神经网络的可解释性
Posted 上下求索.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络的可解释性相关的知识,希望对你有一定的参考价值。
第10章 神经网络的可解释性
以下各章重点介绍神经网络的解释方法。这些方法可视化了神经网络学到的特征和概念,解释了各个预测并简化了神经网络。
深度学习非常成功,尤其是在涉及图像和文本的任务中,例如图像分类和语言翻译。深度神经网络的成功事例始于2012年,当时通过深度学习方法赢得了ImageNet
图像分类挑
战
65
图像分类挑战^65
图像分类挑战65冠军。从那时起,我们见证了深度神经网络架构的寒武纪爆炸式增长,并且趋势是具有越来越多的权重参数的深度网络。
为了使用神经网络进行预测,数据输入将通过与学习的权重相乘的多层乘法进行传递,并经过非线性变换。根据神经网络的架构,单个预测可能涉及数百万个数学运算。我们人类不可能完全遵循从数据输入到预测的精确映射。我们必须考虑数百万个以复杂方式相互作用的权重,才能理解神经网络的预测。为了解释神经网络的行为和预测,我们需要特定的解释方法。本章假定您熟悉深度学习,包括卷积神经网络。
下一章涵盖以下主题:
- 特征可视化:神经网络学到了什么特征?
- “基于示例的解释”一章中的对抗性例子与特征可视化密切相关:我们如何操纵输入以得到错误的分类?
- 概念(进行中):神经网络学到了哪些更抽象的概念?
- 特征归因(进行中):每个输入如何有助于特定的预测?
- 模型蒸馏(进行中):我们如何用简单的模型解释神经网络?
10.1 学习的特征
卷积神经网络从原始图像像素中学习抽象特征和概念。特征可视化就是通过可视化学习到特征的最大化激活值来实现。网络结构分解就是按照人类的概念将神经网络单元(例如,通道)贴上标签。
深度神经网络最大的优势之一是在隐藏层中学习高级特征,这减少了对特性工程的需求。假设您希望使用支持向量机构建一个图像分类器。原始图像像素矩阵并不是训练SVM的最佳输入,因此您需要根据颜色、频域、边缘检测器等创建新的特征。使用卷积神经网络,将原始图像(像素)输入网络,然后将图像变换多次。首先,图像要经过许多卷积层,在这些卷积层中,网络学习新的和越来越复杂的特征。然后将变换后的图像信息通过全连接层进行分类或预测。

