如何入门 Python 爬虫
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何入门 Python 爬虫相关的知识,希望对你有一定的参考价值。
爬虫我也是接触了1个月,从python小白到现在破译各种反爬虫机制,我给你说说我的方向:
1、学习使用解析网页的函数,例如:
import urllib.request
if __name__ == '__main__':
url = "..."
data = urllib.request.urlopen(url).read() #urllib.request.urlopen(需要解析的网址)
data = data.decode('unicode_escape','ignore') #用unicode_escape方式解码
print(data)
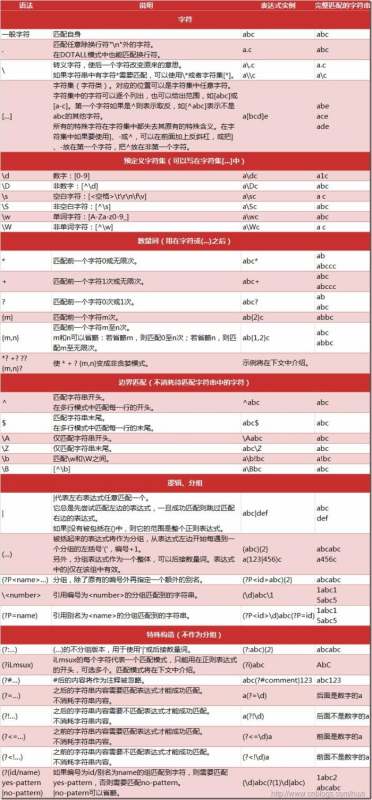
2、学习正则表达式:
正则表达式的符号意义在下面,而正则表达式是为了筛选出上面data中的信息出来,例如:
def get_all(data):
reg = r'(search.+)(" )(mars_sead=".+title=")(.+)(" data-id=")'
all = re.compile(reg);
alllist = re.findall(all, data)
return alllist
3、将得到的结果压进数组:
if __name__ == '__main__':
info = []
info.append(get_all(data))
4、将数组写进excel:
import xlsxwriter
if __name__ == '__main__':
info = []
info.append(get_all(data))
workbook = xlsxwriter.Workbook('C:\\\\Users\\\\Administrator\\\\Desktop\\\\什么文件名.xlsx') # 创建一个Excel文件
worksheet = workbook.add_worksheet() # 创建一个工作表对象
for i in range(0,len(info)):
worksheet.write(行, 列, info[i], font)#逐行逐列写入info[i]
workbook.close()#关闭excel
一个简单的爬虫搞定,爬虫的进阶不教了,你还没接触过更加看不懂
参考技术A先长话短说summarize一下:
你需要学习
基本的爬虫工作原理
基本的http抓取工具,scrapy
Bloom Filter: Bloom Filters by Example
如果需要大规模网页抓取,你需要学习分布式爬虫的概念。其实没那么玄乎,你只要学会怎样维护一个所有集群机器能够有效分享的分布式队列就好。最简单的实现是python-rq: https://github.com/nvie/rq
rq和Scrapy的结合:darkrho/scrapy-redis · GitHub
后续处理,网页析取(grangier/python-goose · GitHub),存储(Mongodb)
小白如何入门 Python 爬虫?
本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫!
想要入门Python 爬虫首先需要解决四个问题
- 熟悉python编程
- 了解HTML
- 了解网络爬虫的基本原理
- 学习使用python爬虫库
一、你应该知道什么是爬虫?
网络爬虫,其实叫作网络数据采集更容易理解。
就是通过编程向网络服务器请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。
归纳为四大步:
- 根据url获取HTML数据
- 解析HTML,获取目标信息
- 存储数据
- 重复第一步
这会涉及到数据库、网络服务器、HTTP协议、HTML、数据科学、网络安全、图像处理等非常多的内容。但对于初学者而言,并不需要掌握这么多。
二、python要学习到什么程度
如果你不懂python,那么需要先学习python这门非常easy的语言(相对其它语言而言)。
编程语言基础语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理这些,学起来会显枯燥但并不难。
刚开始入门爬虫,你甚至不需要去学习python的类、多线程、模块之类的略难内容。找一个面向初学者的教材或者网络教程,花个十几天功夫,就能对python基础有个三四分的认识了,这时候你可以玩玩爬虫喽!
