优雅实现延时任务之zookeeper篇
Posted TimeFriends
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优雅实现延时任务之zookeeper篇相关的知识,希望对你有一定的参考价值。
前言
在《优雅实现延时任务之Redis篇》一文中提到,实现延时任务的关键点,是要存储任务的描述和任务的执行时间,还要能根据任务执行时间进行排序,那么我们可不可以使用zookeeper来实现延时任务呢?答案当然是肯定的。要知道,zookeeper的znode同样可以用来存储数据,那么我们就可以利用这一点来实现延时任务。实际上,著名的zookeeper客户端curator就提供了基于zookeeper的延时任务API,今天就从源码的角度带大家了解下curator是如何使用zookeeper实现延时任务的。不过需要提前说明的是,使用zookeeper实现延时任务不是一个很好的选择,至少称不上优雅,标题中的优雅实现延时任务只是为了和前文呼应,关于使用zookeeper实现延时任务的弊端,后文我会详细解释。
上手curator
关于zookeeper的安装和使用这里就不介绍了,之前也推送过相关文章了,如果对zookeeper不了解的,可以翻下历史记录看下。接下来直接进入主题,首先来体验一把curator的延时任务API。
首先是任务消费者:
public class DelayTaskConsumer implements QueueConsumer<String>
@Override
public void consumeMessage(String message) throws Exception
System.out.println(MessageFormat.format("发布资讯。id - 0 , timeStamp - 1 , " +
"threadName - 2",message,System.currentTimeMillis(),Thread.currentThread().getName()));
@Override
public void stateChanged(CuratorFramework client, ConnectionState newState)
System.out.println(MessageFormat.format("State change . New State is - 0",newState));
curator的消费者需要实现QueueConsumer接口,在这里我们做的逻辑就是拿到任务描述(这里简单起见,任务描述就是资讯id),然后发布相应的资讯。
接下来看下任务生产者:
public class DelayTaskProducer
private static final String CONNECT_ADDRESS="study-machine:32783";
private static final int SESSION_OUTTIME = 5000;
private static final String NAMESPACE = "delayTask";
private static final String QUEUE_PATH = "/queue";
private static final String LOCK_PATH = "/lock";
private CuratorFramework curatorFramework;
private DistributedDelayQueue<String> delayQueue;
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 10);
curatorFramework= CuratorFrameworkFactory.builder().connectString(CONNECT_ADDRESS)
.sessionTimeoutMs(SESSION_OUTTIME).retryPolicy(retryPolicy)
.namespace(NAMESPACE).build();
curatorFramework.start();
delayQueue= QueueBuilder.builder(curatorFramework, new DelayTaskConsumer(),
new DelayTaskSerializer(), QUEUE_PATH).lockPath(LOCK_PATH).buildDelayQueue();
try
delayQueue.start();
catch (Exception e)
e.printStackTrace();
public void produce(String id,long timeStamp)
try
delayQueue.put(id,timeStamp);
catch (Exception e)
e.printStackTrace();
任务生产者主要有2个逻辑,一个是在构造代码块中初始化curator的延时任务队列,另一个是提供一个produce方法供外部往队列里放延时任务。
在初始化延时任务时,需要传入一个字节数组与任务描述实体之间的序列化器,这里简单地将任务描述处理成字符串:
public class DelayTaskSerializer implements QueueSerializer<String>
@Override
public byte[] serialize(String item)
return item.getBytes();
@Override
public String deserialize(byte[] bytes)
return new String(bytes);
最后写一个客户端测一下:
public class DelayTaskTest
public static void main(String[] args) throws Exception
DelayTaskProducer producer=new DelayTaskProducer();
long now=new Date().getTime();
System.out.println(MessageFormat.format("start time - 0",now));