图10.1:训练在ImageNet数据上的卷积神经网络(InceptionV1)获得的特征。这些特征从低卷积层的简单特征(左)到高卷积层的抽象特征(右)。图像来自于 Olah, et al. 2017 (CC-BY 4.0)https://distill.pub/2017/feature-visualization/appendix/.
- 第一个卷积层学习边缘和简单纹理等特征。
- 之后的卷积层学习了更复杂的纹理和模式等特征。
- 最后的卷积层学习物体或物体的部分等特征。
- 全连接层学习将高级特性的激活连接到要预测的单个类。
这太酷了。但我们是如何获得这些充满幻觉的图像呢?
10.1.1特性可视化
将学习到的特征明晰化的方法称为特征可视化。神经网络中一个单元的特征可视化是通过寻找最大限度地激活该单元的输入来实现的。
“Units“是指单个神经元、通道(也称为特征图)、整个层或分类中的最终类别概率(或在做softmax操作前相应的神经元,更推荐这个定义)。单个神经元是网络的基础单元,因此我们可以通过为每个神经元创建特征可视化来获得最多的信息。但有一个问题:神经网络通常包含数百万个神经元。观察每个神经元的特征需要很长时间。通道(有时称为激活图)作为神经网络单元是特性可视化的良好选择。更进一步,我们可以可视化整个卷积层。层作为一个神经网络单元用于谷歌的DeepDream,它不断地将一个层的可视化特性添加到原始图像中,从而得到一个梦幻一样的输入。
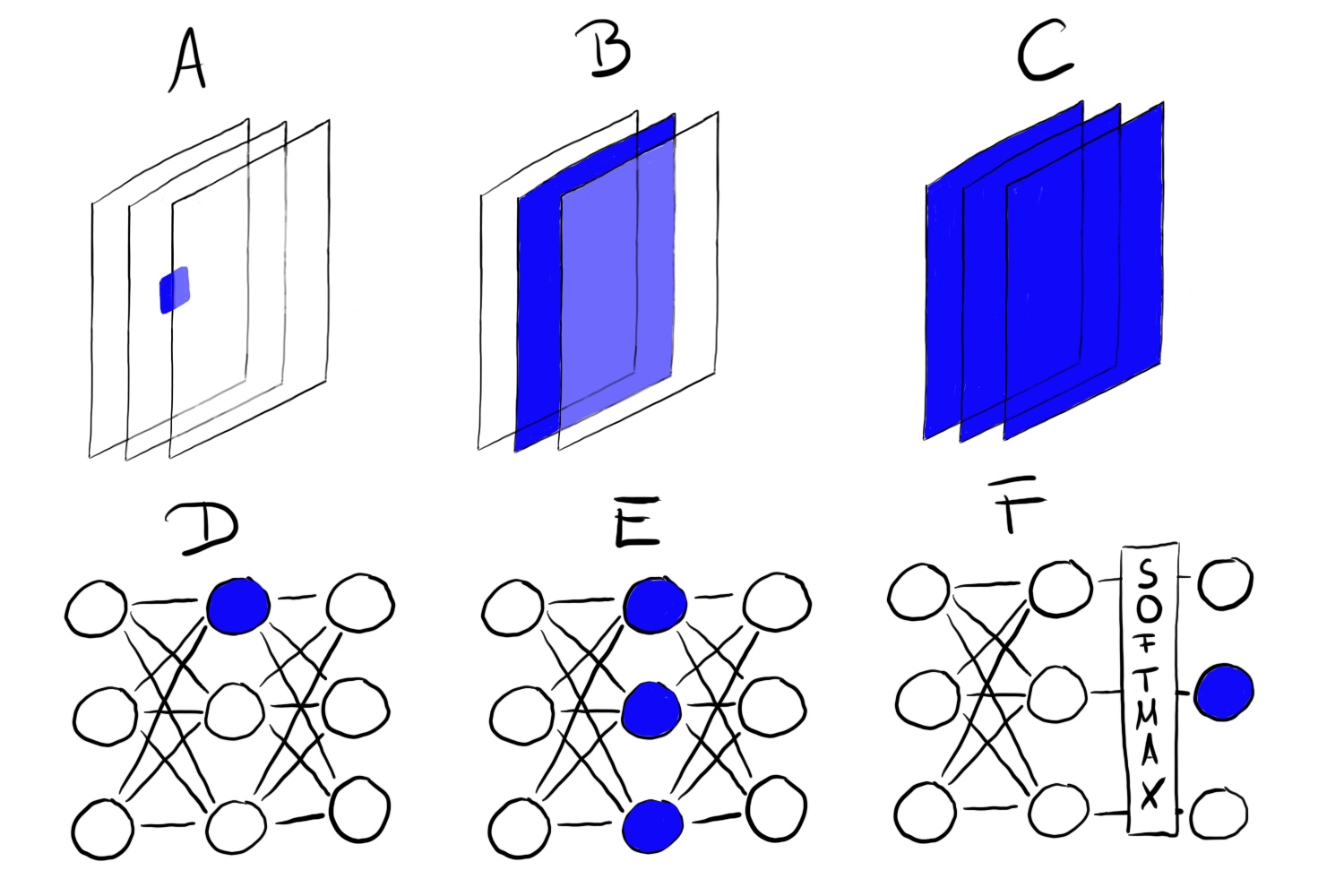
图10.2:可以对不同的神经网络单元进行特性可视化。A)卷积神经元,B)卷积通道,C)卷积层,D)神经元,E)隐层,F)类概率神经元(或在做softmax操作前相应的神经元)
10.1.1.1通过优化方法实现特征可视化
在数学上,特征可视化是一个优化问题。我们假设神经网络的权值是固定的,这意味着网络是经过训练的。我们正在寻找一种能使一个神经网络单元单元(这里是单个神经元)的(平均)激活最大化的新图像:

其中,函数h是神经元的激活,img是网络的输入(一幅图像),x和y描述神经元的空间位置,n表示层,z表示通道索引。对于n层整个通道z的平均激活,我们将其最大化下面公式:

在这个公式中,z通道中所有神经元的权重相等。或者,你也可以最大化随机方向,这意味着神经元会被不同的参数相乘,包括负方向。通过这种方式,我们研究了神经元是如何在通道内相互作用的。您也可以最小化激活(对应于最大化负方向),而不是最大化激活。有趣的是,当你将负方向最大化时,你会得到相同神经网络单元非常不同的特征:

图10.3:先启V1神经元484在混合4d前激活的阳性(左)和阴性(右)。当神经细胞被轮子最大限度地激活时,某些似乎有眼睛的东西却产生了负的激活。代码: https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/feature-visualization/negative_neurons.ipynb
我们可以用不同的方法来解决这个优化问题。首先,我们为什么要生成新图像?我们可以简单地在我们训练图像上搜索并选择那些激活值最大的。这是一种有效的方法,但使用训练数据存在这样的问题:图像上的元素可能相互关联,我们无法明白神经网络真正在寻找什么。如果图像的某一个特定并且出现了高激活值的通道出现了一只狗和一个网球,其实我们不知道神经网络是在看狗,看网球,还是两者都看。另一种方法是从随机噪声中开始生成新图像。为了获得有意义的可视化效果,通常对图像有一些限制,例如只允许进行微小的修改。为了减少特征可视化中的噪声,您可以在进行优化步骤之前对图像进行抖动、旋转或缩放处理。其他正则化选项包括频率惩罚(例如减少相邻像素的方差)或利用先验知识生成图像,例如使用
生成对抗网络
(
G
A
N
s
)
66
生成对抗网络(GANs)^66
生成对抗网络(GANs)66或
去噪自动编码
器
67
去噪自动编码器^67
去噪自动编码器67。

图10.4:从随机图像到最大化激活值的迭代优化。Olah等人2017 (CC-BY 4.0)https://distill.pub/2017/feature-visualization/.
如果您想更深入地研究特性可视化,请查看 distill.pub 的在线文章,特别是Olah等人的
可视化文
章
68
可视化文章^68
可视化文章68,我使用了其中的许多图像,还讨论了
利用可解释性构建块(
b
l
o
c
k
s
)
69
利用可解释性构建块(blocks)^69
利用可解释性构建块(blocks)69。
10.1.1.2与对抗性样本的联系
特征可视化和对抗性样本之间存在联系:这两种技术都最大化了神经网络单元的激活。对于对抗性样本,我们寻找对抗性的(或错误的)类别的神经元的最大激活值。其不同之处在于我们开始时的图像:对于对抗性的样本,我们希望为其生成对抗性的图像。对于特征可视化,根据方法不同,它可以是随机噪声等。
10.1.1.3文本和表格数据
文章的重点是特征可视化卷积神经网络用于图像识别。从技术上讲,没有什么可以阻止你找到最大限度地激活一个神经网络单元的输入,这个神经网络单元来自一个用于制表数据的全连接神经网络或一个用于文本数据的递归神经网络。您可能不再将其称为特征可视化,因为这里的特征是指是输入的表格数据或文本数据。对于信用违约预测,输入可能是先前信用的数量、移动合同的数量、地址和其他几十个特性。一个神经网络单元的学习特征将是几十个特征的某种组合。对于递归神经网络,它能更好地将所学习到的东西可视化:
K
a
r
p
a
t
h
y
等
(
2015
)
70
Karpathy等(2015)^70
Karpathy等(2015)70,发表的论文表明,递归神经网络确实具有学习可解释性特征的神经网络单元。作者训练了一个字符级模型,该模型可以从之前的字符中预测序列中的下一个字符。一旦一个开放括号”(“出现,其中一个神经网络单元会被高度激活,并在遇到对应匹配的关闭括号”)“时该神经网络单元则失效(关闭)。另一些神经元在一行的末端被激活。一些神经元在URLs中激活。CNNs特征可视化的不同之处在于,通过对训练数据中神经元的激活进行研究寻找对抗样本,而不是通过优化来寻找。
一些图片似乎展示了大家熟悉的一些概念,如狗鼻子或建筑物。但是我们怎么能确信呢? 该网络解剖方法可以将人类的概念与各个神经网络单元联系起来。需提前说明的是:网络解剖需要额外的数据集,而这些数据集已经被贴上了人类概念中的标签。
10.1.2网络解剖
Bau &Zhou 等人 ( 2017 ) 71 等人(2017)^71 等人(2017)71提出的网络解剖方法量化了卷积神经网络单元的可解释性。它将高度活跃的CNN通道区域与人类概念(物体、部件、纹理、颜色)联系了起来。卷积神经网络通道学习新的特征,正如我们在特征可视化一章中看到的。但是这些可视化并不能证明一个神经网络单元已经学会了某个的概念。我们也不知道如何测量,比如对于一个神经网络单元检测摩天大楼的效果。在我们深入研究网络解剖的细节之前,我们必须先谈谈这个研究方向背后的重大假设。假设是:神经网络单元(如卷积通道)学习了一些相互纠缠的概念。
无纠缠特征的问题
(卷积)神经网络是学习无纠缠的特征吗?无纠缠特征是指每一个网络单元都检测到一些特定的现实世界概念。卷积的第394个通道可能会检测到摩天大楼 ,第121个通道检测到狗的鼻子, 第12个通道检测30度角…。无纠缠网络的对立面是是一个完全相互纠缠的网络。例如,在一个完全相互缠结的网络中,不会有单独通道进行检测狗嘴。所有的通道都有助于识别狗的鼻子。
无纠缠特性意味着网络具有高度可解释性。假设我们有一个网络,其中的神经网络单元是完全分离的,这些单元用已知的概念来标记。这为跟踪网络的决策过程提供了可能性。例如,我们可以分析网络如何将狼与哈士奇犬分类。我们首先确定“哈士奇”神经网络单元,然后可以检查这个神经网络单元是否依赖于狗鼻子、绒毛和前一层的“snow”神经网络单元。如果确实这样,我们知道它会把背景是雪的哈士奇误认为是狼。在一个无纠缠网络中,我们可以识别出有问题的非因果关系。我们可以自动列出所有高度激活的神经网络单元和它们的概念来解释单个预测。我们可以很容易地检测到神经网络中的偏差。比如,网络是否可以通过学习白皮肤特征来预测工资?
提前说明:卷积神经网络并不是完全无纠缠的。现在,我们将更仔细地研究网络解剖,以找出如何解释神经网络。
10.1.2.1网络解剖算法
网络解剖有三个步骤:
1. 获取带有人类视觉概念的图像,从条纹到摩天大楼。
2. 对这些图像测量CNN通道激活值。
3. 量化激活值和被标记概念一致性。
下图显示了如何将图像前向传播到一个通道并与标被记的概念进行匹配。

