CVPR2022-HairCLIP:基于文本和参考图像的头发编辑方法论文理解
Posted zhanglin0530
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR2022-HairCLIP:基于文本和参考图像的头发编辑方法论文理解相关的知识,希望对你有一定的参考价值。

图1 图像、文本单独或联合编辑发型图
本文作者提出了一种新的头发编辑交互模式,可以根据用户提供的文本或参考图像单独或联合操作发型和发色属性。
前言:
本文是基于StyleCLIP和StyleGAN两种方法上进行改进
StyleCLIP: 通过利用 CLIP强大的图像文本表示能力,取得了惊人的图像处理结果。 CLIP [32] 是一个多模态模型,由从互联网收集的 4 亿个图像-文本对进行预训练。它由一个图像编码器和一个文本编码器组成,分别将图像和文本编码为 512 维嵌入向量。它采用典型的对比学习框架,最小化正确图像文本对的编码向量之间的余弦距离,最大化错误对的余弦距离。得益于大规模的预训练,CLIP 通过学习一个共享的图像-文本嵌入空间,可以很好地测量图像和文本之间的语义相似度。
StyleGAN:可以利用渐进式上采样网络从噪声中合成高分辨率、高保真逼真的图像。它的合成过程涉及多个潜在空间。 Z ∈ R512 是 StyleGAN 的原始噪声空间。一个随机采样的噪声向量 z ∈ Z 在 8 个全连接层之后被转换为 W ∈ R512 潜在空间。几项研究 [8,10,18,36] 表明,StyleGAN 在训练期间自发地学习在其 W 空间内编码丰富的语义,因此 W 表现出良好的语义解耦特性。此外,最近的一些 StyleGAN 反演工作 [1, 33, 47] 将 W 空间扩展到 W+ 空间以进行更好的重建。对于 18 层的 StyleGAN,它由 18 个不同的 512 维向量 [w1, ..., w18] 的级联定义,wi ∈ W。
一、解决问题
现有问题:
1、现有方法交互方式不够直观友好
1) 许多现有发型迁移方法需要精心绘制的草图或蒙版作为编辑的条件输入,但是这些交互既不简单也不高效。
2、StyleCLIP支持基于文本描述的头发编辑,但是不够灵活、效果差,有些发型无法用文本准去表述
1) 对于每个特定的头发编辑描述,它需要训练一个单独的映射器,这在实际应用中是不灵活的;
2) 缺乏量身定制的网络结构和损耗设计,使得该方法对发型、发色和其他不相关属性难以解开;
3) 在实际应用中,某些发型或颜色很难用文字描述。此时,用户可能更喜欢使用参考图像,但是StyleCLIP不支持基于参考图像的头发编辑。
解决方法(创新):
1) 为了将用户从繁琐的交互过程中解放出来,本文作者本文提出了第一个同时实现文本和图像条件的统一框架,即该框架同时支持使用文本或参考图像或者文本+参考图像联合作为发型、发色参照条件。这提供了一种更直观,更方便的交互模式,并在单个模型中实现了多种文本和图像条件,而不需要特意去训练许多独立的模型。此外,受益于为此任务量身定制的新设计,我们的方法还显示出更好的头发处理质量。
2) 为了以一种灵活的文本或参考图像单独或联合操作发型和发色属性以及更好的视觉效果。作者提出了一些新的网络结构设计和为任务量身定制的损失函数。
二、算法框架
本文遵循StyleCLIP并利用在大规模人脸数据集上预先训练的StyleGAN作为其生成器,给定要编辑的真实图像,我们首先使用 StyleGAN 反演方法“e4e”[43] 得到其在 W+ 空间中的隐编码 w,然后使用映射器网络根据 w 预测潜在代码变化 Δw和编辑条件(包括发型条件es和头发颜色条件ec)。最后,将修改后的潜码 w' = w + Δw 反馈到预训练的 StyleGAN 中,得到目标编辑结果。
然后关键是学习一个映射器网络以将输入条件映射到相应的潜在代码更改中。
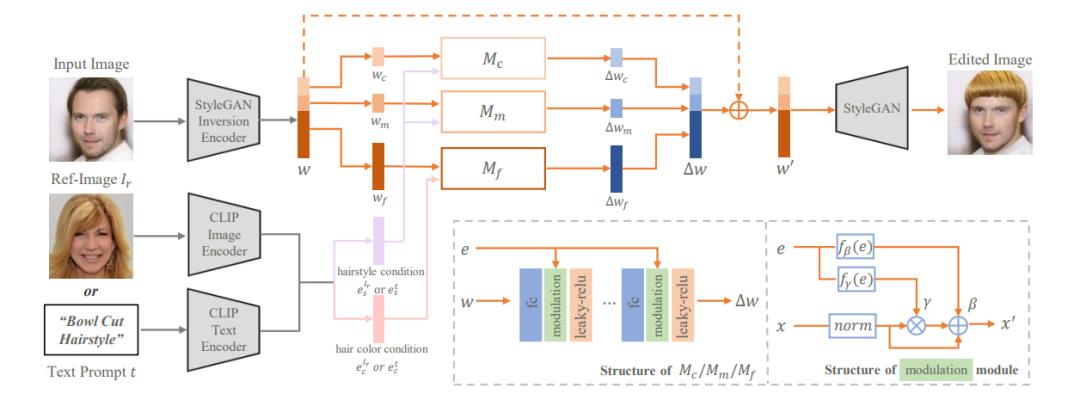
图2 HairCLIP网络框架图
1、整个算法框架的步骤如图2所示:
首先处理目标图像:给定要编辑的目标图像input image,通过StyleGAN Inversion编码器得到目标图像的隐编码w,然后按照语义级别的不同,将隐编码分为不同部分(粗、中、细)对应的头发编辑的 wc, wm, wf。
其次处理发型参照条件: 给定要迁移发型的文本发型提示和文本头发颜色提示(发型发色参考图像/文本提示+参考图像)的发型和发色信息,使用 CLIP 的文本编码器(图像编码器/图像+文本编码器)将它们编码为 512 维条件嵌入,分别表示为 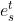 和
和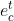 。类似地,发型参考图像和头发颜色参考图像由 CLIP 的图像编码器编码,分别表示为
。类似地,发型参考图像和头发颜色参考图像由 CLIP 的图像编码器编码,分别表示为  和
和 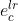 。因为 CLIP 在大规模图像-文本对上训练有素, , , , 都驻留在共享的潜在空间中。
。因为 CLIP 在大规模图像-文本对上训练有素, , , , 都驻留在共享的潜在空间中。
然后将隐编码和发型发色信息输入到头发映射器网络生成∆ w:将隐编码与潜在空间中的发型信息( or )+发色信息( or )分别喂入三个头发映射器子网络Mc,Mm,Mf,它们负责预测对应于潜在代码w = (wc,wm,wf) 的不同部分 (粗,中,细) 的头发编辑的 ∆ w。然后w'=w+∆ w
注:来自 CLIP 的发型信息  ∈ , 的嵌入作为 Mc 和 Mm 的条件输入,来自 CLIP 的头发颜色信息
∈ , 的嵌入作为 Mc 和 Mm 的条件输入,来自 CLIP 的头发颜色信息  ∈ , 的嵌入作为 Mf 的条件输入。这是基于经验观察,发型通常对应于 StyleGAN 中的中高级语义信息,而头发颜色对应于低级语义信息。
∈ , 的嵌入作为 Mf 的条件输入。这是基于经验观察,发型通常对应于 StyleGAN 中的中高级语义信息,而头发颜色对应于低级语义信息。
最后求和后,通过StyleGAN解码器得到最终结果:求和w'=w+∆ w后,将w'输入StyleGAN解码器得到最终的发型迁移结果图
三、网络结构设计
1、共享条件嵌入——在一个框架下统一文本和图像域的条件
我们自然选择通过将它们嵌入到 CLIP 的联合潜在空间中来表示它们。对于用户提供的文本发型提示和文本头发颜色提示,我们使用 CLIP 的文本编码器将它们编码为 512 维条件嵌入,分别表示为 和。类似地,发型参考图像和头发颜色参考图像由 CLIP 的图像编码器编码,分别表示为 和 。因为 CLIP 在大规模图像-文本对上训练有素, , , ,都驻留在共享的潜在空间中,因此可以馈送到一个映射器网络并灵活切换。
2、解耦的信息注入——旨在提高网络对发型和头发颜色编辑的解耦能力
StyleGAN 的不同层对应于生成图像中不同语义级别的信息,而前面的层越多对应于更高语义级别的信息。注意到 StyleGAN 中的这种语义分层现象,提出了解耦信息注入,旨在提高网络对发型和头发颜色编辑的解耦能力。具体来说,使用来自 CLIP 的发型信息 ∈ , 的嵌入作为 Mc 和 Mm 的条件输入,并且使用来自 CLIP 的头发颜色信息 ∈ , 的嵌入作为Mf 的条件输入。因此,头发映射器M可以公式化为:
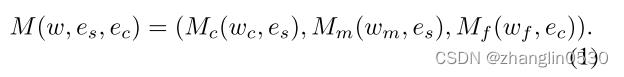
3、调制模块——对潜码输入条件的直接控制,从而提高了该方法的操纵能力
头发映射器子网络:每个头发映射子网络遵循简单的设计,由五个block组成,每个block由一个全连接(fc)层、一个新设计的调制模块和一个非线性激活层(leakly relu )。
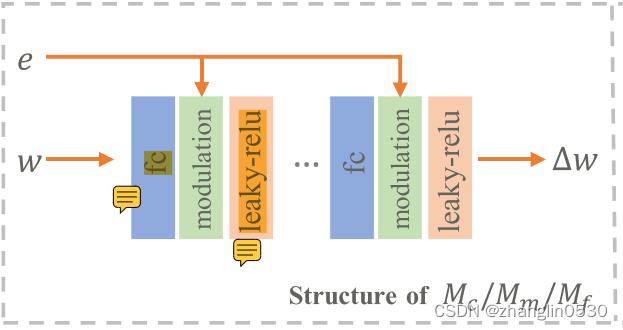
图3 头发映射器子网络结构图
调制模块:调制模块不是简单地将条件嵌入与输入潜在代码连接起来,而是使用条件嵌入 e 来调制前面 fc 层的中间输出 x。
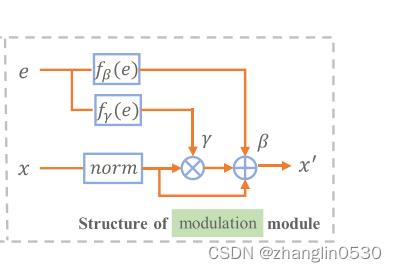
图4 调制模块结构图
所以在数学上,它遵循以下公式:

其中 µx 和 σx 分别表示 x 的均值和标准差。 fγ 和 fβ 使用简单的全连接网络(两个 fc 层,一个layernorm和一个leaky relu layer)实现。在测试过程中,如果没有为发型或头发颜色提供条件输入,则相应的子头发映射器中的所有调制模块都将实现为恒等函数,我们将这种情况表示为 = 0或 = 0。这样,我们灵活地支持用户只编辑发型、只编辑头发颜色或同时编辑发型和头发颜色。
四、损失函数
损失函数主要包括文本操纵损失+图像操纵损失+属性保存损失
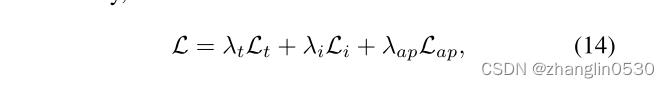
其中 Lt为文本操纵损失;Li为图像操纵损失;Lap为属性保存损失。λ t,λ i,λ ap默认分别设置为2, 1, 1。接下来将分别介绍这三种损失函数。
1、 Text manipulation loss(文本操纵损失)
为了根据发型或颜色的文本提示进行相应的头发操作,我们在CLIP的帮助下设计了如下的文本操纵损失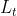 = 发型文本操纵损失
= 发型文本操纵损失 + 发型颜色文本操纵损失
+ 发型颜色文本操纵损失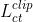