producer.produce("1",now+TimeUnit.SECONDS.toMillis(5));
producer.produce("2",now+TimeUnit.SECONDS.toMillis(10));
producer.produce("3",now+TimeUnit.SECONDS.toMillis(15));
producer.produce("4",now+TimeUnit.SECONDS.toMillis(20));
producer.produce("5",now+TimeUnit.SECONDS.toMillis(2000));
TimeUnit.HOURS.sleep(1);
客户端比较简单,就是往延时队列里放5个任务,其中最后一个任务的执行时间比较晚,主要是为了观察curator到底往zookeeper里放了些啥。运行程序,结果如下:
接下来我们看下zookeeper里到底存了哪些信息:
[zk: localhost(CONNECTED) 2] ls /
[delayTask, zookeeper]
其中,zookeeper节点是zookeeper自带的,除了zookeeper之后,还有一个delayTask节点,这个节点就是我们在生产者里设置的命名空间NAMESPACE。因为同一个zookeeper集群可能会被用于不同的延时队列,NAMESPACE的作用就是用来区分不同延时队列的。再看看NAMESPACE里是啥:
[zk: localhost(CONNECTED) 3] ls /delayTask
[lock, queue]
可以看到,有2个子节点:lock跟queue,分别是我们在生产者中设置的分布式锁路径LOCK_PATH和队列路径QUEUE_PATH。因为同一个延时队列可能会被不同线程监听,所以为了保证任务只被一个线程执行,zookeeper在任务到期的时候需要申请到分布式锁后才能执行任务。接下来我们重点看下queue节点下有什么:
[zk: localhost(CONNECTED) 7] ls /delayTask/queue
[queue-|165B92FCD69|0000000014]
发现里面只有一个子节点,我们猜想应该就是我们刚刚放到延时队列里面的还未执行的任务,我们接着看看这个子节点下面还有没有子节点:
[zk: localhost(CONNECTED) 8] ls /delayTask/queue/queue-|165B92FCD69|0000000014
[]
发现没有了。
那我们就看看queue-|165B92FCD69|0000000014这个节点里面放了什么数据:
[zk: localhost(CONNECTED) 9] get /delayTask/queue/queue-|165B92FCD69|0000000014
5
cZxid = 0x3d
ctime = Sat Sep 08 12:20:41 GMT 2018
mZxid = 0x3d
mtime = Sat Sep 08 12:20:41 GMT 2018
pZxid = 0x3d
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 11
numChildren = 0
可以发现放的是任务描述,也就是资讯id——5。到这里我们就会知道了,zookeeper把任务描述放到了相应任务节点下了,那么任务执行时间放到哪里了呢?由于queue-|165B92FCD69|0000000014并没有子节点,所以我们可以猜想任务执行时间放在了节点名称上了。观察节点名称,queue只是一个前缀,没什么信息量。0000000014应该是节点序号(这里也可以猜测zookeeper用来存放任务的节点是顺序节点)。那么就只剩下165B92FCD69了,这个看上去并不像时间戳或者日期,但是里面有字母,可以猜测会不会是时间戳的十六进制表示。我们将其转化为十进制看下:
@Test
public void test()
long number = Long.parseLong("165B92FCD69", 16);
System.out.println(number);
System.out.println(new Date(number));
可以转化为十进制,然后将十进制数转化成日期,确实也是我们在一开始设置的任务执行时间。这样一来就大概清楚了curator是怎么利用zookeeper来存储延时任务的了:将任务执行时间存储在节点名称中,将任务描述存储在节点相应的数据中。
那么到底是不是这样的呢?接下来我们看下curator的源码就知道了。
curator源码解析
1.DistributedDelayQueue类
curator延时任务的入口就是DistributedDelayQueue类的start方法了。我们先不说start方法,先来看看DistributedDelayQueue类有哪些属性:
private final DistributedQueue<T> queue;
DistributedDelayQueue
(
CuratorFramework client,
QueueConsumer<T> consumer,
QueueSerializer<T> serializer,
String queuePath,
ThreadFactory threadFactory,
Executor executor,
int minItemsBeforeRefresh,
String lockPath,
int maxItems,
boolean putInBackground,
int finalFlushMs
)
Preconditions.checkArgument(minItemsBeforeRefresh >= 0, "minItemsBeforeRefresh cannot be negative");
queue = new DistributedQueue<T>
(
client,
consumer,
serializer,
queuePath,
threadFactory,
executor,
minItemsBeforeRefresh,
true,
lockPath,
maxItems,
putInBackground,
finalFlushMs
)
@Override
