Python神经网络学习--机器学习--线性回归
Posted ChuckieZhu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python神经网络学习--机器学习--线性回归相关的知识,希望对你有一定的参考价值。
前言
终于感觉我对这一章的理解比较深刻,并且也写出了像样的代码实现供大家参考,感觉自己可以写这篇文章,大家久等了。
线性回归
什么是线性回归?
线性回归常用于连续值的预测任务,最经典的例子就是:假设工资水平仅仅和工作时长有关,那么我们要找到一条直线,虽然这个直线不能穿过所有的样本点,但是能在误差尽量小的情况下给出一个预测,如下图所示:
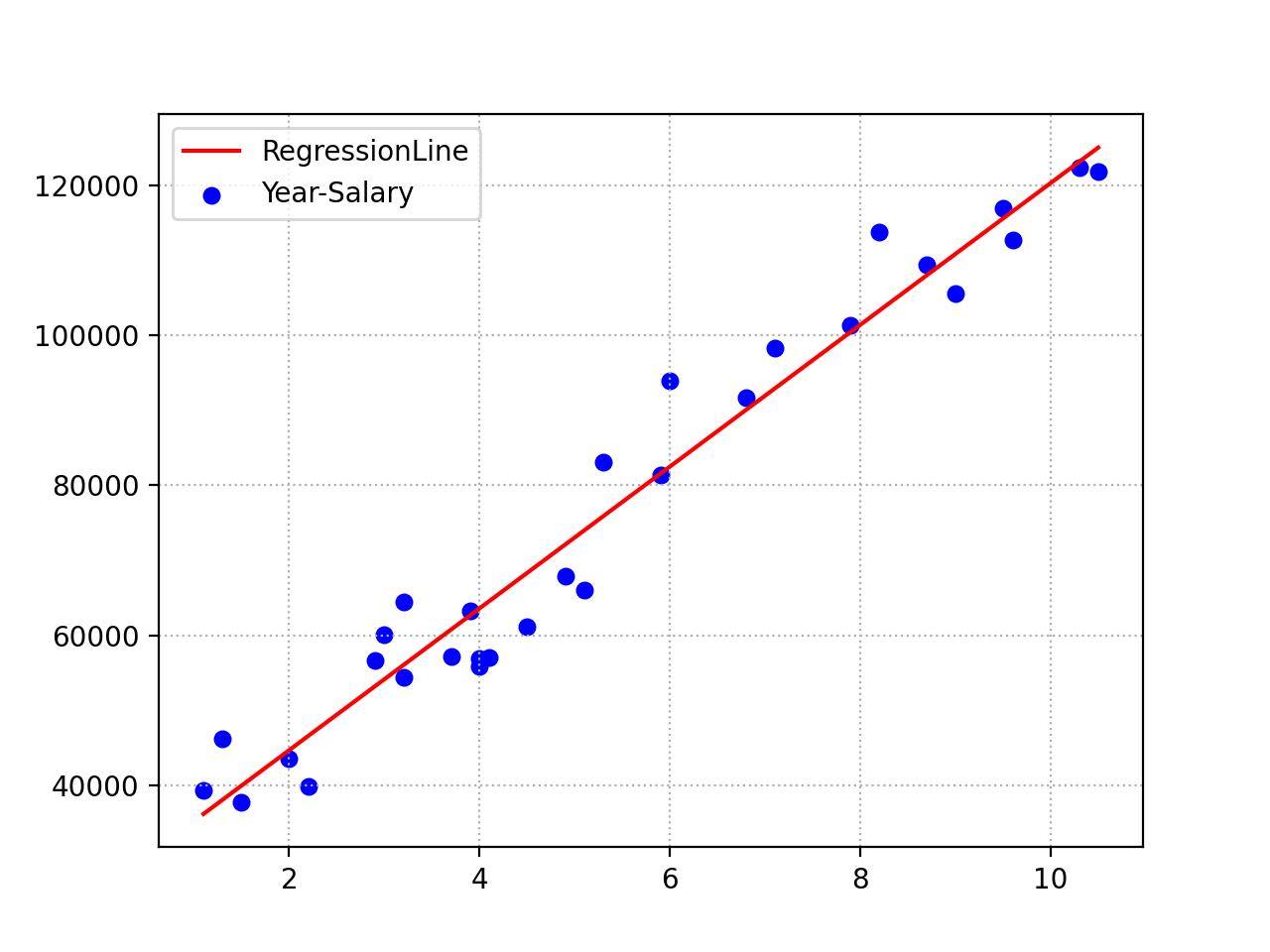
而得到这个直线之后,我们就可以输入工作年限,然后通过计算得出一个大概的工资,虽然跟实际拿到的工资并不一定一致,但是也能给出一个大致的估计。
线性模型
很容易看出, 回归线是一条直线,直线的公式我们也都牢记于心:
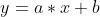
或者我们可以这样写:
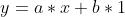
这样的话,在本次例子中,根据图像,x 即工作年数,y 即工资水平。
目标就是:找到一条直线 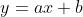 ,尽可能准确的根据工作年数,预测工资水平。
,尽可能准确的根据工作年数,预测工资水平。
分析
那么现在对这个公式进行分析,在此之前,我先提问一个问题:在上述的公式中,什么是已知的,什么是未知的?
