阿里云MaxComputer SQL学习之DML
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云MaxComputer SQL学习之DML相关的知识,希望对你有一定的参考价值。
🐯上一节中,我们介绍了阿里云MaxComputer中的数据定义语言,这一节中,我们将学习数据操作语言。对往期内容感兴趣的小伙伴可以查看如下内容👇:
- 第一篇: Hadoop之Hive数据的导入与导出(DML).
- 第二篇: Hadoop之Hive查询语句.
- 第三篇:Hadoop之Hive的7种Join语句.
- 第四篇: Hadoop之Hive的排序.
- 第五篇: Hadoop之Hive的分区表.
- 第六篇: Hadoop之Hive的分桶表.
- 阿里云系列: 阿里云MaxComputer SQL学习之DDL.
🐅让我们进入今日份的阿里云MaxComputer的学习,上一章节有粉丝反应没有例子,这次我使用阿里云的DataWorks给大家演示一下。
目录
1. MaxComputer SQL的DML
DML主要包括如下的两种操作:
- 查询数据:单表查询、表连接(join)、分支条件判断等。
- 更新数据:插入数据、覆盖插入、多路输出等等。
1.1 查询数据
--语法格式:
SELECT [ALL | DISTINCT] <select_expr>, <select_expr>,...
FROM <table_reference>
[WHERE <where_condition>]
[GROUP BY ‹col_list>]
[HAVING <having_condition>]
[ORDER BY <order_condition>]
[DISTRIBUTE BY <distribute_condition> [SORT BY <sort_condition>] ]
[LIMIT <number>]
- 列可以用列名指定。* 代表所有的列。
- 支持嵌套子查询,子查询必须要有别名
- 子查询可以与其他表或者子查询做join
实验
先来看看表t_dml中的数据

-
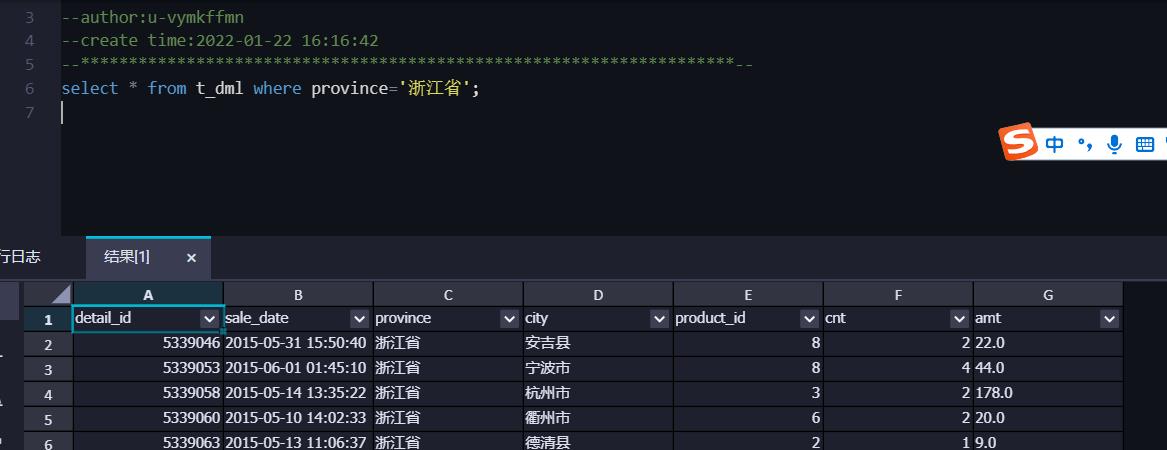
检查表中“浙江省”相关的数据信息
-
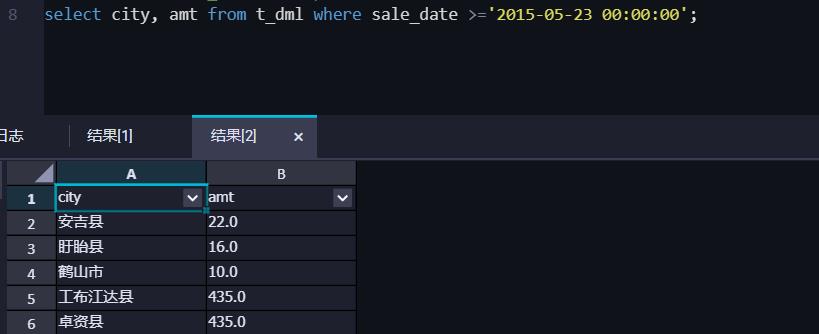
核查销售时间大于或等于某日期的数据信息
-
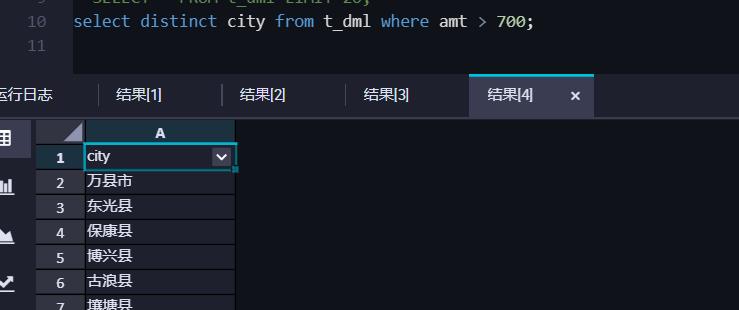
检查总量大于某量的城市信息
-
统计浙江省销量大于某量的销售城市排名 (子查询)