protected long getDelay(String itemNode)
return getDelay(itemNode, System.currentTimeMillis());
private long getDelay(String itemNode, long sortTime)
long epoch = getEpoch(itemNode);
return epoch - sortTime;
@Override
protected void sortChildren(List<String> children)
final long sortTime = System.currentTimeMillis();
Collections.sort
(
children,
new Comparator<String>()
@Override
public int compare(String o1, String o2)
long diff = getDelay(o1, sortTime) - getDelay(o2, sortTime);
return (diff < 0) ? -1 : ((diff > 0) ? 1 : 0);
);
;
这里截取一部分代码出来。实际上DistributedDelayQueue里只有一个queue属性,queue属性是DistributedQueue类的实例,从名字可以看到其是一个分布式队列。不过DistributedDelayQueue里的queue比较特殊,其是DistributedQueue类的匿名内部类的实例,这个匿名子类重写了DistributedQueue的部分方法,如:getDelay、sortChildren等。这一点很重要,后面的代码会用到这2个方法。
2.DistributedDelayQueue的入口start方法
接下来我们就来看下DistributedDelayQueue的入口start方法:
/**
* Start the queue. No other methods work until this is called
*
* @throws Exception startup errors
*/
@Override
public void start() throws Exception
queue.start();
可以看到,其调用的是queue的start方法。我们跟进去看看:
@Override
public void start() throws Exception
if ( !state.compareAndSet(State.LATENT, State.STARTED) )
throw new IllegalStateException();
try
client.create().creatingParentContainersIfNeeded().forPath(queuePath);
catch ( KeeperException.NodeExistsException ignore )
// this is OK
if ( lockPath != null )
try
client.create().creatingParentContainersIfNeeded().forPath(lockPath);
catch ( KeeperException.NodeExistsException ignore )
// this is OK
if ( !isProducerOnly || (maxItems != QueueBuilder.NOT_SET) )
childrenCache.start();
if ( !isProducerOnly )
service.submit
(
new Callable<Object>()
@Override
public Object call()
runLoop();
return null;
);
这个方法首先是检查状态,然后创建一些必须的节点,如前面的queue节点和lock节点就是在这里创建的。
由于我们创建queue的时候有传入了消费者,所以这里isProducerOnly为true,故以下2个分支的代码都会执行:
if ( !isProducerOnly || (maxItems != QueueBuilder.NOT_SET) )
childrenCache.start();
if ( !isProducerOnly )
service.submit
(
new Callable<Object>()
@Override
public Object call()
runLoop();
return null;
);
2.1.childrenCache.start()
先来看看第一个分支:
childrenCache.start();
从名字上看,这个childrenCache应该是子节点的缓存,我们进到start方法里看看:
void start() throws Exception
sync(true);
调的是sync方法,我们跟进去看看:
private synchronized void sync(boolean watched) throws Exception
if ( watched )
client.getChildren().usingWatcher(watcher).inBackground(callback).forPath(path);
else
client.getChildren().inBackground(callback).forPath(path);
这里watched为true,所以会走第一个分支。第一个分支代码的作用是在后台去拿path路径下的子节点,这里的path就是我们配置的queue_path。拿到子节点后,会调用callback里的回调方法。我们看下这里的callback做了什么:
private final BackgroundCallback callback = new BackgroundCallback()
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception
if ( event.getResultCode() == KeeperException.Code.OK.intValue() )
