sleuth+zipkin+kafka+logstash链路追踪二次开发方案
Posted sharedCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sleuth+zipkin+kafka+logstash链路追踪二次开发方案相关的知识,希望对你有一定的参考价值。
系统架构方案
方案一
架构说明:
1.应用接入zipkin客户端,将span的信息直接推送给kafka
2.zipkin-server定kafka中订阅主体为sleuth的消息,将span中的信息推送到elasticsearch中
3.zipkin-ui项目负责从elasticsearch读取信息,分析信息,呈现图标给用户。
方案二
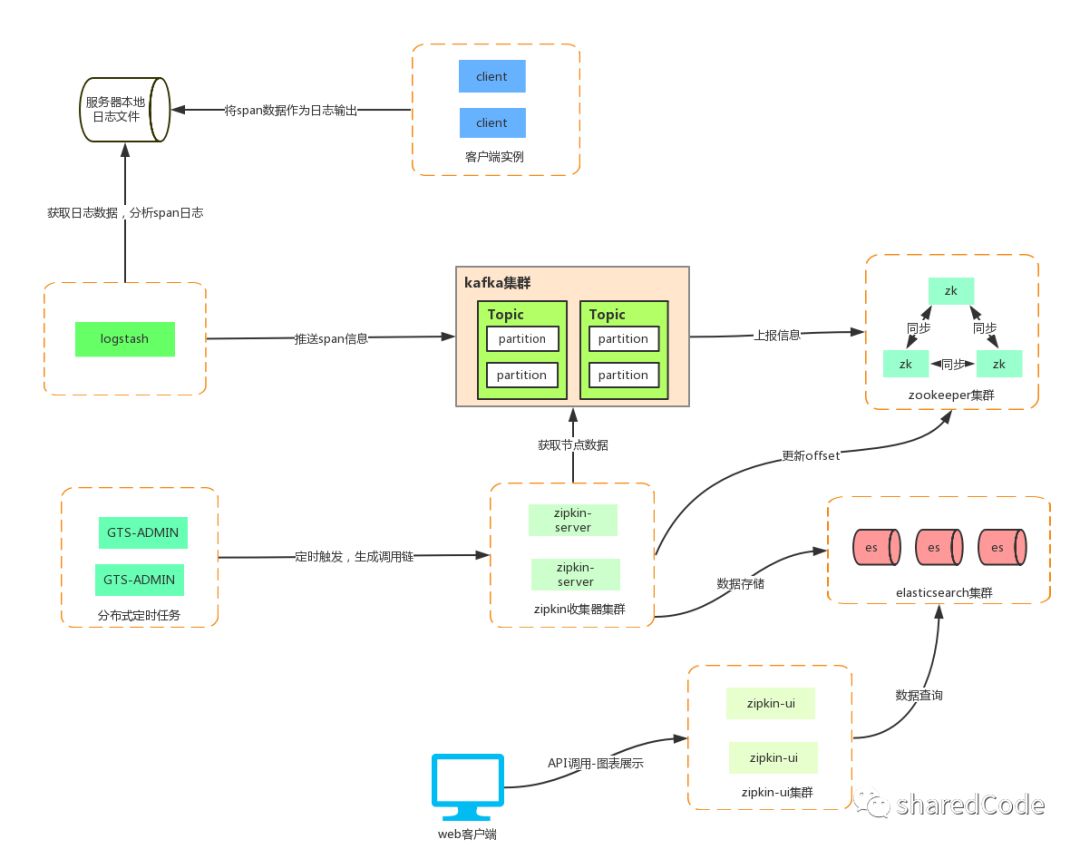
架构说明:
1.接入链路追踪的客户端,仅需对本地日志输出进行配置,输出span的信息到本地文件里面
2.部署logstash,读取应用的span日志信息,然后将span信息发送给kafka
3.zipkin-server通过消费kafka中,topic为“sleuth”的消息,将span信息存入elasticsearch
4.zipkin-ui项目负责从elasticsearch读取信息,分析信息,呈现图标给用户。
