Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪相关的知识,希望对你有一定的参考价值。
文章目录
方案设计
SpringCloud 微服务 使用 Sleuth+ Zipkin 的应用架构实现链路追踪的逻辑图如下:
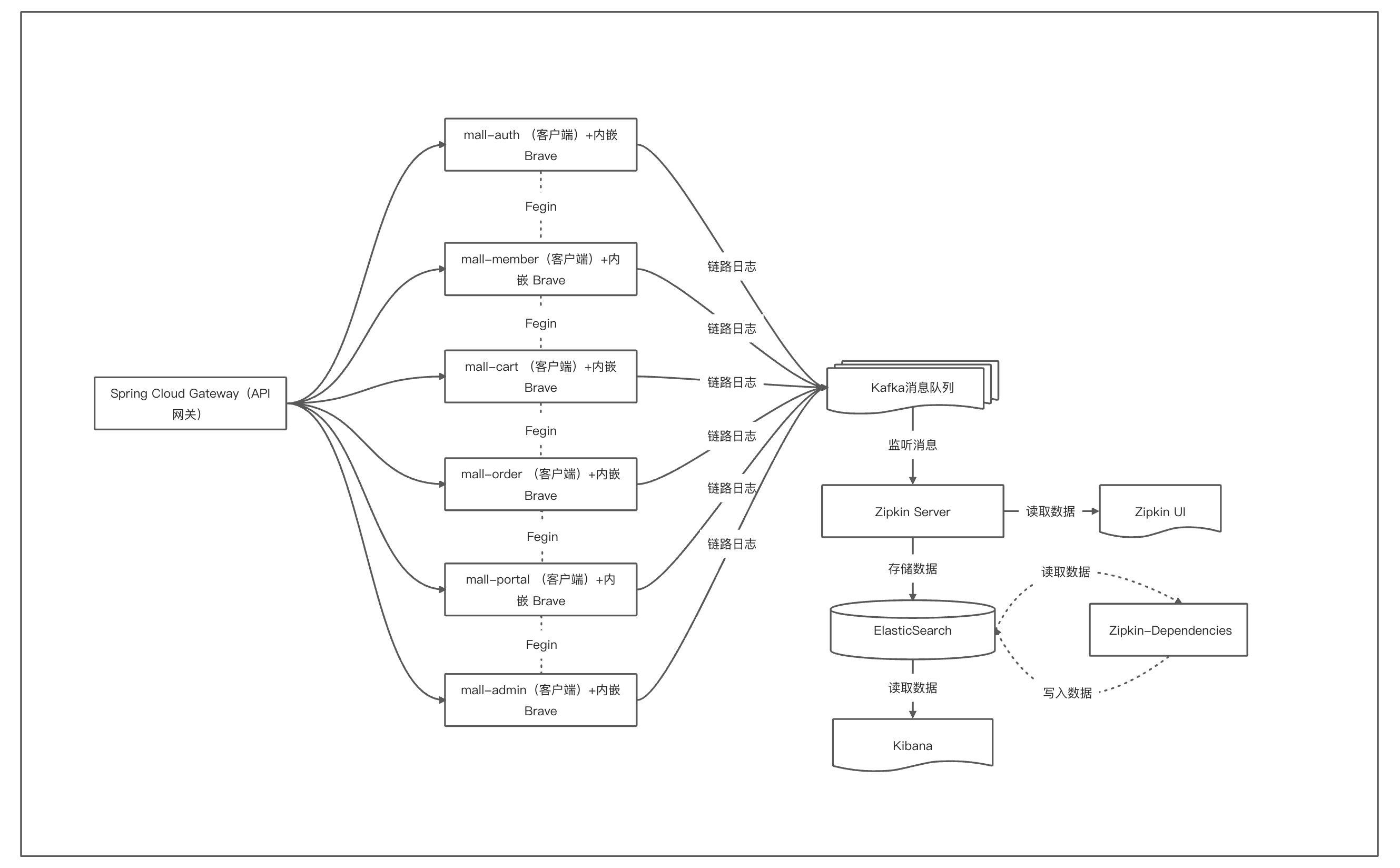
从架构图中可以看到:我们构建了一个服务网关,通过 API 网关调用具体的微服务,所有的服务都注册到 Nacos 上;当客户端的请求到来之时,网关作为服务端的门户,会根据配置的规则,从 Nacos 中获取对应服务的信息,并将请求反向代理到指定的服务实例。
我们这里将链路日志推送到 Kafka,然后启动 Zipkin Server 聚合日志,监听 Kafka ,如果有新的消息则进行拉取存入到 ElasticSeach,最后再用 Zipkin UI 展示链路过程。最后,我们再来梳理下整个系统链路追踪改造部分,它大概分为五大部分:
- 在服务中加入 Spring Cloud Sleuth 生成链路追踪日志;
- 使用 Brave 库,集成 Zipkin 客户端埋点。使用 instrumentation 插件,实现对 SpringMVC、mysql 等组件实现链路追踪的功能;
- 将链路日志推送到 Kafka;
- 启动 Zipkin Server 聚合日志,监听 Kafka ,如果有新的消息则进行拉取存入到 ElasticSeach;
- 最后使用 Zipkin UI 展示链路过程、使用 Kibana 查询链路数据。
环境准备
在实际生产环境中,从经验性角度,前置 kafka,一方面作为队列和缓冲,另一方面提供了统一的入口渠道。需要准备下面组件:
- Kafka: 需要拥有在 Kubernetes 环境中能访问的 Kafka 集群。
- ElasticSearch: 需要拥有在 Kubernetes 环境中能访问的 ElasticSearch 集群。
- Zipkin: 在 Kubernetes 中部署 Zipkin,后面将演示这个部署的过程。
- SpringCloud 服务: 需要两个 SpringCloud 服务,通过 Feign 相互调用接口产生链路日志便于测试,后面将演示如何写测试项目部署到 Kubernetes 中。
在 Kubernetes 中完成链路追踪流程的方案,需要依赖上面各个组件。
部署 Zipkin Server
创建 zipkin-server.yaml 资源文件
apiVersion: v1
kind: Service
metadata:
name: zipkin
labels:
app: zipkin
spec:
type: NodePort #指定为 NodePort 方式暴露出口
ports:
- name: server
port: 9411
targetPort: 9411
nodePort: 30190 #指定 Nodeport 端口
protocol: TCP
selector:
app: zipkin
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: zipkin
labels:
name: zipkin
spec:
replicas: 1
selector:
matchLabels:
app: zipkin
template:
metadata:
labels:
app: zipkin
spec:
containers:
- name: zipkin
image: openzipkin/zipkin
ports:
- containerPort: 9411
