OpenAi[ChatGPT] 使用Python对接OpenAi APi 实现智能QQ机器人-学习详解篇
Posted 小简(JanYork)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenAi[ChatGPT] 使用Python对接OpenAi APi 实现智能QQ机器人-学习详解篇相关的知识,希望对你有一定的参考价值。
文章大部分来自:https://lucent.blog
原文博客地址:https://blog.ideaopen.cn
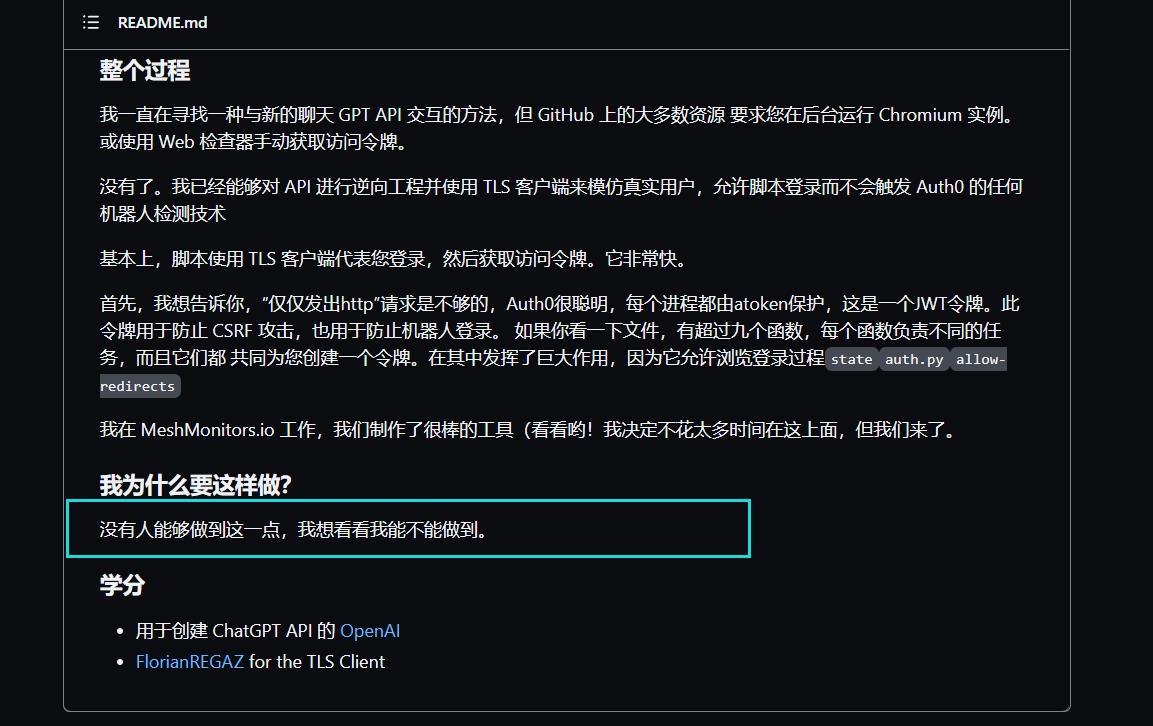
最近火热全文的ChatGPT,被很多人玩出了花,我们在Github上可以看到几个常见的逆向SDK包,这一篇我将以学习的方式来写这一篇文章。
这些SDK不仅仅可以用于开发机器人,还可以自由的开发你所想要的效果,如你所想,他是一个工具包,帮你chuanchuan构建一个ChatGPT服务和会话。
最近
OpenAi给他套上了一个Cloudflare的CDN服务,这个服务会去拦截非真机请求,现在已经可以破解了。
寻找合适的逆向SDK
原作者用的是这个。
整个包的文件并不是很多,喜欢Python的可以去看看,我这个Java看不太懂。
实践开始-实践篇第一
代码中使用到的revChatGPT依赖源码库:
https://github.com/acheong08/ChatGPT
我们的Python版本,需要>=3.8,然后pip直接升级到最新版本。
下面代码的目的是与ChatGPT官方接口进行交互,注意安装一下里面用到的依赖
chat-gpt-qbot.py:
import flask, json
from flask import request
from revChatGPT.revChatGPT import Chatbot
config =
"session_token": "换成你自己的token"
# 创建一个服务,把当前这个python文件当做一个服务
server = flask.Flask(__name__)
chatbot = Chatbot(config, conversation_id=None)
def chat(msg):
message = chatbot.get_chat_response(msg)['message']
print(message)
return message
@server.route('/chat', methods=['post'])