计算这个线性回归模型的时候,是要针对已知样本的(输入,输出),通过计算得到目标直线,(输入,输出)即(工作年数,工资水平),目标直线的(斜率,截距)却不知道,要通过计算得到。所以,(x, y)是已知的,(a, b)是未知的。这个地方大家必须清楚。
现在我们弄明白了谁是已知,谁是未知,就该去确定怎么计算这两个未知数。
目标是找到一条尽可能准确的直线,尽可能准确就是对于所有的样本,误差要尽可能的小。
假设,对于给定的数据,最理想,最好的直线是 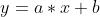 ,根据之前的思想:先初始化一条随机的直线,然后根据误差,慢慢修正参数,最终得到一条近似完美的参数作为最终参数。
,根据之前的思想:先初始化一条随机的直线,然后根据误差,慢慢修正参数,最终得到一条近似完美的参数作为最终参数。
随机一条初始的直线: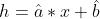 ,对于这个随机直线,输入一个工作年限,会得到一个不一样的工资水平h,这个工资水平h和真实的y是不一样的,有误差的.
,对于这个随机直线,输入一个工作年限,会得到一个不一样的工资水平h,这个工资水平h和真实的y是不一样的,有误差的.
那么, 单一的样本的误差就是: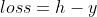 。
。
当计算所有的样本的误差的时候,我们可以把各个样本的误差加起来,但这时候,正负的loss就会抵消,所以要消除其中的负号,消除负号有两种方法:
1. 绝对值。
2. 平方。
但是为了求导方便,这里选择方法2,取平方,即:(假设共 n 个样本)
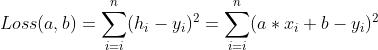
这个里面的 a 和 b 是 h 中的 a 和 b。
再回顾一下我们的目标:找到一条尽可能准确的直线。也就是说,总和误差要达到最小,也就是说Loss(a, b) 要达到最小值。
此时问题转化为了二元函数求极值的问题,也就是说:找到Loss(a, b)的最小值。根据二元函数求极值的方法,我们需要分别对 a 和 b 求偏导数(此时 x 和 y 视为常数),求导结果如下:
 ,
,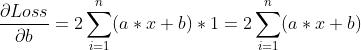
求导之后,此时有两种方法:
1.最小二乘法
最小二乘法在求导后,另上面两个偏导数为0,联立解得 a 和 b 的值,然后直接计算就得到了这条直线,就是解方程的过程,这里就带过了。
2. 梯度下降法(推理过程仅帮助大家理解,未找专业人士求证,如果想要了解最正确的推理过程可以去百度百科或者去找课本。)
有人可能会不知道梯度什么意思,我这里给一个最浅显的理解方式,可能不太符合定义,但是帮助理解:
一元函数,求导之后有斜率,二元及以上函数,求导之后有梯度,可以理解为:梯度就是高维的斜率。如同:平面内是垂直,高维就是正交。
这里先暂停一下,线回顾一下一元方程: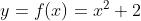 ,那么这个 y = f(x) 是一个凹函数(如无特殊说明,这个文章中的凹凸性,按照2021考研数学中的定义,2021年9月12日。),那么它会在某处存在一个最小值,假设在
,那么这个 y = f(x) 是一个凹函数(如无特殊说明,这个文章中的凹凸性,按照2021考研数学中的定义,2021年9月12日。),那么它会在某处存在一个最小值,假设在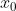 的地方取得最小值,则这个地方导数为0。即:
的地方取得最小值,则这个地方导数为0。即:
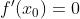 。但是我们不看这个,看这个就是最小二乘法了,我们现在说梯度下降法,要通过某种手段,使得我们最终通过一个可以迭代的步骤来推导出这个点。
。但是我们不看这个,看这个就是最小二乘法了,我们现在说梯度下降法,要通过某种手段,使得我们最终通过一个可以迭代的步骤来推导出这个点。
假设我们从 点出发,我们不知道这个点是否是最小值,但是我们可以求这个点处的斜率。这个点处的斜率特别容易求得:
点出发,我们不知道这个点是否是最小值,但是我们可以求这个点处的斜率。这个点处的斜率特别容易求得:

如果k=0,皆大欢喜,直接这个就是我们需要求到的最小点。
如果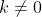 ,假设 k > 0,很容易知道,这个时候图像是朝上的:
,假设 k > 0,很容易知道,这个时候图像是朝上的:
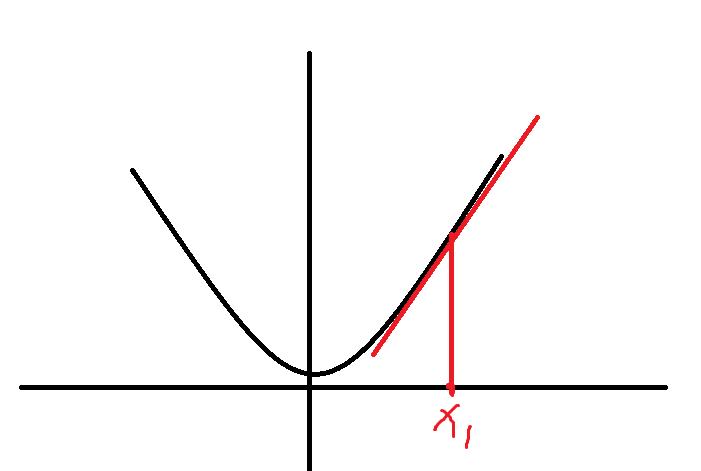