通过logstash分析本地日志的方式,对应用的侵入性,性能影响,高可用的影响 都是降到最低的。
比较
| 方案一 | 方案二 |
|
| 优点 | 部署复杂度较低,开发成本相对较低 | 应用的侵入性,性能影响,高可用的影响 都是降到最低的 |
| 缺点 | 当kafka或者zookeeper宕机时, 已经启动的应用没有影响,对于正在启动的应用会启动失败 | 部署复杂度较大 |
功能设计
首页
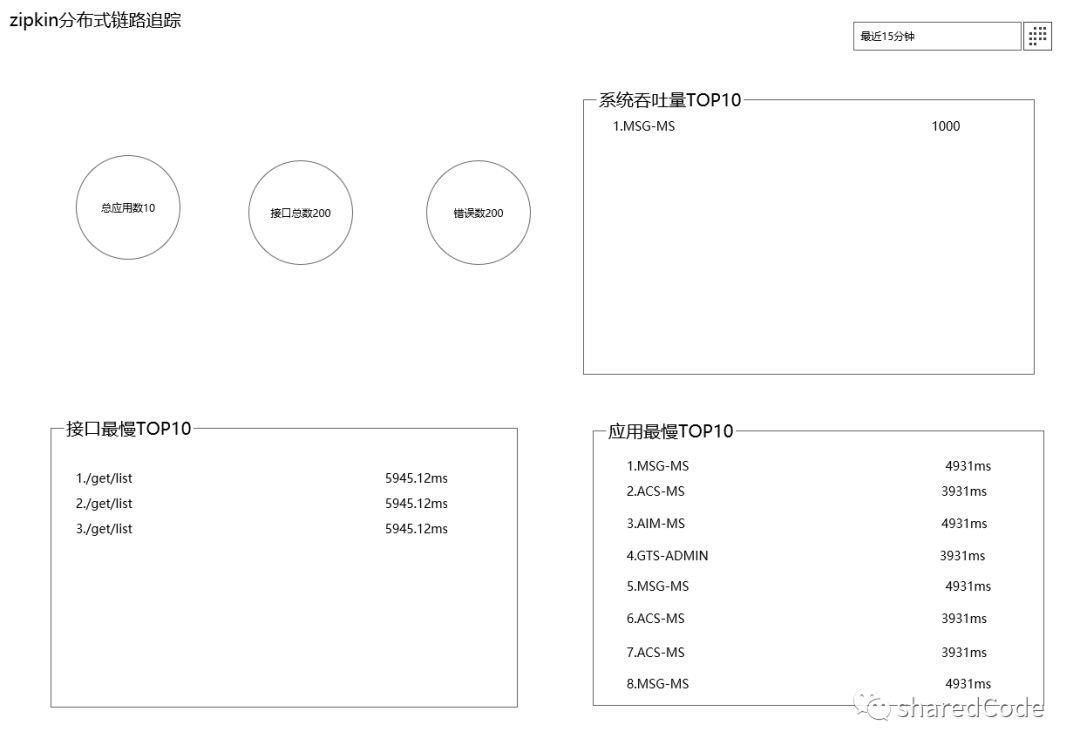
总应用数
接入全链路追踪系统的总应用数
总接口数
链路追踪系统所监测到的总接口数
错误数
最近15分钟之内发生的接口调用错误数量
系统吞吐量
以应用为维度,计算15分钟内的总请求数,求出每秒钟处理的接口数量。当然也可以是前一分钟内的请求总数,然后求出每秒钟平均处理的请求数。
接口最慢TOP10
查询所追踪到的系统,根据相应时间,最近15分钟内,平均响应时间最慢的接口前10
应用最慢TOP10
以应用为维度,查询应用在这15分钟内,所有的请求数据,求出平均响应时间,得到最慢的10个应用。
接口分析
接口列表
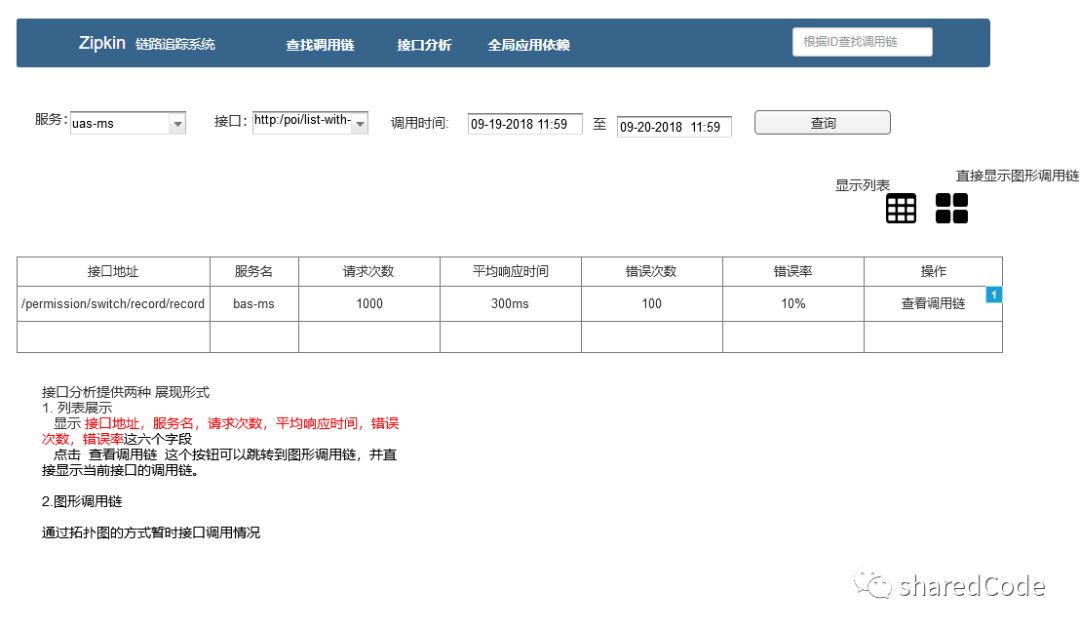
该页面,显示的是所有接口的调用次数,平均响应时间,错误次数等信息,可以看做是接口的全局预览。