def chatapi():
requestJson = request.get_data()
if requestJson is None or requestJson == "" or requestJson == :
resu = 'code': 1, 'msg': '请求内容不能为空'
return json.dumps(resu, ensure_ascii=False)
data = json.loads(requestJson)
print(data)
try:
msg = chat(data['msg'])
except Exception as error:
print("接口报错")
resu = 'code': 1, 'msg': '请求异常: ' + str(error)
return json.dumps(resu, ensure_ascii=False)
else:
resu = 'code': 0, 'data': msg
return json.dumps(resu, ensure_ascii=False)
if __name__ == '__main__':
server.run(port=7777, host='0.0.0.0')
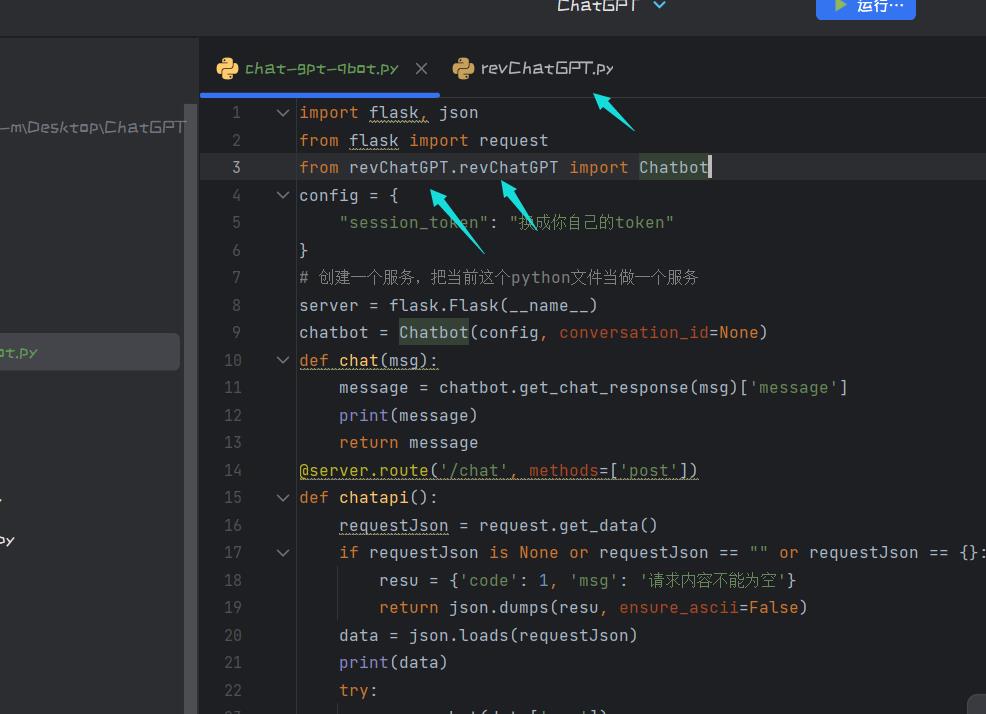
我们导入我们的逆向包。
from revChatGPT.revChatGPT import Chatbot
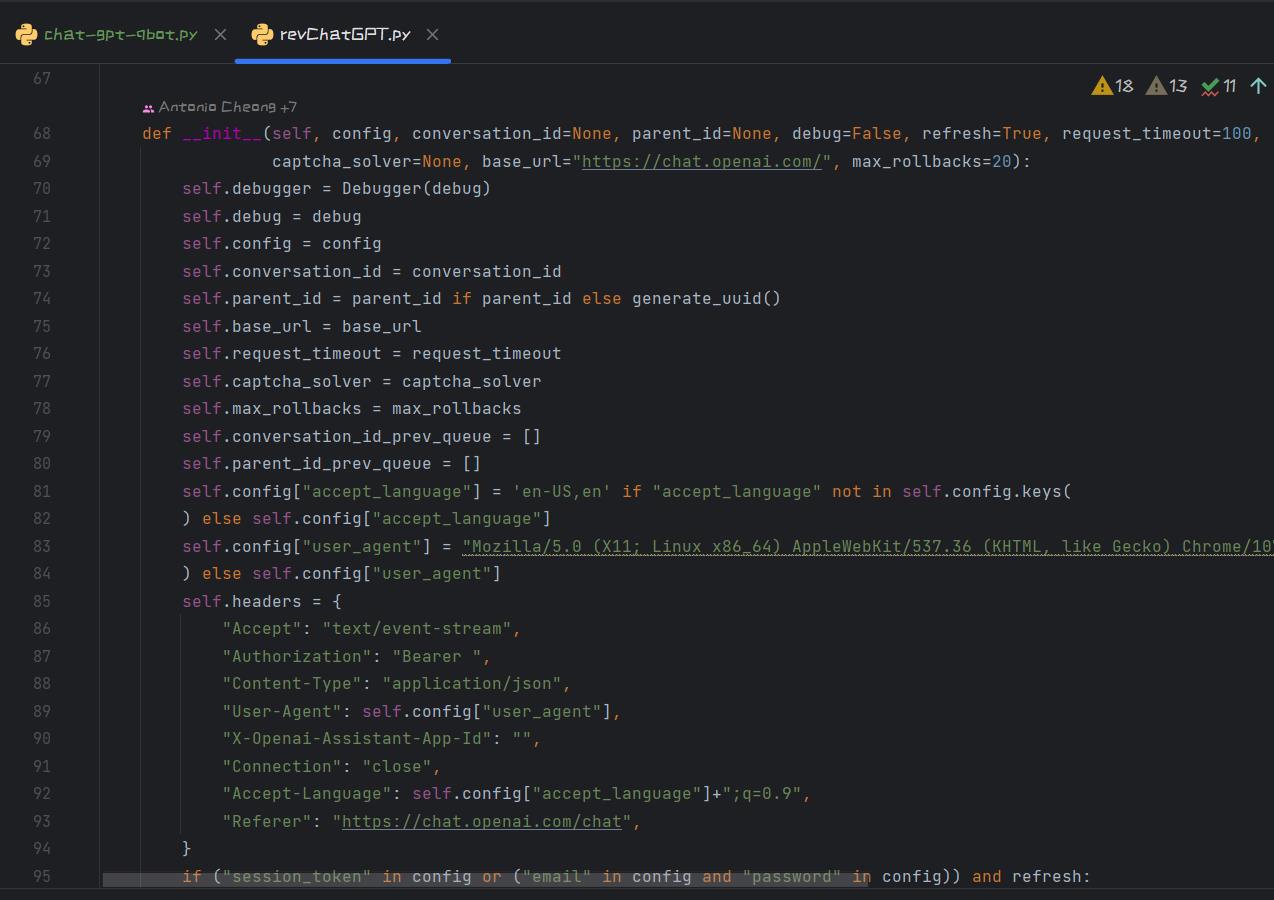
这是逆向包里面的源码,用于初始化一个服务,我们刚刚的类中调用了这个包。
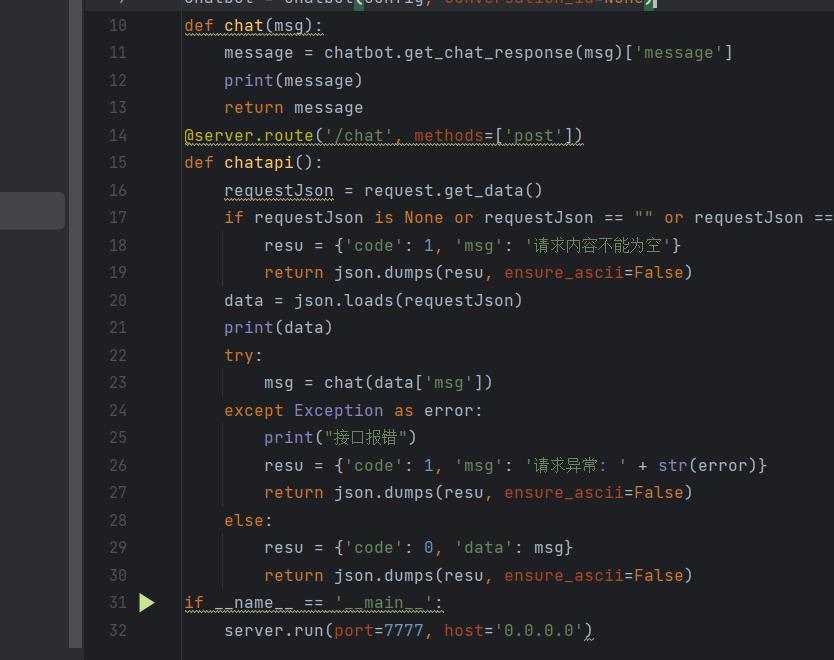
然后去创建抛出这个服务的接口,方便被调用。
我们只要运行上面的代码就可以在7777端口直接与ChatGPT进行交互了。
我们使用接口工具测试一下,结果如下图,可以看到,接口正常工作并从ChatGPT得到了对话结果。
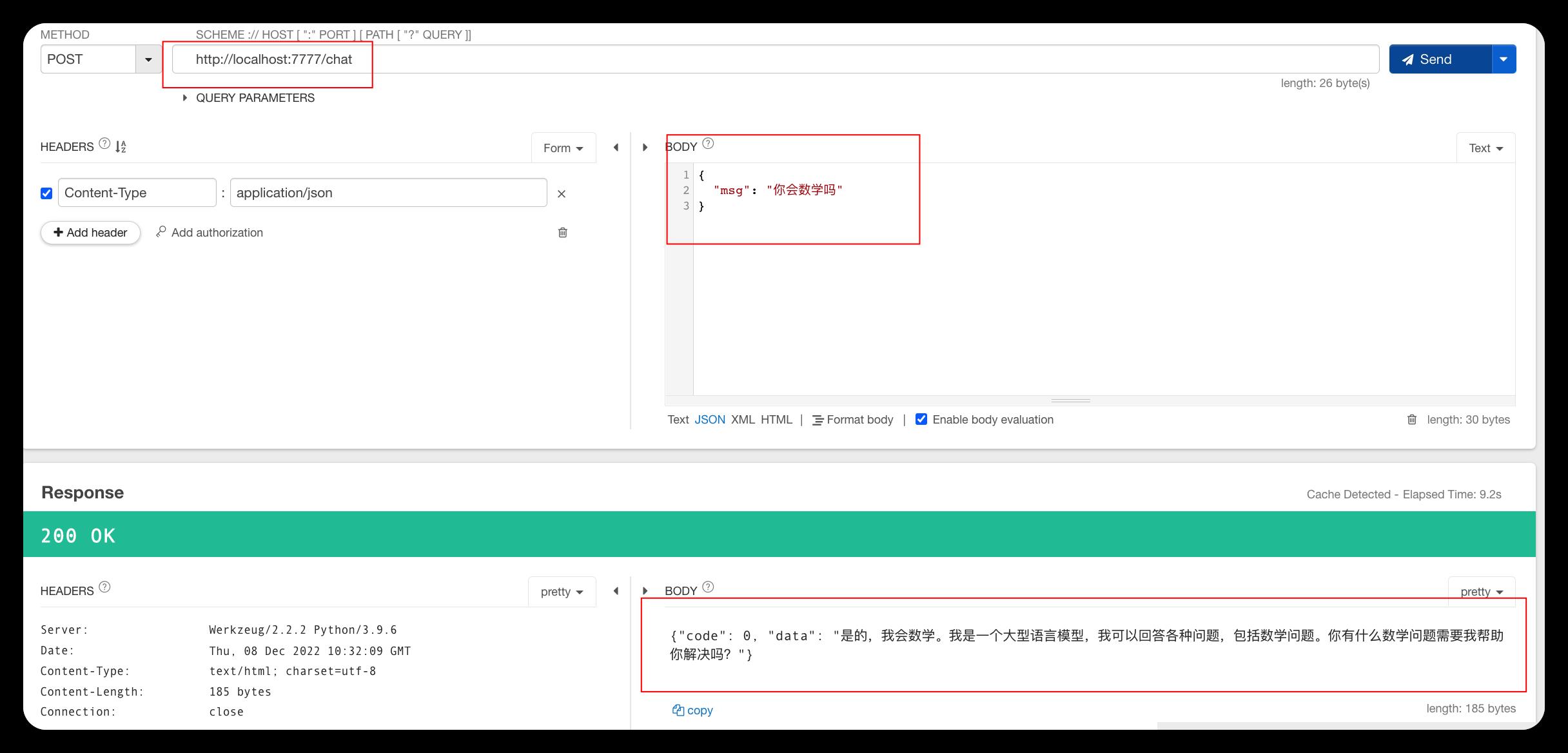
其中消息体:
"msg": "你会数学吗"
消息体是我们自定义的内容,你可以自己增加字段对接口进行功能扩展
本例子中的msg就是我们的发言内容
而接口返回的:
"code": 0,
"data": "是的,我会数学。我是一个大型语言模型,我可以回答各种问题,包括数学问题。你有什么数学问题需要我帮助你解决吗?"