- 发型文本操纵损失
对于发型文本操纵损失,我们在剪辑的潜在空间中测量操纵图像与给定文本之间的余弦距离:
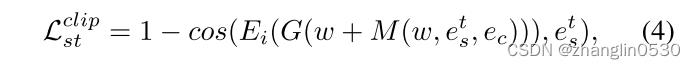
其中cos(·) 表示余弦相似性, 表示CLIP的图像编码器,G表示预训练的StyleGAN生成器, = Et(st) 表示由CLIP的文本编码器Et编码的给定发型描述文本st的嵌入, ∈ , ,0。
表示CLIP的图像编码器,G表示预训练的StyleGAN生成器, = Et(st) 表示由CLIP的文本编码器Et编码的给定发型描述文本st的嵌入, ∈ , ,0。
个人理解:∆ w=M(W, , ),然后w'=w+∆ w后,通过StyleGAN生成器G(w')生成发型迁移结果图,然后把生成的发型迁移结果图输入到CLIP的图像编码器Ei(G(w'))得到,最后求与的余弦相似性,相似性越大,发型文本操纵损失越小
- 发色文本操纵损失
与发型文本操纵损失相同的原理,发色文本操纵损失如下:
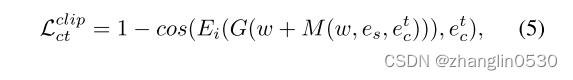
其中表示由CLIP的文本编码器编码的给定发色描述文本的嵌入,并且 ∈ , ,0。
个人理解:与发型文本操纵损失原理一样,唯一的区别是固定头发映射器中的发色文本描述的嵌入,与而发型可以是文本输入可以是图像输入,也可以不输入即为0。然后求与发色文本描述的嵌入的余弦相似性。
2、Image manipulation loss(图像操纵损失)
给定参考图像,作者希望被操纵的图像具有与参考图像相同的发型。然而,表征两种发型之间的相似性是一项具有挑战性的任务。再次利用CLIP的强大潜力,作者使用CLIP的图像编码器分别对它们进行编码,以测量它们在CLIP潜在空间中的相似性: 图像操纵损失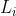 =
= 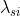 * 发型图像操纵损失
* 发型图像操纵损失 +
+ 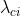 发色图像操纵损失
发色图像操纵损失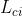