图10.5:对于给定的输入图像和经过训练的网络(固定权值),我们将图像向前传播到目标层,提升激活度以匹配原始图像的大小,并将最大激活度与ground truth像素分割进行比较。数据来源于Bau & Zhou等人(2017)。
步骤1:Broden数据集
第一个困难但至关重要的步骤是数据收集。网络解剖需要使用不同抽象级别(从颜色到街景)概念的像素级标记好的图像。Bau&Zhou等人将一些数据集与像素级概念相结合。他们称这个新的数据集为“Broden”,意思是“广泛且密集标记的数据”。Broden数据集的分割大多是像素级的,对于某些数据集,整幅图像都是有标记的。Broden包含6万张图片,超过1000个不同抽象层次的视觉概念:468个场景,585个物体,234个部件,32种材料,47种纹理和11种颜色。下图显示了来自Broden数据集的示例图像。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cs517Q7v-1663003861722)(https://gitee.com/chiachenluo/chiachenluo.gitee.io/raw/master/images/broden.png)]
图10.6:来自Broden数据集的示例图像。数据来源于Bau & Zhou等人(2017)。
步骤2:检索网络激活
接下来,我们为每个通道和每个图像创建顶部激活区域的蒙版。此处,还没有涉及概念标签。
- 对于每一个卷积通道k:
- 对于Broden数据集中的每个图像x
- 将图像x前向传播到包含通道k的目标层
- 提取卷积通道k的每个像素的激活值:

- 计算像素激活值的分布
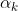
- 确定0.005分位数的水平,这意味着图像x的通道k中0.5%的像素激活值大于

- 对于Broden dataset数据集中的每一个数据x
- 将较低分辨率的激活图缩放(可能是)成原始图像x的分辨率,我们称之为

- 二值化像素激活图:像素要么是打开的(1)要么是关闭的(0),取决于它是否超过激活阈值,新的掩码为
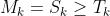
- 将较低分辨率的激活图
- 对于Broden数据集中的每个图像x
步骤3:激活-概念对齐
在第2步之后,我们为每个通道和图像设置一个激活掩码。这些激活掩模标记高度激活的区域。对于每个通道,我们都想找到激活该通道的人类概念。我们通过比较激活掩模和所有标记的概念来找到这个概念。我们量化了激活掩模k和概念掩模c之间的比对,并通过联合(IoU)分数的交集:

其中|.|是集合基数,对齐方式可以理解为比较两个区域之间并交集合操作. 可以解释为神经网络单元k检测概念c的精度。当
可以解释为神经网络单元k检测概念c的精度。当 ,我们将神经网络单元k称为概念c的检测器,此阈值由Bau&Zhou等人在论文中的选择.
,我们将神经网络单元k称为概念c的检测器,此阈值由Bau&Zhou等人在论文中的选择.
下图说明了单个图像的激活掩码和概念掩码的交集和结合:

图10.7:通过比较human ground truth标注和top activated pixels,计算出Union (IoU)上的交集。
下图显示了一个检测狗的神经网络单元:

图10.8:inception_4e通道750的激活掩码,该掩码检测带有IoU = 0.203. 图最初来自Bau&Zhou等(2017)。
10.1.2.2实验
网络解剖的作者从头开始在不同的数据集(ImageNet,Places205,Places365)上训练了不同的网络架构(AlexNet,VGG,GoogleNet,ResNet)。
ImageNet包含来自1000个专注于对象的类的160万张图像。Places205和Places365包含来自205/365个不同场景的240万/ 160万张图像。 他们还对AlexNet进行了自我监督训练任务的培训,例如预测视频帧对图像进行排序或着色。 对于其中许多不同的设置,他们计算了独特的概念检测器作为可解释性的度量。 这是一些发现:
- 网络在较低的层检测较低参差的概念(颜色,纹理),在较高的层检测较高层次的概念(零件,对象)。我们已经在 Feature Visualizations中看到了这一点。
批量标准化减少了独特概念检测器的数量。 - 许多神经网络单元都检测到相同的概念。例如,使用IoU≥0.04作为检测截止值(conv4_3中为4,conv5_3中为91,请参见项目网站)时,在ImageNet上训练的VGG中有95!个狗通道。
- 增加层中的通道数会增加可解释单位的数量。随机初始化(使用不同的随机种子进行训练)导致略有不同。
- 可解释单位的数量。
- ResNet是具有最多数量的唯一检测器的网络体系结构,其次最后是VGG,GoogleNet和AlexNet。
- Places356是学习到最多独特概念的检测器,其次是Places205和ImageNet。
- 独特概念的检测器的数量随训练迭代次数的增加而增加。

