Hive SQL DML语法之查询数据
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive SQL DML语法之查询数据相关的知识,希望对你有一定的参考价值。
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家一起来开始学Spark!
▼往期内容汇总:
- 大数据导论
- Linux操作系统概述
- VMware Workstation虚拟机使用
- Linux常用基础命令、系统命令
- Apache Hadoop概述
- Apache Hadoop集群搭建
- HDFS分布式文件系统基础
- Hadoop技术之HDFS shell操作
- Hadoop技术之HDFS工作流程与机制
- Hadoop MapReduce介绍、官方示例及执行流程
一、Hive SQL select语法介绍
Select语法树
从哪里查询取决于FROM关键字后面的table_reference,这是我们写查询SQL的首先要确定的事即你查询谁?
表名和列名不区分大小写。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[LIMIT [offset,] rows];
数据环境准备

( 1) select_expr

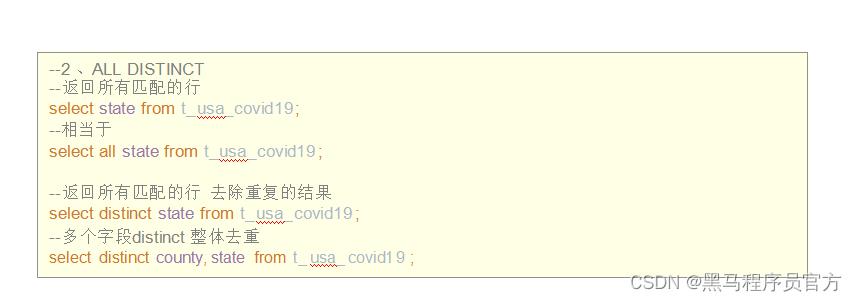
(2) ALL 、 DISTINCT
用于指定查询返回结果中重复的行如何处理。
1. 如果没有给出这些选项,则默认值为ALL (返回所有匹配的行) 。
2. DISTINCT指定从结果集中删除重复的行。

( 3) WHERE
WHERE后面是一个布尔表达式(结果要么为true,要么为false),用于查询过滤,当布尔表达式为true时,返回select后面expr表达式的结果,否则返回空。
在WHERE表达式中, 可以使用Hive支持的任何函数和运算符,但聚合函数除外。
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[LIMIT [offset,] rows];

- 比较运算、逻辑运算
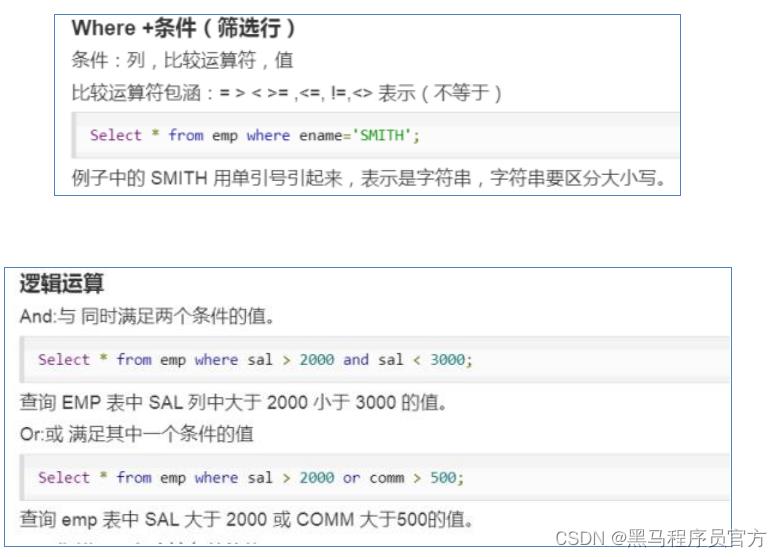
- 特殊条件(空值判断、 between、 in)