其中 , 默认分别设置为 5, 0.02。
- 发型图像操纵损失

其中,被操纵的图像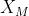 = G(w+M(w,,)), = (x ∗
= G(w+M(w,,)), = (x ∗ 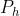 (x)), ∈ , ,0,P表示预先训练的面部解析网络, () 表示 的头发区域的掩码,表示通过图像的发型信息生成的发型迁移图。(x) 表示x的头发区域的掩码,x表示给定的发型参考图像。表示CLIP的图像编码器。
(x)), ∈ , ,0,P表示预先训练的面部解析网络, () 表示 的头发区域的掩码,表示通过图像的发型信息生成的发型迁移图。(x) 表示x的头发区域的掩码,x表示给定的发型参考图像。表示CLIP的图像编码器。
个人理解:首先为 G(w+M(w,,))生成的发型迁移结果图,x为发型参照图,两张图分别取其头发部分的信息即 * ()和 x * (x),然后再通过CLIP的图像编码器得到发型迁移结果图的发型描述图像的嵌入 '与发行参照图的发型描述图像的嵌入
'与发行参照图的发型描述图像的嵌入 ,然后求两者的余弦相似度。
,然后求两者的余弦相似度。
- 发色图像操纵损失
另外,对于基于参考图像的头发颜色处理,我们计算参考图像和处理图像之间的头发区域中的平均色差作为损失:
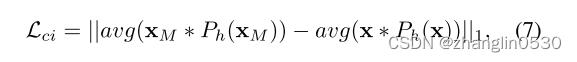
个人理解:发型图像操纵损失类似,只是发色图像操纵损失是求平均色差。首先取生成的发型迁移结果图与发型参照图x 头发部分的信息即 * ()和 x * (x)并求平均值后做差。
3、 Attribute preservation loss(属性保留损失)
整体属性保留损失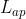 =
=  * 身份损失
* 身份损失 +
+  * 仅操作发型时保持发色损失
* 仅操作发型时保持发色损失 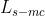 +
+ 
* 背景损失 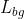 +
+ 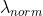 * 非相关属性区域保持不变损失
* 非相关属性区域保持不变损失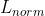
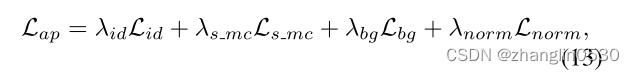
其中、、、 默认分别设置为 0.3、0.02、1、0.8。
- 身份损失
为了确保头发编辑前后的身份一致性,身份损失应用如下:
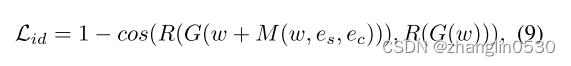
其中, ∈ , ,0, ∈ , ,0,R是用于人脸识别的预训练的ArcFace 网络,G(w) 表示重建的真实图像。
个人理解:生成的发型迁移结果图与目标图像重构的图输入到人脸识别的预训练的ArcFace 网络R中,然后再求两者的余弦相似度
- 仅操作发型时保持发色损失
此外,我们以与发色图像操纵损失相同的方式设计,以便在仅操纵发型时保持发色:
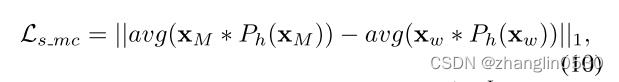
其中 = G(w+M(w,,)), ∈ , , = 0, 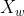 = G(w) 。根据经验,我们发现只改变颜色就可以很好地保留发型,因此我们不添加相应的保留损失。
= G(w) 。根据经验,我们发现只改变颜色就可以很好地保留发型,因此我们不添加相应的保留损失。
个人理解: 为只添加发型信息生成的发型迁移结果图,为目标图像重构得到的图像(即只输入目标图像,发型发色信息为0通过StyleGAN生成器G生成的图像)。 分别取两者的头发部分的信息 * ()和 * (),然后取平均值,再做差。
- 背景损失
此外,作者借助面部解析网络 [27] 引入了背景损失:
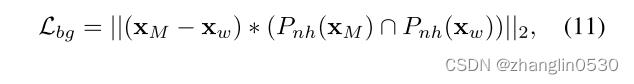
其中 = G(w+M(w,,)), 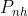 ()表示的非头发区域的掩码。通过这种方式,我们在很大程度上确保了非相关属性区域保持不变。 为生成的发型迁移结果图,为目标图像重构得到的图像(即只输入目标图像,发型发色信息为0通过StyleGAN生成器G生成的图像)
()表示的非头发区域的掩码。通过这种方式,我们在很大程度上确保了非相关属性区域保持不变。 为生成的发型迁移结果图,为目标图像重构得到的图像(即只输入目标图像,发型发色信息为0通过StyleGAN生成器G生成的图像)
- 非相关属性区域保持不变损失
同时为了确保了非相关属性区域保持不变,使用了潜在空间中操作步骤的 L2 范数:
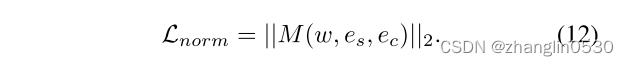
四、成果展示
1、与文本驱动图像处理的方法相比
作者将他们的方法与当前最先进的文本驱动图像处理方法TediGAN 和StyleCLIP 在十个文本描述上进行了比较。视觉比较如下图所示。