这也是我们自己定义的,当code=0时代表与ChatGPT交互成功,此时data为ChatGPT反馈给我们的对话内容。而当code=1时说明出现了错误,此时没有data,但在msg中返回了错误信息。
到这里我们就拥有了一个可以和ChatGPT交互到接口,通过这个接口,我们就能与ChatGPT进行对话
既然进行对话,那就需要一个输入框和一个按钮,你可以做一个网页来调用这个接口,这很简单,我们不在这里赘述了。
我们真正要做的是一个QQ机器人,其原理就是让QQ机器人监听到消息,并通过我们的接口把消息转发给ChatGPT,然后再把ChatGPT返回的对话内容发送给QQ用户,这样一个可以对话的机器人就做好了,具体做法,下文继续讲解。
实践继续-实践篇第二
上文我们实现了一个接口,用代码成功获取到了ChatGPT的对话内容,下面我们将继续完善QQ机器人相关逻辑,注意看代码中的注释。
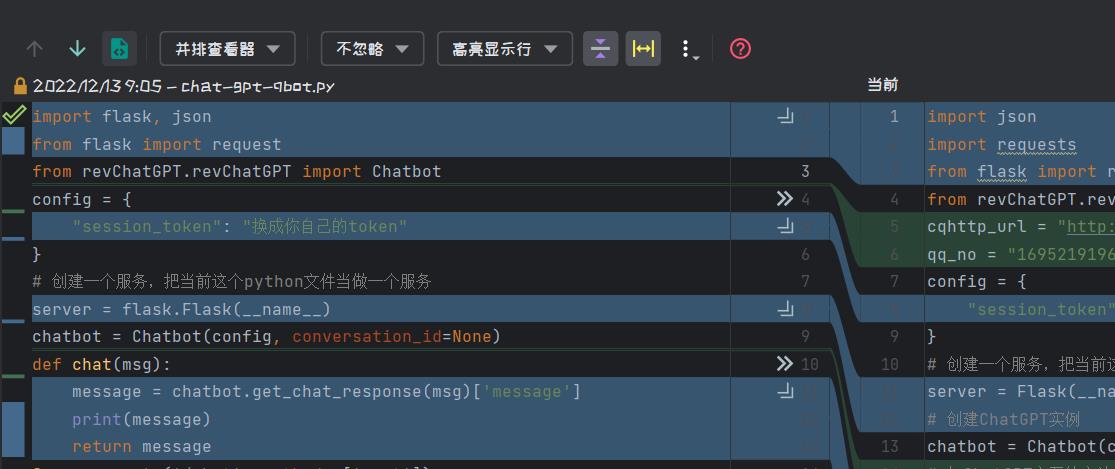
为了更方便的将优化后(接入QQ机器人)的代码,与之前的代码比较,我开启一个本地比较,并收起了没有变动的代码。
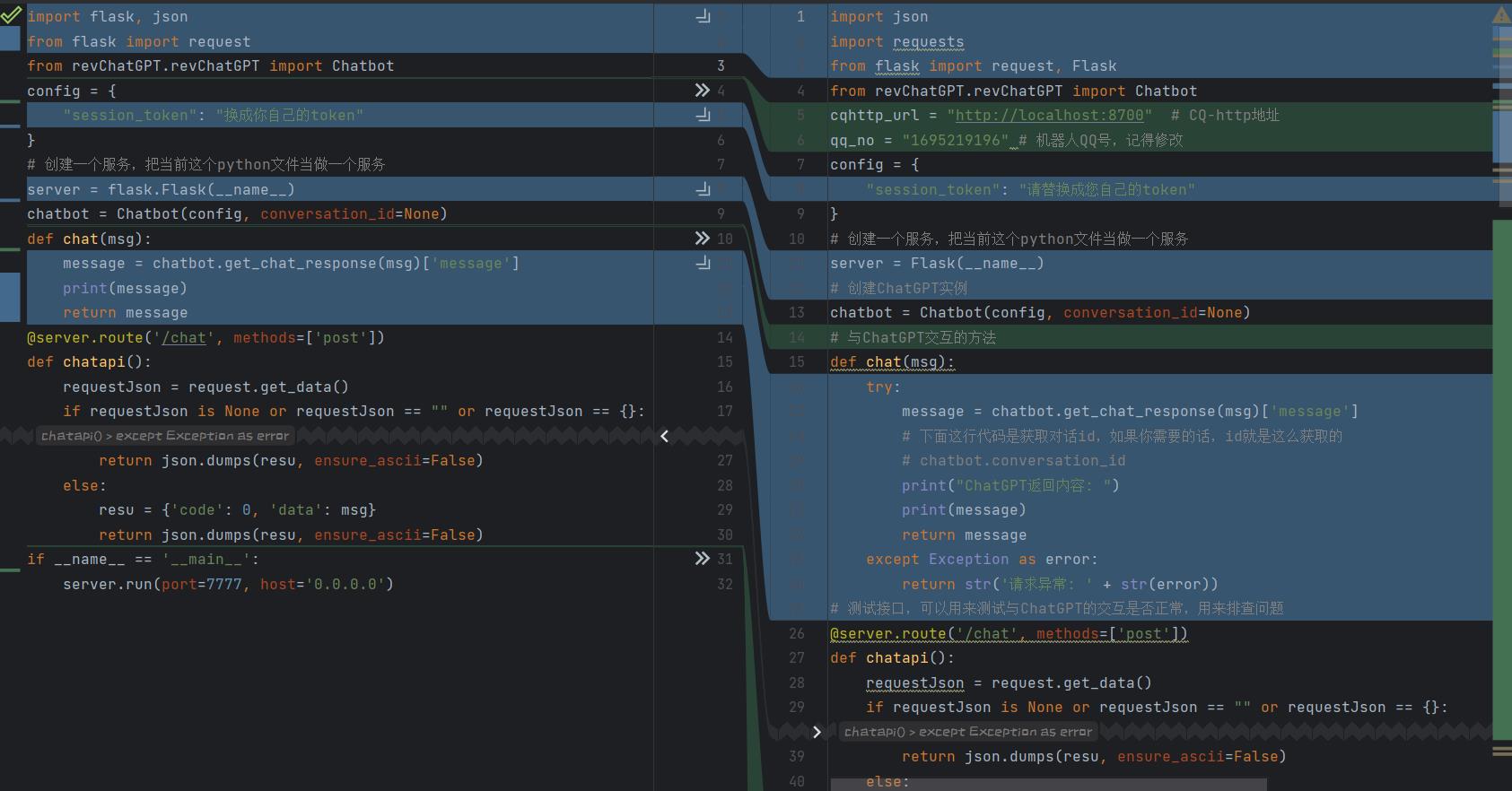
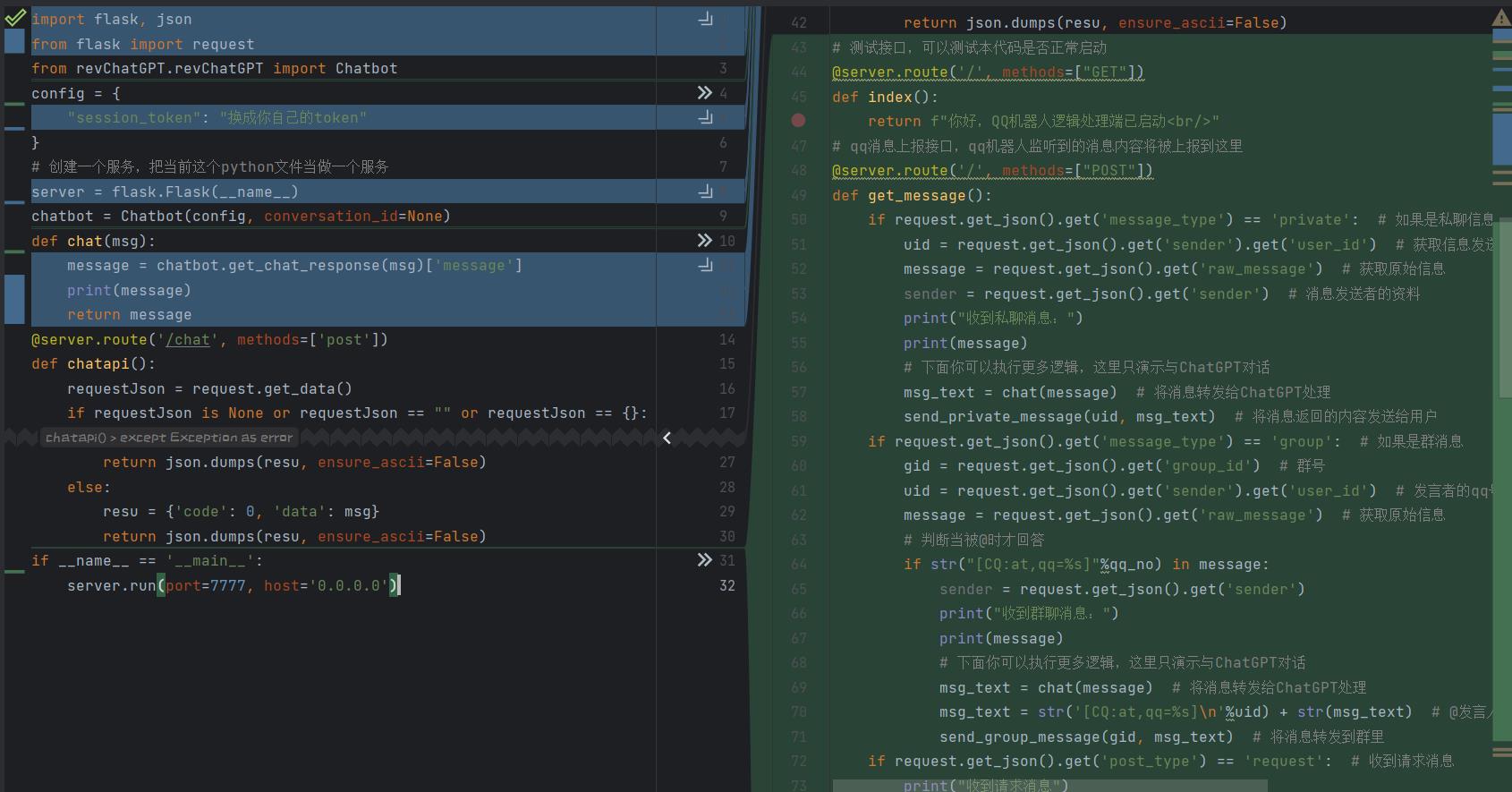
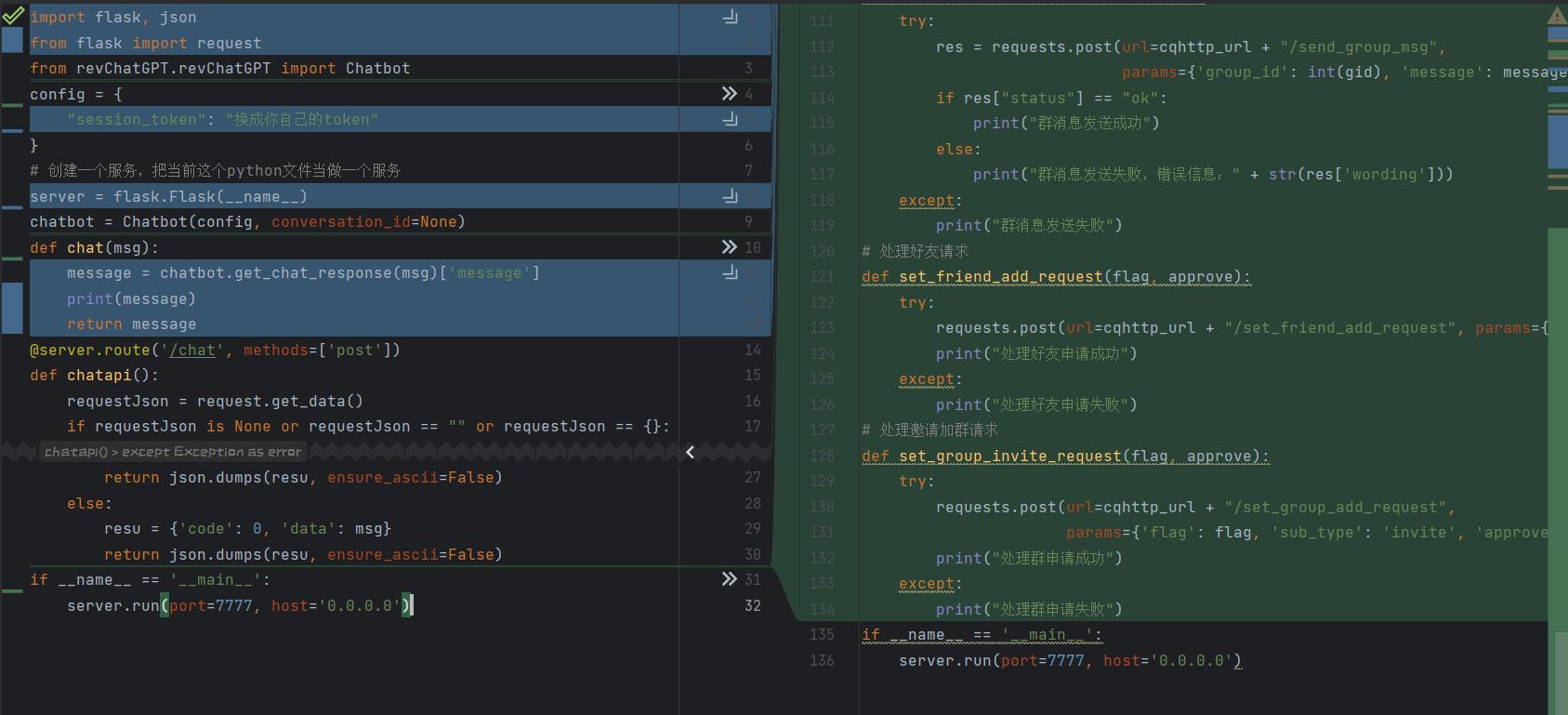
机器人的交互实现逻辑,这个你可能会看不懂,因为我们是使用了一个机器人框架,那其实我们不要局限自己的思想,我们可以尝试自己修改使用其他机器人框架,比如云仔机器人,逻辑去自己实现。
我们使用的是go-cqhttp。
所以说,这一写更改,你得去了解这个go-cqhttp你才能看懂,不过我们要灵活学习,我们只需要了解思路便可,然后去官方文档找使用方法。
此时,这些代码已经拥有了处理好友请求、拉群请求、回复消息的功能。
可以看到,相对于上个文章,我们增加了很多代码,并且都加了注释
当然,这些代码看不懂没关系,可以照着我的文章改一下对应的地方,直接用。
大家来原创作者Q群玩儿,我也在里面:206867743。
实践继续-实践篇第三
前两个文章我们已经解决了和ChatGPT通信的问题和QQ处理消息的问题,现在我们就需要处理如何监听QQ消息了。
在一次次的更新和遇到的问题中,原创作者和逆向包的很多作者都更新了很多内容,我们看看原创作者的更新记录:
2022-12-12 23:52
- 增加一个Windows专用版本,只能在Windows电脑或服务器上使用,可以自动获取cloudflare Cookie
2022-12-12 12:38 更新内容
- 增加CloudFlare配置,更新依赖,暂不支持账号密码,暂不知道CloudFlare配置多久需要更换一次,现在好像必须要翻墙了
2022-12-10 17:42 更新内容
- 增加账号密码支持,可以不使用token,直接使用账号密码
2022-12-10 00:23 更新内容
