CVPR2022:Generalizable Cross-modality Medical Image Segmentation via StyleAugmentation and Dual Norm
Posted HheeFish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR2022:Generalizable Cross-modality Medical Image Segmentation via StyleAugmentation and Dual Norm相关的知识,希望对你有一定的参考价值。
CVPR2022:Generalizable Cross-modality Medical Image Segmentation via StyleAugmentation and Dual Normalization基于样式增强和双重归一化的通用跨模态医学图像分割
0.摘要
对于医学图像分割,想象一下,如果只在源域使用MR图像训练模型,在目标域直接分割CT图像的性能如何?这种设置,即广义交叉模式分割,具有临床潜力,比其他相关设置,如领域适应更具挑战性。为了实现这一目标,我们在本文中提出了一种新的双归一化模型,在我们的广义分割过程中利用增强的源相似图像和源不同图像。具体来说,在给定单个源域的情况下,为了模拟在不可见的目标域中可能出现的外观变化,我们首先利用非线性变换来增强源相似图像和源不同图像。然后,为了充分利用这两种类型的增强,我们提出的基于双归一化的模型使用一个共享的骨干但独立的批归一化层进行单独的归一化。然后,我们提出了一种基于样式的选择方案来自动选择测试阶段的合适路径。在三个公开可用的数据集上的广泛实验,即BraTS、跨模态心脏和腹部多器官数据集,已经证明我们的方法优于其他最先进的领域一般化方法。
1.概述
近年来,深度卷积神经网络在医学图像分割方面取得了深刻的进展[22,30,35]。得益于这些最近的努力,医学图像分割的准确性得到了很大的提高。尽管它们取得了成功,但训练(或标记)和测试(或未标记)数据之间的分布转移通常会导致经过训练的分割模型-els部署期间严重的性能退化。分配转移的原因通常来自不同方面,例如:,不同的采集参数,不同的成像方法或不同的模式。
为了对抗领域转移,人们研究了几种实用的设置,其中基于UDA(无监督域适应)的分割[6,14,44]是最受欢迎的。具体而言,在UDA设置中,通过假设可以观察到测试数据或未标记数据,首先在标记的源域(即训练集)和未标记的目标域(即测试集)上训练模型,减小它们的域间隙。然后,利用训练好的模型将图像与目标域进行分割。然而,这些基于UDA的模型要求目标域可以被观察,甚至被允许接受训练。这种前提条件在实际应用中有时难以满足或不可行。例如,为了保护个人隐私信息,某些机构的目标域(或测试集)不能被直接访问
为了缓解UDA对目标区域的要求,我们考虑了一种更可行但更具有挑战性的设置,即领域泛化(DG,Domain Generation),以实现针对区域偏移的可泛化医学图像分割。我们没有注意到,大多数现有的DG模型仅仅在不同主频之间的小变化下,跨中心设置下表现良好,而大的域偏移(例如,跨模态)很少被研究,这可能会极大地降低它们的性能[25,26,40]。
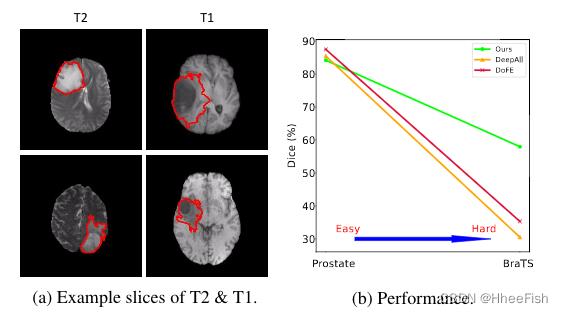
图1。(a) BraTS数据集的示例切片;(b)我们的方法与“DeepAll”和“DoFE”方法在跨中心前列腺分割任务和跨模态脑肿瘤分割任务上的比较
我们现在展示两种可概括的细分场景(即跨中心和跨模态)来阐明我们的动机。具体地说,在图1b中,我们如何在两个不同的DG任务上实现我们的方法(称为“我们的”)、“DeepAll”基线和最先进的跨中心DG方法(“DoFE”)[40]的结果。第一个任务是跨中心前列腺分割任务[27]。正如图1b所示,所有这些方法在这个任务中都取得了相对较高的Dice分数(80%),而且不同方法之间的差距非常小。然而,当我们将这三种方法应用于BraTS数据集[29]时,跨模量脑肿瘤分割数据集,“DeepAll”和“DoFE”方法在Dice分数上显示了剧烈的下降(40%),而我们的方法仍然达到了竞争性的Dice分数(50%)。性能下降的原因在于大的域迁移。例如,在图1a中,我们展示了BraTSdataset[29]中的T2和t1加权图像。需要用红色曲线分割的脑肿瘤。很明显,T2和t1形态表现出明显不同的外观。因此,我们注意到跨通道分布式任务比跨中心分布式任务更具挑战性,因为前者需要处理更大的域转移。在本文中,我们的目标是处理具有大域转移的分布式分布式任务(如跨模态任务),而以往的分布式分布式任务方法都不是针对这一问题设计的。
我们的设置有其临床意义。例如,在成像过程中,由于一些不可预测的因素(如光源干扰)导致的较大分布偏移,对现有的概化方法提出了挑战。此外,在某些情况下,目标域的数据稀缺使得uda难以实现。总之,我们打算开发一种实现域分布位移不敏感建模的鲁棒方法。
