TensorFlow入门1-CNN网络及MNIST例子讲解
Posted 轩辕223
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow入门1-CNN网络及MNIST例子讲解相关的知识,希望对你有一定的参考价值。
1. 前言
人工智能自从阿尔法狗大败李世石后就异常火爆,最近工作中需要探索 AI 在移动端的应用,趁着这个计划入门下深度学习吧。
深度学习的入门曲线还是很陡峭的,看了很多资料,询问了从事相关工作的朋友后终于有点感觉了,这篇文章就讲一下我在这个过程中的所见所得吧,肯定是不专业的,如果所说有什么错误,也希望大家帮忙指出,共同进步。
这个入门的文章准备分以下几个部分来说:
- CNN 的原理
- TensorFlow 使用 CNN 网络解决 MNIST 问题的例子讲解
- Demo 改造解决我自己的股票图片识别问题
- 训练出的模型部署到 ios 端的 TensorFlow Mobile 框架中
- 训练出的模型部署到 iOS 端的 TensorFlow Lite 框架中
首先我做的第一件事是分清楚一些概念,之前完全不懂得时候只觉得人工智能很厉害,能解决人力解决不了的问题,但人工智能到底是什么,完全不知道。既然要学习,首先就得分清楚人工智能,机器学习,深度学习都是些什么东西,需要从哪里入手等等这些问题。这个问了从事相关工作的同学后再查阅了一些资料后,很容易的就理解了。知乎上的这个回答比较靠谱,传送门,总结一下就是这两句话。
机器学习:一种实现人工智能的方法
深度学习:一种实现机器学习的技术
而三者的关系就是

可以看的出来,人工智能是一个很大的概念,想用机器来解决问题的一种思想都可以认为是人工智能,而这个概念早在 19 世纪 50 年代就提出了。机器学习就是实现人工智能的一种方法,一切使用数据分析帮助决策的场景都可以叫做机器学习,这个概念从 19 世纪 80 年代到现在也已经发展了快 40 年了,机器学习其实一点都不神秘,在现代生产中的应用随处可见,比如各种网站的推荐算法,垃圾邮件的过滤算法等等。而最近火热的概念其实人工智能中很小的一部分,叫做深度学习。简单来说,使用深度神经网络去解决问题的学习方法叫做深度学习。如果说广义的机器学习是人类定义好规则,让计算机去做,那么深度学习就是人类定义好规则后,让计算机去学。深度学习依赖于现在计算能力的提升飞速发展,在图像识别、语音识别等领域发挥了巨大的作用。看完这篇文章后,你应该对深度学习会有一个简单的理解。
考虑到机器学习的算法实在是太多,学习需要很多时间(按照我粗浅的理解,机器学习就是一整部统计学在计算机界的应用,很大)。而深度学习就相对单纯一些,据我所知,目前比较流行的深度学习算法就只有 CNN(卷积神经网络),RNN(循环神经网络)和 DNN(深度神经网络)。DNN 是整个深度学习的基础,后面的 CNN 和 RNN 其实都是基于DNN来做的,CNN(卷积神经网络)比较擅长于提取图片特征,处理图像问题。RNN 是把前一次网络的输出作为下一次网络的输入,让整个网络有了前因后果的概念,比较擅长处理有前后时间序列关系的问题,比如语音识别,语义分析等。
根据之前列的大纲,这篇文章会先讲一下 CNN 网络的概念,然后讲一下 TensorFlow 中一个很有用的例子,用 CNN 网络去解决 MNIST 问题。大纲中剩下的部分会在接下来的文章中讲解。
2. CNN神经网络
CNN 神经网络,全称是卷积神经网络,是目前深度学习中最常见、应用最广泛的一种网络,适合于解决图像识别,图片分类,图像预测的问题。
这里有一篇讲 CNN 比较好的文章,我看到很多大V讲到 CNN 的时候也会引用这篇文章的内容。有兴趣可以先看一下这篇文章。
An Intuitive Explanation of Convolutional Neural Networks
如果不考虑 CNN,可以先思考下一个自己去实现一个分类图片的程序会怎么做。我之前做了一个判断一张图片是否是自选股截图的程序,自选股截图指的是下面这种图片。
首先我会去看这种图片有什么特征,很明显,自选股截图上面有规则的红绿方块,而其他图片是没有的。那么在程序中,我首先提取出图片的各个像素值,然后去查找这张图片中是否有这种红绿色块,查找红绿色块的算法,可以这样做,看红色的像素值的坐标是否是一个方块,或者绿色的像素值的坐标是否是一个方块。
由上所知,一个典型的图片分类算法就是提取特征,比较特征。CNN 网络简单来说就是将这个过程自动化,开发人员不需要告诉网络图片的特征是什么,CNN 网络可以自动的从图片中寻找特征,并记录。这个过程是怎么做到的呢,下面来讲。
输入一张图片,网络通过一系列的运算,提取出图片的特征。如下图所示:

当然,这中间的一系列计算是有算法和参数的。训练的时候我们会给每张图片打上一个对应的标签,CNN 通过上面一系列计算出特征后,每个特征就对应着一个标签。比如
特征1 -> 标签A
特征2 -> 标签B
特征3 -> 标签A 当下一张图进入训练时,CNN 网络仍然以上次训练计算出来的参数去提取特征,假如提取出的是特征 2,如果图片的标签是 B,那么证明参数正确,无需调整。如果提取出的是特征 2,但是图片的标签是 A,那么证明参数不准确,需要调整下参数。调整完参数后继续下次训练,以此类推,直到参数大概率准确的时候。
很简单的去解释了 CNN 卷积神经网络是怎么工作的,当然实际的过程比这要复杂的多,提取特征需要一些算法,比如卷积、池化、激活,算法的参数也不是 1 个这么简单,而是几百万个。下面的文章中基于 TensorFlow 中一个很简单的例子 MNIST 问题的代码来讲一下 CNN 网络是怎样工作的。
3. MNIST问题
MNIST 问题就相当于图像处理的 Hello World 程序,在 TensorFlow 的官方教程里已经有一个完整的 Demo。
MNIST 问题是很常见的图片分类问题,训练集是已经编码过的手写图片,图片中是手写的 0~9 的数字,模型经过训练后,输入一张图片,可以输出 0~9 的数字。
3.1 输入集
首先我们来看一下 MNIST 问题的输入集,数据集的介绍传送门。
整个数据集由以下四个文件构成,
//训练集-图片数据
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
//训练集-label数据
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
//测试集-图片数据
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
//测试集-label数据
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)训练集-图片数据的格式如下
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel训练集-label 数据的格式如下
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.测试集的数据格式和训练集是一样的。
首先我们写个程序试着解析一下这些数据:
#coding=utf-8
import os
import struct
import numpy as np
import matplotlib.pyplot as plt
def load_mnist(path, kind='train'):
# 读取文件
labels_path = os.path.join(path,
'%s-labels-idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images-idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
# 读取magic numer,labels数量
magic, n = struct.unpack('>II',
lbpath.read(8))
print 'label magic : ',
print magic
# 载入label数据
labels = np.fromfile(lbpath,
dtype=np.uint8).reshape(n, 1)
with open(images_path, 'rb') as imgpath:
# 读取magic numer,图片数量,图片宽,高
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
print 'image magic : ',
print magic
# 载入图片数据
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(num, rows * cols)
return images, labels, rows, cols
def show_image():
images, labels, rows, cols = load_mnist('/tmp/TensorFlow/mnist/input_data/')
fig, ax = plt.subplots(
nrows=2,
ncols=5,
sharex=True,
sharey=True, )
ax = ax.flatten()
for i in range(10):
img = images[i].reshape(rows, cols)
print labels[i]
ax[i].imshow(img, cmap='Greys', interpolation='nearest')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
if __name__ == '__main__':
show_image()
运行程序后,会显示输入集的前 10 张图片,如下图所示:

在控制台会输出 labels
label magic : 2049
image magic : 2051
[5] [0] [4] [1] [9] [2] [1] [3] [1] [4]这是一个 CNN 模型需要的典型的输入,有一些数据,每个数据都有一个 label。后面我们做自己项目的时候,也是这种数据格式。
因为 MNIST 问题是个比较典型的问题,所以 TensorFlow 甚至封装了解析的方法。
3.2 MNIST问题代码解析
完整的代码在 TensorFlow 的 /TensorFlow/git/TensorFlow/TensorFlow/examples/tutorials/mnist/mnist_deep.py 里面。
我们根据程序的运行顺序来看一下。
3.2.1 读取数据
if __name__ == '__main__':
# 解析命令行参数,默认没有
parser = argparse.ArgumentParser()
# 添加MNIST数据集的下载地址
parser.add_argument('--data_dir', type=str,
default='/tmp/TensorFlow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
# 运行main方法
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) # Import data
mnist = input_data.read_data_sets(FLAGS.data_dir)代码将 MNIST 的下载和解析过程封装了一次,看下 read_data_sets 方法
def read_data_sets(train_dir,
fake_data=False,
one_hot=False,
dtype=dtypes.float32,
reshape=True,
validation_size=5000,
seed=None,
source_url=DEFAULT_SOURCE_URL):
...
return base.Datasets(train=train, validation=validation, test=test)这个方法最后返回的是一个 Datasets 格式,里面 train,validation 和 test 都是已经解析好的数据,解析方法就类似于上一节讲到的。
读到这里,你可能有个疑问,MNIST 数据里面只有 train 和 test,那验证数据集 validation 是哪里来的。这里 validation 使用的就是 train 数据集。CNN 网络在每次训练完之后运行 validation 数据集,可以让开发者了解目前的准确度,在所有训练结束之后运行 test 数据集,可以知道训练出的这个模型的准确度。所以运行 validation 数据只是给开发者参考用的,这里对数据的要求不是很严苛,可以直接用 train 的数据集,而最后测试模型的准确度时使用的 test 数据集一定不能是 train 里面的数据,因为如果两个数据集有重合,可能无法准确的测试模型的准确度。
3.2.2 定义输入输出
# Create the model
x = tf.placeholder(tf.float32, [None, 784], name="x")
# Define loss and optimizer
y_ = tf.placeholder(tf.int64, [None])
tf.placeholder 可以理解为定义占位符,这些占位符虽然定义的时候没有值,但在实际运行中会给定输入值。这里定义了两个占位符,一个是输入值 x,类型是浮点数,维度是 [None, 784],None 代表不确定数量,784 代表 28*28,也就是一张 MNIST 输入集的图片,这里的意思是说输入层x可以是不确定数量的图片,代表着我们这个网络可以同时输入多张图片的数据。这种变量就是 TensorFlow 的张量 tensor,而每个 tensor 都可以指定名称,但是我们一般只指定具有代表性的几个 tensor 的名称,比如这个输入节点的名称是 x。
而 y_ 声明的存储 label 的变量,类型是 int 类型,因为 label 是 1-10,也是不确定数量的,因为前面x输入多少图片,这里的 label 就应该有多少数量。
声明一个变量为什么要如此复杂,为什么不能像我们写程序一样直接声明 float x = 5 这样。这里需要给读者讲解一下 TensorFlow 计算图和静态图的概念。训练一个深度学习网络的时候,是需要大量计算的,而深度学习框架为了加快计算速度,会直接把计算的过程扔给 CPU 或 GPU 去运行,CPU 和 GPU 运行结束后返回框架结果。举个简单的例子,如果我们要计算 3*5+2,普通的程序是先计算 3*5,得到结果之后再 +2,得到结果。如果 TensorFlow 也这样做的话,相当于让 CPU 算 3*5, CPU 算完后返回结果,然后把返回的结果和 2 再扔给 CPU 去算,最后得到结果。但是需要知道的是,每一次和CPU的交互其实都是特别浪费时间的,所以如果像普通的程序一样,那训练神经网络会特别耗时。所以有一些深度学习框架像 TensorFlow 提出了静态图的概念,首先定义好整个计算图,放在前面的例子里,就是定义好“先乘后加”,然后将需要计算的数字和这个计算图扔给 CPU,最后 CPU 会计算出一个最终的结果返回给框架,这样整个过程中框架和CPU只有一次交互。这样做可以提升计算的速度,但是有一个致命的缺点是不能调试,你不能在 3*5 之后打个断点看看结果对不对,你只能知道最后的结果是不是正确。
所以 tf.placeholder 只是定义了整个计算图中的一个节点 tensor,所以必须用TensorFlow 定义 tensor 的语法。
3.2.3 定义计算图
# Build the graph for the deep net
y_conv = deepnn(x)deepnn 这个方法是整个程序的核心,在这个方法中定义了一整个计算图。我们一层一层的看。这个 CNN 的网络用的是LeNet网络。构成是这样的。