- 将每个QQ私聊区分,每个人私聊机器人都是一个独立的会话
- 将每个QQ群区分,每个QQ群是一个独立的会话
- 增加回复字数限制,超过限制转换成图片回复(见配置文件)
- 如果想要重置会话,对机器人发送:重置会话
简介
监听QQ消息并不需要我们写代码,因为市面上已经有很多开源QQ机器人框架,在这里我们使用go-cqhttp
官方文档: go-cqhttp
如果您感兴趣的话,可以阅读一下官方文档,如果不想看,直接看我的文章即可。
前提条件
- 您需要准备一个QQ号,不要使用自己大号
- 您需要准备一个OpenAi的账号,用来获取Token
- 一台服务器(可选,如果您想让机器人7x24小时在线的话,请准备一台,1核1G足以,外服最好)
注意:OpenAi(ChatGPT)的注册方式B站有一堆视频,随便参考一个就行。
不会注册也可以看看我博客的文章:一文教你快速注册OpenAi(ChatGPT)
(旧版本)机器人搭建教程我也是写过了:使用OpenGPT(ChatGPT)搭建 QQ 机器人
但是!注意,先前说过,现在的ChatGPT套了一个CF的CDN,会拦截人机交互请求。
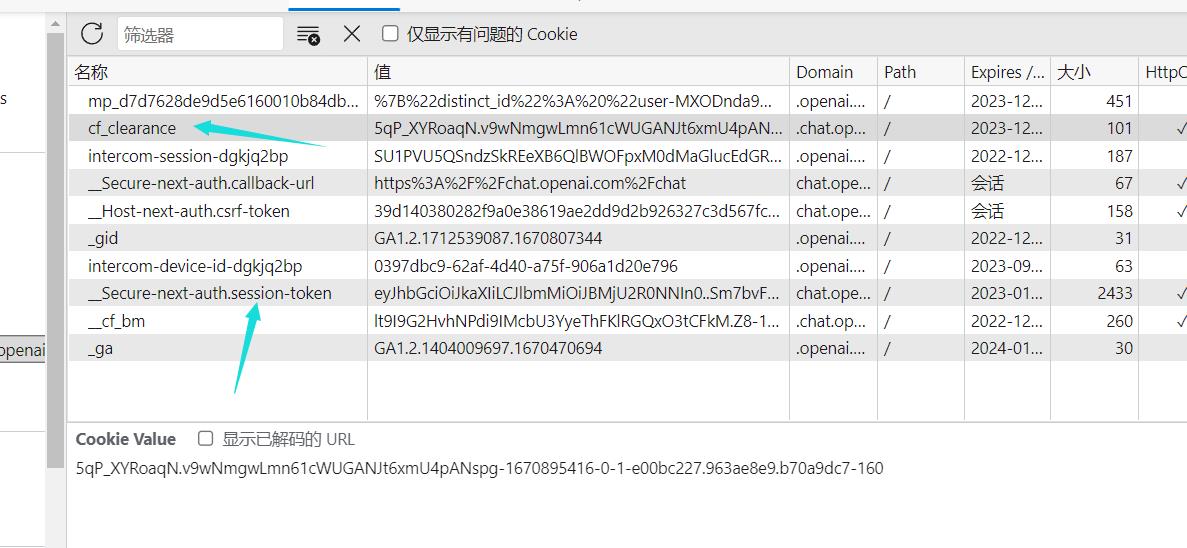
那我们现在,除了需要获取OpenAi的session-token,还需要获取cf_clearance。
同时,我们还需要获取user-agent。
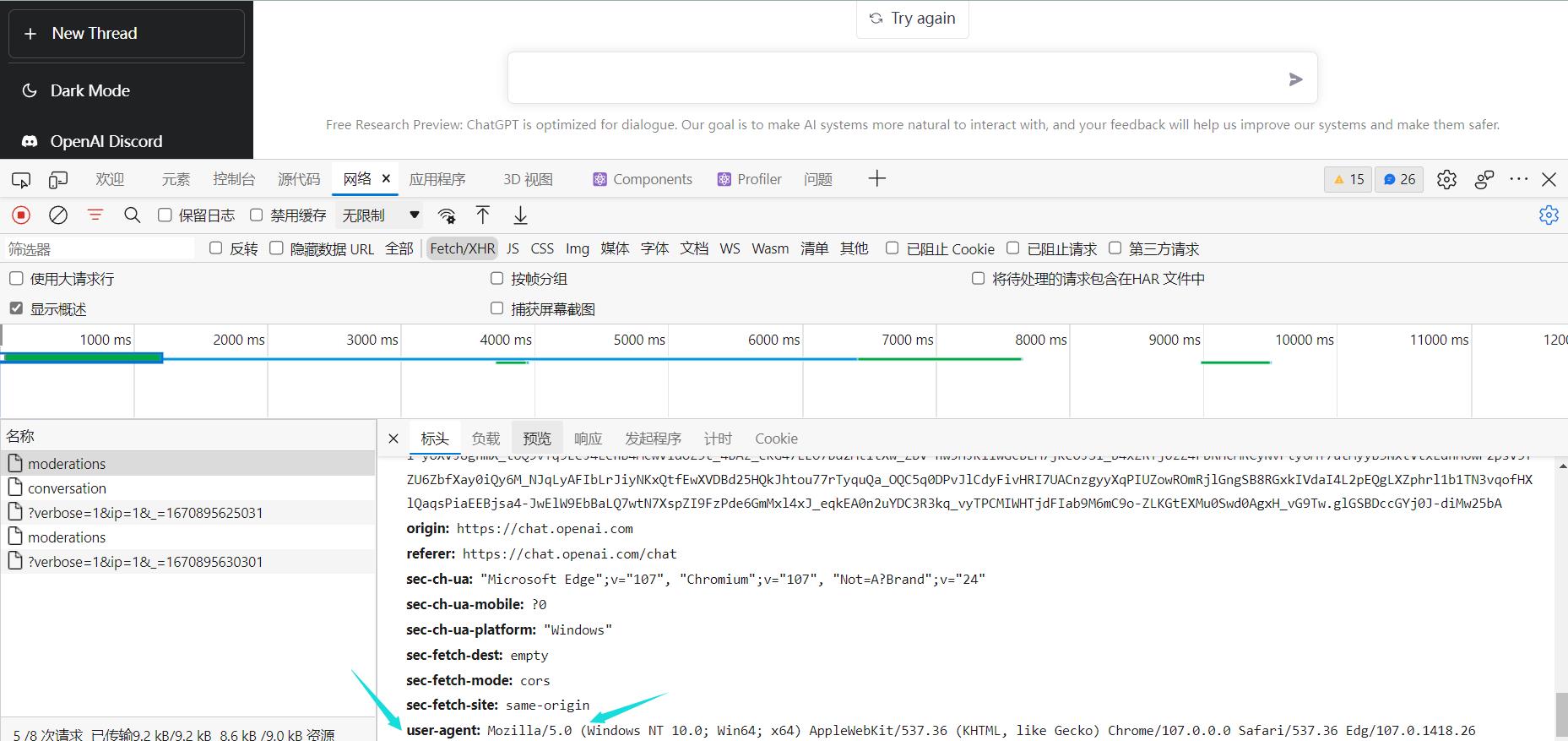
前往控制台的网络标签里面查看,如果是空白,你发一句消息就可以。
复制之后写到配置文件中,也就是py/config.js文件。
目前原创作者打包了两个版本,一个Linux的,麻烦在于cf的CDN交互令牌会在2H内失效,我们需要手动获取并更新,麻烦。
另一个是window版本,已经实现自动获取CloudflareCookie。
配置指南
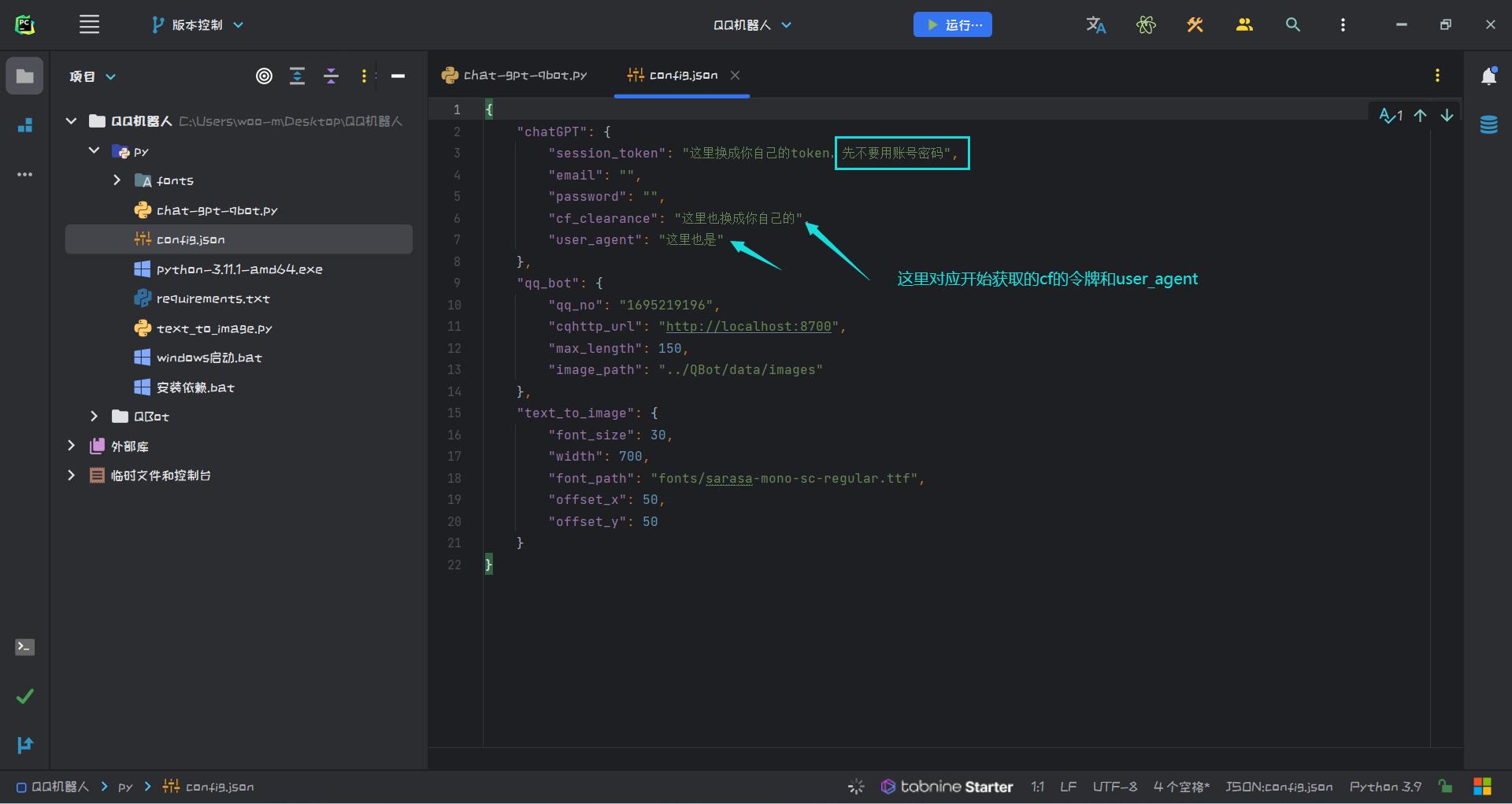
这个版本只能在Windows上使用,Windows电脑或服务器都行。
依然只支持token。
系统会自动打开谷歌浏览器获取Cloufflare相关Cookie,第一次运行时可能需要手动验证,请注意点一下。
注意,脚本它只能打开Google浏览器,没配置其他浏览器。
其他描述
那在作者最新版本的代码里面,也是新增了一部分功能。
自行研究。
然后很多逆向包作者也在想一个完美解决的办法,我们慢慢等待吧!
然后,请看看这句话:
尾述
写着一篇,我基本上是去看原创作者的代码和逆向包的代码,我是一个业余的Python,但是我觉得,很多东西是可以去尝试的,通原理而致用,当你学会整个思路,那你也可以自己写一个自己的机器人,自己去配置去设计交互逻辑。
比如可以新增一个Markdown渲染器+代码高亮,将长文本以图片方式展示(虽然已经存在了),又比如,绑定一个不被拦截的域名,过长文本直接生成一个临时链接,点开查看,刚好通过网页渲染后,美观度高很多。
小简绝得,有兴趣有时间,都可以试试,下篇再见。