基于上述动机,我们提出了一种通用的跨模态医学图像分割方法,训练于单个源域(如CT),并直接应用于不可见的目标域(如MRI),无需任何再训练。在医学图像中,形态差异通常表现为灰度分布差异。意识到这一事实,我们希望在不可见的目标域中模拟可能的外观变化。为了解决这个具有挑战性的跨模态分布式任务,我们引入了一个模块,可以随机地将源域扩展成不同的风格。具体来说,我们利用B́ezierCurves[31]作为变换函数,生成了两组图像:一组图像与s源域图像相似(即source-similar domain),另一组图像与源域图像分布差距较大(即source-dissimilar domain)。然后,我们引入了一个双归一化模块的分割模型来保存源-相似域-主要域和源-不同域的风格信息。最后,开发了一个基于样式的路径选择模块,帮助目标域图像选择最佳的归一化路径,以获得最佳的分割结果。本文的主要贡献总结如下:
- 我们提出了一个深度双归一化模型来解决更具挑战性的DG任务,即:,该算法可以直接将图像从不可见的目标区域中分割出来,而无需再训练。
- 我们通过基于b́ezier曲线生成源相似和源不同的图像来增强源域的多样性,并开发了一个用于有效开发的双归一化网络。此外,我们在测试阶段提出了基于样式的路径选择方案。
- 大量实验证明了我们的有效性。在OnBraTS数据集上,我们的方法在T2和T1CE源域上的Dice分别为54.44%和57.98%,这与作为我们的上界的UDA非常接近。在心脏和腹部多器官交叉模式数据集上,我们的方法优于最先进的DG方法。
2.方法
2.1.定义和概述
我们表示我们的单源域Ds=xsi,ysiNsi=1,其中s表示域ID,xsi源域中的第i个图像,ysi是xsi的分割掩膜, Ns为总样本数。我们的目的是在源域训练一个分割模型Sθ:x→y,其中x和y表示源域Ds中的图像集和标签集,Sθ表示分割模型,θ为模型参数。我们希望模型Sθ能很好地推广到不可见目标域Dt。

图2.我们方法的总体框架。我们首先使用样式增强模块将源域生成为不同的样式,并将它们划分为源相似域(Dss)和源不相似域(Dds)。然后,我们在(Dss)和(Dsd)上训练一个双重归一化(DN)分割网络。最后,我们通过基于样式的选择模块在目标域上测试训练的网络。
具体地说,我们首先提出了一个风格增强模块,该模块带有多个转换函数将源域扩展为源相似域和源不相似域。然后,基于一般的域Dss和Dsd,在我们的方法中引入了配备双归一化(DN)模块的网络。我们在域Dss和Dsd训练基于DN的模型。DN可以在模型训练后保留域样式信息。最后,根据DN中的域样式信息和目标域的实例样式信息,我们可以选择DN中最接近的归一化统计量来归一化目标域的特征,并获得最佳分割结果。我们的方法图如图2所示。我们现在讨论我们方法的技术细节。
2.2.风格增强模块
对于一般化的医学图像分割任务,使用单个源域来训练模型是非常困难的。不同模式之间的风格偏差会显著降低性能。从这个角度来看,我们提出一个简单而有效的样式增强模块,从源域生成不同的样式化图像
图1。(a) BraTS数据集的示例切片;(b)我们的方法与“DeepAll”和“DoFE”方法在跨中心前列腺分割任务和跨模态脑肿瘤分割任务上的比较
常用的医学图像模式(如X射线、CT和磁共振图像(MRI))通常是灰度图像。如图1所示,在T2加权MR脑图像中,整个肿瘤区域比周围亮得多。相反,在T1加权MR脑图像中,整个肿瘤的前景比背景区域暗。生成不同样式的简单方法是调整图像的灰度值分布。受先前工作模型Genesis[47]的启发,我们采用了几种单音非线性变换函数将原始图像的像素值映射到新值。因此,可以实现改变图像的灰度分布的操作。与[47]类似,我们使用平滑单调的B́ezier曲线[31]作为变换函数
B́ezier曲线可由两个端点(P0和P3)和两个控制点(P1和P2)生成。函数定义如下:
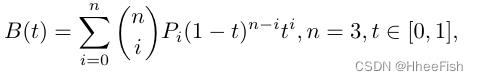

图3.T2加权增强MR脑图像和增强图像
其中t是沿直线长度的一个分数。所有B́ezier曲线的域和范围为:[−1,1]. 在图3中,我们展示了原始T2加权BraTS图像及其增强图像。我们设置P0=(−1.−1) 和P3=(1,1)得到一个递增函数,相反得到一个递减函数。当P0=P1和P2=P3时,B́ezier曲线是线性函数(如第2、5列所示)。然后,我们随机生成另外两对控制点。具体来说,我们设置P1=(−v、 v)和P2(v,−v)(v∈(0,1)). 我们随机为每个图像生成两个差分,因此我们通过反转得到两条增加曲线(如第3列和第4列所示)和两条减少曲线(如6列和第7列所示)。最后,我们得到了6个用于增强的非线性变换函数(三个增加和三个减少)。在我们的三个任务中,我们将每个样本标准化为[−1,1]. 应该注意的是,我们只对前景区域执行转换操作。
显然,在灰度医学图像中,单调递增变换函数对图像风格的影响较小。因此,我们将通过增加变换函数获得的这些变换图像分类为与源域图像相似的图像,我们称之为源相似域(Dss)。相反,由去增量变换函数生成的这些图像将被视为源异域(不相似)(Dsd)。我们假设灰度分布接近于源域图像的图像在通过Dss训练的模型上具有良好的泛化性能,而与源域具有较大分布间隙的其他图像可以在通过Dsd训练的模型上具有良好泛化性能。我们使用这两个域来训练下一节中介绍的基于DN的模型