(4)聚合操作
SQL中拥有很多可用于计数和计算的内建函数,其使用的语法是: SELECT function(列) FROM 表。
这里我们要介绍的叫做聚合(Aggregate)操作函数,如: Count、 Sum、 Max、 Min、Avg等函数。
聚合函数的最大特点是不管原始数据有多少行记录, 经过聚合操作只返回一条数据,这一条数据就是聚合的结果。
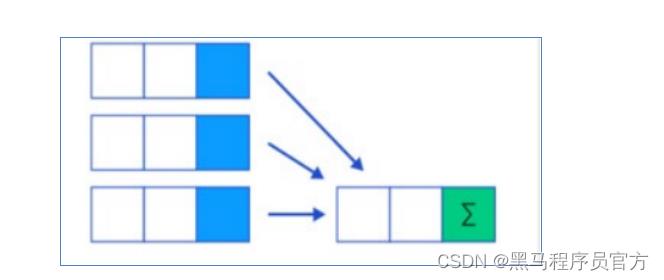
- 常见的聚合操作函数

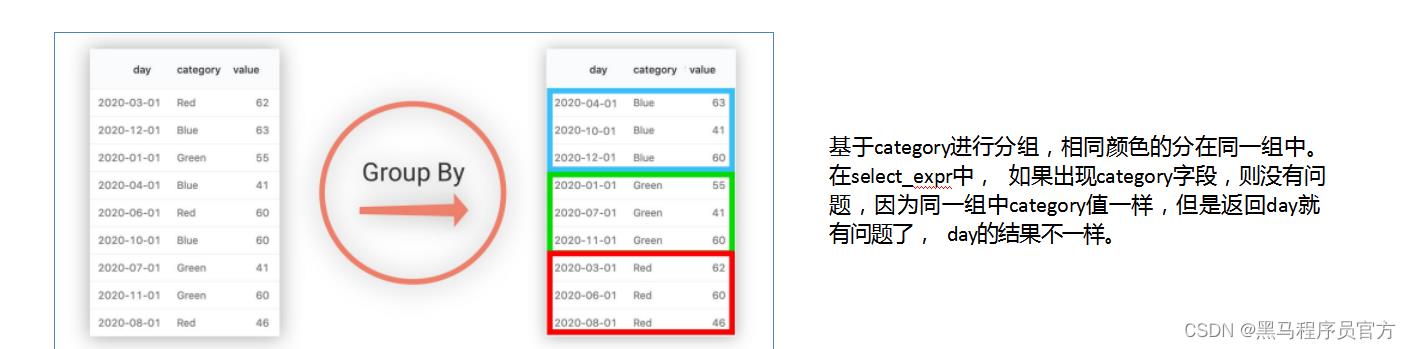
 (5)GROUP BY概念
(5)GROUP BY概念
GROUP BY语句用于结合聚合函数, 根据一个或多个列对结果集进行分组;
如果没有group by语法,则表中的所有行数据当成一组。
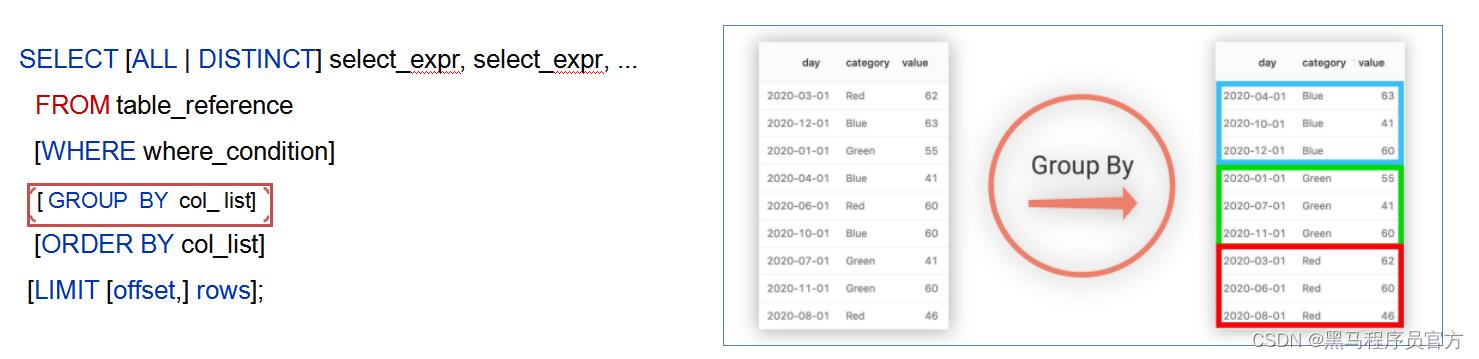
GROUP BY使用