setNewChildren(event.getChildren());
;
可以看到,当有子节点时,会去调用setNewChildren方法。我们继续跟进去:
private synchronized void setNewChildren(List<String> newChildren)
if ( newChildren != null )
Data currentData = children.get();
children.set(new Data(newChildren, currentData.version + 1));
notifyFromCallback();
这里就是把子节点放到缓存里,并调用notifyFromCallback方法:
private synchronized void notifyFromCallback()
notifyAll();
这里就是唤醒所有等待线程。既然有唤醒,那么就一定有等待。继续看ChildrenCache类的其他方法,发现在blockingNextGetData方法中,调用了wait方法:
synchronized Data blockingNextGetData(long startVersion, long maxWait, TimeUnit unit) throws InterruptedException
long startMs = System.currentTimeMillis();
boolean hasMaxWait = (unit != null);
long maxWaitMs = hasMaxWait ? unit.toMillis(maxWait) : -1;
while ( startVersion == children.get().version )
if ( hasMaxWait )
long elapsedMs = System.currentTimeMillis() - startMs;
long thisWaitMs = maxWaitMs - elapsedMs;
if ( thisWaitMs <= 0 )
break;
wait(thisWaitMs);
else
wait();
return children.get();
当blockingNextGetData方法被调用时,会先睡眠,当有子节点到来时,等待线程才会被唤醒,进而返回当前的子节点。这个blockingNextGetData方法后面还会看到。
2.2.runLoop方法
接下来我们看下start方法的最后一段代码:
service.submit
(
new Callable<Object>()
@Override
public Object call()
runLoop();
return null;
);
这段代码主要是向线程池提交了一个Callable,主要逻辑是runLoop方法。我们进到runLoop方法里看看:
private void runLoop()
long currentVersion = -1;
long maxWaitMs = -1;
try
while ( state.get() == State.STARTED )
try
ChildrenCache.Data data = (maxWaitMs > 0) ? childrenCache.blockingNextGetData(currentVersion, maxWaitMs, TimeUnit.MILLISECONDS) : childrenCache.blockingNextGetData(currentVersion);
currentVersion = data.version;
List<String> children = Lists.newArrayList(data.children);
sortChildren(children); // makes sure items are processed in the correct order
if ( children.size() > 0 )
maxWaitMs = getDelay(children.get(0));
if ( maxWaitMs > 0 )
continue;
else
continue;
processChildren(children, currentVersion);
catch ( InterruptedException e )
// swallow the interrupt as it's only possible from either a background
// operation and, thus, doesn't apply to this loop or the instance
// is being closed in which case the while test will get it
catch ( Exception e )
log.error("Exception caught in background handler", e);
可以看到,runLoop方法就是一个死循环,只要与服务器的状态一直是STARTED,这个循环就不会退出。
首先看这句代码:
ChildrenCache.Data data = (maxWaitMs > 0) ?
childrenCache.blockingNextGetData(currentVersion, maxWaitMs, TimeUnit.MILLISECONDS) :
childrenCache.blockingNextGetData(currentVersion);
这行代码比较长,我把他拆成多行了。这句代码主要是去获取子节点,前面说了,当调用blockingNextGetData方法时,会先等待,直到有新的子节点时,才会调用notifyAll唤醒等待线程。
拿到子节点后就对子节点列表进行排序:
sortChildren(children); // makes sure items are processed in the correct order
