论文精读HumanNeRF
Posted YuhsiHu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文精读HumanNeRF相关的知识,希望对你有一定的参考价值。
目录
- Abstract
- 1.Introduction
- 2.Related work
- 3.Representing a Human as a Neural Field
- 4.Optimizing a HumanNeRF
- 5.Results
- 6.Discussion
今天读的是CVPR 2022 oral的一篇文章,文章由UW和Google合作,旨在使用NeRF基于单目视频渲染合成运动的人体。
项目地址:https://grail.cs.washington.edu/projects/humannerf/
Abstract
引入了一种自由视点渲染方法——HumanNeRF。它适用于人类进行复杂身体运动的单目视频。该方法可以在任何帧暂停视频,并从任意新的摄像机视点甚至是该特定帧和身体姿势的完整 360 度摄像机路径渲染主体。这项任务特别具有挑战性,因为它需要合成身体的细节,从输入视频中可能不存在的各种角度看,以及合成精细的细节,如布料褶皱和脸部细节。我们的方法优化了人在规范 T 姿势中的体积表示,与运动场相一致,该运动场通过向后扭曲将估计的规范表示映射到视频的每一帧。运动场被分解为由深度网络产生的骨骼刚性和非刚性运动。文章展示了性能改进和在随意的场景中移动人类的单目视频的渲染示例。
1.Introduction
给定一个人类运动的视频,我们想要在任何帧暂停并能够360度旋转在任何角度观察这个视频里的表演者。这个问题长期以来都是一个挑战,因为它需要合成一些摄像机完全没有涉及到的角度,并且还需要合成诸如衣服折叠、头发摆动、复杂肢体运动等等细节。
先前的工作可以在拥有小心拍摄的多个视图的情况下合成新视角,但在人类的合成上表现不好,因为人类的动作包含非刚体运动。针对人类的合成会把SMPL模板当作先验条件,这虽然有助于限制运动空间,但也会在服装和复杂运动中引入 SMPL 模型未捕获的伪影。最近,可变形的 NeRF 方法对于小的变形表现良好,但不适用于像跳舞这样的大的全身运动。
我们创造了一种名为 HumanNeRF 的方法,该方法将运动的人的视频作为输入,并在使用现成的估计器提取每帧 3D 姿势后,优化人体的典型体积 T-pose和通过backward warping将估计的规范体积映射到每个视频帧的motion field。运动场结合了骨骼刚性运动和非刚性运动,每一个都以体积表示。标准体积和运动场源自视频本身,并针对大的身体变形进行了优化,端到端训练,包括 3D 姿势细化,无需模板模型。在测试时,我们可以在视频中的任何帧暂停,并根据该帧中的姿势,渲染生成从任何角度来看的体积表示。