2.3.双归一化基础网络
已经证明,批处理归一化[16]可以使神经网络很容易捕获其内部潜在空间[24]中的数据偏差。然而,基于BN的神经网络获取的数据偏差依赖于域的分布,这可能会降低在新域上测试的泛化能力。对于我们的样式增强图像,简单地采用BN会使模型失去Dss和Dsd的特定领域分布信息。因此,我们的模型可能不能很好地概括目标域。
为了捕获Dss和Dsd内不同的域分布信息,受之前工作[2]的启发,我们在一个模型中采用了两个不同的BN层来分别规范化Dss和Dsd的激活特性。我们称之为双重规范化(DN)。DN模块可以写成
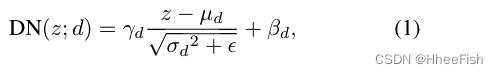
其中,z表示来自域d的激活特征,d表示域标签,γd和βd是仿射参数,(μd,σd2)表示来自域d的输入特征z的均值和方差, ε>0是一个较小的常数值,以避免数值不稳定。
在训练过程中,BN层通过带更新因子α的指数移动平均来估计激活特征的均值和方差。对于DN,它们可以写成

其中t为当前训练迭代,μ-td和(σ-td2为域d在第t次迭代运算的估计均值和方差。每个域DN的估计均值和方差可以看作是域的分布信息。在对目标域进行测试时,这些域的分布信息(μd,σd2)可以与目标域的分布信息(μd,σt2)进行比较。从而选择合适的区域分布统计量对目标区域的激活特征进行归一化
2.4.基于风格的路径选择
DN模块允许模型学习Dss和Dsd的多源分布。因此,估计DN中的统计信息可以看作是Dss和Dsd的域样式信息。因此,我们得到了一个轻量级集成模型,其中除归一化统计外,每个领域共享相同的模型参数。
通过Dss和Dsd对带有DN模块的模型进行训练。训练结束后,DN模块将保留域d的统计量μ和σ2d,以及训练数据的仿射参数γ和βd。因此,我们将得到两组μ和σ2d,可以表示为

其中d表示Dss和Dsd的域标签,l∈1,2,…,L表示模型中的第l个BN层。这可以定义为为某个特定域d嵌入[36]的批处理规范化。在我们的工作中,我们把ed称为领域d的风格嵌入。
对于目标样本,我们可以通过前向传播捕获实例统计(μ,σ2d)。目标域样本的样式嵌入可以描述为
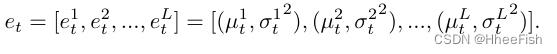
每个e1t表示向前传播过程中某一层目标域样本的实例样式统计。一旦目标域样本的实例样式嵌入可用,就有可能通过计算两个样本之间的距离来测量目标域样本的相似性
为了度量源域和目标域的风格嵌入之间的距离,我们采用了一个满足三角形不等式的对称距离函数。在我们的方法中,我们选择欧氏距离。第二层嵌入的距离可以写成

我们通过对所有层的风格嵌入elt和eld之间的距离求和来测量目标样本xt和源域之间的距离:

一旦计算到每个源域的距离,我们可以选择最近的源域风格嵌入和仿射参数γd和βd归一化目标域的输入特征:

对目标域特征的归一化表示为
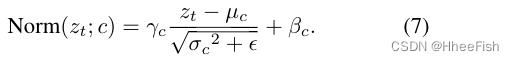
由于我们的模型在Dss和Dsd共享除批归一化层外的所有参数,我们训练的模型可以通过方程(7)中的归一化特征预测目标域的结果。我们用Sθ(·)作为我们的分割模型,Sθ表示模型中除批归一化层外的参数。因此我们可以形成对目标域Sθ(zct)的预测结果,其中zct表示式(7)归一化的目标域特征。
2.5.训练细节
如前所述,DN模块在我们的模型中包含两个独立的批处理规范化层——一个是为Dss,另一个是为Dsd。首先,我们将源域通过样式扩充模块扩充为Dss和Dsd。然后,我们将它们输入到基于DN的模型中,以获得软预测。然后,利用分割损失对模型Sθ进行优化。为了克服相对较小的前景和较大的背景之间的类不平衡问题,我们使用Dss和Dsd的一组软Dice损失来训练分割网络:
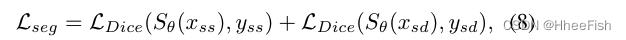
式中(xss,yss)和(xsd,ysd)表示来自Dss和Dsd的成对图像和相关的独热真值掩码,Sθ(·)得到软预测。我们在图2中展示了该方法的整体框架。
图2.我们方法的总体框架。我们首先使用样式增强模块将源域生成为不同的样式,并将它们划分为源相似域(Dss)和源不相似域(Dds)。然后,我们在(Dss)和(Dsd)上训练一个双重归一化(DN)分割网络。最后,我们通过基于样式的选择模块在目标域上测试训练的网络。
参考文献
[1] Yogesh Balaji, Swami Sankaranarayanan, and Rama Chel-lappa. Metareg: Towards domain generalization using meta-regularization.Advances in Neural Information ProcessingSystems, 31:998–1008, 2018. 3