显然,这个时候在最小值右边,下一个点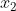 需要向左走一点点,但不能走太多。
需要向左走一点点,但不能走太多。
也就是说:
这个时候就看到了梯度下降法的雏形了。
进一步一般化这个式子,就能看到一个非常简单的公式:
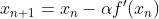
即,给定一个初始的x,经过一定次数的迭代之后,就能慢慢的逼近最终的一个极小值的结果。
上面是一元方程中的问题,那么现在来到二元方程,帮助你们回顾:
误差的损失函数: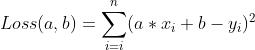
对于 a 的偏导数:
对于 b 的偏导数: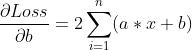
偏导数就是在某一个方向上的导数,对于每一个单独的 a 或者 b 都可以看作:Loss(a),Loss(b),那么可以接受一元方程中的扩展。
那么就得到了 a 和 b 的修正规则:
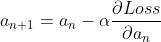 ,
,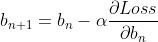
前面的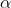 就可以认为是一个学习率。根据这两个公式,就能一步一步的求出目标的相对最优的直线参数了。
就可以认为是一个学习率。根据这两个公式,就能一步一步的求出目标的相对最优的直线参数了。
代码实现
代码实现很简单,注释都在代码里,我感觉注释应该写清楚了。能简化的步骤我都给予了简化,希望大家能理解,不懂得欢迎评论区留言。
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def main():
"""线性回归,梯度下降法"""
# 随机编写一组点,使用numpy的数组可以进行加减乘的运算
x = np.array([0.5, 0.7, 1.0, 1.5, 2.1, 2.3, 3.0, 3.3])
y = np.array([5.0, 5.6, 5.3, 6.0, 7.0, 6.8, 9.1, 10.5])
# 随机初始y = ax + b 的参数
a, b = 1, 1
times = 10000 # 迭代训练次数
learning_rate = 0.001
for i in range(times): # 开始训练
# 根据两个偏导数计算Loss/a的偏导数
dloss_da = 2 * ((a * x + b - y)*x).sum()
dloss_db = 2 * (a * x + b - y).sum()
# 根据修正规则,修正参数
a = a - learning_rate * dloss_da
b = b - learning_rate * dloss_db
# 得到最终的直线上x对应的点
final_y = a * x + b
# 画散点
plt.scatter(x, y, label="test data point")
plt.plot(x, final_y, label='final regression line') # 训练完的回归线
plt.legend() # 将label贴到图片上
plt.show() # 展示这个图片
if __name__ == "__main__":
main()
最终的效果如图所示:

注意
在使用梯度下降法的时候要注意的大小,如果太大了,一步从当前值迈过了最小值,去到了另一边,如下:
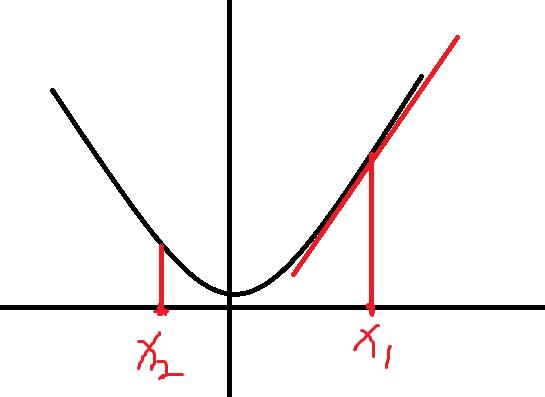
这个时候可以考虑降低的大小,我在实战中,最大的的值用过0.5,再大没试过,不知道行不行,最小我用过 ,也就是一百万分之一,大家实战时根据实际情况调整,如果不知道的话,可以从小的开始,慢慢增大。
,也就是一百万分之一,大家实战时根据实际情况调整,如果不知道的话,可以从小的开始,慢慢增大。
结束语
这期距离上期时间间隔确实挺长,但是不会断更,因为我希望我能用最简洁的方式给大家说明白,如果我的解释哪些地方可能是错的,我会标注出,留给大家深入理解了并且数学知识足够了,再去自己探索(比如梯度下降算法的推导过程,实际情况肯定不是这样,但是这样我觉得是最容易理解的方式,需要的知识也仅仅是求导的知识而已)。
希望大家能学习到知识,这期就到这里,下期再见!欢迎评论区留言交流。
以上是关于Python神经网络学习--机器学习--线性回归的主要内容,如果未能解决你的问题,请参考以下文章
机器学习------- 线性回归(Linear regression )