图10.9:在Places365上训练的ResNet是唯一具有最多数量的检测器。 随机权重的AlexNet是唯一具有最少数量的检测器,并将其用作基准。 图最初来自Bau&Zhou等.(2017)。
- 与在监督任务上训练的网络相比,在自监督任务上训练的网络具有较少的独特检测器。
- 在迁移学习中, 通道的概念可以改变。例如,一只狗探测器成为一个瀑布探测器。这发生在模型最初被训练用于分类一些物体,然后通过对网络微调对场景进行分类。
- 在其中一个实验中,作者将通道投射到一个新的旋转基础上。这是在ImageNet上训练出的VGG网络所做的。“旋转”并不意味着图像是旋转的。“旋转”意味着我们从 conv5 层获取 256 个通道,并计算新的 256 个通道作为原始通道的线性组合。在这个过程中,网络通道被相互缠住了。旋转减少了可解释性,也就是说,与概念对齐的通道数量减少了。旋转是为了保持模型的性能不变而设计的。第一个结论是:CNN的可解释性与轴有关。这意味着随机组合的通道不太可能发现独特的概念。第二个结论:可解释性与判别力无关。在判别力不变的情况下,信道可以通过正交变换进行变换,但可解释性降低。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3bbW0PiA-1663003861723)(https://gitee.com/chiachenluo/chiachenluo.gitee.io/raw/master/images/rotation-dissect.png)]
图10.10:独特的概念探测器的数量减少256渠道AlexNet conv5 ImageNet(训练)正逐渐改变了基础使用一个随机正交变换。图来自鲍起静
作者也用网络解剖生成对抗网络(GANs)。你可以找到网络解剖GANs的项目网站。
10.1.3 优点
特征可视化可以给予神经网络的工作以独特的洞察,特别是图像识别。鉴于神经网络的复杂性和不透明性,特征可视化是分析和描述神经网络的重要步骤。通过特征可视化,我们了解到神经网络首先学习简单的边缘和纹理检测器,然后在更高的层次上学习更抽象的部分和对象检测器。网络解剖扩展了这方面洞见,使网络单元的可解释性得以衡量。
网络解剖非常方便的让我们自动联系了神经网络单元和概念。
特征可视化是一个很好的表达工具以非技术的方式展示神经网络工作方式。
有了随网络解剖,我们也可以在分类任务中检测类别之外的概念。但是我们需要数据集包含像素级概念标记的图像。
特征可视化可以和特征归因方法结合,这就解释了哪些像素对于分类是重要的。这两种方法的结合实现了解释单独的分类任务以及在分类任务中涉及的学习到的特征局部可视化。参见The Building Blocks of Interpretability from distill.pub.。
最后,特征可视化生成了绚丽的桌面壁纸和T恤印花图案。
10.1.4 缺点
许多特征可视化图像根本无法解释,总之是包含了一些抽象的特征,我们对这些抽象特征没有任何言语或思维上的概念。可视化的特征和训练数据一起展示可以提供一些帮助。这些展示图片仍然不可能揭示神经网络反应原理,只能显示类似“也许有一些黄色的图片”之类的东西。即使有了网络解剖,一些通道仍然不能和人类的概念联系到一起。比如,在ImageNet上训练出的VGG网络,其中conv5_3层有193个通道(512通道)不能与一个人类的概念匹配上。
即使“仅仅”可视化通道激活,也有太多的神经网络单元不能看到。InceptionV1在9层卷积层已经有超过5000个通道。如果你也想要展示负激活加上一些训练数据图像,这些图像可以最大程度地或最小程度地激活通道(比如说4张正类的,4张负类的图像),那么你必须已经显示50000张图片。至少我们知道————多亏了网络解剖————我们不需要按照随机方向进行研究。
可解释性的错觉?特征可视化可以传达一种错觉,即好像我们了解神经网络在做什么。但我们真的理解神经网络发生了什么吗?即使我们看到成百上千的可视化特征,我们也无法弄明白神经网络。通道之间以复杂的方式进行相互作用,正向和负向激活是无关的,多个神经元可能学习非常相似的特征,并且对于许多特征,我们没有人类匹配的概念。我们绝不能仅仅因为我们看到第7层中的349神经元被雏菊这个概念激活而相信自己完全理解了神经网络。
网络解剖表明,诸如ResNet或Inception之类的架构具有的神经网络单元可以对某些概念做出反应。但是IoU并不是那么出色,通常许多神经网络单元会响应相同的概念,有些甚至根本没有响应。它们的通道并没有完全分解开,我们不能孤立地解释它们。
对于网络解剖,您需要使用概念在像素级别标记的数据集。 这些数据集需要花费大量的精力来收集,因为每个像素都需要标记,通常通过在图像上围绕对象绘制片段来解决。
网络解剖仅只将人的概念与积极的激活联系起来,而没有与消极的通道激活联系起来。 如特征可视化所示,负激活似乎与概念相关。这可以通过另外查看激活的较低位数来解决。
10.1.5 软件和其他材料
功能可视化的开源实现称为Lucid。 您可以使用Lucid Github页面上提供的笔记本链接在浏览器中方便地尝试它。 不需要其他软件。 其他实现包括用于TensorFlow的tf_cnnvis,用于Keras的Keras Filters和用于Caffe的DeepVis。
Network Dissection有一个很棒的项目网站。除了出版物,该网站还提供其他材料,例如代码,数据和激活掩码的可视化。
65.Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg and Li Fei-Fei. (* = equal contribution) ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015↩
66.Nguyen, Anh, et al. “Synthesizing the preferred inputs for neurons in neural networks via deep generator networks.” Advances in Neural Information Processing Systems. 2016.↩
67.Nguyen, Anh, et al. “Plug & play generative networks: Conditional iterative generation of images in latent space.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.↩
68.Olah, et al., “Feature Visualization”, Distill, 2017.↩
69.Olah, et al., “The Building Blocks of Interpretability”, Distill, 2018.↩
70.Karpathy, Andrej, Justin Johnson, and Li Fei-Fei. “Visualizing and understanding recurrent networks.” arXiv preprint arXiv:1506.02078 (2015).↩
71.Bau, David, et al. “Network dissection: Quantifying interpretability of deep visual representations.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.↩
以上是关于神经网络的可解释性的主要内容,如果未能解决你的问题,请参考以下文章