[2] Woong-Gi Chang, Tackgeun You, Seonguk Seo, Suha Kwak,and Bohyung Han. Domain-specific batch normalizationfor unsupervised domain adaptation.InProceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition, pages 7354–7362, 2019. 2, 4
[3] Wei-Lun Chang, Hui-Po Wang, Wen-Hsiao Peng, and Wei-Chen Chiu. All about structure: Adapting structural infor-mation across domains for boosting semantic segmentation.InProceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition, pages 1900–1909, 2019. 2
[4] Prithvijit Chattopadhyay, Yogesh Balaji, and Judy Hoffman.Learning to balance specificity and invariance for in and outof domain generalization. InEuropean Conference on Com-puter Vision, pages 301–318, 2020. 3
[5] Cheng Chen, Qi Dou, Hao Chen, Jing Qin, and Pheng AnnHeng. Unsupervised bidirectional cross-modality adapta-tion via deeply synergistic image and feature alignment formedical image segmentation.IEEE transactions on medicalimaging, 39(7):2494–2505, 2020. 2
[6] Yun-Chun Chen, Yen-Yu Lin, Ming-Hsuan Yang, and Jia-Bin Huang. Crdoco: Pixel-level domain transfer with cross-domain consistency. InProceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, pages1791–1800, 2019. 1, 2
[7] Qi Dou, Daniel Coelho de Castro, Konstantinos Kamnitsas,and Ben Glocker. Domain generalization via model-agnosticlearning of semantic features.Advances in Neural Informa-tion Processing Systems, 32:6450–6461, 2019. 3
[8] Yingjun Du, Jun Xu, Huan Xiong, Qiang Qiu, XiantongZhen, Cees GM Snoek, and Ling Shao. Learning to learnwith variational information bottleneck for domain general-ization. InEuropean Conference on Computer Vision, pages200–216, 2020. 3
[9] Xinjie Fan, Qifei Wang, Junjie Ke, Feng Yang, BoqingGong, and Mingyuan Zhou. Adversarially adaptive normal-ization for single domain generalization. InProceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition, pages 8208–8217, 2021. 3
[10] Muhammad Ghifary, W Bastiaan Kleijn, Mengjie Zhang,and David Balduzzi. Domain generalization for object recog-nition with multi-task autoencoders. InProceedings of theIEEE international conference on computer vision, pages2551–2559, 2015. 3
[11] Rui Gong, Wen Li, Yuhua Chen, and Luc Van Gool. Dlow:Domain flow for adaptation and generalization. InProceed-ings of the IEEE/CVF Conference on Computer Vision andPattern Recognition, pages 2477–2486, 2019. 3
