kafka生产者客户端链路架构梳理
Posted 另一花生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka生产者客户端链路架构梳理相关的知识,希望对你有一定的参考价值。
一、整体架构
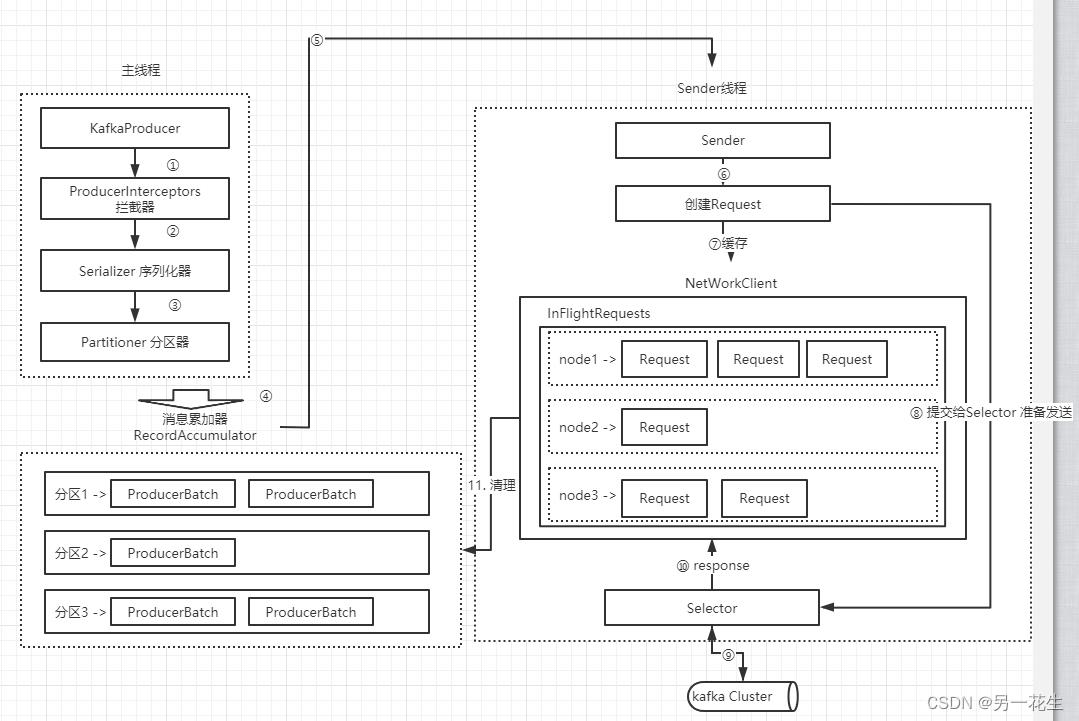
二、详细环节
1. 拦截器(Interceptor)
是早在Kafka 0.10.0.0中就已经引入的一个功能,Kafka一共有两种拦截器:生产者拦截器和消费者拦截器。
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
自定义实现org.apache.kafka.clients.producer.ProducerInterceptor接口
2. 序列化器:
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给Kafka。而在对侧,消费者需要用反序列化器(Deserializer)把从 Kafka 中收到的字节数组转换成相应的对象。
需要实现: org.apache.kafka.common.serialization.Serializer接口
生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的,如果生产者使用了某种序列化器,比如StringSerializer,而消费者使用了另一种序列化器,比如IntegerSerializer,那么是无法解析出想要的数据的。
3. 分区器
消息在通过send()方法发往broker的过程中,有可能需要经过拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)的一系列作用之后才能被真正地发往 broker。拦截器(下一章会详细介绍)一般不是必需的,而序列化器是必需的。消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。如果消息ProducerRecord中没有指定partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值。分区器的作用就是为消息分配分区。