接口调用链
当前接口的颜色要进行区分, 查询时间要进行限制,不可以查询所有数据,后期数量量较大
traceId管理
traceId列表
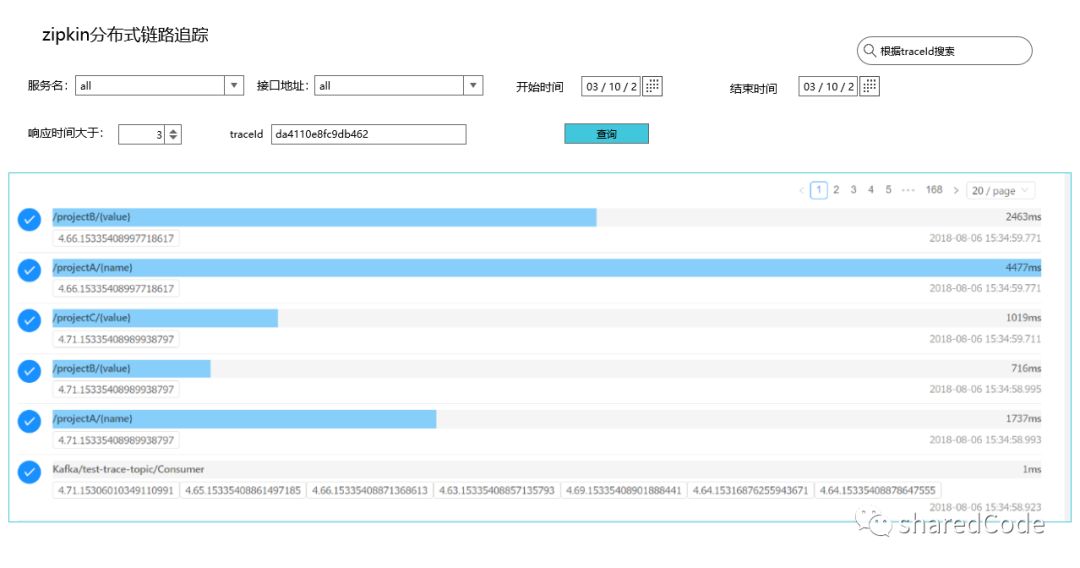
traceId 详情
页面样式可以参考原生的,显示的就是这个traceId关联的调用链
全局调用链
以上是关于sleuth+zipkin+kafka+logstash链路追踪二次开发方案的主要内容,如果未能解决你的问题,请参考以下文章
分布式链路跟踪sleuth(zipkin+kafka+elasticsearch)
Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪
Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪
Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪
Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪
在 docker 中与 Zipkin 和 kafka 一起使用时找不到 zipkin2.reporter.Sender bean