-
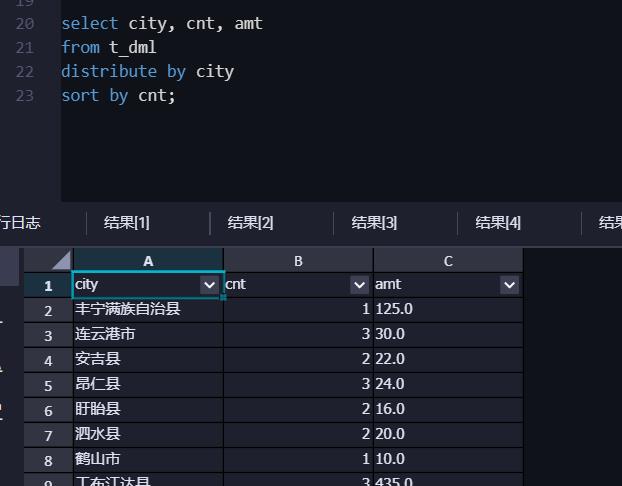
城市排名统计
1.2 更新数据
- 插入到普通表或者静态分区
--基本语法:输出到普通表或者静态分区
INSERT (INTO|OVERWRITE TABLE <table_name> [PARTITION (<pt_spec>)] [<col_name>,<col_ name>...)]
<select statement>
FROM <from_statement>
- 插入到动态分区
--基本语法:输出到动态分区
INSERT (INTO|OVERWRITE) TABLE <table_name> PARTITION (<ptcol_name>[, <ptcol_name>...])
<select_statement› FROM <from_statement>;
- 动态分区就是分区值是由分区字段的值来决定,静态分区是分区字段已经指定为固定值。
- 如果目标表有多级分区,在运行insert语句时允许指定部分分区为静态,但是静态分区必须是高级分区。
- 动态分区的分区值不可以为NULL。
实验
- 插入一条记录
insert into table t_dml select -1,'1900-01-01 00:00:00','','',0,0,0 from dual;

