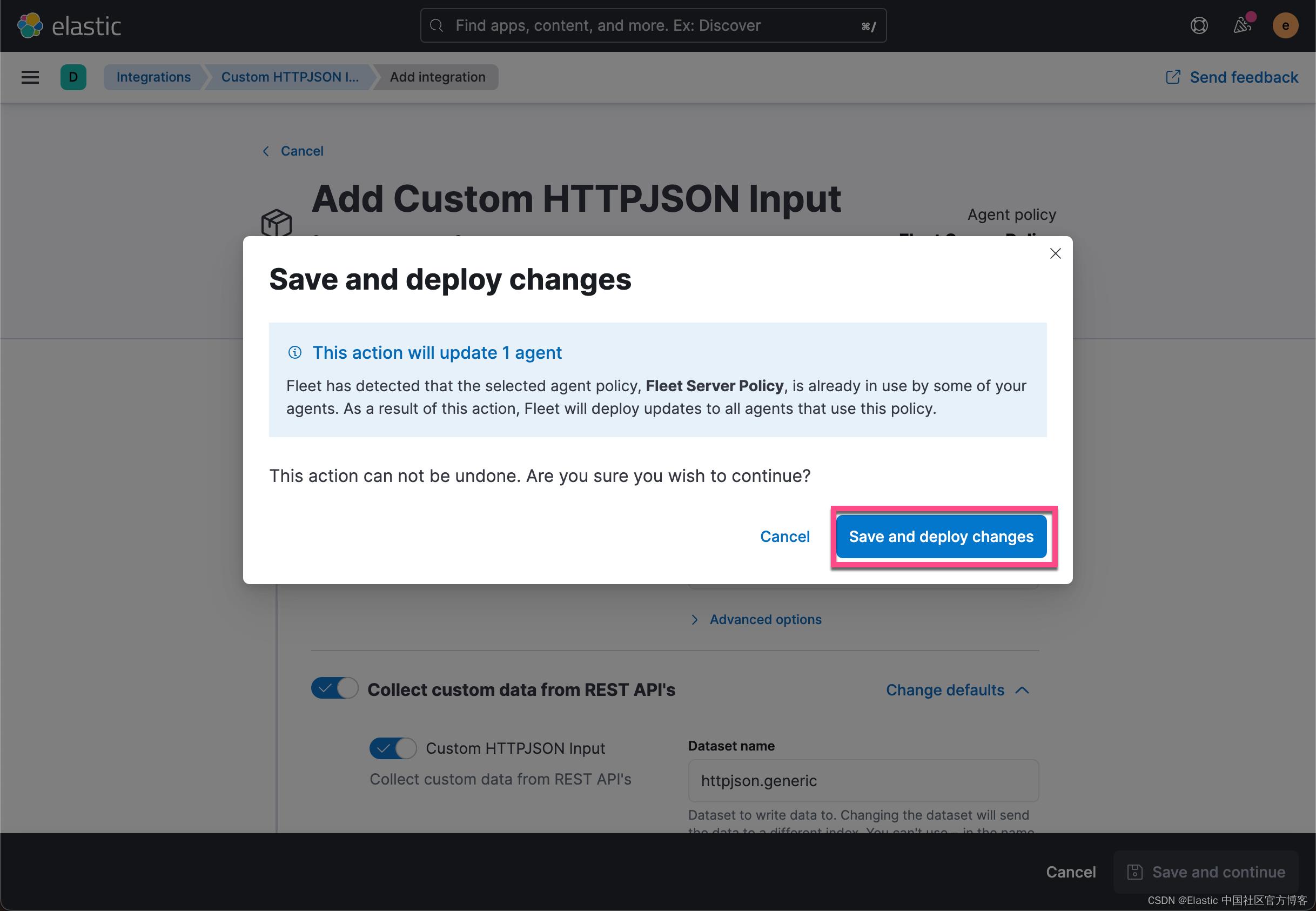
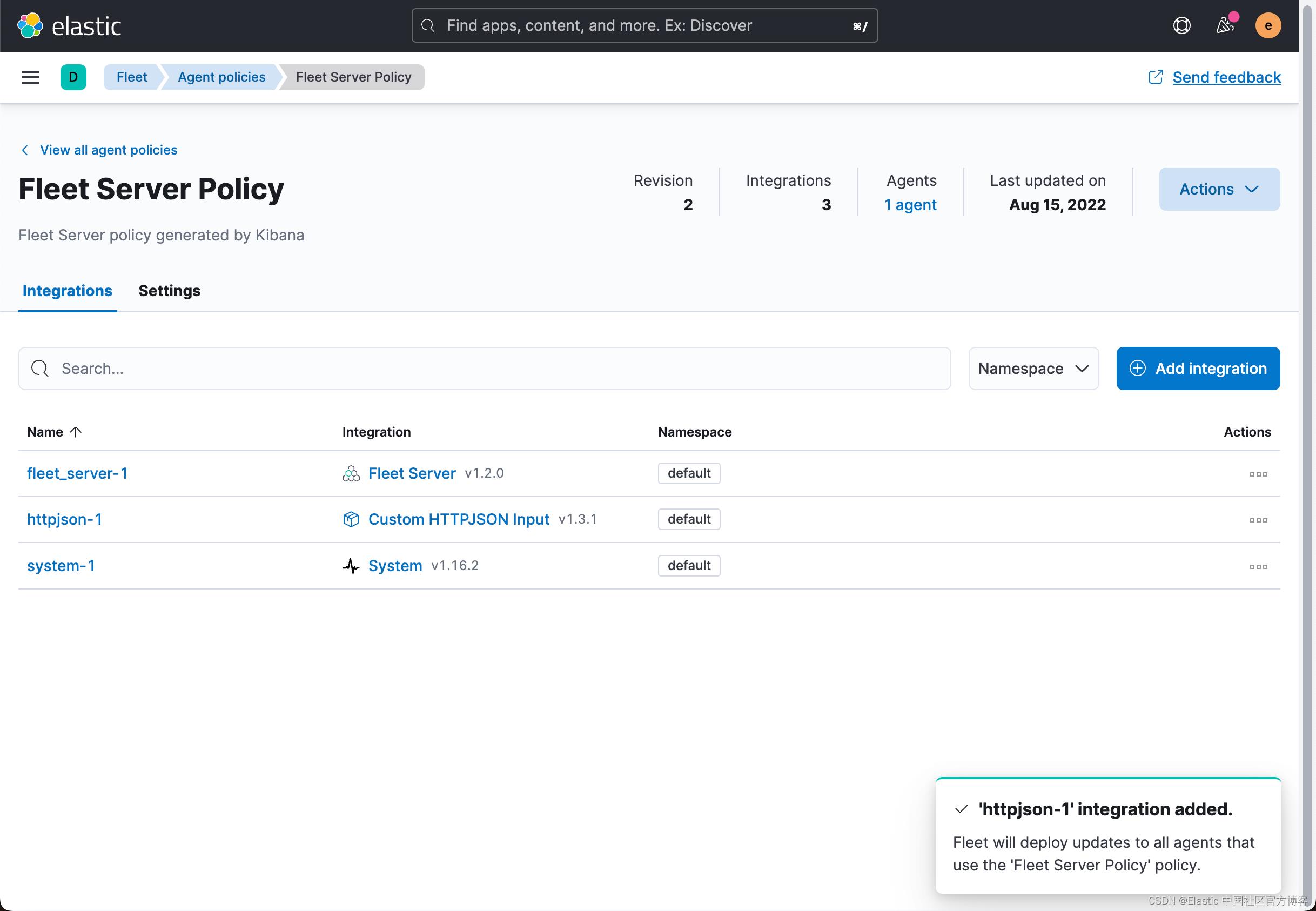
我们看到 httpjson-1 已经被成功地添加了。
我们接下来查看 datastream 里的数据:
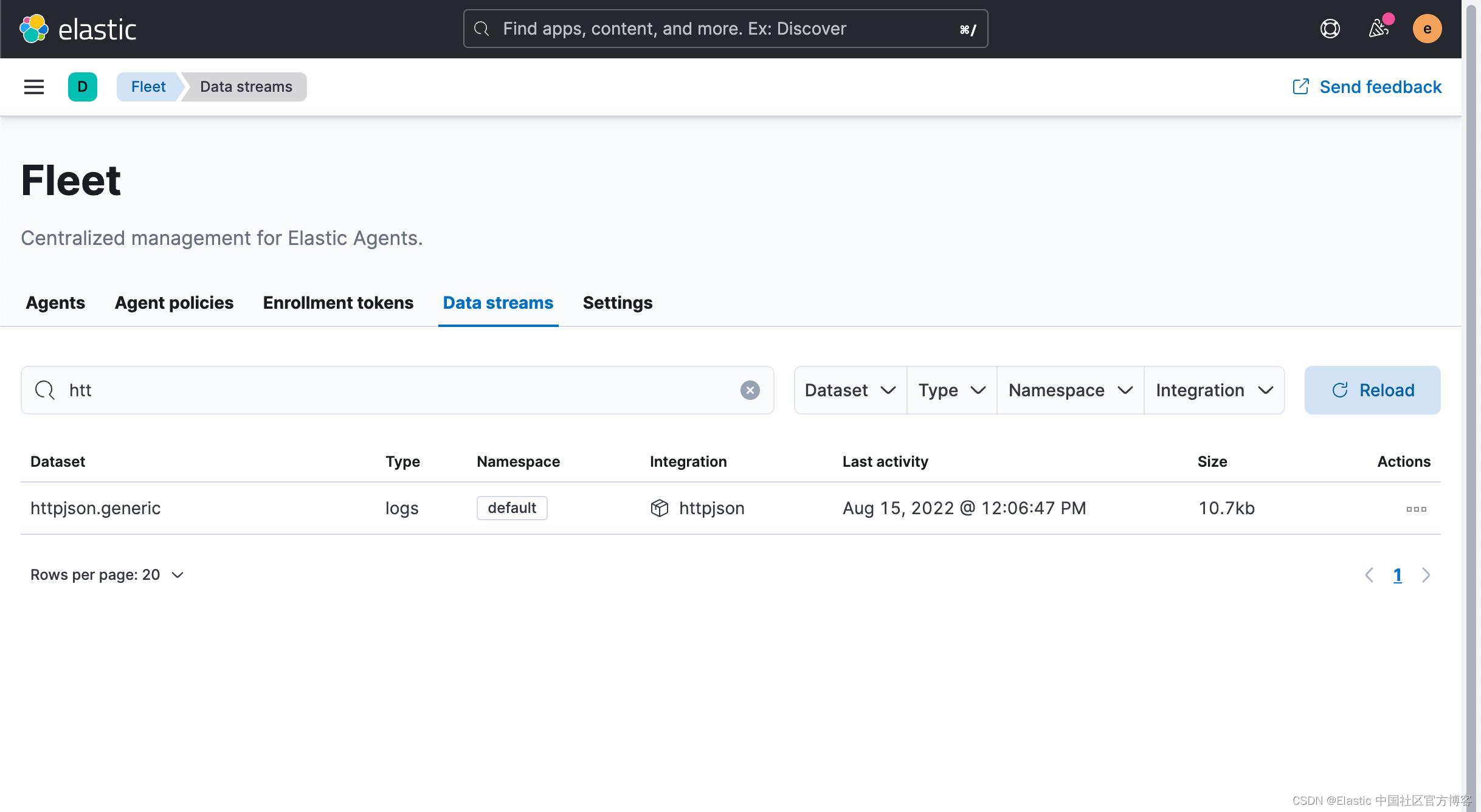
在 Data streams 里,我们可以看到 httpjson.generic 数据集。过一会儿,我们可以看到数据的变化:
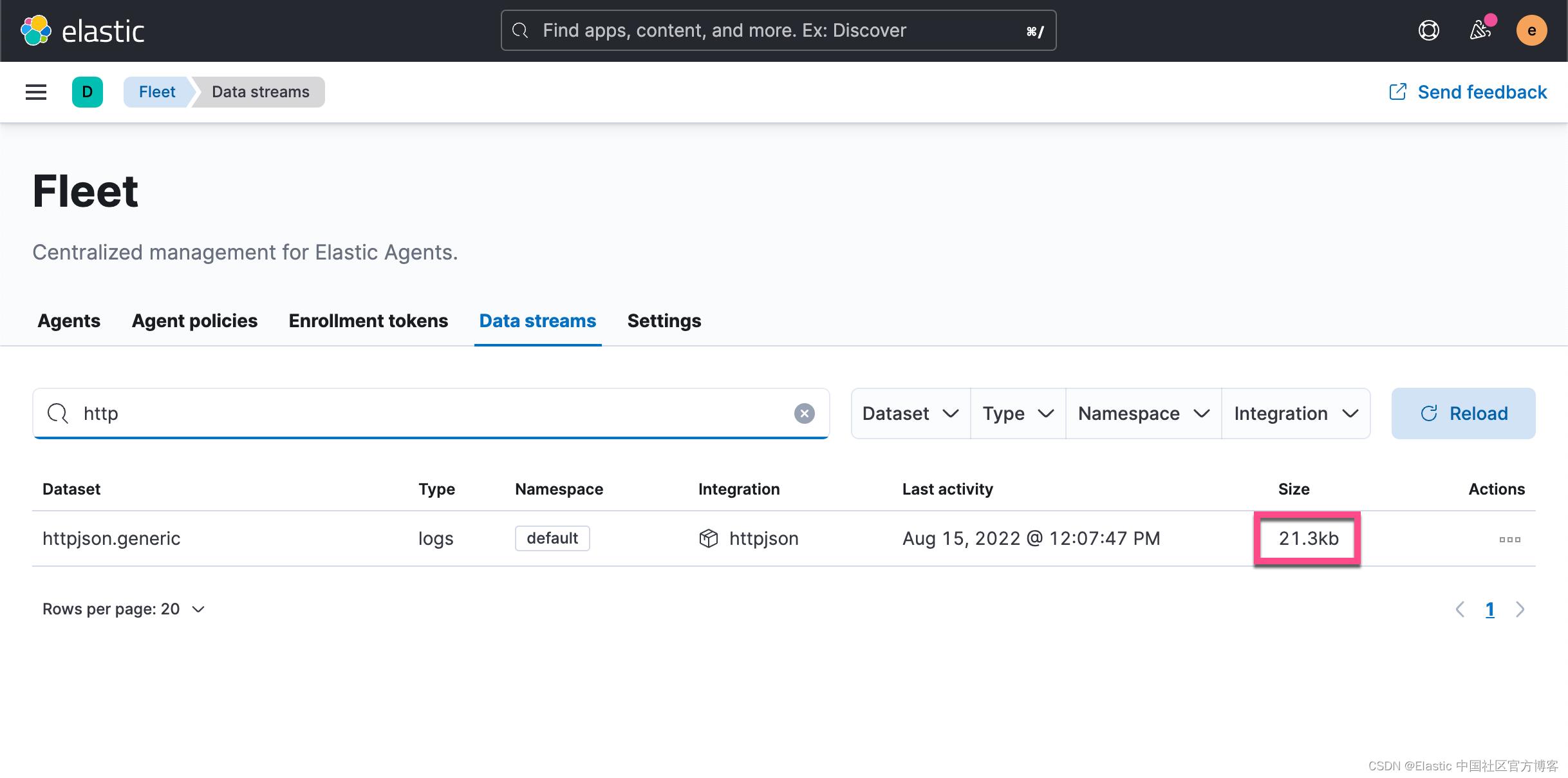
我们是每一分钟采集一次。由于这个是定制的数据采集,它没有对应的 dashboard 及可视化可以使用。我们可以在 Discover 中来查看数据:
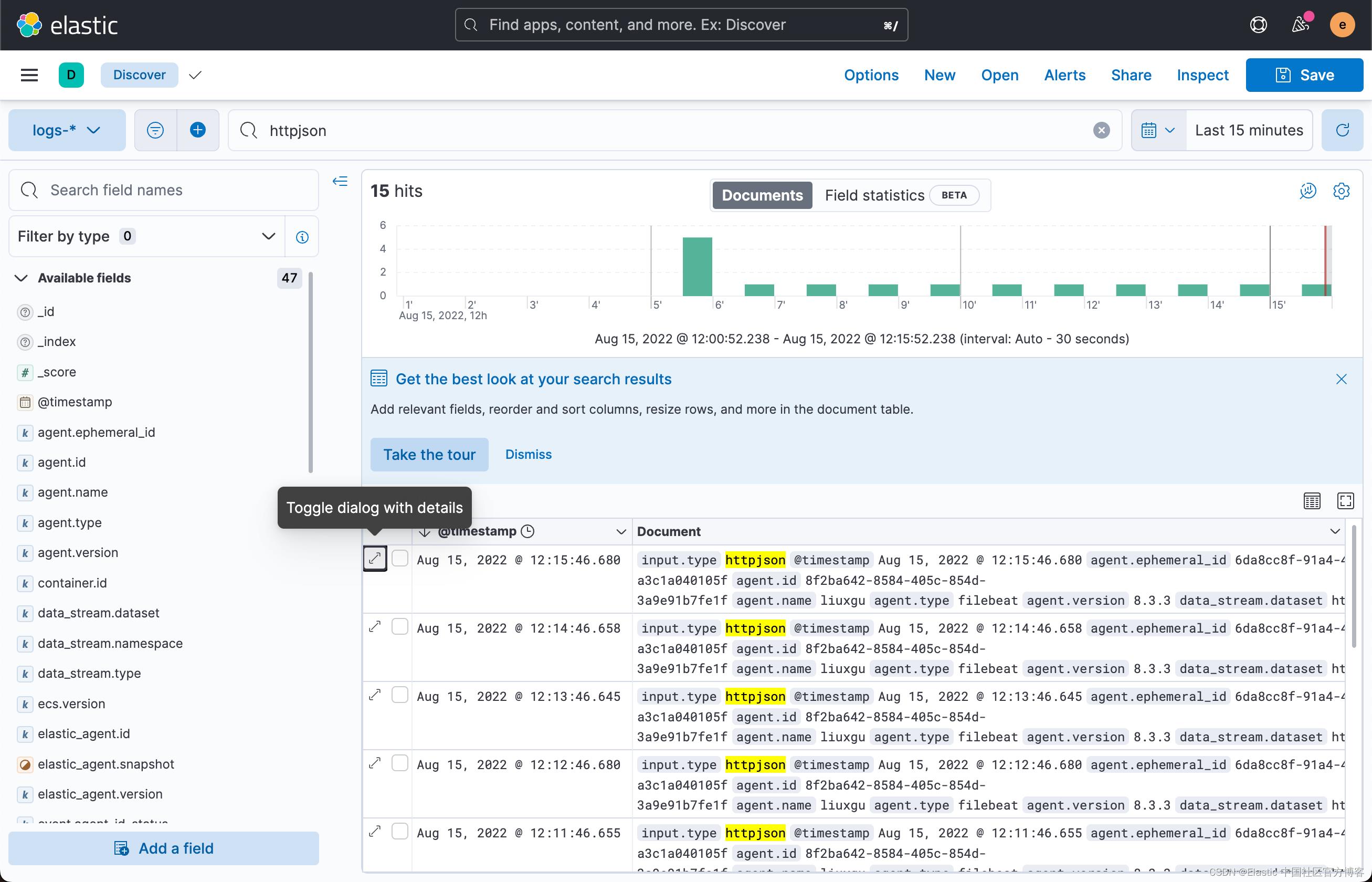
在上面,我们针对 logs-* 来进行搜索,我们发现有一些日志信息。我们点击其中的一个信息:
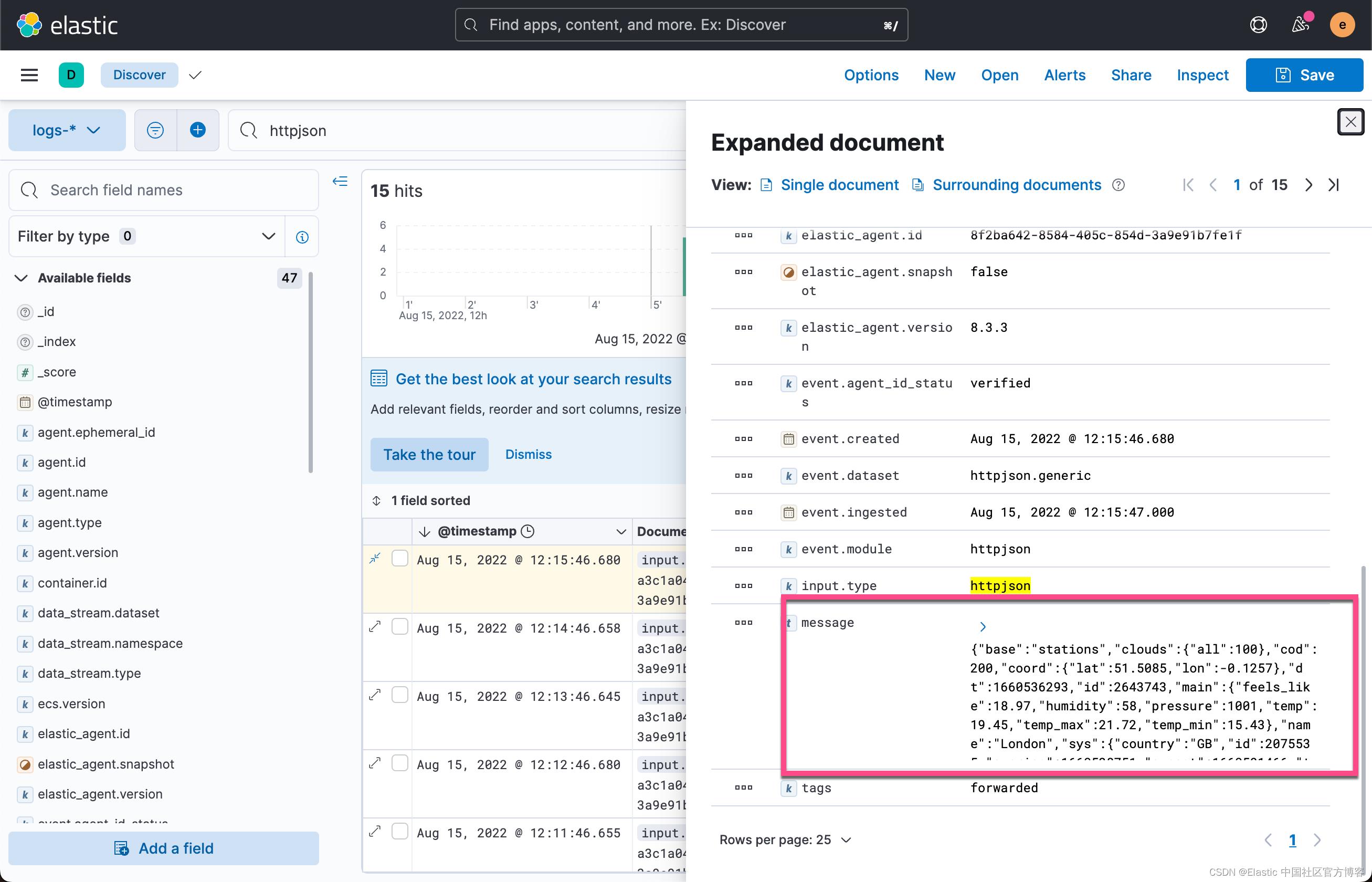