我们展示了各种示例的结果:现有的实验室数据集、我们在实验室外捕获的视频以及从 YouTube 下载的内容。我们的方法在数值上优于最先进的方法,并产生显着更高的视觉质量。
2.Related work
自由视点渲染的物理特性涉及对几何和表面属性进行建模,然后从新的相机视图进行渲染。但是,仍然很难重新创建复杂的几何形状和微妙的照明效果。 另外,基于图像的渲染提供了基于图像域中给定视图集的新视图,并在过去几十年中进行了大量研究。
Human specific rendering
Kanade 等人的工作是对人类自由视点渲染的最早研究之一。,它引入了一个配备相机的圆顶来恢复深度图和网格,通过重投影和混合不同的视图来渲染新的视图,以解决由于遮挡引起的网格空洞。 后来,Matusik 等人从对象的轮廓中重建了一个visual hull,并通过仔细选择没有辅助几何表示的像素来渲染它。 Carranza等人使用参数化的身体模型作为先验并组合无标记运动捕捉和依赖于视图的纹理。紧接着的工作带来了非刚性变形、纹理扭曲以及基于体积或球体的各种表示。Collet等人和Guo等人建立了一个系统和pipeline来生成高质量的视频中的移动人物。这些基本都依赖多个视角的视频和昂贵的采集装置,但我们想用简单的单目相机来达到这个效果。
Neural radiance fields
神经辐射场使得高质量渲染成为可能。文章将会把提出的方法与一些动态和可变形NeRF进行了对比。
Human-specific neural rendering
Lingjie 等人的工作从预先捕获的身体模型开始,学习对时间相关的动态纹理进行建模并强制执行时间连贯性。Martin-Brualla等人训练了一个 UNet 来改善体积捕获引入的artifacts。 Pandey 等人的后续工作通过半参数学习将所需输入帧的数量减少到单个 RGBD 图像。Wu和Peng等人探索了使用嵌入点云(来自 MVS)或 reposed mesh vertices(来自SMPL),并学习了一个随附的基于 UNet 或 NeRF 的神经渲染器。Zhang等人将场景分解为背景和表演者,并用分离的 NeRF 表示它们,从而实现场景编辑。除了自由视点渲染,还有另一个相关的活跃研究领域,专注于 2D或 3D 中的人类移动重定位。我们的方法与那些的主要区别在于,我们将包含复杂人体运动的单目视频作为输入,并可以进行高质量 3D 渲染。
Concurrent work