默认实现: org.apache.kafka.clients.producer.internals.DefaultPartitioner
4. 消息累加器
Sender 线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。RecordAccumulator 缓存的大小可以通过生产者客户端参数buffer.memory 配置,默认值为 33554432B,即 32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候KafkaProducer的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数max.block.ms的配置,此参数的默认值为60000,即60秒。
5. 发送
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区,Deque<ProducerBatch>>的保存形式转变成<Node,List<ProducerBatch>的形式,其中Node表示Kafka集群的broker节点。对于网络连接来说,生产者客户端是与具体的broker节点建立的连接,也就是向具体的broker 节点发送消息,而并不关心消息属于哪一个分区;而对于 KafkaProducer的应用逻辑而言,我们只关注向哪个分区中发送哪些消息,所以在这里需要做一个应用逻辑层面到网络I/O层面的转换。
6. 转换Request
在转换成<Node,List<ProducerBatch>>的形式之后,Sender 还会进一步封装成<Node,Request>的形式,这样就可以将Request请求发往各个Node了,这里的Request是指Kafka的各种协议请求,对于消息发送而言就是指具体的ProduceRequest
7. 缓存
请求在从Sender线程发往Kafka之前还会保存到InFlightRequests中,InFlightRequests保存对象的具体形式为 Map<NodeId,Deque<Request>>,它的主要作用是缓存了已经发出去但还没有收到响应的请求(NodeId 是一个String 类型,表示节点的 id 编号)。与此同时,InFlightRequests还提供了许多管理类的方法,并且通过配置参数还可以限制每个连接(也就是客户端与Node之间的连接)最多缓存的请求数。这个配置参数为max.in.flight.requests.per.connection,默认值为 5,即每个连接最多只能缓存5 个未响应的请求,超过该数值之后就不能再向这个连接发送更多的请求了,除非有缓存的请求收到了响应(Response)。通过比较Deque<Request>的size与这个参数的大小来判断对应的Node中是否已经堆积了很多未响应的消息,如果真是如此,那么说明这个 Node 节点负载较大或网络连接有问题,再继续向其发送请求会增大请求超时的可能
8. Selector
多路复用选择器准备发送信息
9. 将信息发送到kafka集群
10. 得到相应结果response
11. 清理消息累加器中已经发送成功的消息缓存
Kafka 的生产者优秀架构设计


生产者流程概述
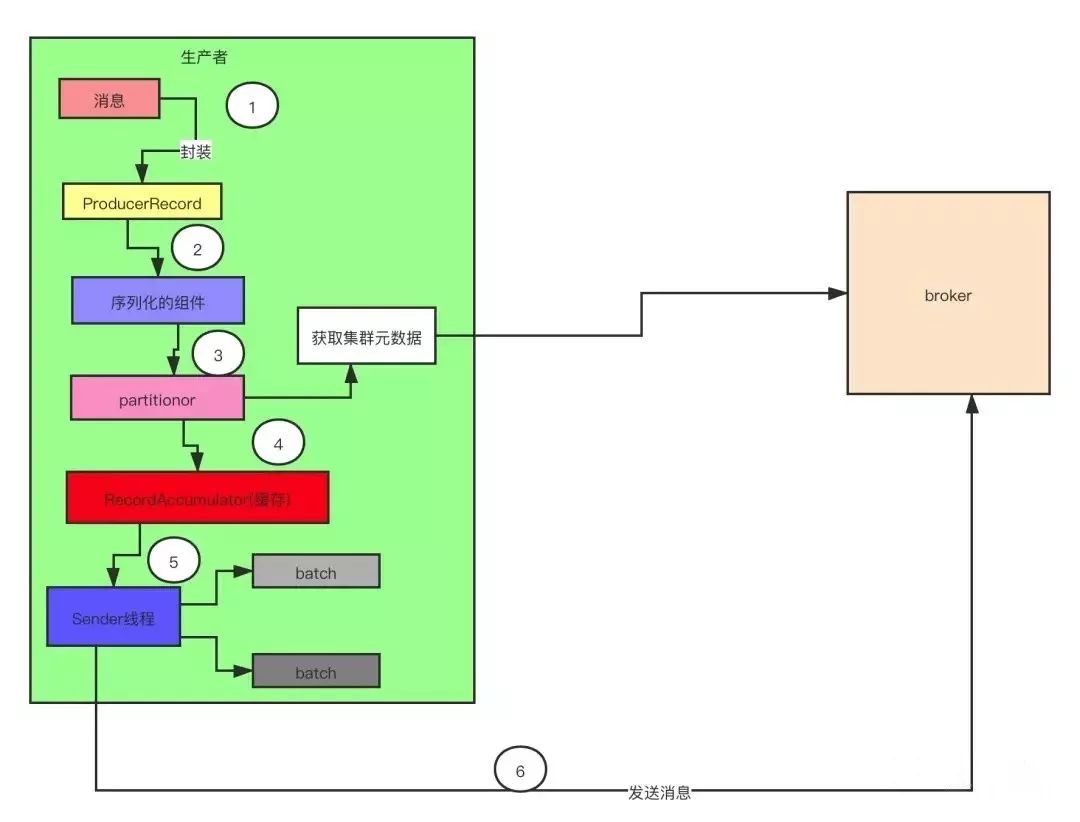
步骤二: 接下来要对这个对象进行序列化,因为 Kafka 的消息需要从客户端传到服务端,涉及到网络传输,所以需要实现序列。Kafka 提供了 默认的序列化机制,也支持自定义序列化(这种设计也值得我们积累,提高项目的扩展性)。
步骤三: 消息序列化完了以后,对消息要进行分区,分区的时候需要获取集群的元数据。分区的这个过程很关键,因为这个时候就决定了,我们的这条消息会被发送到 Kafka 服务端到哪个主题的哪个分区了。
步骤四: 分好区的消息不是直接被发送到服务端,而是放入了生产者的一个缓存里面。在这个缓存里面,多条消息会被封装成为一个批次(batch),默认一个批次的大小是 16K。
步骤五: Sender 线程启动以后会从缓存里面去获取可以发送的批次。