在上面,它显示了被采集的数据。显然上面的 message 中的 JSON 数据并不利于我们对这个数据进行分析。它是一个非结构化的数据。那么我改如何来对这个数据进行结构化呢?
那么针对我们目前的 Elastic Agent 摄入方式,我们该如何结构化这个 message 信息呢?答案是使用 ingest pipeline。
我们在 Kibana 的 Dev Tools 中创建如下的 ingest pipeline:
POST _ingest/pipeline/_simulate
"pipeline":
"description": "structure a JSON format message",
"processors": [
"json":
"field": "message",
"target_field": "json_fields"
]
,
"docs": [
"_source":
"message": """"firstname": "Xiaoguo", "surname": "Liu""""
]
上面的模拟的结果是:
"docs": [
"doc":
"_index": "_index",
"_id": "_id",
"_source":
"json_fields":
"firstname": "Xiaoguo",
"surname": "Liu"
,
"message": """"firstname": "Xiaoguo", "surname": "Liu""""
,
"_ingest":
"timestamp": "2022-08-15T04:23:56.930824Z"
]
也就是说 json processor 可以成功把一个 JSON 的文档结构化。我们可以创建如下的一个 pipeline:
PUT _ingest/pipeline/message_structure
"description": "structure a JSON format message",
"processors": [
"json":
"field": "message",
"target_field": "json_fields"
]
我们需要在 Kibana 的 console 中执行上面的命令。
我们接下来在 Custom HTTPJSON input 集成里使用这个 pipeline:
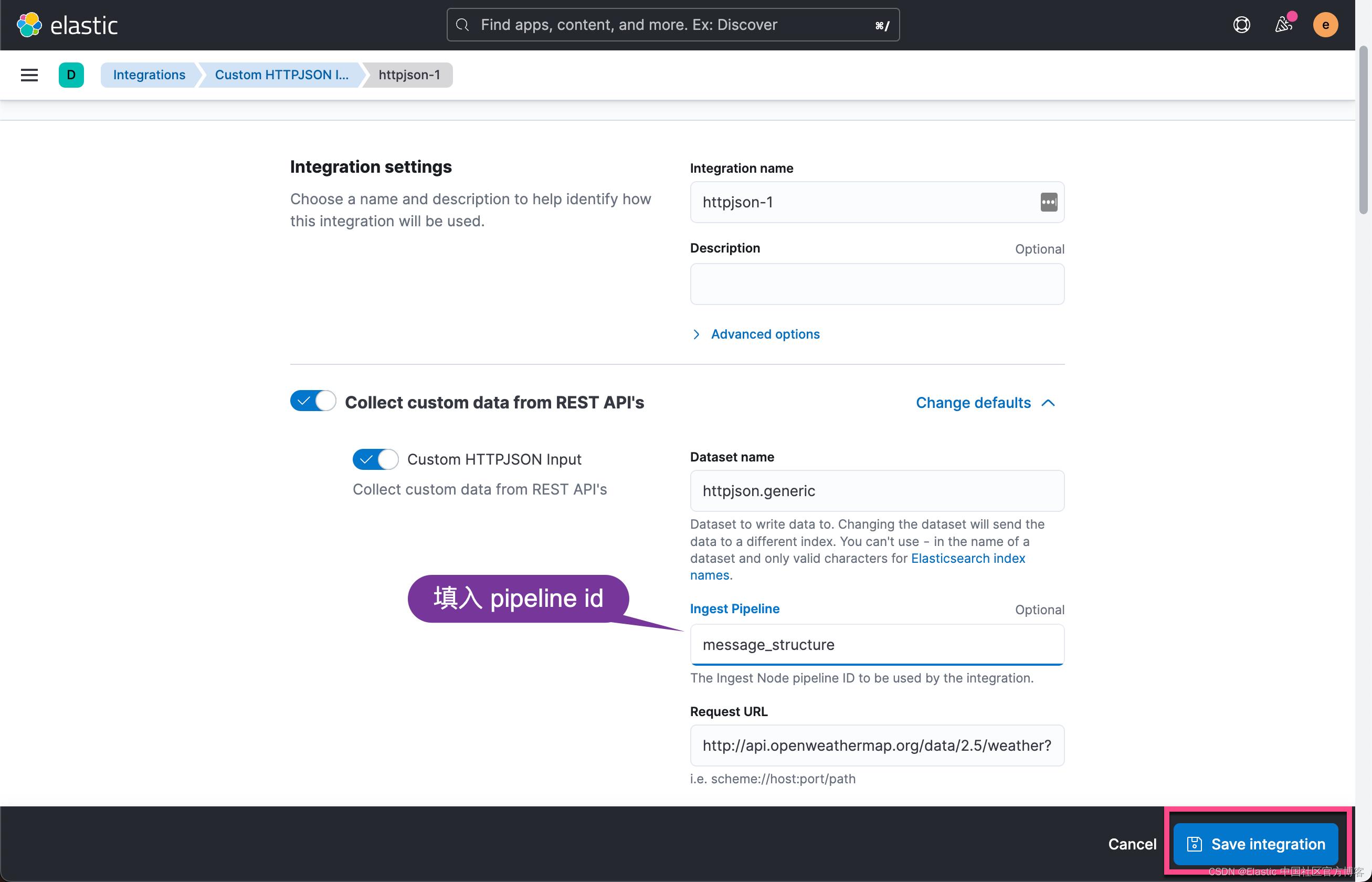
保存这个配置:

过一段时间,我们再去 Discover 界面查询这个数据:
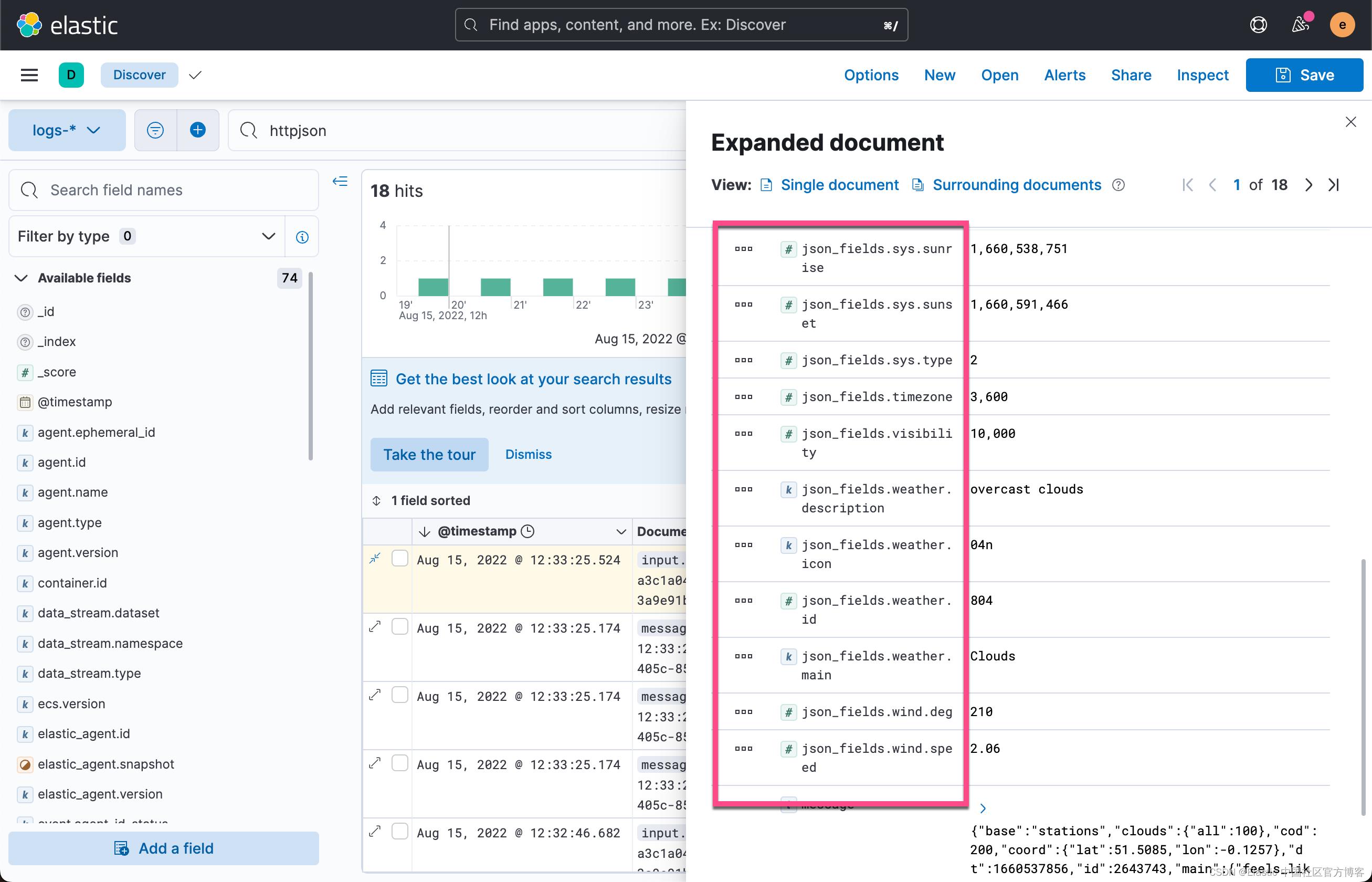
我们发现数据现在已经被成功地结构化了。我们可以运用这个结构来做可视化。
以上是关于Observability:如何使用 Elastic Agents 把微服务的数据摄入到 Elasticsearch 中的主要内容,如果未能解决你的问题,请参考以下文章
Observability:运用 Fleet 来轻松地导入 Nginx 日志
Observability:如何使用 Elastic Agents 把微服务的数据摄入到 Elasticsearch 中
Observability:运用 Fleet 来轻松地导入 Nginx 日志及指标
Observability:在 Elastic Observability 部署中添加免费和开放的 Elastic APM
Observability:在 Elastic Observability 部署中添加免费和开放的 Elastic APM