Xu等人的工作能够同时学习隐式几何以及图像的外观, 他们主要关注多视图设置,其中有一些简单的人体运动(A-pose)单目视频示例。 Su等人使用过度参数化的 NeRF 来严格转换 NeRF 特征,以优化身体姿势,从而进行最终渲染。 非刚性运动没有显式建模,所以渲染质量不高。 Noguchi等人发现了类似的方法但效果也不够理想。
3.Representing a Human as a Neural Field
我们将一个移动的人物表达为
F
c
F_c
Fc,转换为观察的姿势下能看到的样子
F
o
F_o
Fo:
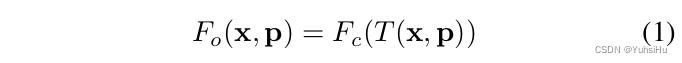
其中
F
c
:
x
−
>
(
c
,
σ
)
F_c:x->(c,\\sigma)
Fc:x−>(c,σ)表示位置
x
x
x和颜色
c
c
c体积密度
s
i
g
m
a
sigma
sigma,
T
:
(
x
0
,
p
)
−
>
x
c
T:(x_0,p)->x_c
T:(x0,p)−>xc定义了一个motion field,把点从观察空间映射回canonical space,由观察姿态
p
=
(
J
,
Ω
)
p=(J,\\Omega)
p=(J,Ω)引导,其中
J
J
J包含
K
K
K个标准3D联合位置,
Ω
=
w
i
\\Omega=\\w_i\\
Ω=wi是表示为轴角向量的local joint rotations。
我们通过将运动场分解为两部分来处理具有复杂变形的复杂人体运动:

其中
T
s
k
e
l
T_skel
Tskel表示skeleton驱动的变形,基本上就是逆linear-blend skinning,
T
N
R
T_NR
TNR从骨架驱动的变形开始,并对其产生偏移
Δ
x
Δx
Δx。实际上,
T
s
k
e
l
T_skel
Tskel提供由标准skinning驱动的粗略变形,而
T
N
R
T_NR
TNR 提供更多非刚性效果,比如由于服装的变形。
对于野外图像,我们使用现成的 3D 身体+相机姿势估计器。 由于姿势估计的不准确,我们还求解了一个姿势校正函数
P
p
o
s
e
(
p
)
P_pose (p)
Ppose(p),它可以更好地解释观察结果,并将这种改进应用于骨架驱动的变形,即,我们将
T
s
k
e
l
(
x
,
p
)
T_skel (x, p)
Tskel(x,p) 替换为
T
s
k
e
l
(
x
,
P
p
o
s
e
(
p
)
)
T_skel(x, P_pose (p))
Tskel(x,Ppose(p)) 。整体架构如下图所示:
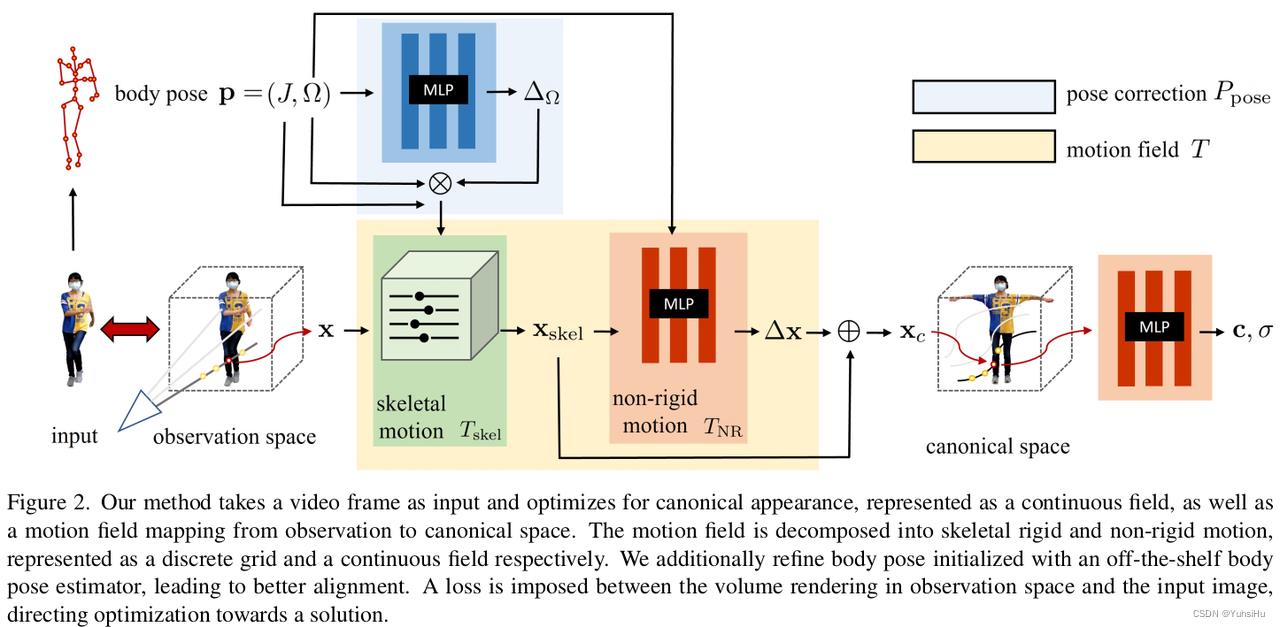
Canonical volume
我们把canonical volume
F
c
F_c
Fc表示为具有MLP的连续场,在给定点
x
x
x 的情况下输出颜色
c
c
c 和密度