sortChildren方法是DistributedQueue类的方法,在一开始分析DistributedDelayQueue类的时候说到,DistributedDelayQueue类中的queue是一个匿名内部类实例,其重写了getDelay和sortChildren等方法,因此我们要看经过重写的getDelay和sortChildren是怎样的,由于sortChildren方法依赖getDelay方法,因此我们先看看getDelay方法:
@Override
protected long getDelay(String itemNode)
return getDelay(itemNode, System.currentTimeMillis());
其会去调用getDelay私有方法,同时传入当前时间戳:
private long getDelay(String itemNode, long sortTime)
long epoch = getEpoch(itemNode);
return epoch - sortTime;
getDelay私有方法又会去调用getEpoch方法:
private static long getEpoch(String itemNode)
int index2 = itemNode.lastIndexOf(SEPARATOR);
int index1 = (index2 > 0) ? itemNode.lastIndexOf(SEPARATOR, index2 - 1) : -1;
if ( (index1 > 0) && (index2 > (index1 + 1)) )
try
String epochStr = itemNode.substring(index1 + 1, index2);
return Long.parseLong(epochStr, 16);
catch ( NumberFormatException ignore )
// ignore
return 0;
getEpoch方法其实就是去解析子节点名称的,前面带大家看了zookeeper队列路径下的子节点名称,是这种形式的:queue-|165B92FCD69|0000000014。这个方法的作用就是将其中的任务执行的时间戳给解析出来,也就是中间的那段字符串。拿到字符串后再将十六进制转化为十进制:
Long.parseLong(epochStr, 16);
这样验证了我们之前的猜想:curator会把任务执行时间编码成十六进制放到节点名称里。至于为什么要编码成十六进制,个人认为应该是为了节省字符串长度。
我们再回到私有方法getDelay:
private long getDelay(String itemNode, long sortTime)
long epoch = getEpoch(itemNode);
return epoch - sortTime;
拿到延时任务执行时间戳后,再跟当前时间戳相减,得出任务执行时间戳跟当前时间戳的差值,这个差值决定了这个任务要不要立即执行,如果说这个差值小于或等于0,说明任务已经到了执行时间,那么就会执行相应的任务。当然这个差值还有一个用途,就是用于排序,具体在sortChildren方法里面:
@Override
protected void sortChildren(List<String> children)
final long sortTime = System.currentTimeMillis();
Collections.sort
(
children,
new Comparator<String>()
@Override
public int compare(String o1, String o2)
long diff = getDelay(o1, sortTime) - getDelay(o2, sortTime);
return (diff < 0) ? -1 : ((diff > 0) ? 1 : 0);
);
这个sortChildren方法是经过重写了的匿名内部类的方法,其根据任务执行时间与当前时间戳的差值进行排序,越早执行的任务排在前面,这样就可以保证延时任务是按执行时间从早到晚排序的了。
分析完了getDelay和sortChildren,我们再回到runLoop方法:
ChildrenCache.Data data = (maxWaitMs > 0) ? childrenCache.blockingNextGetData(currentVersion, maxWaitMs, TimeUnit.MILLISECONDS) : childrenCache.blockingNextGetData(currentVersion);
currentVersion = data.version;
List<String> children = Lists.newArrayList(data.children);
sortChildren(children); // makes sure items are processed in the correct order
if ( children.size() > 0 )
maxWaitMs = getDelay(children.get(0));
if ( maxWaitMs > 0 )
continue;
else
continue;
processChildren(children, currentVersion);
在对子节点按执行时间进行升序排序后,会先拿到排在最前面的子节点,判断该子节点的执行时间与当前时间戳的差值是否小于0,如果小于0,则说明到了执行时间,那么就会调用下面这行代码:
processChildren(children, currentVersion);
我们跟进去看看:
private void processChildren(List<String> children, long currentVersion) throws Exception
final Semaphore processedLatch = new Semaphore(0);
final boolean isUsingLockSafety = (lockPath != null);
int min = minItemsBeforeRefresh;
for ( final String itemNode : children )
if ( Thread.currentThread().isInterrupted() )