[12] Yunye Gong, Xiao Lin, Yi Yao, Thomas G. Dietterich, AjayDivakaran, and Melinda Gervasio. Confidence calibrationfor domain generalization under covariate shift. InProceed-ings of the IEEE/CVF International Conference on Com-puter Vision, pages 8958–8967, October 2021. 3
[13] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, TorstenHoefler, and Daniel Soudry. Augment your batch: Improvinggeneralization through instance repetition. InProceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition, pages 8129–8138, 2020. 3
[14] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu,Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell.Cycada: Cycle-consistent adversarial domain adaptation. InInternational conference on machine learning, pages 1989–1998, 2018. 1, 2
[15] Yen-Chang Hsu, Zhaoyang Lv, and Zsolt Kira. Learning tocluster in order to transfer across domains and tasks.arXivpreprint arXiv:1711.10125, 2017. 3
[16] Sergey Ioffe and Christian Szegedy. Batch normalization:Accelerating deep network training by reducing internal co-variate shift. InInternational conference on machine learn-ing, pages 448–456, 2015. 4
[17] A Emre Kavur, N Sinem Gezer, Mustafa Barıs ̧, SinemAslan, Pierre-Henri Conze, Vladimir Groza, Duc Duy Pham,Soumick Chatterjee, Philipp Ernst, Savas ̧ ̈Ozkan, et al. Chaoschallenge-combined (ct-mr) healthy abdominal organ seg-mentation.Medical Image Analysis, 69:101950, 2021. 5
[18] B Landman, Z Xu, J Eugenio Igelsias, M Styner, T Langerak,and A Klein. Miccai multi-atlas labeling beyond the cranialvault–workshop and challenge. InProc. MICCAI: Multi-Atlas Labeling Beyond Cranial Vault-Workshop Challenge,2015. 5
[19] Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy MHospedales. Learning to generalize: Meta-learning for do-main generalization. InThirty-Second AAAI Conference onArtificial Intelligence, 2018. 3, 6, 7
[20] Da Li, Jianshu Zhang, Yongxin Yang, Cong Liu, Yi-ZheSong, and Timothy M Hospedales. Episodic training for do-main generalization. InProceedings of the IEEE/CVF Inter-national Conference on Computer Vision, pages 1446–1455,2019.