σ
\\sigma
σ:

其中y是和NeRF当中一模一样的位置编码方式。
Skeletal motion
我们计算了骨骼形变
T
s
k
e
l
T_skel
Tskel作为一种逆向linear blend skinning,将观察空间中的点映射到规范空间:
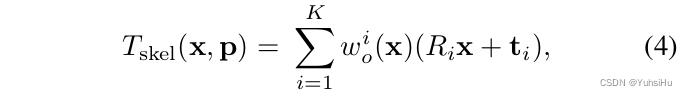
其中
w
0
i
w^i_0
w0i是第
i
i
i个骨骼的混合权重,
R
i
R_i
Ri和
t
i
t_i
ti是旋转和平移,将骨骼的坐标从观察映射到规范空间。
R
i
R_i
Ri 和
t
i
t_i
ti 可以从
p
p
p 显式计算,我们的目标是针对
w
i
o
w^o_i
wio 进行优化。
在实践中,我们通过将 K 个混合权重存储为一组体积
w
c
i
(
x
)
w_c^i (x)
wci(x) 来求解在规范空间中定义的
w
c
i
w_c^i
wci,从中导出观察权重为:
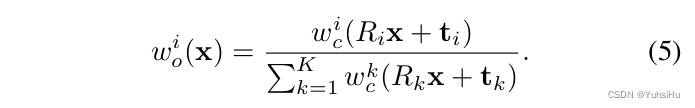
求解规范空间中的一组权重体积
w
c
i
(
x
)
w_c^i (x)
wci(x),而不是观察空间中的
N
N
N 组
w
o
i
(
x
)
w_o^i (x)
woi(x)(对应于
N
N
N 个输入图像),可以导致更好的泛化,因为它避免了过拟合。
我们将
w
c
i
(
x
)
w_c^i (x)
wci(x)的集合打包成具有 K 个通道的单个volume
W
c
(
x
)
W_c (x)
Wc(x)。 我们没有使用 MLP 对
W
c
W_c
Wc 进行编码,而是出于两个原因选择显式体积表示:(1) 等式 5 表明需要
K
K
K 个 MLP 评估来计算每个
w
o
i
(
x
)
w_o^i (x)
woi(x),这对于优化是不可行的(在我们的工作中
K
=
24
K = 24
K=24); (2) 通过三线性插值重新采样的具有有限分辨率的显式体积提供了平滑度,有助于以后对优化进行正则化。 在实践中,在优化过程中,我们不是直接求解
W
c
W_c
Wc ,而是求解从随机(恒定)潜在代码 z 生成体积的 CNN 的参数
θ
s
k
e
l
θ_skel
θskel :

我们还添加了一个通道,一个背景类,并将
W
c
W_c
Wc 表示为具有
K
+
1
K + 1
K+1 个通道的volume。然后,我们将channel-wise的 softmax 应用于 CNN 的输出,在通道之间执行统一分区。然后可以使用等式5的分母来近似相似度
f
(
x
)
f (x)
f(x)(作为主体的一部分),其中
f
(
x
)
=
f (x) =
f(x)=
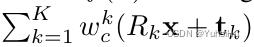