2. 添加分区

3. 往分区添加数据
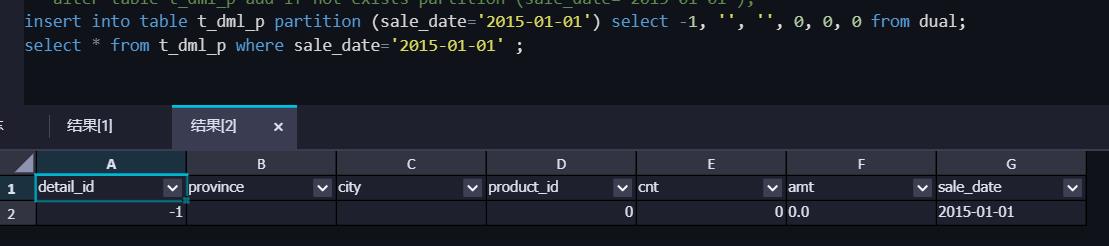
4. 覆盖插入

5. 分区表数据操作 (依次执行下面的三个操作,添加分区、插入数据、检查分区表数据)

6. 清空分区表
使用覆盖插入的方式清空非分区表
insert overwrite table t_dml select * from t_dml where 1=2; --清空操作

通过删除的方式删除分区
alter table t_dml_p drop if exists partition (sale_date='2015-01-01');

1.3 多路输出
多路输出的意思是一个select输出向多个表或多个分区插入数据
--基本语法
FROM <from statement>
INSERT OVERWRITE INTO TABLE <table_name1> [PARTITION (<pt_spec1>)]
‹select_statement1>
INSERT OVERWRITE INTO TABLE <table_name2> [PARTITION (‹pt_spec2>)]
‹select_statement2>
. . .;
多路输出的限制:
- 单个sql里最多可以写255路输出
- 对于分区表,同一目标分区不可以出现多次
- 对于未分区表,该表不能做为目标表多次出现
- 对于同一张表的不同分区,不能同时有insert overwrite 和insert into 操作
实验
将表 t_dml 中的数据detail_id编号大于5340000的插入一张临时表备查,并将5月1日的记录插入分区表 t_dml_p 的20150501分区中去,将5月2日的数据插入20150502分区,分为三个步骤:
1) 目标表增加分区
2) 备份核查数据
3) 多路输出不同分区
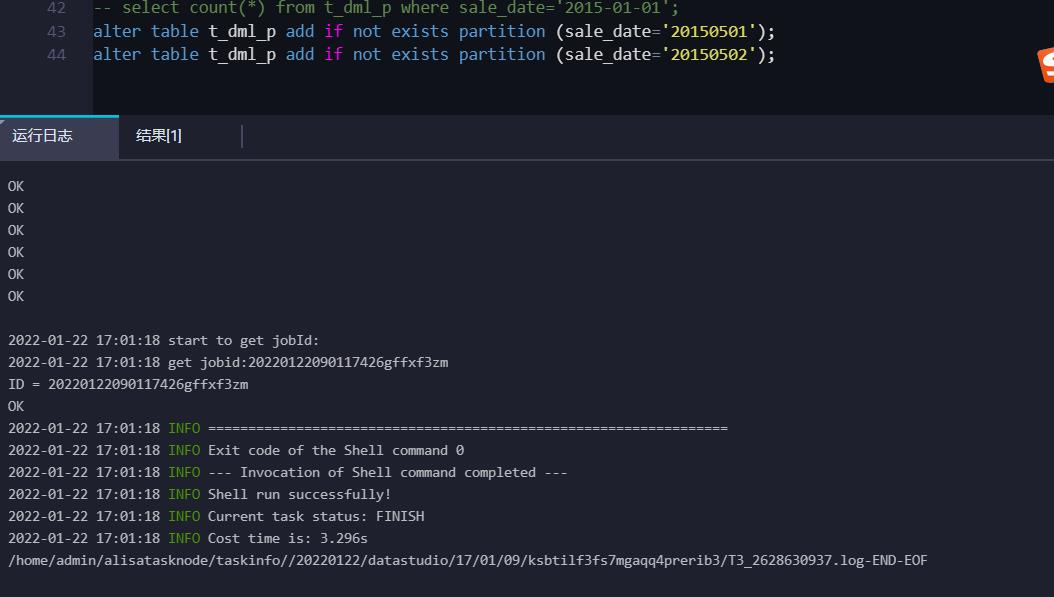
- 增加分区,依次增加两个分区,操作如下
2. 创建临时表