[21] Haoliang Li, Sinno Jialin Pan, Shiqi Wang, and Alex C Kot.Domain generalization with adversarial feature learning. InProceedings of the IEEE/CVF Conference on Computer Vi-sion and Pattern Recognition, pages 5400–5409, 2018. 3
[22] Xiaomeng Li, Hao Chen, Xiaojuan Qi, Qi Dou, Chi-Wing Fu, and Pheng-Ann Heng.H-denseunet: hybriddensely connected unet for liver and tumor segmentationfrom ct volumes.IEEE Transactions on Medical Imaging,37(12):2663–2674, 2018. 1
[23] Ya Li, Xinmei Tian, Mingming Gong, Yajing Liu, TongliangLiu, Kun Zhang, and Dacheng Tao. Deep domain gener-alization via conditional invariant adversarial networks. InProceedings of the European Conference on Computer Vi-sion (ECCV), pages 624–639, 2018. 3
[24] Yanghao Li, Naiyan Wang, Jianping Shi, Jiaying Liu, andXiaodi Hou. Revisiting batch normalization for practical do-main adaptation.arXiv preprint arXiv:1603.04779, 2016. 4
[25] Quande Liu, Cheng Chen, Jing Qin, Qi Dou, and Pheng-AnnHeng. Feddg: Federated domain generalization on medicalimage segmentation via episodic learning in continuous fre-quency space. InProceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition
[26] Quande Liu, Qi Dou, and Pheng-Ann Heng. Shape-awaremeta-learning for generalizing prostate mri segmentation tounseen domains.InInternational Conference on Medi-cal Image Computing and Computer-Assisted Intervention,pages 475–485, 2020. 2, 3
[27] Quande Liu, Qi Dou, Lequan Yu, and Pheng Ann Heng. Ms-net: Multi-site network for improving prostate segmentationwith heterogeneous mri data.IEEE Transactions on MedicalImaging, 2020. 2, 8
[28] Ziwei Liu, Zhongqi Miao, Xingang Pan, Xiaohang Zhan,Dahua Lin, Stella X Yu, and Boqing Gong. Open compounddomain adaptation. InProceedings of the IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, pages12406–12415, 2020. 2
[29] Bjoern H Menze, Andras Jakab, Stefan Bauer, JayashreeKalpathy-Cramer, Keyvan Farahani, Justin Kirby, YuliyaBurren, Nicole Porz, Johannes Slotboom, Roland Wiest,et al.The multimodal brain tumor image segmentationbenchmark (brats).IEEE transactions on medical imaging,34(10):1993–2024, 2014. 2, 5
[30] Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi.V-net: Fully convolutional neural networks for volumetricmedical image segmentation. In2016 fourth internationalconference on 3D vision (3DV), pages 565–571, 2016. 1
[31] Michael E Mortenson.Mathematics for computer graphicsapplications. Industrial Press Inc., 1999. 2, 4
[32] Saeid Motiian, Marco Piccirilli, Donald A Adjeroh, and Gi-anfranco Doretto. Unified deep supervised domain adapta-tion and generalization. InProceedings of the IEEE inter-national conference on computer vision, pages 5715–5725,2017. 3
[33] Xingang Pan, Ping Luo, Jianping Shi, and Xiaoou Tang. Twoat once: Enhancing learning and generalization capacitiesvia ibn-net. InEuropean Conference on Computer Vision,pages 464–479, 2018. 3, 6, 7
[34] Fengchun Qiao, Long Zhao, and Xi Peng.Learning tolearn single domain generalization. InProceedings of theIEEE/CVF Conference on Computer Vision and PatternRecognition, pages 12556–12565, 2020. 3
[35] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmen-tation. InInternational Conference on Medical image com-puting and computer-assisted intervention, pages 234–241,2015. 1, 6
[36] Mattia Segu, Alessio Tonioni, and Federico Tombari. Batchnormalization embeddings for deep domain generalization.arXiv preprint arXiv:2011.12672, 2020. 3, 5
