论文精读COLING 2022-KiPT: Knowledge-injected Prompt Tuning for Event Detection
Posted Trouble..
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文精读COLING 2022-KiPT: Knowledge-injected Prompt Tuning for Event Detection相关的知识,希望对你有一定的参考价值。
【论文精读】COLING 2022-KiPT: Knowledge-injected Prompt Tuning for Event Detection
【论文原文】:KiPT: Knowledge-injected Prompt Tuning for Event Detection
【作者信息】:Li, Haochen and Mo, Tong and Fan, Hongcheng and Wang, Jingkun and Wang, Jiaxi and Zhang, Fuhao and Li, Weiping
论文:https://aclanthology.org/2022.coling-1.169.pdf
代码:未开源
博主关键词:知识注入,提示学习,事件检测
推荐相关论文:无

摘要
事件检测旨在通过识别和分类事件触发词(最具代表性的单词)来从文本中检测事件。现有的大部分工作严重依赖复杂的下游网络,需要足够的训练数据。因此,这些模型在结构上可能是冗余的,并且在数据稀缺时表现不佳。基于提示的模型很容易构建,并且很有希望完成少样本任务。然而,目前基于提示的方法由于没有引入事件相关的语义知识(如词性、语义相关性等),可能存在精度不高的问题。为了解决这些问题,本文提出了一种知识注入的提示调优模型。具体来说,事件检测任务被表述为条件生成任务。然后,利用外部知识库构建知识注入提示,并利用提示调优策略对提示进行优化。大量实验表明,KiPT优于强基线,特别是在少样本场景下。
1、简介
事件触发词是事件中最具代表性的词语或短语,通常由动词或名词组成。事件和事件触发词之间是一一对应的,因此ED任务相当于识别和分类事件触发词。事件检测具在下游任务具有很多的应用,因此ED广泛吸引了学术界和工业界大量的关注。
目前大多数ED模型使用预训练语言模型来构建复杂的下游网络(包括CNN、RNN、GCN等),这些方法在公共数据集上表现良好,并引入大量额外参数,但它们严重依赖于微调策略来训练其下游网络。然而,由于ED标注数据的稀缺性和分布不均匀,这些方法可能会导致严重的过拟合问题。此外,这些方法在数据稀缺的情况下可能表现不佳,因为它们的额外参数不能完全优化。
基于提示的学习方法是近年来自然语言处理的新趋势。研究人员证实,预训练的语言模型已经有足够的知识,所以复杂的下游网络在很多情况下是不必要的。基于提示的学习方法充分利用预训练语言模型中的信息,通过构造提示来指导语言模型解决NLP任务。具体来说,基于提示符的方法首先将原始输入转换为包含初始输入、提示token和未填充的输出槽的提示模板。然后,使用预训练的语言模型来填充未填充的插槽,以获得最终字符串,从中可以导出最终输出。
基于提示学习的方法消除了复杂的下游网络和大量额外参数,因此在数据稀缺的情况下具有优势。同时,提示的质量直接影响模型的表现。但是,手动选择最佳提示费时费力。考虑到这一点,提出了提示调优策略,通过引入连续的虚拟token作为可训练的提示,将通过训练进行优化。但是,上述提示由于没有引入事件相关的语义知识,可能导致精度较低。