步骤六: Sender 线程把一个一个批次发送到服务端。大家要注意这个设计,在 Kafka0.8 版本以前,Kafka 生产者的设计是来一条数据,就往服务端发送一条数据,频繁的发生网络请求,结果性能很差。后面的版本再次架构演进的时候把这儿改成了批处理的方式,性能指数级的提升,这个设计值得我们积累。

接下来我们生产者这儿技术含量比较高的一个地方,前面概述那儿我们看到,一个消息被分区以后,消息就会被放到一个缓存里面,我们看一下里面具体的细节。默认缓存块的大小是 32M,这个缓存块里面有一个重要的数据结构:batches,这个数据结构是 key-value 的结果,key 就是消息主题的分区,value 是一个队列,里面存的是发送到对应分区的批次,Sender 线程就是把这些批次发送到服务端。
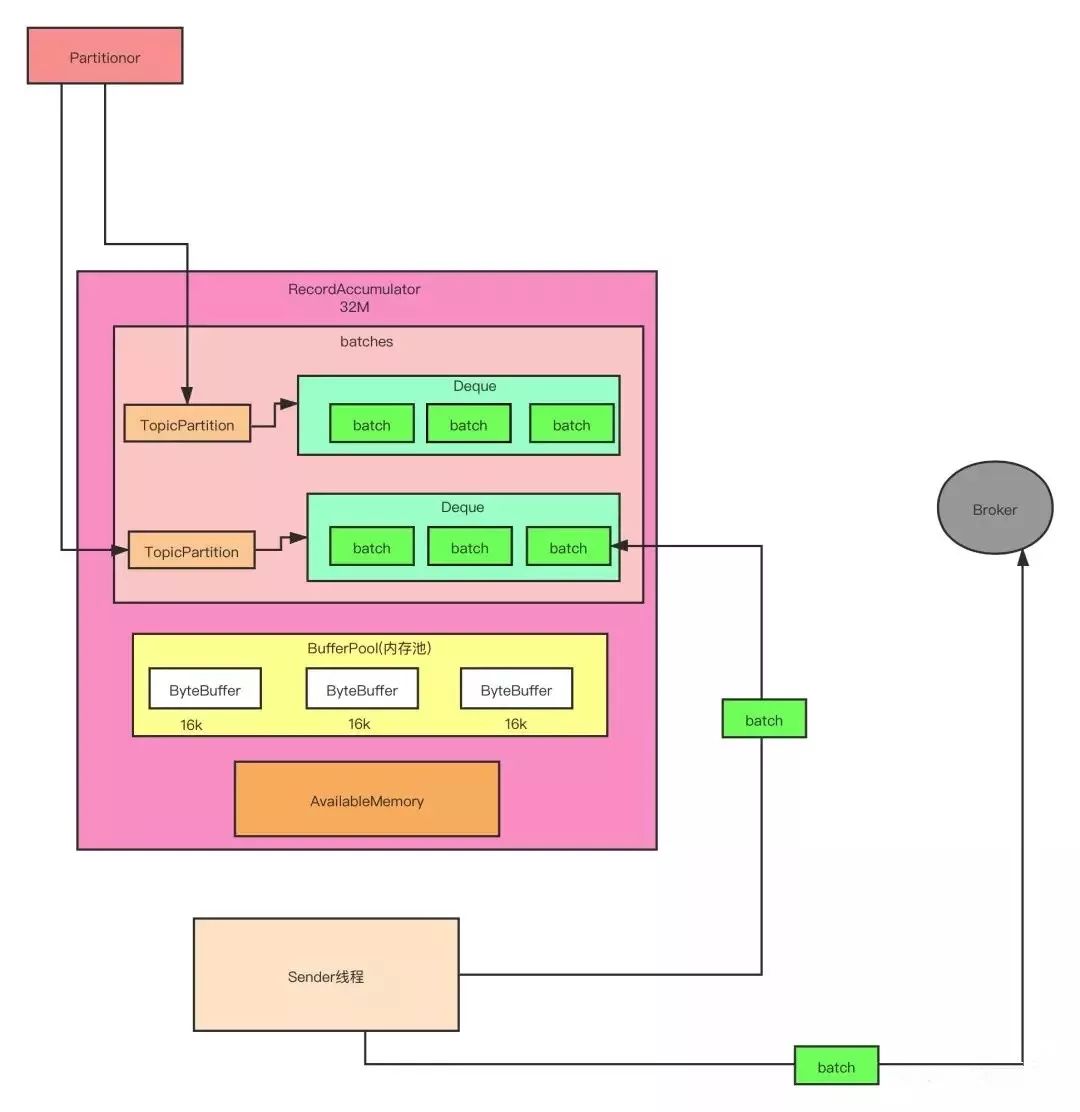
1
他们存储的信息的是 key-value 的结构,key 是分区,value 是要存到这个分区的对应批次(批次可能有多个,所以用的是队列),故因为是 key-value 的数据结构,所以锁定用 Map 数据结构。
2
这个 Kafka 生产者面临的是一个高并发的场景,大量的消息会涌入这个这个数据结构,所以这个数据结构需要保证线程安全,这样我们就不能使用 HashMap 这样的数据结构了。
3
这个数据结构需要支持的是读多写少的场景。读多是因为每条消息过来都会根据 key 读取 value 的信息,假如有 1000 万条消息,那么就会读取 batches 对象 1000 万次。写少是因为,比如我们生产者发送数据需要往一个主题里面去发送数据,假设这个主题有 50 个分区,那么这个 batches 里面就需要写 50 个 key-value 数据就可以了(大家要搞清楚我们虽然要写 1000 万条数据,但是这 1000 万条是写入 queue 队列的 batch 里的,并不是直接写入 batches,所以就我们刚刚说的这个场景,batches 里只需要最多写 50 条数据就可以了)。
以上是关于kafka生产者客户端链路架构梳理的主要内容,如果未能解决你的问题,请参考以下文章