其中有两层卷积层,两层池化层,最后输出层是两层全连接层。代码如下:
def deepnn(x):
"""deepnn builds the graph for a deep net for classifying digits.
Args:
x: an input tensor with the dimensions (N_examples, 784), where 784 is the
number of pixels in a standard MNIST image.
Returns:
A tuple (y, keep_prob). y is a tensor of shape (N_examples, 10), with values
equal to the logits of classifying the digit into one of 10 classes (the
digits 0-9). keep_prob is a scalar placeholder for the probability of
dropout.
"""
# Reshape to use within a convolutional neural net.
# Last dimension is for "features" - there is only one here, since images are
# grayscale -- it would be 3 for an RGB image, 4 for RGBA, etc.
with tf.name_scope('reshape'):
x_image = tf.reshape(x, [-1, 28, 28, 1])
# First convolutional layer - maps one grayscale image to 32 feature maps.
with tf.name_scope('conv1'):
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# Pooling layer - downsamples by 2X.
with tf.name_scope('pool1'):
h_pool1 = max_pool_2x2(h_conv1)
# Second convolutional layer -- maps 32 feature maps to 64.
with tf.name_scope('conv2'):
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# Second pooling layer.
with tf.name_scope('pool2'):
h_pool2 = max_pool_2x2(h_conv2)
# Fully connected layer 1 -- after 2 round of downsampling, our 28x28 image
# is down to 7x7x64 feature maps -- maps this to 1024 features.
with tf.name_scope('fc1'):
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Map the 1024 features to 10 classes, one for each digit
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.add(tf.matmul(h_fc1, W_fc2), b_fc2, name="output")
return y_conv下面一层一层的看这个网络是怎么工作的。
卷积层
CNN 叫卷积神经网络,可以看出卷积是这个网络的核心。卷积层是用于提取图片特征,卷积的操作是用一个卷积矩阵(也叫卷积核)在输入矩阵上依次扫描,做矩阵相乘,得到的结果输入矩阵的某一个特征。这样讲是不太好理解,下面用图片说一下这个过程。
假设输入矩阵是这样的

选取如下一个卷积核

用卷积核在输入矩阵上依次扫过,做矩阵相乘的操作,就可以得到输入矩阵由这个卷积核提取的特征。
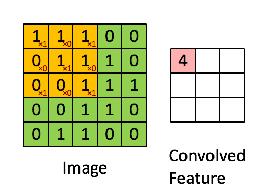
在 CNN 的术语中,3x3 的矩阵叫做“滤波器(filter)”或者“核(kernel)”或者“特征检测器(feature detector)”,通过在图像上滑动滤波器并计算点乘得到矩阵叫做“卷积特征(Convolved Feature)”或者“激活图(Activation Map)”或者“特征图(Feature Map)”。记住滤波器在原始输入图像上的作用是特征检测器。
是不是在怀疑,这种操作真的能够提取特征吗,看下对实际图片进行卷积操作的例子。
输入图像如下:

用不同的卷积核进行卷积操作的结果如下:

可以看到,不同的卷积核对原图像进行处理后可以得到不同的特征图像,有的卷积核能提取边缘信息,有的卷积核能提取色彩信息,有的卷积核能提取明暗特征,等等等等。有没有觉得这一步特别像 PS 中的滤镜,其实卷积的操作和滤镜的操作是很类似的。不同的卷积就像不同的滤镜对不同的特征敏感度不同。而代码中的卷积层如下:
# First convolutional layer - maps one grayscale image to 32 feature maps.
with tf.name_scope('conv1'):
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)首先定义一个卷积核 W_conv1 变量,由于后面会多次定义变量,所以将定义变量的部分提取了方法,如下:
def weight_variable(shape):
"""weight_variable generates a weight variable of a given shape."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)tf.Variable 生成一个变量 tensor,参数 initial 是初始化值。initial 由truncated_normal 方法生成,shape 指定了生成变量的维度,这里是[5,5,1,32]四维的变量,初始化值是由 truncated_normal 产生的正态分布的值,这就是 truncated_normal 方法的作用,详细的说明可以看文档。
相对于卷积核的声明,偏量 b_conv1 的生成要简单一点。
def bias_variable(shape):
"""bias_variable generates a bias variable of a given shape."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)初始化值是固定的 0.1。
这两个变量的初始化值不能是 0,而要加入一些脏值,是为了打破对称性以及避免 0 梯度,提升模型训练的效率。
后面的代码就是执行卷积操作,我们来看,
conv2d(x_image, W_conv1)
def conv2d(x, W):
"""conv2d returns a 2d convolution layer with full stride."""
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')这个函数就是 TensorFlow 中用于做卷积的函数,2d 代表生成的是一个二维特征图,这个是什么意思呢,后面会提到。除了 conv2d,还有 conv1d 和 conv3d 函数。
看下 conv2d 的函数签名。
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)除去 name 参数用以指定该操作的 name,与方法有关的一共五个参数:
第一个参数 input:指需要做卷积的输入图像,它要求是一个 tensor,具有 [batch, in_height, in_width, in_channels] 这样的 shape,具体含义是[训练时一个 batch 的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个 4 维的 tensor,要求类型为 float32 和 float64 其中之一
第二个参数 filter:相当于 CNN 中的卷积核,它要求是一个 tensor,具有 [filter_height, filter_width, in_channels, out_channels] 这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数 input 相同,有一个地方需要注意,第三维 in_channels,就是参数 input 的第四维
第三个参数 strides:卷积时在图像每一维每一次移动的步长,这是一个一维的向量,长度跟前面卷积核的维度相同,这里是4。
第四个参数 padding:string 类型的量,只能是 “SAME”, “VALID” 其中之一,这个值决定了不同的卷积方式
第五个参数:use_cudnn_on_gpu: bool 类型,是否使用 cudnn 加速,默认为 true,cudnn 是英伟达的GPU处理单元,这里也就是用 GPU 进行加速计算。
二维特征向量
conv2d 生成的是二维特征向量,conv2d 有两个参数是必要的,input 和 filter。我们的输入参数是一张图片,三维的数据[宽,高,颜色空间],为了最后向量相乘的结果是二维的,filer 的第三个维度应该和 input 的第四个维度相等,也就是 in_channels 相等,这样永远都只能输出一个二维的特征向量,也就是这个函数叫 conv2d 的原因,这里比较难理解,可以仔细考虑一下。
padding参数
padding 参数的可选值是 SAME 和 VALID,这个参数影响了了卷积核对输入矩阵边缘的处理,决定了输出的特征向量大小。