事件触发词多为动词和名词,通常在语义上与事件的核心概念词相关。因此,语义知识(如词性、词语语义关联等)在ED任务中起着至关重要的作用。为此,本文提出了一种知识注入提示调优(KiPT)模型,利用外部知识库引入事件相关知识。
具体来说,我们将ED任务制定为条件生成任务。然后,利用外部知识库和语义工具获取与输入句子和事件相关的语义知识。然后,将语义知识注入到ED提示中。最后,使用注入知识的提示提取事件触发词,并通过提示调优策略对提示进行优化。我们的方法直接有效,可以很容易地推广到其他任务中。
本文的主要贡献总结如下:
- 我们引入了知识注入方法,将事件相关语义知识注入到提示模板中,这在ED任务中尚属首次;
- 我们为ED提出了一种基于提示的学习模型,称为知识注入提示调优(KiPT),它利用提示调优策略来优化提示;
- 大量实验表明,我们的模型优于当前基于提示的ED模型和强基线,特别是在数据稀缺的情况下。
2、相关工作
2.1 事件检测方法
事件检测模型通常被分为序列标注模型和条件生成模型。
Chen等人和Nguyen等人首次将ED定义为序列标记任务,并使用CNN和RNN对句子级特征进行建模;Liu等和Y an等使用GCN来强调语义依赖。Nguyen和Nguyen基于共享的隐藏表示共同提取实体、触发词和论元;Wadden等人提供了一种图形传播方法来捕获与实体、关系和事件相关的上下文;Lin等人构建了一个端到端信息提取系统,该系统采用全局特征和beam search来提取全局最优事件结构;
条件生成方法使用生成式预训练语言模型(如BART(Lewis et al, 2019)和T5(rafffel et al, 2019))对句子进行编码。Li等人利用BART的条件生成模型,Paolini等人将事件提取视为增强自然语言之间的翻译任务;Lu等人将事件构建为事件树,并使用Seq2Structure模型。
2.2 基于提示学习的方法
基于提示的学习方法使用提示来指导预训练的语言模型来生成结果,因此提示模板的质量至关重要。目前基于提示的学习模板包括:手动设置离散提示模板(模板中的实际单词):Schick和Schütze使用手动提示模板将文本分类任务转换为完形填空任务。Petroni等人通过提示模板将三元组补全任务转换为完形填空问题。
构建可训练的连续提示模板(模板中的虚拟token):Li和Liang使用可训练的前缀标记作为提示,并在语言模型的每一层添加软token。Liu等人在提示模板中用可训练的软token替换了实际单词,并引入了额外的提示编码器。
然而,这两种方法都没有引入与任务相关的知识,不能与外部知识一起优化提示。
2.3 基于提示知识的注入
一些著作已经尝试在提示型学习中引入外部知识。Hu等人通过在语言器中引入额外的知识来增强模型输出和预定义类别的映射。Chen等人引入虚拟token来增强关系提取任务的类别特征。Li等人通过引入ground-truth加强了模型。尽管这些方法很有指导意义,但它们具有很强的任务依赖性,很难应用于事件检测。我们的工作旨在使用具有事件相关知识的基于提示的模型来执行ED任务。
为此,本文提出了一种知识注入的提示调优方法。
3、方法
本节首先介绍ED任务的定义。然后,详细介绍了所提出的KiPT模型。
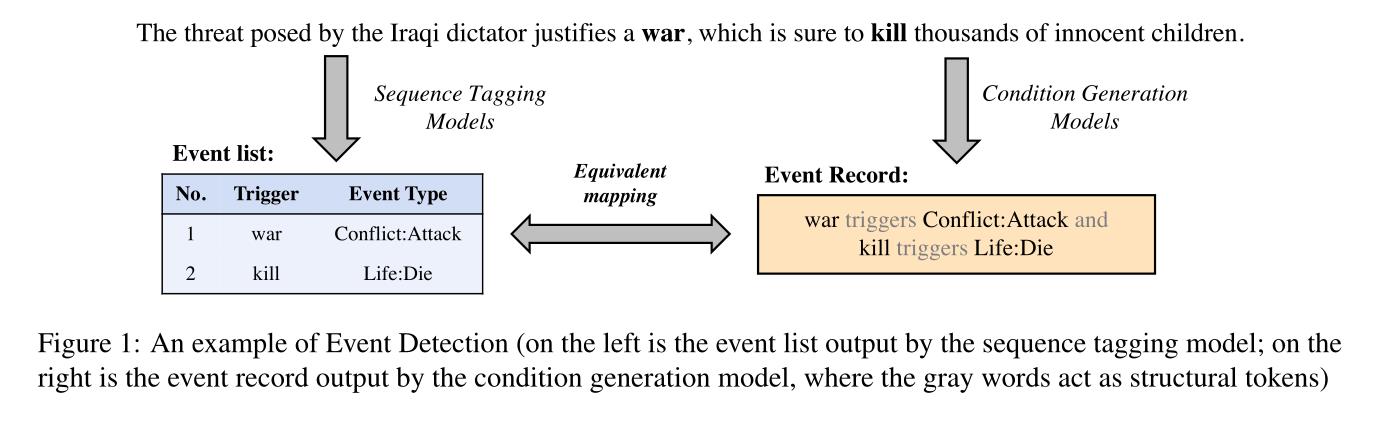
3.1 任务描述
根据自动内容提取的任务描述,ED的标准任务包括事件触发词识别(Trig-I)和触发词分类(Trig-C)。请考虑图1中的示例。ED方法在获取输入句子后,首先识别触发词“war”和“kill”的事件,然后将其分为“Conflict:Attack”和“Life:Die”两种事件类型。