processedLatch.release(children.size());
break;
if ( !itemNode.startsWith(QUEUE_ITEM_NAME) )
log.warn("Foreign node in queue path: " + itemNode);
processedLatch.release();
continue;
if ( min-- <= 0 )
if ( refreshOnWatch && (currentVersion != childrenCache.getData().version) )
processedLatch.release(children.size());
break;
if ( getDelay(itemNode) > 0 )
processedLatch.release();
continue;
executor.execute
(
new Runnable()
@Override
public void run()
try
if ( isUsingLockSafety )
processWithLockSafety(itemNode, ProcessType.NORMAL);
else
processNormally(itemNode, ProcessType.NORMAL);
catch ( Exception e )
ThreadUtils.checkInterrupted(e);
log.error("Error processing message at " + itemNode, e);
finally
processedLatch.release();
);
processedLatch.acquire(children.size());
这里用信号量Semaphore保证了只有当所有子节点都被遍历并处理了或者线程被中断了,这个方法才会返回。如果这段程序是单线程执行的,那么不需要使用信号量也能做到这一点。但是大家看代码就知道,这个方法在执行到期的延时任务的时候是放到线程池里面执行的,所以才需要使用信号量来保证当所有任务被遍历并处理了,这个方法才返回。
我们重点关注延时任务的执行部分:
executor.execute
(
new Runnable()
@Override
public void run()
try
if ( isUsingLockSafety )
processWithLockSafety(itemNode, ProcessType.NORMAL);
else
processNormally(itemNode, ProcessType.NORMAL);
catch ( Exception e )
ThreadUtils.checkInterrupted(e);
log.error("Error processing message at " + itemNode, e);
finally
processedLatch.release();
);
由于我们在初始化延时队列的时候传入了lockPath ,所以实际上会走到下面这个分支:
processWithLockSafety(itemNode, ProcessType.NORMAL);
从方法名可以看到,这个方式是使用锁的方式来处理延时任务。这里顺便提一句,好的代码是自解释的,我们仅仅看方法名就可以大概知道这个方法是做什么的,这一点大家平时在写代码的时候要时刻牢记,因为我在公司的老系统上已经看到不少method1、method2之类的方法命名了。这里略去1万字……
我们进到processWithLockSafety方法里面去:
@VisibleForTesting
protected boolean processWithLockSafety(String itemNode, ProcessType type) throws Exception
String lockNodePath = ZKPaths.makePath(lockPath, itemNode);
boolean lockCreated = false;
try
client.create().withMode(CreateMode.EPHEMERAL).forPath(lockNodePath);
lockCreated = true;
String itemPath = ZKPaths.makePath(queuePath, itemNode);
boolean requeue = false;
byte[] bytes = null;
if ( type == ProcessType.NORMAL )
bytes = client.getData().forPath(itemPath);
requeue = (processMessageBytes(itemNode, bytes) == ProcessMessageBytesCode.REQUEUE);
if ( requeue )
client.inTransaction()
.delete().forPath(itemPath)
.and()
.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(makeRequeueItemPath(itemPath), bytes)
.and()
.commit();
else
client.delete().forPath(itemPath);
return true;
catch ( KeeperException.NodeExistsException ignore )
// another process got it
catch ( KeeperException.NoNodeException ignore )
// another process got it
catch ( KeeperException.BadVersionException ignore )
// another process got it
finally
if ( lockCreated )
client.delete().guaranteed().forPath(lockNodePath);
return false;
这个方法首先会申请分布式锁:
client.create().withMode(CreateMode.EPHEMERAL).forPath(lockNodePath);
这里申请锁是通过创建临时节点的方式实现的,一个任务只对应一个节点,所以只有一个zk客户端能够创建成功,也就是说只有一个客户端可以拿到锁。
拿到锁后就是处理任务了,最后在finally块中释放分布式锁。
我们重点看下处理任务那一块:
requeue = (processMessageBytes(itemNode, bytes) == ProcessMessageBytesCode.REQUEUE);
我们进到processMessageBytes里面去:
private ProcessMessageBytesCode processMessageBytes(String itemNode, byte[] bytes) throws Exception
ProcessMessageBytesCode resultCode = ProcessMessageBytesCode.NORMAL;
MultiItem<T> items;
try
items = ItemSerializer.deserialize(bytes, serializer);
catch ( Throwable e )
ThreadUtils.checkInterrupted(e);
log.error("Corrupted queue item: " + itemNode, e);
return resultCode;
for(;;)
T item = items.nextItem();
if ( item == null )
break;
try
consumer.consumeMessage(item);
catch ( Throwable e )
ThreadUtils.checkInterrupted(e);
log.error("Exception processing queue item: " + itemNode, e);
if ( errorMode.get() == ErrorMode.REQUEUE )
resultCode = ProcessMessageBytesCode.REQUEUE;
break;
return resultCode;
千呼万唤始出来,总算看到任务消费的代码了:
consumer.consumeMessage(item);
这里的consumer就是我们初始化延时任务队列时传入的任务消费者了。到这里curator延时任务的处理逻辑就全部讲完了。其他细节大家可以自己去看下源码,这里就不细讲了。
总结
这里简单回顾下curator实现延时任务的逻辑:首先在生产任务的时候,将所有任务都放到同一个节点下面,其中任务执行时间放到子节点的名称中,任务描述放到子节点的data中。后台会有一个线程去扫相应队列节点下的所有子节点,客户端拿到这些子节点后会将执行时间和任务描述解析出来,再按任务执行时间从早到晚排序,再依次处理到期的任务,处理完再删除相应的子节点。这就是curator处理延时任务的大致流程了。
前面说了,curator实现延时任务不是很优雅,具体不优雅在哪里呢?首先,curator对任务执行时间的排序不是在zookeeper服务端完成的,而是在客户端进行,假如说有人一次性往zookeeper里放了100万个延时任务,那么curator也会全部拿到客户端进行排序,这在任务数多的时候肯定是有问题的。再者,zookeeper的主要用途不是用于存储的,他不像mysql或者Redis一样,被设计成存储系统,zookeeper更多地是作为分布式协调系统,存储不是他的强项,所以如果你要存储的延时任务很多,用zookeeper来做也是不合适的。
之所以花了这么大的篇幅来介绍curator如何利用zookeeper来实现延时任务,是为了告诉大家,不是只要有轮子就可以直接拿来用的,如果不关心轮子是怎么实现的,那有一天出了问题就无从下手了。
resultCode = ProcessMessageBytesCode.REQUEUE;
break;
return resultCode;
千呼万唤始出来,总算看到任务消费的代码了:
consumer.consumeMessage(item);
这里的consumer就是我们初始化延时任务队列时传入的任务消费者了。到这里curator延时任务的处理逻辑就全部讲完了。其他细节大家可以自己去看下源码,这里就不细讲了。
总结
这里简单回顾下curator实现延时任务的逻辑:首先在生产任务的时候,将所有任务都放到同一个节点下面,其中任务执行时间放到子节点的名称中,任务描述放到子节点的data中。后台会有一个线程去扫相应队列节点下的所有子节点,客户端拿到这些子节点后会将执行时间和任务描述解析出来,再按任务执行时间从早到晚排序,再依次处理到期的任务,处理完再删除相应的子节点。这就是curator处理延时任务的大致流程了。
前面说了,curator实现延时任务不是很优雅,具体不优雅在哪里呢?首先,curator对任务执行时间的排序不是在zookeeper服务端完成的,而是在客户端进行,假如说有人一次性往zookeeper里放了100万个延时任务,那么curator也会全部拿到客户端进行排序,这在任务数多的时候肯定是有问题的。再者,zookeeper的主要用途不是用于存储的,他不像MySQL或者Redis一样,被设计成存储系统,zookeeper更多地是作为分布式协调系统,存储不是他的强项,所以如果你要存储的延时任务很多,用zookeeper来做也是不合适的。
之所以花了这么大的篇幅来介绍curator如何利用zookeeper来实现延时任务,是为了告诉大家,不是只要有轮子就可以直接拿来用的,如果不关心轮子是怎么实现的,那有一天出了问题就无从下手了。
关于延时任务之zookeeper,你学废了么?
真诚地邀请您加入我们的大家庭.
在这里不仅有技术知识分享,还有博主们之间的互帮互助
不定期发红包,每月更有抽奖环节,游戏机和实体书相赠(包邮)
让我们抱团取暖,抱团内卷.打造美好C站.期待您的加入.
备注 : CSDN-xxxxxx (xxxxxx代表你csdn的昵称)
PHP7之Reids键空间通知配合TP5 实现分布式延时任务
源 / php中文网 源 / www.php.cn
本篇文章主要给大家介绍Reids 键空间通知配合TP5 实现分布式延时任务,希望对需要的朋友有所帮助!