卷积核和按照步数一步步的扫描输入矩阵,做乘法操作。但是在输入矩阵的边缘,如果输入矩阵剩余的维度小于定义的卷积核的维度,那么卷积核就无法做乘法操作了,剩余这部分边界怎么处理呢。
如果 padding 是 SAME,则会在输入矩阵的两端补齐 0,使补齐后的输入矩阵维度刚好可以被卷积核处理,最后得到的特征矩阵和原来的输入矩阵维度相同。
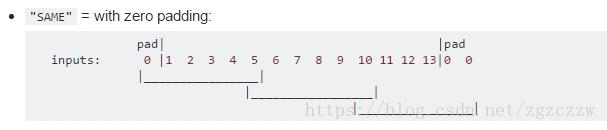
如果 padding 是 VALID,则会抛弃边界的节点,最后输出的特征矩阵维度和输入矩阵不相同

再回来看代码
W_conv1 = weight_variable([5, 5, 3, 32])
conv2d(x_image, W_conv1)卷积核是 5*5*3 的,一共 32 个卷积核,对图像处理后,可以得到32个特征向量,因为我们没有指定步长和 padding,所以步长默认是1,padding 是 SAME,这样的话,输出的特征矩阵就是28 * 28 * 1。
# 第一个卷积层,从图像中提取32的特征
with tf.name_scope('conv1'):
W_conv1 = weight_variable([5, 5, 3, 32]) # y =wX+b
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)做完了卷积后,进行了一个relu处理
ReLU 是一个元素级别的操作(应用到各个像素),并将特征图中的所有小于 0 的像素值设置为零。ReLU 的目的是在 ConvNet 中引入非线性,因为在大部分的我们希望 ConvNet 学习的实际数据是非线性的(卷积是一个线性操作——元素级别的矩阵相乘和相加,所以我们需要通过使用非线性函数 ReLU 来引入非线性。
引入非线性可以让神经网络更好的工作,这个更好的工作指的是在做反向传播的时候避免出现梯度消失的问题,原因涉及到比较深的理论,这篇文章就不多说了。
这样第一个卷积操作就结束了。
池化
卷积操作之后是一个池化层。
# Pooling layer - downsamples by 2X.
with tf.name_scope('pool1'):
h_pool1 = max_pool_2x2(h_conv1)池化的作用类似于压缩,这种压缩是在缩小输入值的维度的同时还要保持输入值的特征。比如在 2*2 的 4 个像素点中取最大值,最小值或者平均值。不过经过研究,最大池化能够比较好的保持原来的特征值。
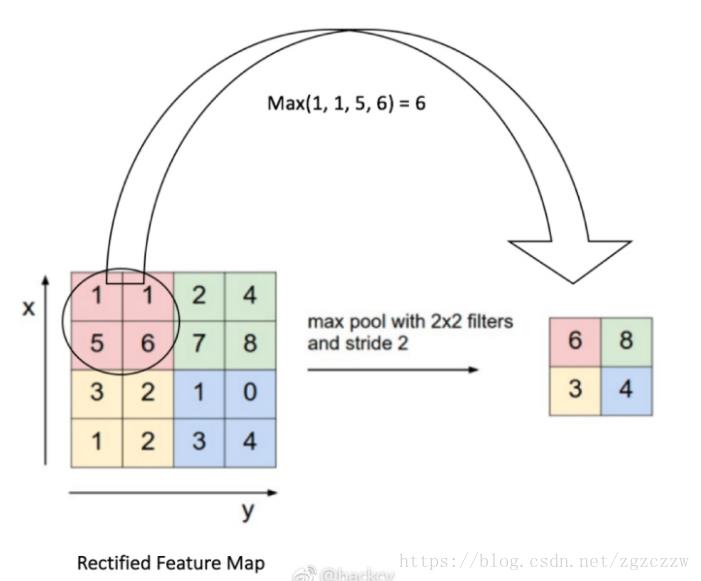
# 2*2的最大化池化层
with tf.name_scope('pool1'):
h_pool1 = max_pool_2x2(h_conv1)def max_pool_2x2(x):
"""max_pool_2x2 downsamples a feature map by 2X."""
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')池化操作也是调用的 TensorFlow 的函数,参数 strides 和 padding 跟前面提到的 conv2d 函数的参数一致。ksize 是定义的在每个维度上池化的大小,上一步卷积之后,输出的特征向量是 1*28*28*1,所以在中间两个维度进行处理。
# Second convolutional layer -- maps 32 feature maps to 64.
with tf.name_scope('conv2'):
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# Second pooling layer.
with tf.name_scope('pool2'):
h_pool2 = max_pool_2x2(h_conv2)后面又做了一个卷积操作和一个池化操作,这个跟前面的操作是一样的。卷积操作的输出不影响输入值的维度,但是影响输入值的深度。池化操作不影响输入值的深度但是影响输入值的维度,经过两层的卷积和 2*2 的池化后,输入值的维度变成了原来的 1/4。深度变成 64。也就是 7*7*64。
上面的几层又叫隐藏层,表示使用者看不到的处理层。
全连接
接下来是输出层,输出层是两个全连接层。
# Fully connected layer 1 -- after 2 round of downsampling, our 28x28 image
# is down to 7x7x64 feature maps -- maps this to 1024 features.
with tf.name_scope('fc1'):
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Map the 1024 features to 10 classes, one for each digit
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.add(tf.matmul(h_fc1, W_fc2), b_fc2, name="output")全连接层,顾名思义,指的是这一层的每个节点都跟上一层的全部节点有连接。