env:
- name: JAVA_OPTS
value: "
-Xms512m -Xmx512m
-Dlogging.level.zipkin=DEBUG
-Dlogging.level.zipkin2=DEBUG
-Duser.timezone=Asia/Shanghai
"
- name: STORAGE_TYPE
value: "elasticsearch" #设置数据存储在ES中
- name: ES_HOSTS
value: "elasticsearch-client:9200" #ES地址
- name: ES_INDEX #设置ES中存储的zipkin索引名称
value: "zipkin"
- name: ES_INDEX_REPLICAS #ES索引副本数
value: "1"
- name: ES_INDEX_SHARDS #ES分片数量
value: "3"
- name: ES_USERNAME #如果ES启用x-pack,需要设置用户名、密码
value: "elastic"
- name: ES_PASSWORD
value: "admin@123"
- name: KAFKA_BOOTSTRAP_SERVERS #Kafka 地址
value: "kafka:9092"
- name: KAFKA_TOPIC #Kafka Topic名称,默认为"zipkin"
value: "zipkin"
- name: KAFKA_GROUP_ID #Kafka 组名,默认为"zipkin"
value: "zipkin"
- name: KAFKA_STREAMS #消耗Topic的线程数,默认为1
value: "1"
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 500m
memory: 256Mi
关于 Zipkin Server 配置参数,可以参考:https://github.com/openzipkin/zipkin/tree/master/zipkin-server
创建资源:
kubectl apply -f zipkin-server.yaml
部署 Zipkin-Dependencies
zipkin-dependencies 是一个聚合数据依赖关系的服务,这里启动服务后它会自动从 ElasticSearch 中获取索引,分析依赖关系然后再以 zipkin索引名称-dependency-yyyy-mm-dd 命名创建新索引存入 ElasticSearch。
并且这个服务内置 Crond 定时任务,默认每隔一小时会执行分析 ElasticSearch 中索引关系的任务(在 Kubernetes 中将其设置一个 Job 任务来使用也是可以的,因为它每次启动时候都会先进行分析依赖数据,当然也可以用容器内部的 Crond 来执行定时任务)。
官网地址:https://github.com/openzipkin/zipkin-dependencies
注意:下面 yaml 中一定要设置 command 命令来启用 crond 定时任务,否则之后执行一次分析依赖关系任务后程序自动关闭。
创建资源文件 zipkin-dependencies.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: zipkin-dependencies
spec:
schedule: "*/5 * * * *"
jobTemplate:
spec:
ttlSecondsAfterFinished: 86400
template:
spec:
containers:
- name: zipkin
image: openzipkin/zipkin-dependencies:2.6
imagePullPolicy: IfNotPresent
env:
- name: JAVA_OPTS
value: "-Xms512m -Xmx512m -Duser.timezone=Asia/Shanghai"
- name: STORAGE_TYPE
value: elasticsearch
- name: ES_HOSTS
value: elasticsearch-client:9200
- name: ES_INDEX
value: zipkin
- name: ES_INDEX_REPLICAS
value: "1"
- name: ES_INDEX_SHARDS
value: "3"
- name: ES_USERNAME
value: elastic
- name: ES_PASSWORD
value: admin@123
- name: KAFKA_BOOTSTRAP_SERVERS
value: kafka:9092
- name: KAFKA_TOPIC
value: zipkin
- name: KAFKA_GROUP_ID
value: zipkin
- name: KAFKA_STREAMS
value: "1"
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 500m
memory: 256Mi
restartPolicy: OnFailure
部署资源:
kubectl apply -f zipkin-dependencies.yaml
微服务应用配置
第一步,我们需要在各个服务引入 Kafka 依赖。
<!-- 引入 Spring Cloud Stream Kafka-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
第二步,修改 bootstrap.yml 配置文件,增加 Kafka 系列配置。
spring:
zipkin: #设置zipkin服务端地址
sender:
type: kafka #指定发送到kafka,还可以指定Rabbit、Web
service:
name: $spring.application.name #Zipkin链路日志中收集的服务名称
kafka:
topic: zipkin
kafka:
bootstrap-servers: kafka:9092 #Kubernetes中Kakfa地址,当然也可以指定Kubernetes集群外的Kafk
测试查看链路信息
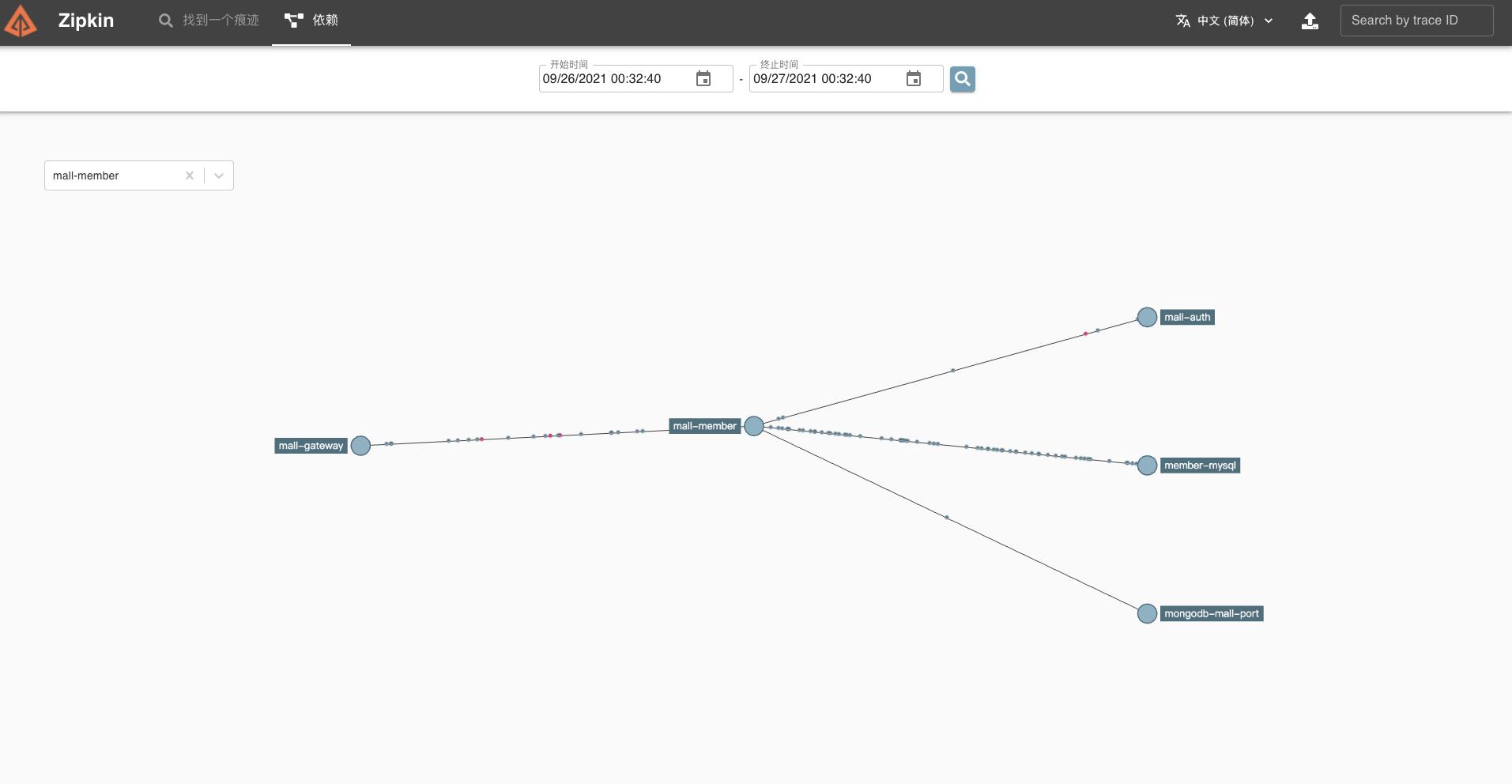
部署完成后就能通过node IP + NodePort 端口访问 Zipkin UI。可以看到 Zipkin 页面。

最后进行测试,首先需要调用服务接口,让其通过 Feign 调用,完成后再次打开 Zipkin UI 界面,点击进入 Dependency Links,然后按下分析按钮后出现链路依赖关系图。
源码地址:
- https://github.com/zuozewei/blog-example/tree/master/Kubernetes/k8s-zipkin
以上是关于Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪的主要内容,如果未能解决你的问题,请参考以下文章
Kubnernetes 集群部署 Zipkin+Kafka+ElasticSearch 实现链路追踪