3. 将表t_dml中的数据按不同条件同时输出到新建的表和新建的t_dml_p的两个分区中
from t_dml
insert into table t_dml_01
select detail_id,sale_date,province,city,product_id,cnt,amt
where detail_id > 5340000
insert overwrite table t_dml_p partition (sale_date='20150501')
select detail_id,province,city,product_id,cnt,amt
where sale_date >= '2015-05-01 00:00:00'
and sale_date <= '2015-05-01 23:59:59'
insert overwrite table t_dml_p partition (sale_date='20150502')
select detail_id,province,city,product_id,cnt,amt
where sale_date >= '2015-05-02 00:00:00'
and sale_date <= '2015-05-02 23:59:59' ;

1.4 表关联
下图是连接的几种情况:阴影部分表示最后的结果部分

SELECT [t1.col_name, ]
[t2.col_name,]
FROM
<tab_name1> t1
[LEFT OUTER] JOIN <tab_name2> t2
ON <[t1.col_name = t2.col_name]
[AND t1.col_name = t2.col_name]
......>
实验
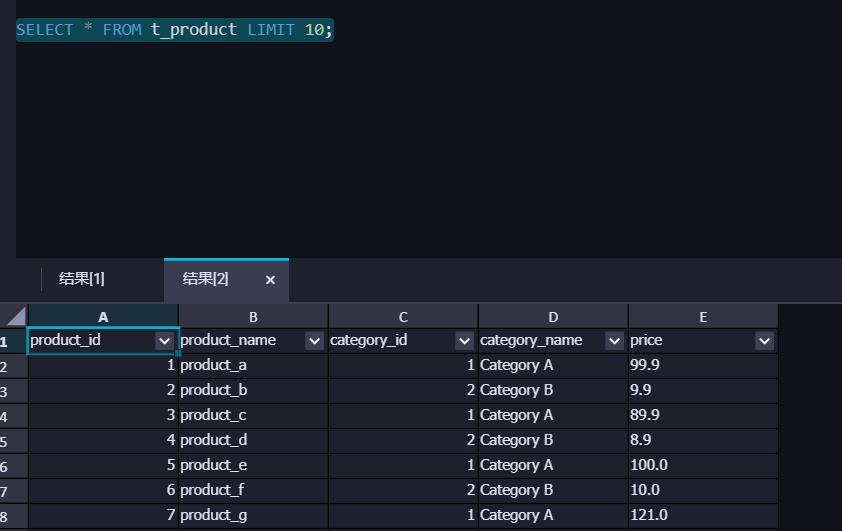
先展示一下t_product表,事实表t_dml包含了销售记录信息,其中字段 product_id为产品标识,可以关联另一张维表t_product获得产品的说明信息。
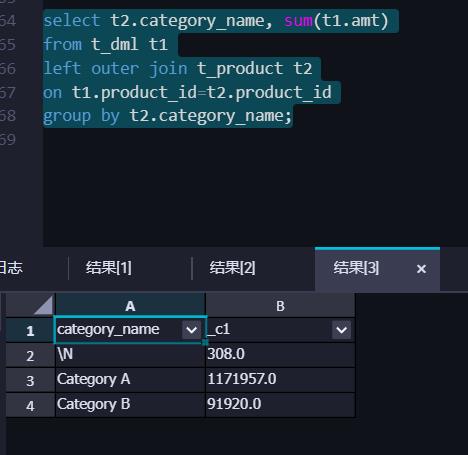
- 按照产品分类(category_name)统计销售金额
1.5 Mapjoin(提高效率)
- 可以使用不等值的or作为连接条件
-- 示例1:不等值 or 作为连接条件
SELECT /*+ MAPJOIN(a) */
a. shop_name
,a. total_price
,b. total_price
FROM sale_detail_sj a
JOIN sale_detail b
ON a.total_price<b.total_price
OR a.total_price + b.total_price < 500;
- 提升性能
--示例2:提升性能
SELECT /* + MAPJOIN(a) */
a. shop_name
,b. customer_id
,b. total_price
FROM shop a
JOIN sale_detail b
ON a.shop_name = b.shop_name;
- 使用情景:一个大表和一个或多个小表做join
- 基本原理:将用户指定的小表全部加载到执行 join 操作的程序的内存中,从而加快 join 的执行速度
- 注意事项:
left outer join 的左表必须是大表
right outer join 的右表必须是大表
inner join 左表或右表均可以作为大表
full outer join不能使用 mapjoin
支持小表为子查询,需要使用别名
可以使用不等值连接或者使用 or 连接多个条件
目前最多支持指定128张小表
所有小表加载至内存后占用的内存总和不得超过512M
实验
由于各种原因,造成销售信息表 t_dml 中的记录存在一些质量问题,可能的问题包括:
1- 产品标识错误: 可以通过单价判断,单价相等的标识不同,则可能存在错误
2- 价格错误:如果销售记录中的平均单价高于产品维表中的定价,则可能存在问题
请协助发现这些可能存在问题的记录。
- left outer join 实现质量问题