比如图中全连接层的节点 a1 与上一层的所有节点 x1,x2,x3 有联系,a2 也与上一层的所有节点有联系,就这样,少一个也不行。因此解释全连接层的时候,图就是这样一个网状结构。
上文中提到了联系,这里的“联系”具体指的是什么呢。如图所示,假设 x1,x2,x3 是全连接层的输入值,那么在全连接层的a1可以表示为以下的形式。
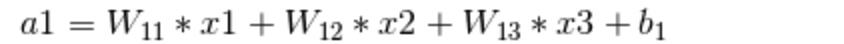
从这个公式可以看出,a1 与 x1,x2,x3 都有联系,只是输入节点的权重值不同。同理,a2 和 a3 也可以表示为以下的形式。
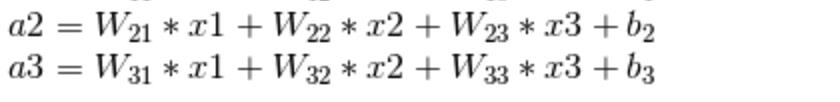
由此就可以从数学层面去理解什么叫全连接层,但是这个全连接层在实际应用中表示得意义是什么呢,简单来说,它可以作为一个分类网络,还是上面那个图,输入层是 3 个值,全连接层是 3 个节点,就代表这个全连接层可以把上一层的特征值分类为三种特征。当然,输入层和全连接层的节点数并不一定相同,比如下面这个结构。
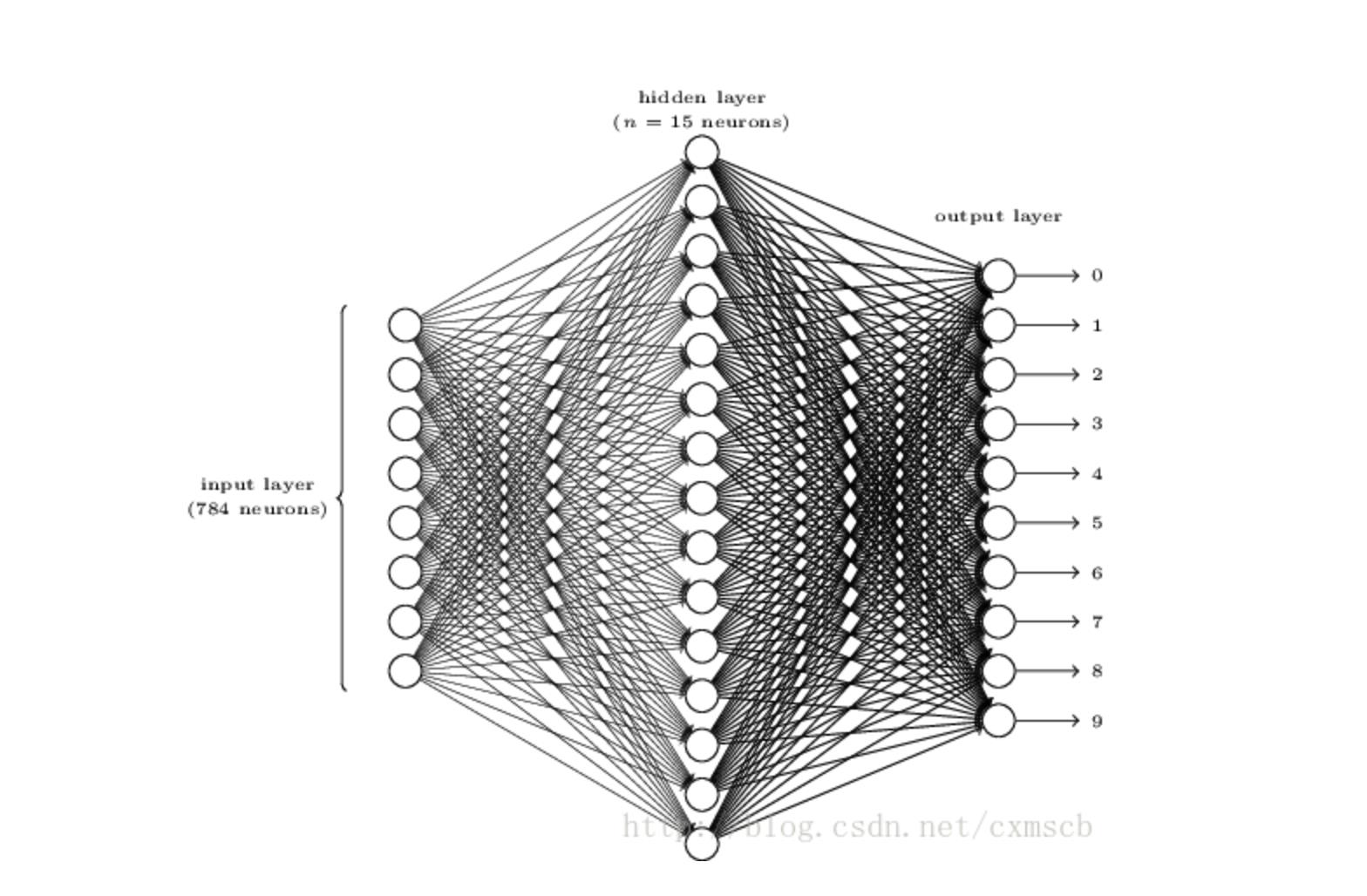
最后的全连接层是 10 个节点,全连接层的上一层是 15 个特征值,这样就把 15 个特征值归类为 10 种特征。举例来说,比如输出的 15 个特征标记位 t1-15,而 t1,t3,t5 三种特征可以认为都属于某一种输出 o1。而 t2,t6 两种特征可以认为属于输出 o2,以此类推,就可以把15个特征分类为 10 个输出。
前面提到的MNIST问题中,全连接层有两层,第一层是 1024 个节点,第二层是 10 个节点。一般情况下,最靠近用户的输出层就是用户所期待的结果类别数,MNIST 问题中,用户期待的输出是 0-9 一共 10 个数字也就是 10 种类别,所以第二层全连接层是 10 个节点。再往前看,卷积层在每一个像素点上提取 64 个特征值,所以整个图片可以有高*宽*64个特征值,也就是 7*7*64 个特征,第一个全连接层是 1024 个节点,表示希望这个网络将这 7*7*64 个特征归类为 1024 个分类。至于为什么第一个连接层是 1024 个节点,是一个经验值的问题,这个节点的个数是可以调整的,后面会讲到全连接层对模型体积的影响,也会再说到这个经验值的问题。那么全连接层是如何分类的。一起来看一下。
回顾一下全连接层的表示公式。
这里的输入值 x1,x2,x3…,输出值 a1 和权重 W,偏移量 b 到底指的是什么呢。
在MNIST的基础上,可以考虑这样一种情况。看下面这个图,对于0这个数字来说,我们经过训练之后,认为如果一张图片在中间红色部分出现了像素值,那这张图有一定概率不是 0,并且出现在红色部分的像素值越多,不是 0 的概率越大。如果在周围一圈的蓝色部分出现了像素值,那么这张图有一定概率是 0,并且出现在蓝色部分的像素值越多,是 0 的概率越大。