当然,前提是你必须在这十几天里认真敲代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等最核心的东西都得捻熟于心、于手。
教材方面比较多选择,我个人是比较推荐python官方文档以及python简明教程,前者比较系统丰富、后者会更简练。
三、为什么要懂HTML
前面说到过爬虫要爬取的数据藏在网页里面的HTML里面的数据,有点绕哈!
维基百科是这样解释HTML的:
超文本标记语言(英语:HyperTextMarkupLanguage,简称:HTML)是一种用于创建网页的标准标记语言。
HTML是一种基础技术,常与CSS、JavaScript一起被众多网站用于设计网页、网页应用程序以及移动应用程序的用户界面[3]。网页浏览器可以读取HTML文件,并将其渲染成可视化网页。
HTML描述了一个网站的结构语义随着线索的呈现,使之成为一种标记语言而非编程语言。
总结一下,HTML是一种用于创建网页的标记语言,里面嵌入了文本、图像等数据,可以被浏览器读取,并渲染成我们看到的网页样子。
所以我们才会从先爬取HTML,再 解析数据,因为数据藏在HTML里。
学习HTML并不难,它并不是编程语言,你只需要熟悉它的标记规则,这里大致讲一下。
HTML标记包含标签(及其属性)、基于字符的数据类型、字符引用和实体引用等几个关键部分。
HTML标签是最常见的,通常成对出现,比如<h1>与</h1>。
这些成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间为元素的内容(文本、图像等),有些标签没有内容,为空元素,如<img>。
以下是一个经典的Hello World程序的例子:
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<p>Hello world!</p>
</body>
</html>
HTML文档由嵌套的HTML元素构成。它们用HTML标签表示,包含于尖括号中,如<p>
在一般情况下,一个元素由一对标签表示:“开始标签”<p>与“结束标签”</p>。元素如果含有文本内容,就被放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
- 发送GET请求,获取HTML
- 解析HTML,获取数据
这两件事,python都有相应的库帮你去做,你只需要知道如何去用它们就可以了。
首先,发送HTML数据请求可以使用python内置库urllib,该库有一个urlopen函数,可以根据url获取HTML文件,这里尝试获取百度首页“https://www.baidu.com/”的HTML内容
# 导入urllib库的urlopen函数 from urllib.request import urlopen # 发出请求,获取html html = urlopen("https://www.baidu.com/") # 获取的html内容是字节,将其转化为字符串 html_text = bytes.decode(html.read()) # 打印html内容 print(html_text)
看看效果:
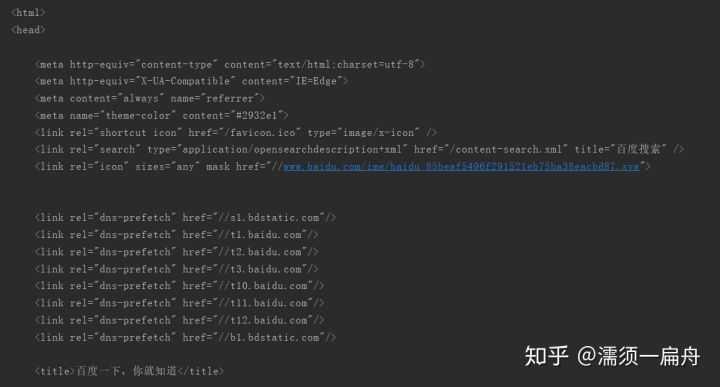
我们看一下真正百度首页html是什么样的
如果你用的是谷歌浏览器,在百度主页打开设置>更多工具>开发者工具,点击element,就可以看到了:
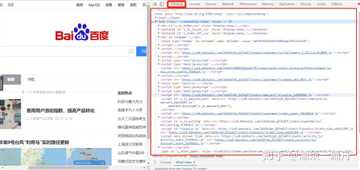
对比一下你就会知道,刚才通过python程序获取到的HTML和网页中的一样!