OpenAI ChatGpt API参考
在线免费体验:
sisss.cn
编写了一个python写的ChatGPT的web服务,基于aigcfun仿写:
https://github.com/liupig/ChatGptWeb
介绍
您可以通过来自任何语言的 HTTP 请求、通过我们的官方 Python 绑定、我们的官方 Node.js 库或社区维护的库与 API 交互。
要安装官方 Python 绑定,请运行以下命令:
pip install openai
要安装官方 Node.js 库,请在 Node.js 项目目录中运行以下命令:
npm install openai
验证
OpenAI API 使用 API 密钥进行身份验证。访问您的API 密钥页面以检索您将在请求中使用的 API 密钥。
请记住,您的 API 密钥是秘密的!不要与他人共享或在任何客户端代码(浏览器、应用程序)中公开它。生产请求必须通过您自己的后端服务器进行路由,您的 API 密钥可以从环境变量或密钥管理服务中安全加载。
所有 API 请求都应在 HTTP 标头中包含您的 API 密钥,Authorization如下所示:
Authorization: Bearer YOUR_API_KEY
请求组织
对于属于多个组织的用户,您可以传递一个标头来指定哪个组织用于 API 请求。来自这些 API 请求的使用将计入指定组织的订阅配额。
卷曲命令示例:
curl https://api.openai.com/v1/models \\
-H 'Authorization: Bearer YOUR_API_KEY' \\
-H 'OpenAI-Organization: org-SwryXJEbmXJtrD5Kv9F4u1vf'
Python 包的示例openai:
import os
import openai
openai.organization = "org-SwryXJEbmXJtrD5Kv9F4u1vf"
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Model.list()
Node.js 包的示例openai:
import Configuration, OpenAIApi from "openai";
const configuration = new Configuration(
organization: "org-SwryXJEbmXJtrD5Kv9F4u1vf",
apiKey: process.env.OPENAI_API_KEY,
);
const openai = new OpenAIApi(configuration);
const response = await openai.listEngines();
组织 ID 可以在您的组织设置页面上找到。
发出请求
您可以将下面的命令粘贴到您的终端中以运行您的第一个 API 请求。确保替换YOUR_API_KEY为您的秘密 API 密钥。