当
f
(
x
)
f (x)
f(x) 接近于零时,我们很可能在远离主体的自由空间中,我们将在体绘制期间使用它。
优化混合权重的主意其实并不新颖,相似的方法在human modeling上也有被使用过。
Non-rigid motion
我们使用非刚体运动
T
N
可视化论文精读系列:SizePairs
论文题目:《SizePairs: Achieving Stable and Balanced Temporal Treemaps using Hierarchical Size-based Paring》
论文作者:Chang Han, Anyi Li, Jaemin Jo, Bongshin Lee, Oliver Deussen, Yunhai Wan
Treemap 简介
引用 http://www.tuzhidian.com:3000/chart?id=5c56e2434a8c5e048 189c6a5 的描述:
“树图,或者矩形树图,是一个由不同大小的嵌套式矩形来显示树状结构数据的统计图表。在矩形树图中,父子层级由矩形的嵌套表示。在同一层级中,所有矩形依次无间隙排布,他们的面积之和代表了整体的大小。单个矩形面积由其在同一层级的占比决定。”

本篇精读论文,主要介绍了时序treemap构建算法SizePairs,并设计了一系列实验与当前先进方法进行对比,证明了其能够生成美观且稳定的时序treemap布局,相关截图如无特别说明均来自论文。
算法目标
该算法的目标是快速生成稳定且平衡的treemap:
稳定:treemap在不同时间点应保持布局的稳定,每一项数据不会移动太多
平衡:各个矩形的长宽比比较平衡,尽可能美观(【2/3,1】的长宽比范围较为合适)
快速:算法耗时不能太长
论文中总结的算法设计目标如下:
• DG1. Create the layout of each time step as square as possible;
• DG2. Maintain the stability over time as much as possible; and
• DG3. Generate temporal treemaps as fast as possible.
算法思想
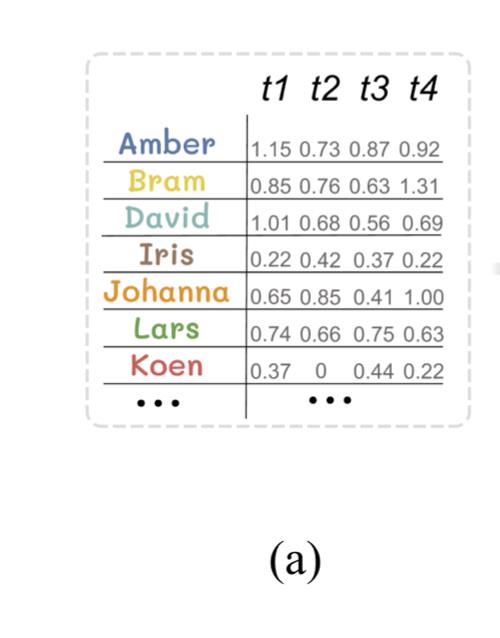
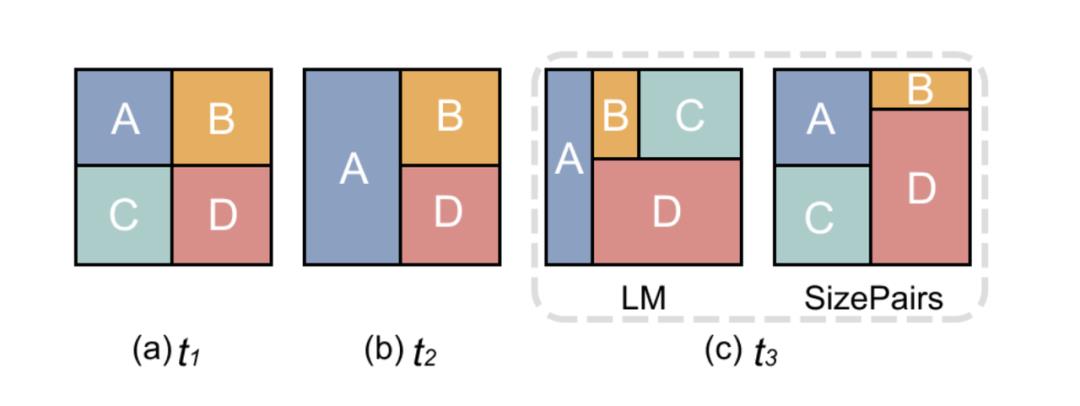
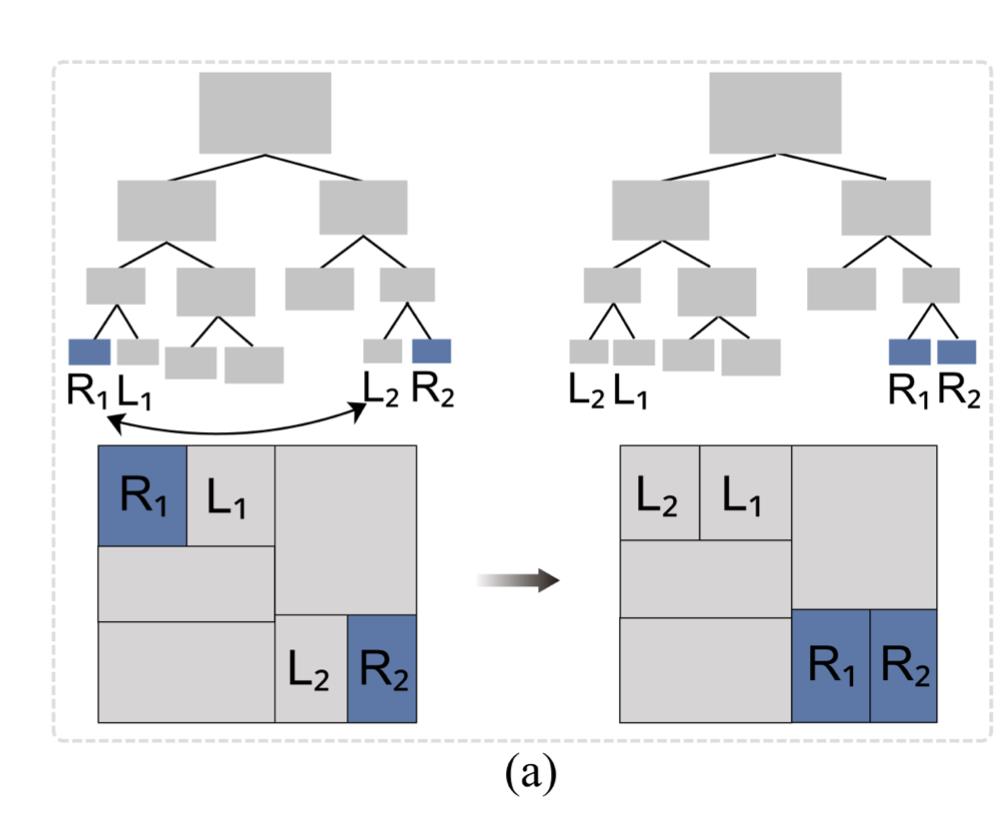
传统的treemap生成方法是不断对矩形进行递归划分,如下图(a,b,c):