- inner join (join) 实现质量问题

在做关联时,如果关联条件比较复杂(比如包含 or 等连接条件)或者是关联条件中存在非等值关联(比如大于、小于或者不等于等),则普通的 join 无法实现,可以采用带有 mapjoin HINT 的 join 方法。
1.6 分支表达式
case when 有两种写法:
- case后面接字段
--两种 CASE WHEN 语法:
--1. case+value
CASE <value>
WHEN <condition 1> then <result 1>
WHEN <condition 2> then <result 2>
else <result n>
END
-- 例如:
SELECT CASE gender WHEN 1 THEN '男' WHEN 2 THEN '女' END
FROM table1;
- case when后面接字段(大多数用这种,更灵活)
-- 2. case when+value
CASE
WHEN <condition 1> then <result 1>
WHEN <condition 2> then <result 2>
else <result n>
END
--例如:
SELECT CASE WHEN gender=1 THEN '男' WHEN gender=2 THEN '女' END
FROM table1;
- 如果返回结果类型不一样,会进行类型转换,返回统一的结果。
- 非贪婪式,碰到第一个满足条件的结果就会返回。
实验
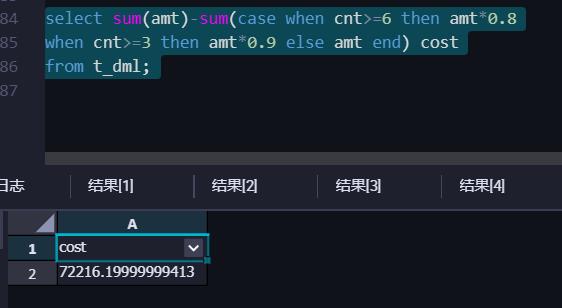
在目前的售价上实行9折优惠,一次购买6个及以上产品的,给与8折优惠。请基于5月份数据想评估一下此次活动的成本(为了简单可行,活动成本定义为目前销售额减掉优惠后的销售额)
2. 总结
在这一部分中,需要注意的点:
- 企业中所有表的查询都需要带上分区。
- 记住mapjoin的原理,面试重点。
3. 参考资料
《阿里云全球培训中心》
《阿里云DataWorks使用手册》
以上是关于阿里云MaxComputer SQL学习之DML的主要内容,如果未能解决你的问题,请参考以下文章