图5 三种文本驱动图像方法生成的效果比较图
如图5所示,与StyleCLIP 和TediGAN 的视觉比较。对应的简化文字说明 (编辑发型、发色,或两者兼而有之) 列在每行最左侧,所有输入图像均为真实图像的反转。我们的方法在完成指定的头发编辑的同时,展示了更好的视觉真实感和不相关的属性保存能力。
2、与头发转移方法的比较
如图 6所示. 作者的方法与 LOHO 和 MichiGAN 在头发转移方面的比较。 HRI 表示发型参考图像,CRI 表示头发颜色参考图像。

图6 三种发型迁移方法生成的效果比较图
3、用户体验
为了进一步评估两种类型的头发编辑任务中不同方法的编辑结果的操纵能力和视觉真实感,作者招募了20名参与者进行用户研究。
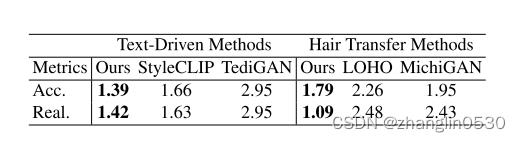
表1. 文本驱动的图像处理方法和头发转移方法的用户研究。
Acc表示给定条件输入和实数的操纵精度。Real表示操纵图像的视觉真实感。表格中的数字是平均排名,越低越好
4、消融实验
为了定量评估不相关属性的保存,使用了四个指标: IDS表示由课程表面计算的编辑前后的身份相似性 。PSNR和SSIM是在编辑前后非头发区域的相交区域中计算的。ACD代表头发区域的平均色差。
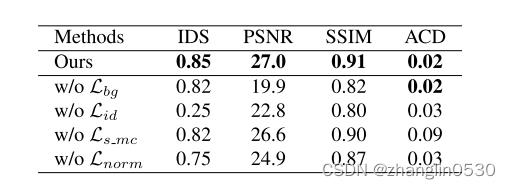
表2. 属性保存损失的定量消融实验。

图7. 各个指标对迁移结果图的影响

图8. 通过该方法和模型的变体生成的结果的视觉比较
如图8所示,文字描述为 “烫发发型和红头发”。(a) 将条件输入与潜在代码连接。(b) 用头发颜色嵌入替换粗和中子头发映射器的条件输入,用发型嵌入替换细子头发映射器的条件输入。(c) 将中等子毛发映射器的条件输入替换为毛发颜色嵌入,其余部分保持不变。
5、头发插值
给定两个编辑后的隐编码 WA,WB ∈ W+,我们可以通过插值实现细粒度的头发编辑。通过线性加权将两个隐编码组合起来完成细粒度的头发编辑。

图9. 头发插值结果
6、泛化能力
由于共享条件嵌入策略,该方法在仅使用有限数量的头发编辑描述进行训练后具有一定的外推能力,这对于从未出现在训练描述中的文本产生了合理的编辑结果。

图10. 模型的泛化能力
尽管从未接受过 “卷发短发”,“蘑菇发型”,“紫罗兰色头发” 和 “银发” 的这些描述的训练,但该模型的方法仍然可以产生合理的操作结果。
五、总结
作者提出了一种新的头发编辑交互模式,将来自文本和图像域的条件输入统一在一个统一的框架中。在该框架中,用户可以单独或共同提供文字描述和参考图像来完成头发编辑。这种多模态交互大大增加了头发编辑的灵活性,降低了用户的交互成本。同时作者通过最大限度地发挥 CLIP 的巨大潜力、量身定制的网络结构设计和损失函数,以解耦的方式支持高质量的头发编辑。
以上是关于CVPR2022-HairCLIP:基于文本和参考图像的头发编辑方法论文理解的主要内容,如果未能解决你的问题,请参考以下文章
论文速递CVPR2021 - 基于自适应原型学习和分配的小样本分割
CVPR2022 | ZeroCap:零样本图像到文本生成的视觉语义算法
CVPR2022:Generalizable Cross-modality Medical Image Segmentation via StyleAugmentation and Dual Norm