获取了HTML之后,接下就要解析HTML了,因为你想要的文本、图片、视频都藏在HTML里,你需要通过某种手段提取需要的数据。
python同样提供了非常多且强大的库来帮助你解析HTML,这里以著名的python库BeautifulSoup为工具来解析上面已经获取的HTML。
BeautifulSoup是第三方库,需要安装使用。在命令行用pip安装就可以了:
pip install bs4
BeautifulSoup会将HTML内容转换成结构化内容,你只要从结构化标签里面提取数据就OK了:

比如,我想获取百度首页的标题“百度一下,我就知道”,怎么办呢?
这个标题是被两个标签套住的,一个是一级标签<head><head>,另一个是二级标签<title><title>,所以只要从标签中取出信息就可以了
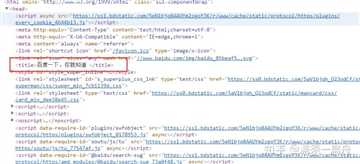
# 导入urlopen函数 from urllib.request import urlopen # 导入BeautifulSoup from bs4 import BeautifulSoup as bf # 请求获取HTML html = urlopen("https://www.baidu.com/") # 用BeautifulSoup解析html obj = bf(html.read(),‘html.parser‘) # 从标签head、title里提取标题 title = obj.head.title # 打印标题 print(title)
看看结果:
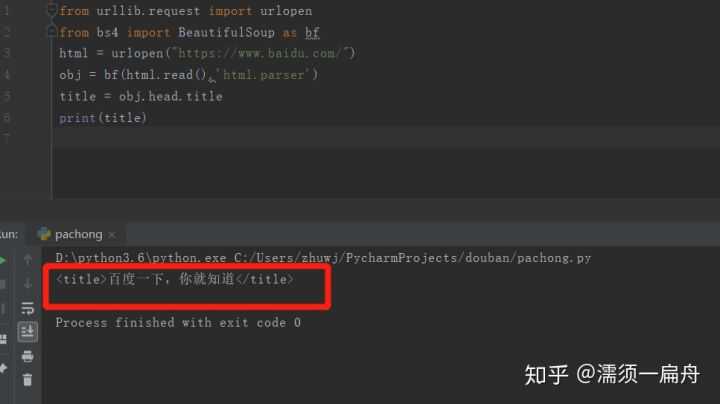
这样就搞定了,成功提取出百度首页的标题。
如果我想要下载百度首页logo图片呢?