GROUP BY语法限制
出现在GROUP BY中select_expr的字段: 要么是GROUP BY分组的字段; 要么是被聚合函数应用的字段。
原因: 避免出现一个字段多个值的歧义。
1. 分组字段出现select_expr中, 一定没有歧义,因为就是基于该字段分组的,同一组中必相同;
2. 被聚合函数应用的字段,也没歧义, 因为聚合函数的本质就是多进一出,最终返回一个结果。
(6) HAVING
在SQL中增加HAVING子句原因是, WHERE关键字无法与聚合函数一起使用。
HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where, group by已经执行结束,结果集已经确定。
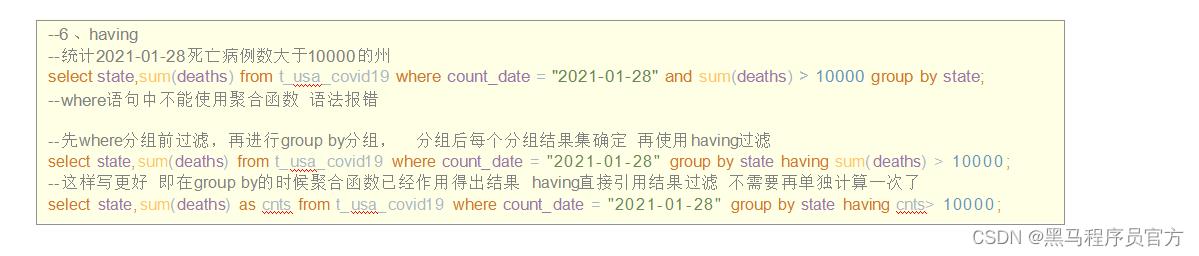
HAVING与WHERE区别
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
(7) ORDER BY
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照升序(ASC) 对记录进行排序。如果您希望按照降序对记录进行排序,可以使用DESC关键字


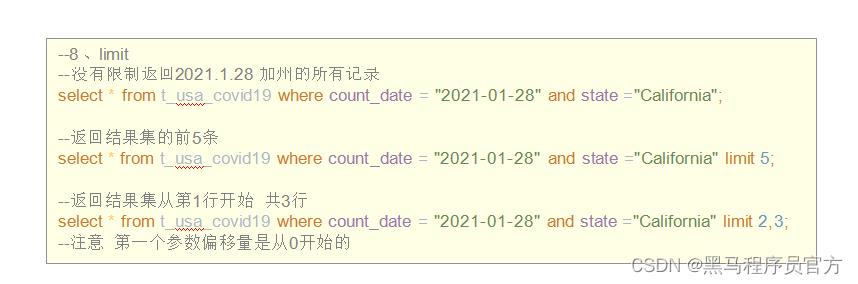
(8) LIMIT
LIMIT用于限制SELECT语句返回的行数。
LIMIT接受一个或两个数字参数,这两个参数都必须是非负整数常量。
第一个参数指定要返回的第一行的偏移量(从 Hive 2.0.0开始),第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为0。
执行顺序
在查询过程中执行顺序: from > where > group (含聚合) > having >order > select;
1. 聚合语句(sum,min,max,avg,count)要比having子句优先执行
2. where子句在查询过程中执行优先级别优先于聚合语句(sum,min,max,avg,count)
结合下面SQL感受: 
以上是关于Hive SQL DML语法之查询数据的主要内容,如果未能解决你的问题,请参考以下文章