这个过程用数学公式怎么表示呢,蓝色部分拥有正值的权重,红色部分拥有负值的权重,将输入图片的每个像素点与权重值进行相乘后求和,这样如果红色部分出现的像素值越多,则最后的和越小,如果蓝色部分出现的像素值越多,则最后的和越大。最后得出的结果我们称为是输入图片x是这种分类(比如分类0)的证据 evidence。这样对于一张输入的图片,最后落在每个节点上的 evidence 就可以用如下的公式表示。

看这个公式,是不是就是全连接层的公式。所以全连接层这个过程比较绕,但是是深度学习网络的基本原理,可以仔细理解一下。
反过来看代码。
# Fully connected layer 1 -- after 2 round of downsampling, our 28x28 image
# is down to 7x7x64 feature maps -- maps this to 1024 features.
with tf.name_scope('fc1'):
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)首先生成全连接层的权重 W_fc1 和偏量 b_fc1,这里复用了前面卷积操作生成卷积核和偏量的两个方法,虽然概念不同,但计算是相通的,所以可以复用。tf.reshape(h_pool2, [-1, 7 * 7 * 64]) 将之前层的四维 [1,7,7,64] 的输出变成一个一维的向量,因为全连接层只能处理一维的问题。后面用 tf.matmul 向量乘法实现了全连接层的操作。tf.nn.relu 和前面一样,是个激活函数。
droupout
在第一层全连接层之后,加了一个 dropout 的操作
# Dropout - controls the complexity of the model, prevents co-adaptation of
# features.
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)droupout 的操作如下图所示:
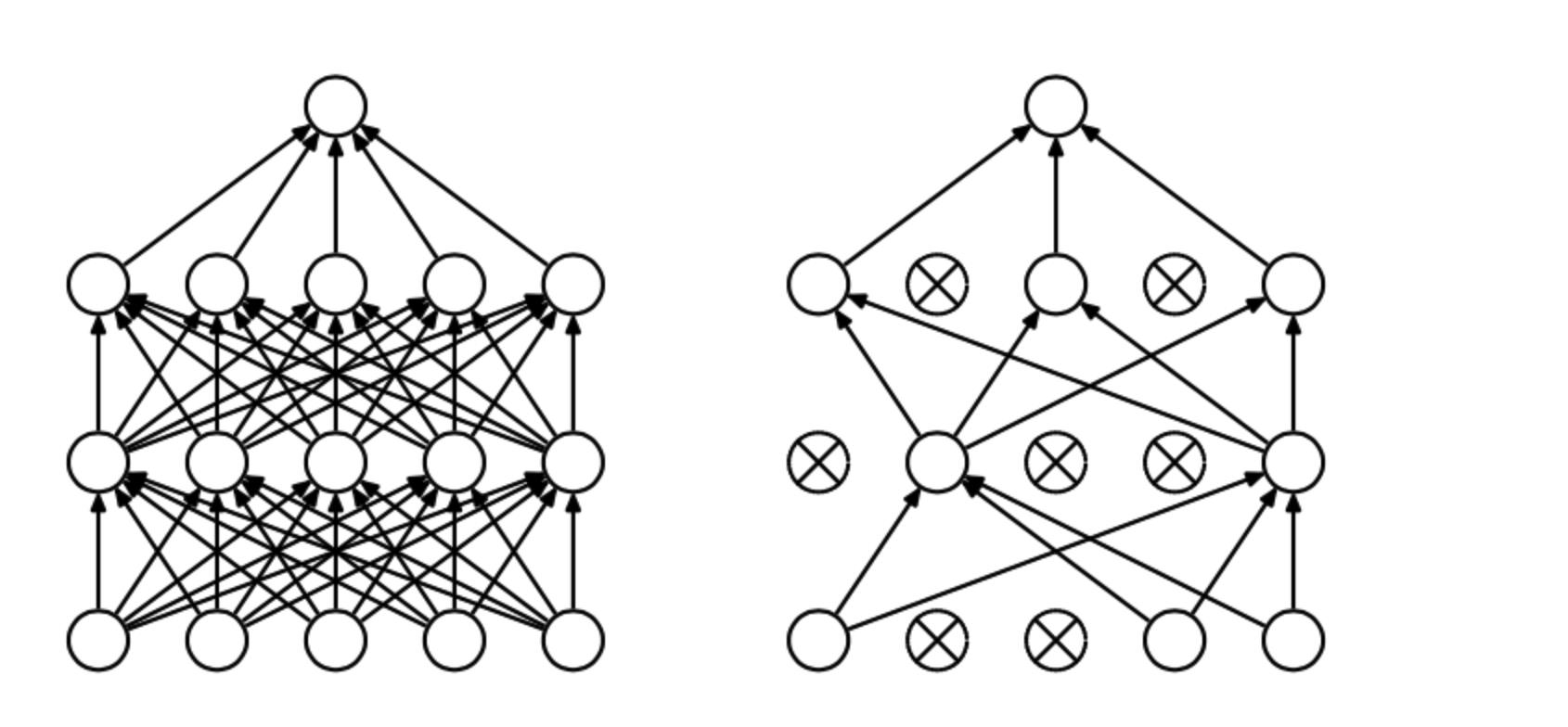
在计算的过程中,随机的“丢弃”一些节点,简单来说,h_fc1有 1024 个节点,在 droupout 之后,如果 keep_prob 是50%,那么经过 droupout 之后,可以认为参与计算的是 512 个节点。droupout 有两个优势。
- 解决过拟合的问题
- 在训练中加入概率性
droupout 操作之后又是一层全连接。
# Map the 1024 features to 10 classes, one for each digit
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.add(tf.matmul(h_fc1, W_fc2), b_fc2, name="output")第二层全连接将上一层产生的 1024 个节点归类到 10 个节点上,,得到最后的输出。即使经过 droupout 之后,实体依然是 1024 个节点,只是其中一部分不再参与计算。这个网络结构最后的输出是10个节点的 evidence 的值。
3.2.4 Softmax回归处理
至此,整个计算图就定义完了,接下来定义一些训练中的必要单元来告知框架如何训练。
with tf.name_scope('loss'):
cross_entropy = tf.losses.sparse_softmax_cross_entropy(
labels=y_, logits=y_conv)
cross_entropy = tf.reduce_mean(cross_entropy)定义损失函数使用 softmax 交叉熵的,关于 softmax 和交叉熵,这里引用传送门一段描述。
神经网络的原始输出不是一个概率值,实质上只是输入的数值做了复杂的加权和与非线性处理之后的一个值而已,那么如何将这个输出变为概率分布?
这就是 softmax 层的作用,假设神经网络的原始输出为 y1,y2,….,yn,那么经过 softmax 回归处理之后的输出为:

经过 softmax 的公式后,所有节点的和变成了 1,之前神经网络输出的每个节点的权重值变成了每个节点的概率值。
单个节点的输出变成的一个概率值,经过 softmax 处理后结果作为神经网络最后的输出。label
3.2.5 交叉熵的原理
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布 p 为期望输出,概率分布 q 为实际输出,H(p,q) 为交叉熵,则:

这个公式如何表征距离呢,举个例子:
假设 N=3,期望输出为 p = (1,0,0),实际输出 q1 = (0.5,0.2,0.3),q2 = (0.8,0.1,0.1),那么:

很显然,q2 与 p 更为接近,它的交叉熵也更小。
除此之外,交叉熵还有另一种表达形式,还是使用上面的假设条件:
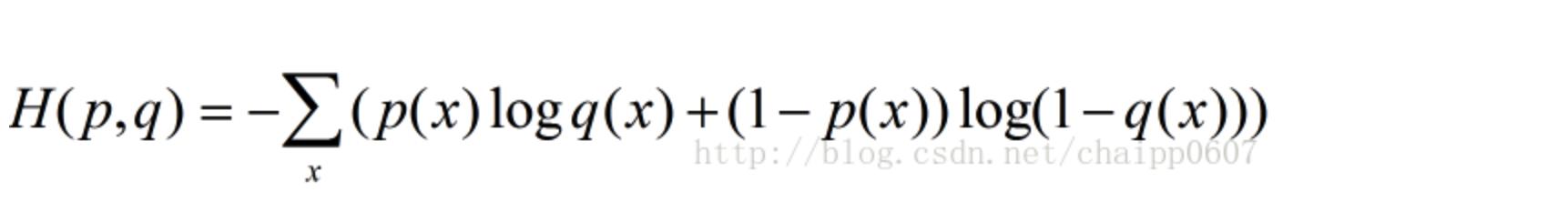
其结果为:
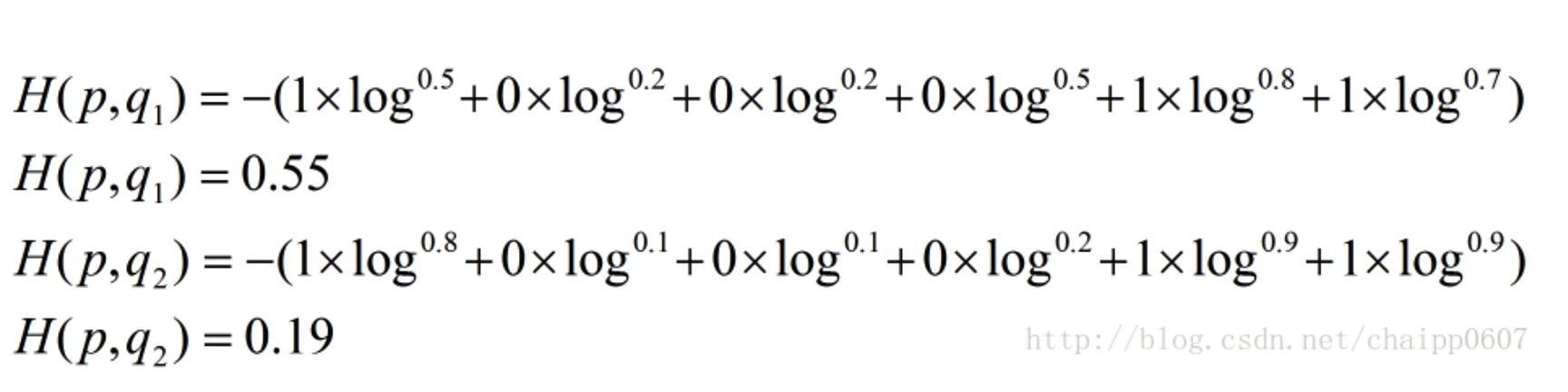
以上的所有说明针对的都是单个样例的情况,而在实际的使用训练过程中,数据往往是组合成为一个 batch 来使用,所以对用的神经网络的输出应该是一个 m*n 的二维矩阵,其中 m 为 batch 的个数,n为分类数目,而对应的 label 也是一个二维矩阵,还是拿上面的数据,组合成一个 batch=2 的矩阵:

所以交叉熵的结果应该是一个列向量(根据第一种方法):

而对于一个 batch,最后取平均为 0.2。
tf.losses.sparse_softmax_cross_entropy 是 TensorFlow 将以上两个过程封装后的产物,最后的结果是一个 batch 的概率值,reduce_mean 用来取得概率的平均值。综上作为整个网络的损失函数。
3.2.6 训练方法-梯度下降
然后定义梯度下降的方法
with tf.name_scope('adam_optimizer'):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)以下降步速,即学习率为1e-4的速度最小化损失函数 cross_entropy。这样就能定义训练的目的是为了让损失函数越来越来,每次参数的变化值为1e-4。
3.2.7 准确度
定义准确度的计算方法
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv, 1), y_)
correct_prediction = tf.cast(correct_prediction, tf.float32)
accuracy = tf.reduce_mean(correct_prediction)y_conv 是网络输出的原始结果,也就是图片在最后 10 个节点上的权重值,比如 [314, -423, 342…] ,最后权重值最大的节点是我们的期望节点,比如这里第三个节点的权重值最大,那这幅图片可能就是数字 2,tf.argmax 是取出权重值最大的下标。y_ 是我们给的 label 值,把这两个值相比较得出准确度。最后依然用 tf.reduce_mean 算出 batch 的平均准确度。
3.2.8 计算图可视化
graph_location = tempfile.mkdtemp()
print('Saving graph to: %s' % graph_location)
train_writer = tf.summary.FileWriter(graph_location)
train_writer.add_graph(tf.get_default_graph())这是 TensorFlow 提供的计算图可视化的方法,这里暂时没起到作用。
3.2.9 启动计算图
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict=
x: batch[0], y_: batch[1], keep_prob: 1.0)
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict=x: batch[0], y_: batch[1], keep_prob: 0.5)
print('test accuracy %g' % accuracy.eval(feed_dict=
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0))这里就是前面提到的将计算图和计算数据给 CPU 计算,TensorFlow 将和 CPU 的一个交互过程定义为 session,启动 session 后,开始运行。
sess.run(tf.global_variables_initializer())首先将前面定义的所有变量初始化,注意前面在定义图的时候只是定义了变量初始化的方法,而没有真正去做初始化,真正运行是在这个地方。
然后循环 20000 次,每次从训练集中取出50个图片数据作为一个 batch。
train_step.run(feed_dict=x: batch[0], y_: batch[1], keep_prob: 0.5)开始训练,train_step 是前面定义的梯度下降的方法,以这种方法开始训练。参数是图片数据,正确的 labels,和 droupout 的参数。
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict=
x: batch[0], y_: batch[1], keep_prob: 1.0)
print('step %d, training accuracy %g' % (i, train_accuracy))每训练 100 次,输出一下当前的准确率,是为了开发者感知的。测试准确率的时候,是不需要 droupout 操作的,所以 keep_prob 是1。
print('test accuracy %g' % accuracy.eval(feed_dict=
x:以上是关于TensorFlow入门1-CNN网络及MNIST例子讲解的主要内容,如果未能解决你的问题,请参考以下文章
TensorFlow入门实战|第1周:实现mnist手写数字识别
TensorFlow入门实战|第1周:实现mnist手写数字识别
TensorFlow入门实战|第1周:实现mnist手写数字识别