第一步先获取该网页所有图片标签和url,这个可以使用BeautifulSoup的findAll方法,它可以提取包含在标签里的信息。
一般来说,HTML里所有图片信息会在“img”标签里,所以我们通过findAll("img")就可以获取到所有图片的信息了。
# 导入urlopen from urllib.request import urlopen # 导入BeautifulSoup from bs4 import BeautifulSoup as bf # 请求获取HTML html = urlopen("https://www.baidu.com/") # 用BeautifulSoup解析html obj = bf(html.read(),‘html.parser‘) # 从标签head、title里提取标题 title = obj.head.title # 使用find_all函数获取所有图片的信息 pic_info = obj.find_all(‘img‘) # 分别打印每个图片的信息 for i in pic_info: print(i)
看看结果:
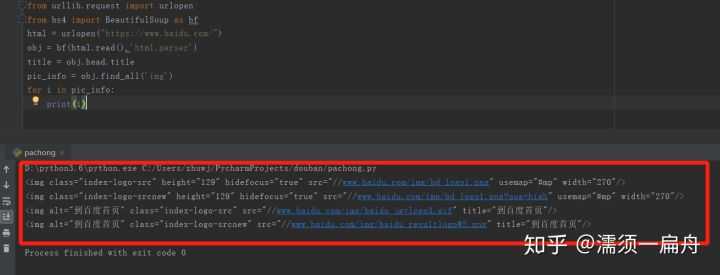
打印出了所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有百度首页logo的图片,该图片的class(元素类名)是index-logo-src。

[<img class="index-logo-src" height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" usemap="#mp" width="270"/>, <img alt="到百度首页" class="index-logo-src" src="//www.baidu.com/img/baidu_jgylogo3.gif" title="到百度首页"/>]
可以看到图片的链接地址在src这个属性里,我们要获取图片链接地址:
# 导入urlopen from urllib.request import urlopen # 导入BeautifulSoup from bs4 import BeautifulSoup as bf # 请求获取HTML html = urlopen("https://www.baidu.com/") # 用BeautifulSoup解析html obj = bf(html.read(),‘html.parser‘) # 从标签head、title里提取标题 title = obj.head.title # 只提取logo图片的信息 logo_pic_info = obj.find_all(‘img‘,class_="index-logo-src") # 提取logo图片的链接 logo_url = "https:"+logo_pic_info[0][‘src‘] # 打印链接 print(logo_url)
结果:
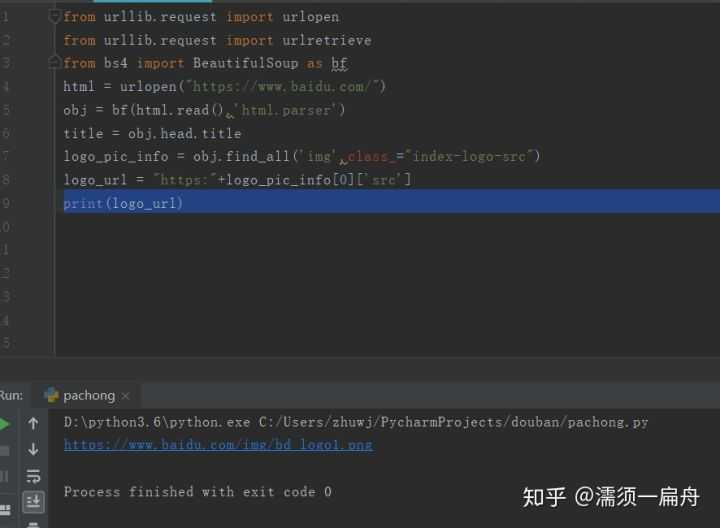
获取地址后,就可以用urllib.urlretrieve函数下载logo图片了
# 导入urlopen from urllib.request import urlopen # 导入BeautifulSoup from bs4 import BeautifulSoup as bf # 导入urlretrieve函数,用于下载图片 from urllib.request import urlretrieve # 请求获取HTML html = urlopen("https://www.baidu.com/") # 用BeautifulSoup解析html obj = bf(html.read(),‘html.parser‘) # 从标签head、title里提取标题 title = obj.head.title # 只提取logo图片的信息 logo_pic_info = obj.find_all(‘img‘,class_="index-logo-src") # 提取logo图片的链接 logo_url = "https:"+logo_pic_info[0][‘src‘] # 使用urlretrieve下载图片 urlretrieve(logo_url, ‘logo.png‘)
最终图片保存在‘logo.png‘

六、结语
本文用爬取百度首页标题和logo图片的案例,讲解了python爬虫的基本原理以及相关python库的使用,这是比较初级的爬虫知识,还有很多优秀的python爬虫库和框架等待后续去学习。
当然,掌握本文讲的知识点,你就已经入门python爬虫了。加油吧,少年!
以上是关于如何入门 Python 爬虫的主要内容,如果未能解决你的问题,请参考以下文章