为了简化输出,本文将标准ED任务化为条件生成任务。首先,结构词“triggers”用于组合触发词及其对应类型,如“war triggers Conflict:Attack”。然后,如果一个句子包含一个以上的事件,这些事件将被另外一个结构词"and"连接。考虑图1中的例子,我们构建的事件记录是“war triggers Conflict:Attack and kill triggers Life:Die”。因此,给定输入句子,我们的模型生成上述事件记录作为输出。值得一提的是,我们方法的输出与原始ED任务相当,因为事件记录可以很容易地分成事件触发词和事件类型。
3.2 KiPT的整体架构
KiPT的总体结构如图2所示。首先,给定输入句子 x x x,构造知识注入提示 P r o m p t ( x ) Prompt(x) Prompt(x)。然后构建提示模板输入 T T T,输入预训练的语言模型LM,得到输出事件记录 y y y。
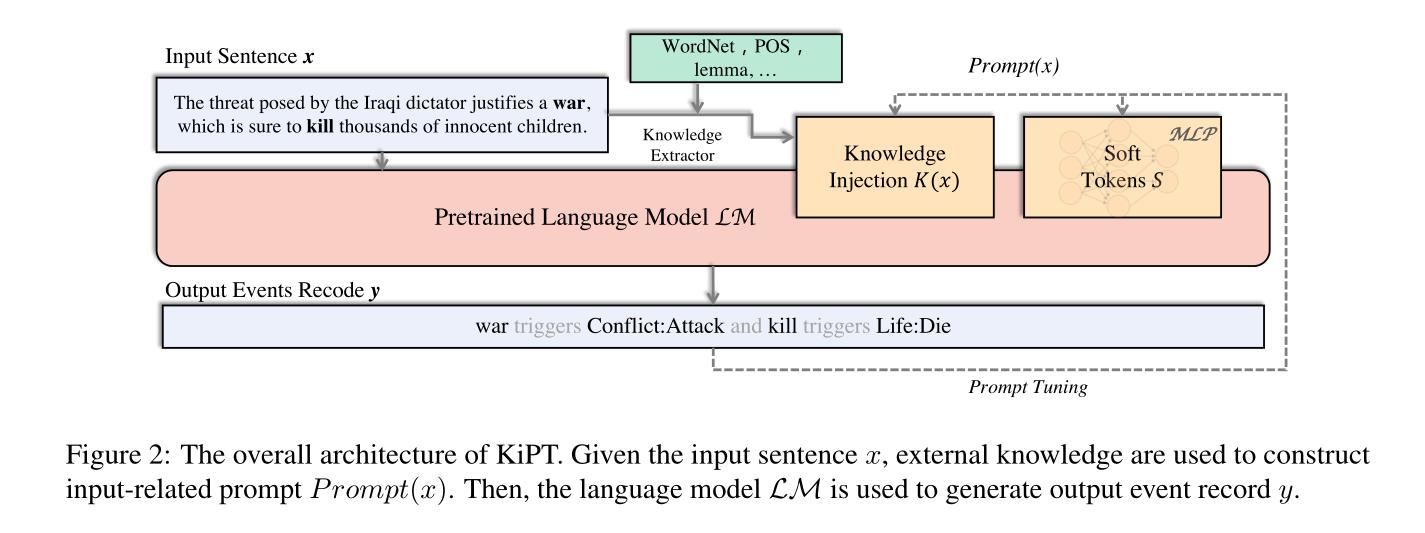
我们在KiPT中提出了一种可训练的知识注入提示 P r o m p t ( x ) Prompt(x) Prompt(x)。 P r o m p t ( x ) Prompt(x) Prompt(x)包括两部分:与输入相关的知识注入 K ( x ) K(x) K(x)和与输入无关的软token S S S。 K ( x ) K(x) K(x)和 S S S都是可训练的,在训练过程中会进行优化。
在下面的小节中,将详细解释知识注入提示的构造和调优。
3.3 知识注入的提示构建
本节首先介绍知识注入 K ( x ) K(x) K(x)和软token S S S的定义。然后,将 K ( x ) K(x) K(x)和 S S S组合成提示符 P r o m p t ( x ) Prompt(x) Prompt(x)。
知识注入 K ( x ) K(x) K(x):给定每个输入句子 x x x,token序列 x 1 : n = x 1 , x 2 , … , x n x_1:n = \\x_1, x_2,\\ldots, x_n\\ x1:n=x1,x2,…,xn可以通过使用标记器获得。然后,利用知识提取器对 x x x的事件相关知识 K ( x ) K(x) K(x)进行提取,并利用NLP分析工具和外部知识库构建知识提取器。
首先,由于事件触发词主要是动词和名词,因此每个标记的词性(POS)是必不可少的。因此,使用语义分析工具对每个token x i x_i xi执行POS分析(Stanford 's Stanza(Qi et al, 2020))。然后,使用Stanza的引理化模块恢复每个输入token的引理形式 x i x_i xi(例如,“died” -> “die”)。在获得每个标记的POS和引理形式后,将动词和名词作为潜在触发词 P T 1 : ∣ P T ∣ = p t 1 , p t 2 , … , p t ∣ P T ∣ PT_1:|P T| = \\pt_1, pt_2,\\ldots, pt_|P T|\\ PT1:∣PT∣=pt1,pt2,…,pt∣PT∣。
知识库中的语义关联也为ED提供了重要的信息。每一种事件都有一些核心概念,例如,事件类型"Conflict: Attack" 有一些概念如"attack, fight, bomb, etc.",事件类型"Life: Die" 有"kill, suicide, murder, etc."的概念。为了挖掘词汇和事件核心概念的语义相关性,我们做了以下假设:
假设3.1:如果一个词与特定事件类型的核心概念有很强的语义相关性,那么这个词就有可能触发该类型的事件。