[37] Seonguk Seo, Yumin Suh, Dongwan Kim, Geeho Kim, Jong-woo Han, and Bohyung Han. Learning to optimize domainspecific normalization for domain generalization. InCom-puter Vision–ECCV 2020: 16th European Conference, Glas-gow, UK, August 23–28, 2020, Proceedings, Part XXII 16,pages 68–83, 2020. 3, 6, 7
[38] Riccardo Volpi, Hongseok Namkoong, Ozan Sener, JohnDuchi, Vittorio Murino, and Silvio Savarese. Generalizing to unseen domains via adversarial data augmentation.arXivpreprint arXiv:1805.12018, 2018. 3
[39] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, MatthieuCord, and Patrick P ́erez. Advent: Adversarial entropy min-imization for domain adaptation in semantic segmentation.InProceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition, pages 2517–2526, 2019. 2
[40] Shujun Wang, Lequan Yu, Kang Li, Xin Yang, Chi-WingFu, and Pheng-Ann Heng. Dofe: Domain-oriented featureembedding for generalizable fundus image segmentation onunseen datasets.IEEE Transactions on Medical Imaging,39(12):4237–4248, 2020. 2, 3, 6, 7, 8
[41] Xiangyu Yue, Yang Zhang, Sicheng Zhao, AlbertoSangiovanni-Vincentelli,KurtKeutzer,andBoqingGong.Domain randomization and pyramid consistency:Simulation-to-real generalization without accessing targetdomain data. InProceedings of the IEEE/CVF InternationalConference on Computer Vision, pages 2100–2110, 2019. 3
[42] Sergey Zakharov, Wadim Kehl, and Slobodan Ilic. Decep-tionnet: Network-driven domain randomization. InProceed-ings of the IEEE/CVF International Conference on Com-puter Vision, pages 532–541, 2019. 3
[43] Ling Zhang, Xiaosong Wang, Dong Yang, Thomas Sanford,Stephanie Harmon, Baris Turkbey, Bradford J Wood, HolgerRoth, Andriy Myronenko, Daguang Xu, et al. Generalizingdeep learning for medical image segmentation to unseen do-mains via deep stacked transformation.IEEE transactionson medical imaging, 39(7):2531–2540, 2020. 3
[44] Yiheng Zhang, Zhaofan Qiu, Ting Yao, Dong Liu, and TaoMei. Fully convolutional adaptation networks for semanticsegmentation. InProceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition, pages 6810–6818, 2018. 1, 2
[45] Kaiyang Zhou, Yongxin Yang, Timothy Hospedales, and TaoXiang. Deep domain-adversarial image generation for do-main generalisation. InProceedings of the AAAI Conferenceon Artificial Intelligence, pages 13025–13032, 2020. 3
[46] Kaiyang Zhou, Yongxin Yang, Timothy Hospedales, and TaoXiang. Learning to generate novel domains for domain gen-eralization. InEuropean Conference on Computer Vision,pages 561–578, 2020. 3
[47] Zongwei Zhou, Vatsal Sodha, Md Mahfuzur Rahman Sid-diquee, Ruibin Feng, Nima Tajbakhsh, Michael B Gotway,and Jianming Liang. Models genesis: Generic autodidacticmodels for 3d medical image analysis. InInternational con-ference on medical image computing and computer-assistedintervention, pages 384–393, 2019. 4
[48] Xiahai Zhuang and Juan Shen. Multi-scale patch and multi-modality atlases for whole heart segmentation of mri.Medi-cal image analysis, 31:77–87, 2016. 5
[49] Danbing Zou, Qikui Zhu, and Pingkun Yan.Unsuper-vised domain adaptation with dual-scheme fusion networkfor medical image segmentation. InIJCAI, pages 3291–3298, 2020
以上是关于CVPR2022:Generalizable Cross-modality Medical Image Segmentation via StyleAugmentation and Dual Norm的主要内容,如果未能解决你的问题,请参考以下文章
CVPR2022 | CVPR2022最全整理,CVPR2022下载链接,CVPR2022全部论文代码
CVPR2022 | CVPR2022最全整理,CVPR2022下载链接,CVPR2022全部论文代码