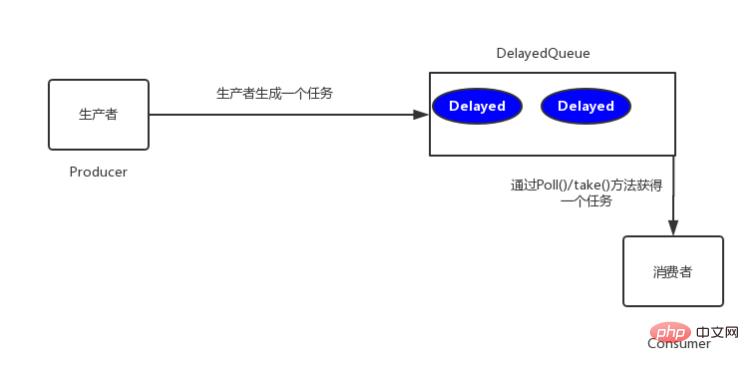
(查看原文请点击本文末尾左下角:阅读原文)
测试环境:windows 10 + phpStudy
配置redis配置文件 redis.windows.conf
notify-keyspace-events "Ex"
重启redis服务
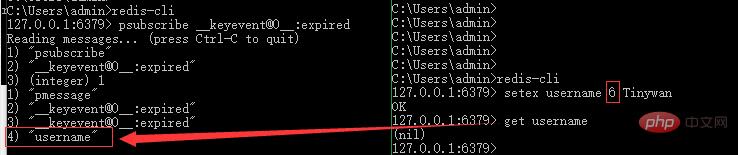
psubscribe __keyevent@0__:expired
打开新窗口执行了阻塞订阅操作后的终端,等会会有信息输出:
C:Usersadmin>redis-cli
127.0.0.1:6379> psubscribe __keyevent@0__:expired
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "__keyevent@0__:expired"
3) (integer) 1
再开启一个终端,redis-cli 进入 redis,新增一个 6秒过期的键 username:
命令行完成了
二、借助TP5.1 的命令行工具
命令行工具的使用:
https://www.kancloud.cn/manual/thinkphp5_1/354146
1、新建命令行pay
<?php
/**.-------------------------------------------------------------------------------------------------------------------
* | Github: https://github.com/Tinywan
* '------------------------------------------------------------------------------------------------------------------*/
namespace appcommoncommand;
use apppayserviceRedisSubscribe;
use thinkconsoleCommand;
use thinkconsoleInput;
use thinkconsoleinputArgument;
use thinkconsoleOutput;
class Pay extends Command
{
// 配置指令
public function configure()
{
$this->setName('pay')
->addArgument('type', Argument::REQUIRED, "the type of the task that pay needs to run")
->setDescription('this is payment system command line tools');
}
// 执行指令
public function execute(Input $input, Output $output)
{
$type = $input->getArgument('type');
if ($type == 'psubscribe') {
// 发布订阅任务
$this->psubscribe();
}
}
/**
* Redis 发布订阅模式
*/
private function psubscribe()
{
$service = new RedisSubscribe();
$service->sub();
}
}
2、编写脚本 RedisSubscribe.php
<?php
/**.-------------------------------------------------------------------------------------------------------------------
* | Github: https://github.com/Tinywan
* '------------------------------------------------------------------------------------------------------------------*/
namespace apppayservice;
use redisBaseRedis;
use thinkfacadeLog;
class RedisSubscribe
{
public function sub()
{
Log::error(get_current_date().'--过期事件的订阅-- ');
$redis = BaseRedis::location(); //这里是直接连接本地redis
$redis->setOption(Redis::OPT_READ_TIMEOUT, -1);
$redis->psubscribe(array('__keyevent@0__:expired'), function ($redis, $pattern, $chan, $msg) {
Log::error('[1]--过期事件的订阅 ' . $msg);
});
}
}
说明:
psubscribe( patterns,patterns,callback ) 方法的第二个参数为一个回调函数,这里我使用闭包作为一个回调。
官方解释:
匿名函数(Anonymous functions),也叫闭包函数(closures),允许 临时创建一个没有指定名称的函数。最经常用作回调函数(callback)参数的值。当然,也有其它应用的情况。
3、在TP5 项目根目录执行pay 命令工具
php think pay psubscribe
4、新打开console 窗口终端
C:Usersadmin>redis-cli
127.0.0.1:6379> setex UserName 10 Tinywan
OK
127.0.0.1:6379> get UserName
"Tinywan"
127.0.0.1:6379> get UserName
(nil)
127.0.0.1:6379>
5、查看打日志文件,看有没有接收到过期的key
更高级的慢慢扩展
1、自动取消订单
2、订单完成后发送短信
3、延迟任务等等
-END-
声明:本文选自「 php中文网 」,搜索「 phpcnnew 」即可关注!
▼请点击下方:“阅读原文”,在线查看全部文章内容!
以上是关于优雅实现延时任务之zookeeper篇的主要内容,如果未能解决你的问题,请参考以下文章
PHP7之Reids键空间通知配合TP5 实现分布式延时任务
精华推荐 |算法数据结构专题「延时队列算法」史上非常详细分析和介绍如何通过时间轮(TimingWheel)实现延时队列的原理指南