curl https://api.openai.com/v1/completions \\
-H "Content-Type: application/json" \\
-H "Authorization: Bearer YOUR_API_KEY" \\
-d '"model": "text-davinci-003", "prompt": "Say this is a test", "temperature": 0, "max_tokens": 7'
此请求查询 Davinci 模型以完成以提示“ Say this is a test ”开头的文本。该参数设置了API 将返回的令牌max_tokens数量的上限。您应该会收到类似于以下内容的响应:
"id": "cmpl-GERzeJQ4lvqPk8SkZu4XMIuR",
"object": "text_completion",
"created": 1586839808,
"model": "text-davinci:003",
"choices": [
"text": "\\n\\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
],
"usage":
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
现在你已经生成了你的第一个完成。echo如果您连接提示和完成文本(如果您将参数设置为 ,API 将为您执行此操作true),则生成的文本为“ Say this is a test. This indeed a test. ”您还可以将stream参数设置为true用于 API 流回文本(作为仅数据服务器发送的事件)。
模型
列出并描述 API 中可用的各种模型。您可以参考模型文档以了解可用的模型以及它们之间的区别。
列出模型
得到
https://api.openai.com/v1/models
列出当前可用的模型,并提供有关每个模型的基本信息,例如所有者和可用性。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/models \\
-H 'Authorization: Bearer YOUR_API_KEY'
回复
"data": [
"id": "model-id-0",
"object": "model",
"owned_by": "organization-owner",
"permission": [...]
,
"id": "model-id-1",
"object": "model",
"owned_by": "organization-owner",
"permission": [...]
,
"id": "model-id-2",
"object": "model",
"owned_by": "openai",
"permission": [...]