基于上述假设,手工构造了一个字典 C o n c e p t 1 : e Concept_1:e Concept1:e,其中包含每种事件类型的核心概念( e e e表示事件类型的总数),而 c o n c e p t k concept_k conceptk表示第 k k k种事件类型的概念。然后,引入WordNet(Fellbaum and Miller, 1998),获得输入token与核心概念之间的语义相关性,通过计算WordNet中两个词的语义相似度来判断它们是否具有较强的语义相关性。对于潜在触发词 P T PT PT列表中的每个单词 p t j pt_j ptj和每个事件类型的核心概念 c o n c e p t k concept_k conceptk,使用WuPalmer相似算法计算它们的语义相关性 S c ( p t j , c o n c e p t k ) Sc(pt_j, concept_k) Sc(ptj,conceptk) (Wei et al, 2015)。如果语义相关性 S c ( p t j , c o n c e p t k ) Sc(pt_j, concept_k) Sc(ptj,conceptk)高于相似阈值 θ s i m θ_sim θsim,则潜在的触发词 p t j pt_j ptj和对应的事件类型 e v e n t k event_k eventk都加到 K ( x ) K(x) K(x)中。
综上所述,知识提取器的过程如下:
最终提取的知识注入 K ( x ) K(x) K(x)是由潜在触发词及其潜在事件类型组成的文本序列。记为 K ( x ) 1 : ∣ K ∣ = k 1 , k 2 , … , k ∣ k ∣ K(x)_1:|K|= \\k_1, k_2,\\ldots, k_|k|\\ K(x)1:∣K∣=k1,k2,…,k∣k∣,其中 ∣ k ∣ |k| ∣k∣代表 k k k的长度。此外,相似阈值 θ s i m θ_sim θsim可能会影响我们模型的性能。
soft tokens S S S:本文除了使用知识注入 K ( x ) K(x) K(x)外,还在提示符中添加了一些可训练的软token。软token是与实际单词共享相同维度的虚拟token(例如,T5-base为768),但没有实际含义。之前的工作已经证明,可训练的软提示比实际文字更灵活有效(Liu et al, 2021;Li and Liang, 2021)。
该方法使用随机初始化的张量作为软提示符号,并在语言模型训练过程中进行优化。本文使用的软token记为 S 1 : p = s 1 , s 2 , … , s p S_1:p = \\s_1, s_2,\\ldots, s_p\\ S1:p=s1,s2,…,sp。 p p p的选择可能会稍微影响我们模型的性能。
提示模板构建:获得知识注入
K
(
x
)
K(x)
K(x)和软token
S
S
S 后,串联为
P
r
o
m
p
t
(
x
)
Prompt(x)
Prompt(x): 《自适应交换机:用于网络中心计算的异构交换机体系结构》 以上是关于论文精读COLING 2022-KiPT: Knowledge-injected Prompt Tuning for Event Detection的主要内容,如果未能解决你的问题,请参考以下文章
P
r
o
m
p
t
(
x
)
=
[
K
(
x
)
;
S
]
=
k
1
,
…
,
k
∣
K
∣
,
s
1
,
…
,
s
p
Prompt(x)=[K(x);S]=\\ k_1,\\ldots,k_|K|,s_1,\\ldots,s_p \\
Prompt(x)=[K(目录
文章目录
网络领域
《基于在网计算加速的拜占庭容错算法》
《阿里巴巴新一代高速云网络拥塞控制协议 HPCC》