PHP爬虫抓取
Posted Yuanr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PHP爬虫抓取相关的知识,希望对你有一定的参考价值。
目标:利用php解决网站列表内容抓取
描述:在群里看到小伙伴问到关于抓取网站列表内容,我就想起了当时工作关于文章采集的问题,但是后面想想又不对,这是列表抓取,于是就想起了大神们经常说的说的“爬虫”,我想一定可以解决小伙伴的问题,因为是php小白,所以在网上找了很多爬虫的写法,但是太长了不想看,受网友帖子启发看到了fopen()方法,那么这个方法是干嘛的?
fopen() 定义:"把指定文件或者url资源绑定到资源流上";注释
额 好像不错,在查找流的相关用法时,看到stream_get_contents()方法,那么这个方法具体有什么作用呢?
stream_get_contents() 定义: "把资源流转化成字符串";注释
这下明白,利用他们就可以解决页面抓取了。
代码:
<?php define("URL", "http://www.zcy.gov.cn/search?shopId=6&pageNo="); $start_time = microtime(true); $array = Array(); echo \'<ul class="view-mode-thumb">\'; for($index = 1; $index <= 5; $index++){ $url = URL.$index; $fp = fopen($url, \'r\'); $all_Str = stream_get_contents($fp, -1, -1); // $len = strlen($all_Str); $preg =\'/<li class="product\\s*\\w*" style="\\s*\\w*\\s*">.*?<\\/li>/s\'; $int = @preg_match_all($preg, $all_Str, $arr); $array = array_merge($array, $arr[0]); } foreach ($array as $key => $value) { # code... echo $value; } echo \'</ul>\'; $end_time = microtime(true); echo "<script>console.log(\'文件数目:".count($array)." 耗用时间:".($end_time-$start_time)."s\')</script>"; // fpassthru($fp); fclose($fp); exit(); ?>
效果图:
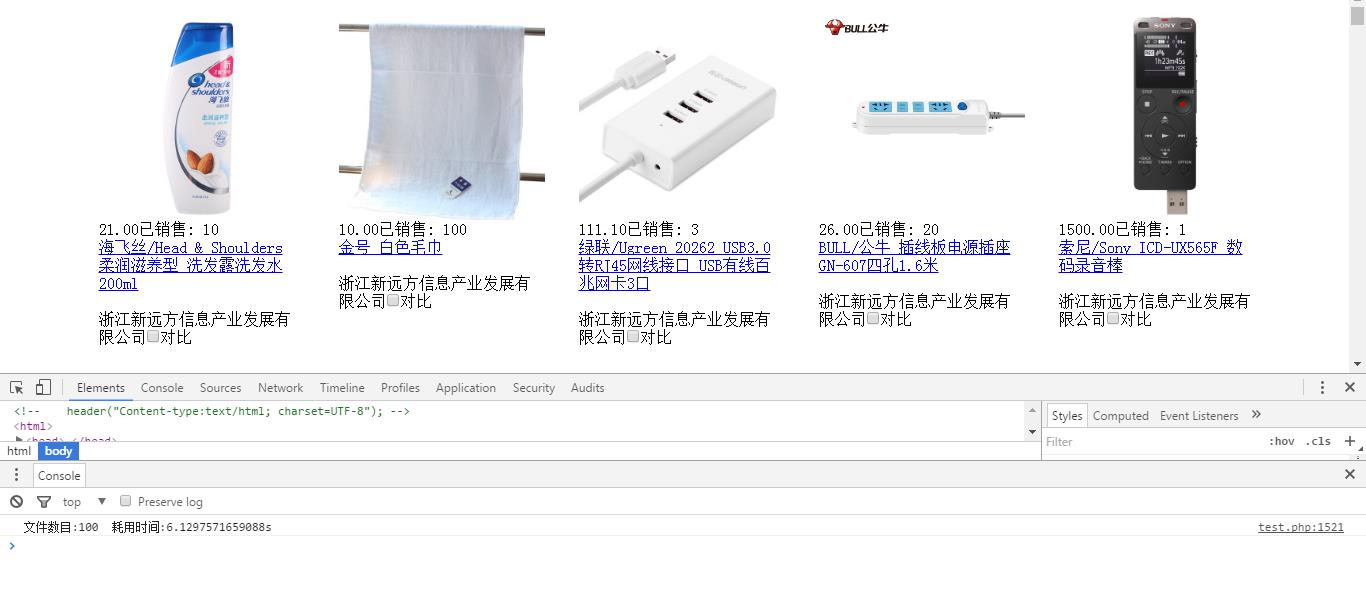
说明:不知道是自己能力问题还是其他原因,PHP爬虫的抓取页面效率不是很高,测试500个链接10000个数据耗时接近10分钟,最后本人还是菜鸟,写法上可能不是很完善,望见谅!
以上是关于PHP爬虫抓取的主要内容,如果未能解决你的问题,请参考以下文章