,
],
"object": "list"
检索模型
得到
https://api.openai.com/v1 /models/模型
检索模型实例,提供有关模型的基本信息,例如所有者和权限。
路径参数
模型
细绳
必需的
用于此请求的模型的 ID
示例请求
文本-davinci-003
文本-davinci-003
卷曲
卷曲
curl https://api.openai.com/v1/models/text-davinci-003 \\
-H 'Authorization: Bearer YOUR_API_KEY'
回复
文本-davinci-003
文本-davinci-003
"id": "text-davinci-003",
"object": "model",
"owned_by": "openai",
"permission": [...]
完工
给定一个提示,该模型将返回一个或多个预测的完成,并且还可以返回每个位置的替代标记的概率。
创建完成
邮政
https://api.openai.com/v1/completions
为提供的提示和参数创建完成
请求正文
模型
细绳
必需的
要使用的模型的 ID。您可以使用List models API 来查看所有可用模型,或查看我们的模型概述以了解它们的描述。
迅速的
字符串或数组
选修的
默认为<|endoftext|>
生成完成的提示,编码为字符串、字符串数组、标记数组或标记数组数组。
请注意,<|endoftext|> 是模型在训练期间看到的文档分隔符,因此如果未指定提示,模型将生成新文档的开头。
后缀
细绳
选修的
默认为空
插入文本完成后出现的后缀。
最大令牌数
整数
选修的
默认为16
完成时生成的最大令牌数。
您的提示加上的令牌计数max_tokens不能超过模型的上下文长度。大多数模型的上下文长度为 2048 个标记(最新模型除外,它支持 4096)。
温度
数字
选修的
默认为1
使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。
我们通常建议改变这个或top_p但不是两者。
top_p
数字
选修的
默认为1
一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。
我们通常建议改变这个或temperature但不是两者。
n
整数
选修的
默认为1
为每个提示生成多少完成。
注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对max_tokens和进行了合理的设置stop。
溪流
布尔值
选修的
默认为假
是否回流部分进度。如果设置,令牌将在可用时作为仅数据服务器发送事件发送,流由data: [DONE]消息终止。
日志概率
整数
选修的
默认为空
包括logprobs最有可能标记的对数概率,以及所选标记。例如,如果logprobs是 5,API 将返回 5 个最有可能的标记的列表。API 将始终返回logprob采样令牌的 ,因此响应中最多可能有logprobs+1元素。
的最大值logprobs为 5。如果您需要更多,请通过我们的帮助中心联系我们并描述您的用例。
回声
布尔值
选修的
默认为假
除了完成之外回显提示
停止
字符串或数组
选修的
默认为空
API 将停止生成更多令牌的最多 4 个序列。返回的文本将不包含停止序列。
存在_惩罚
数字
选修的
默认为0
-2.0 和 2.0 之间的数字。正值会根据到目前为止是否出现在文本中来惩罚新标记,从而增加模型谈论新主题的可能性。
查看有关频率和存在惩罚的更多信息。
频率惩罚
数字
选修的
默认为0
-2.0 和 2.0 之间的数字。正值会根据新标记在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性。
查看有关频率和存在惩罚的更多信息。
最好的
整数
选修的
默认为1
在服务器端生成best_of完成并返回“最佳”(每个标记具有最高对数概率的那个)。无法流式传输结果。
与 一起使用时n,best_of控制候选完成的数量并n指定要返回的数量 -best_of必须大于n。
注意:因为这个参数会产生很多完成,它会很快消耗你的令牌配额。请谨慎使用并确保您对max_tokens和进行了合理的设置stop。
logit_bias
地图
选修的
默认为空
修改指定标记出现在完成中的可能性。
接受一个 json 对象,该对象将令牌(由 GPT 分词器中的令牌 ID 指定)映射到从 -100 到 100 的相关偏差值。您可以使用此分词器工具(适用于 GPT-2 和 GPT-3)来转换文本到令牌 ID。从数学上讲,偏差会在采样之前添加到模型生成的对数中。确切的效果因模型而异,但 -1 和 1 之间的值应该会减少或增加选择的可能性;像 -100 或 100 这样的值应该导致相关令牌的禁止或独占选择。
例如,您可以传递“50256”: -100以防止生成 <|endoftext|> 标记。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
文本-davinci-003
文本-davinci-003
卷曲
卷曲
curl https://api.openai.com/v1/completions \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_API_KEY' \\
-d '
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
'
参数
文本-davinci-003
文本-davinci-003
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0,
"top_p": 1,
"n": 1,
"stream": false,
"logprobs": null,
"stop": "\\n"
回复
文本-davinci-003
文本-davinci-003
"id": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7",
"object": "text_completion",
"created": 1589478378,
"model": "text-davinci-003",
"choices": [
"text": "\\n\\nThis is indeed a test",
"index": 0,
"logprobs": null,
"finish_reason": "length"
],
"usage":
"prompt_tokens": 5,
"completion_tokens": 7,
"total_tokens": 12
编辑
给定提示和指令,模型将返回提示的编辑版本。
创建编辑
邮政
https://api.openai.com/v1/edits _
为提供的输入、指令和参数创建新的编辑。
请求正文
模型
细绳
必需的
要使用的模型的 ID。您可以将text-davinci-edit-001或code-davinci-edit-001模型与此端点一起使用。
输入
细绳
选修的
默认为’’
用作编辑起点的输入文本。
操作说明
细绳
必需的
告诉模型如何编辑提示的指令。
n
整数
选修的
默认为1
为输入和指令生成多少编辑。
温度
数字
选修的
默认为1
使用什么采样温度,介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使输出更加集中和确定。
我们通常建议改变这个或top_p但不是两者。
top_p
数字
选修的
默认为1
一种替代温度采样的方法,称为核采样,其中模型考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只考虑构成前 10% 概率质量的标记。
我们通常建议改变这个或temperature但不是两者。
示例请求
text-davinci-edit-001
text-davinci-edit-001
卷曲
卷曲
curl https://api.openai.com/v1/edits \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_API_KEY' \\
-d '
"model": "text-davinci-edit-001",
"input": "What day of the wek is it?",
"instruction": "Fix the spelling mistakes"
'
参数
text-davinci-edit-001
text-davinci-edit-001
"model": "text-davinci-edit-001",
"input": "What day of the wek is it?",
"instruction": "Fix the spelling mistakes",
回复
"object": "edit",
"created": 1589478378,
"choices": [
"text": "What day of the week is it?",
"index": 0,
],
"usage":
"prompt_tokens": 25,
"completion_tokens": 32,
"total_tokens": 57
图片
给定提示和/或输入图像,模型将生成新图像。
相关指南:图像生成
创建图像测试版
邮政
https://api.openai.com/v1/images/generations
根据提示创建图像。
请求正文
迅速的
细绳
必需的
所需图像的文本描述。最大长度为 1000 个字符。
n
整数
选修的
默认为1
要生成的图像数。必须介于 1 和 10 之间。
尺寸
细绳
选修的
默认为1024x1024
生成图像的大小。必须是256x256、512x512或之一1024x1024。
响应格式
细绳
选修的
默认为url
生成的图像返回的格式。必须是 或url之一b64_json。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/images/generations \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_API_KEY' \\
-d '
"prompt": "A cute baby sea otter",
"n": 2,
"size": "1024x1024"
'
参数
"prompt": "A cute baby sea otter",
"n": 2,
"size": "1024x1024"
回复
"created": 1589478378,
"data": [
"url": "https://..."
,
"url": "https://..."
]
创建图像编辑测试版
邮政
https://api.openai.com/v1/images/edits
在给定原始图像和提示的情况下创建编辑或扩展图像。
请求正文
图像
细绳
必需的
要编辑的图像。必须是有效的 PNG 文件,小于 4MB,并且是方形的。如果未提供遮罩,图像必须具有透明度,将用作遮罩。
面具
细绳
选修的
附加图像,其完全透明区域(例如,alpha 为零的区域)指示image应编辑的位置。必须是有效的 PNG 文件,小于 4MB,并且与image.
迅速的
细绳
必需的
所需图像的文本描述。最大长度为 1000 个字符。
n
整数
选修的
默认为1
要生成的图像数。必须介于 1 和 10 之间。
尺寸
细绳
选修的
默认为1024x1024
生成图像的大小。必须是256x256、512x512或之一1024x1024。
响应格式
细绳
选修的
默认为url
生成的图像返回的格式。必须是 或url之一b64_json。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/images/edits \\
-H 'Authorization: Bearer YOUR_API_KEY' \\
-F image='@otter.png' \\
-F mask='@mask.png' \\
-F prompt="A cute baby sea otter wearing a beret" \\
-F n=2 \\
-F size="1024x1024"
回复
"created": 1589478378,
"data": [
"url": "https://..."
,
"url": "https://..."
]
创建图像变体测试版
邮政
https://api.openai.com/v1/images/variations _
创建给定图像的变体。
请求正文
图像
细绳
必需的
用作变体基础的图像。必须是有效的 PNG 文件,小于 4MB,并且是方形的。
n
整数
选修的
默认为1
要生成的图像数。必须介于 1 和 10 之间。
尺寸
细绳
选修的
默认为1024x1024
生成图像的大小。必须是256x256、512x512或之一1024x1024。
响应格式
细绳
选修的
默认为url
生成的图像返回的格式。必须是 或url之一b64_json。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/images/variations \\
-H 'Authorization: Bearer YOUR_API_KEY' \\
-F image='@otter.png' \\
-F n=2 \\
-F size="1024x1024"
回复
"created": 1589478378,
"data": [
"url": "https://..."
,
"url": "https://..."
]
嵌入
获取给定输入的矢量表示,机器学习模型和算法可以轻松使用该表示。
相关指南:嵌入
创建嵌入
邮政
https://api.openai.com/v1/embeddings
创建表示输入文本的嵌入向量。
请求正文
模型
细绳
必需的
要使用的模型的 ID。您可以使用List models API 来查看所有可用模型,或查看我们的模型概述以了解它们的描述。
输入
字符串或数组
必需的
输入文本以获取嵌入,编码为字符串或标记数组。要在单个请求中获取多个输入的嵌入,请传递一个字符串数组或令牌数组数组。每个输入的长度不得超过 8192 个标记。
用户
细绳
选修的
代表您的最终用户的唯一标识符,可以帮助 OpenAI 监控和检测滥用行为。了解更多。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/embeddings \\
-X POST \\
-H "Authorization: Bearer YOUR_API_KEY" \\
-H "Content-Type: application/json" \\
-d '"input": "The food was delicious and the waiter...",
"model": "text-embedding-ada-002"'
参数
"model": "text-embedding-ada-002",
"input": "The food was delicious and the waiter..."
回复
"object": "list",
"data": [
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
],
"model": "text-embedding-ada-002",
"usage":
"prompt_tokens": 8,
"total_tokens": 8
文件
文件用于上传可与微调等功能一起使用的文档。
列出文件
得到
https://api.openai.com/v1/files
返回属于用户组织的文件列表。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/files \\
-H 'Authorization: Bearer YOUR_API_KEY'
回复
"data": [
"id": "file-ccdDZrC3iZVNiQVeEA6Z66wf",
"object": "file",
"bytes": 175,
"created_at": 1613677385,
"filename": "train.jsonl",
"purpose": "search"
,
"id": "file-XjGxS3KTG0uNmNOK362iJua3",
"object": "file",
"bytes": 140,
"created_at": 1613779121,
"filename": "puppy.jsonl",
"purpose": "search"
],
"object": "list"
上传文件
邮政
https://api.openai.com/v1/files
上传包含要跨各种端点/功能使用的文档的文件。目前,一个组织上传的所有文件的大小最大可达 1 GB。如果您需要增加存储限制,请联系我们。
请求正文
文件
细绳
必需的
要上传的JSON 行文件的名称。
如果purpose设置为“微调”,则每一行都是一个 JSON 记录,其中包含代表您的训练示例的“提示”和“完成”字段。
目的
细绳
必需的
上传文件的预期目的。
使用“微调”进行微调。这使我们能够验证上传文件的格式。
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/files \\
-H "Authorization: Bearer YOUR_API_KEY" \\
-F purpose="fine-tune" \\
-F file='@mydata.jsonl'
回复
"id": "file-XjGxS3KTG0uNmNOK362iJua3",
"object": "file",
"bytes": 140,
"created_at": 1613779121,
"filename": "mydata.jsonl",
"purpose": "fine-tune"
删除文件
删除
https://api.openai.com/v1 /files/file_id
删除文件。
路径参数
文件编号
细绳
必需的
用于此请求的文件的 ID
示例请求
卷曲
卷曲
curl https://api.openai.com/v1/files/file-XjGxS3KTG0uNmNOK362iJua3 \\
-X DELETE \\
-H 'Authorization: Bearer YOUR_API_KEY'
回复
"id": "file-XjGxS3KTG0uNmNOK362iJua3",
"object": "file",
"deleted": true
检索文件
得到
https://api.openai.com/v1/files/file_id
返回有关特定文件的信息。
路径参数
文件编号
细绳
必需的
用于此请求的文件的 ID
示例请求
卷曲
卷曲
1
2
curl https://api.openai.com/v1/files/file-XjGxS3KTG0uNmNOK362iJua3
-H ‘Authorization: Bearer YOUR_API_KEY’
回复
1
2
3
4
5
6
7
8
“id”: “file-XjGxS3KTG0uNmNOK362iJua3”,
“object”: “file”,
“bytes”: 140,
“created_at”: 1613779657,
“filename”: “mydata.jsonl”,
“purpose”: “fine-tune”
检索文件内容
得到
https://api.openai.com/v1 /files/file_id/content
返回指定文件的内容
路径参数
文件编号
细绳
必需的
用于此请求的文件的 ID
示例请求
卷曲
卷曲
1
2
curl https://api.openai.com/v1/files/file-XjGxS3KTG0uNmNOK362iJua3/content
-H ‘Authorization: Bearer YOUR_API_KEY’ > file.jsonl
微调
管理微调作业以根据您的特定训练数据定制模型。
相关指南:微调模型
创建微调
邮政
https://api.openai.com/v1/fine-tunes _
创建一个从给定数据集微调指定模型的作业。
响应包括排队作业的详细信息,包括作业状态和完成后微调模型的名称。
了解有关微调的更多信息
请求正文
培训文件
细绳
必需的
包含训练数据的上传文件的 ID。
有关如何上传文件,请参见上传文件。
您的数据集必须格式化为 JSONL 文件,其中每个训练示例都是一个带有键“提示”和“完成”的 JSON 对象。此外,您必须上传带有目的的文件fine-tune。
有关详细信息,请参阅微调指南。
验证文件
细绳
选修的
包含验证数据的上传文件的 ID。
如果您提供此文件,该数据将用于在微调期间定期生成验证指标。这些指标可以在微调结果文件中查看。您的火车和验证数据应该是互斥的。
您的数据集必须格式化为 JSONL 文件,其中每个验证示例都是一个带有键“prompt”和“completion”的 JSON 对象。此外,您必须上传带有目的的文件fine-tune。
有关详细信息,请参阅微调指南。
模型
细绳
选修的
默认居里
要微调的基本模型的名称。您可以选择“ada”、“babbage”、“curie”、“davinci”或 2022-04-21 之后创建的微调模型之一。要了解有关这些模型的更多信息,请参阅 模型文档。
n_epochs
整数
选修的
默认为4
训练模型的时期数。一个纪元指的是训练数据集的一个完整周期。
批量大小
整数
选修的
默认为空
用于训练的批量大小。批量大小是用于训练单个前向和后向传递的训练示例数。
默认情况下,批量大小将动态配置为训练集中示例数量的 0.2%,上限为 256 - 通常,我们发现较大的批量大小往往更适用于较大的数据集。
学习率乘数
数字
选修的
默认为空
用于训练的学习率乘数。微调学习率是用于预训练的原始学习率乘以该值。
默认情况下,学习率乘数是 0.05、0.1 或 0.2,具体取决于 final batch_size(较大的学习率往往在较大的批量大小下表现更好)。我们建议使用 0.02 到 0.2 范围内的值进行试验,
以上是关于OpenAi[ChatGPT] 使用Python对接OpenAi APi 实现智能QQ机器人-学习详解篇的主要内容,如果未能解决你的问题,请参考以下文章
基于ChatGPT+Python快速打造前后端分离的OpenAI人工智能聊天机器人
瑟瑟发抖吧~OpenAI刚刚推出王炸——引入ChatGPT插件,开启AI新生态
ChatGPT 国内无需注册 openai 即可访问 ChatGPT:ChatGPT Sidebar 浏览器扩展程序的安装与使用