若采用传统方法针对每一帧数据单独生成treemap布局,可以看到同一数据生成图形的位置变化较大,这在时序数据中很难用连贯且平滑的方式展现数据变化的过程。
时序数据在变化过程中,变化趋势相反的数据项可以相互弥补:

上图展示了两个连续的时间帧中具有相反变化趋势的两个矩形。红色圆圈代表每个矩形的中心,绿色三角形代表整体布局的中心。可以看出当黄色矩形变小时,腾出的空间正好被蓝色矩形占满,从而使得整体中心保持不变。
将能够相互弥补的数据项放在一块,能够实现局部布局的稳定,从而实现整体布局的稳定效果。
采用层次打包配对的思想,不断寻找具有这种特性的数据项,将他们两两打包在一起。根据打包结果指导最终布局的生成。
同时,从全局的视角,而不仅仅是相邻的两个时间步对数据进行优化,能够取得更好的稳定性。
算法流程

输入数据
该算法针对的是时序(文本)数据,每一项数据在不同时间点都有不同的权重:
生成树构建
量化指标
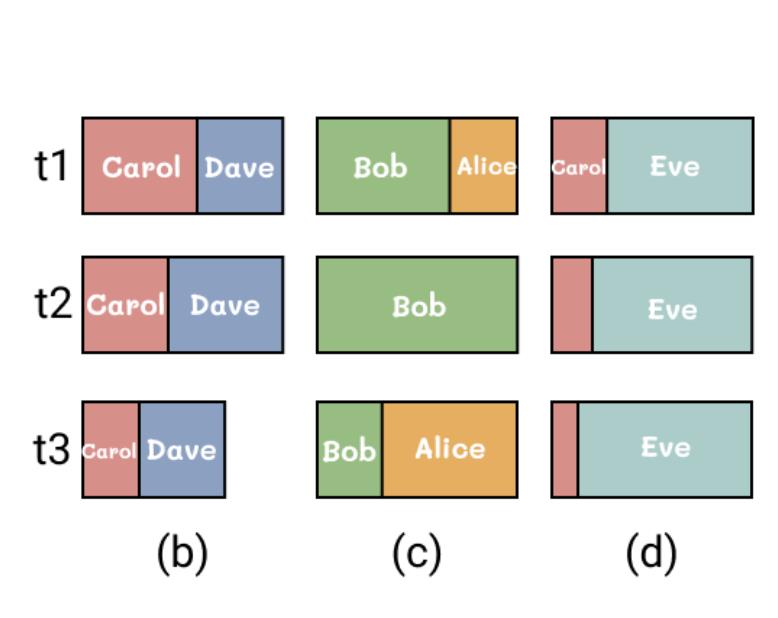
Compensation Degree:衡量两个数据项i和j在所有时间步中相互弥补程度

在分子上,变化程度相反的两个数据项可以相互抵消,越小说明相互弥补的程度越好
Size Difference :衡量两个数据项i和j的差异程度
有些数据虽然相互弥补的程度很好,但是其长宽比差异过大,导致美观程度下降(b vs d)
因此定义了数据差异程度的量化指标:
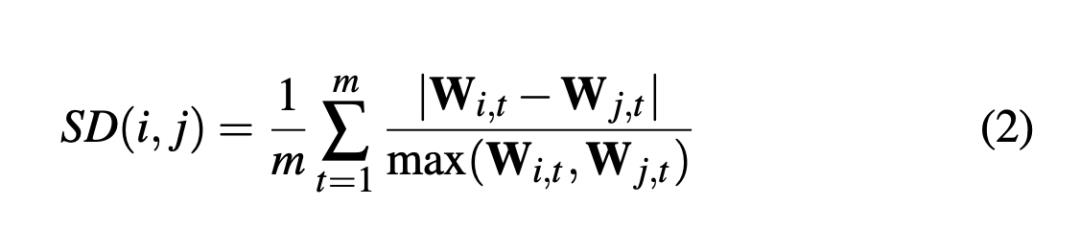
该指标越小说明两个数据项越相似,将它们放在一块,可以避免极端情况的出现。
将上面两个指标结合,给i和j进行打分:
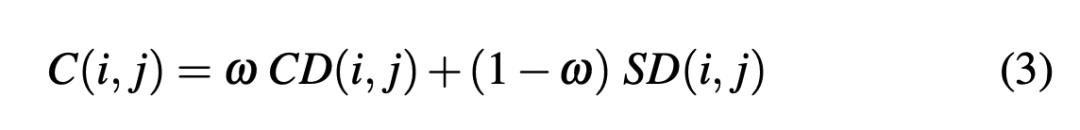
通过权重w在两项指标之间进行平衡,w=0.5 是一个推荐值。
层次打包
根据计算出的C(i,j),不断迭代,选择得分最优的两个数据项进行打包。打包后的两个数据项作为一个整体,参与下一轮迭代
(a)展示了传统的层次打包算法,每次选择得分最优的一对合并,并更新得分C(i,j)

为了避免极端情况的出现,规定面积大于所有矩形面积之和的2/3的矩形作为super nodes,并规定super nodes只能与super nodes相互打包。
打包算法流程
首先将所有数据项作为叶子节点,并计算相互之间的打包得分C(i,j)。首先将所有的super nodes移除,对所有的非super nodes进行迭代:每次选择得分最优的一对i j进行合并,再从剩下的非super nodes中选择得分最好的进行合并。不断重复直到无法合并为止。对所有新形成的节点,更新得分并挑出super nodes。不断重复,直到只剩下一个节点,或者没有节点剩余为止。
对于所有的super nodes,采用传统的层次打包算法,每次选择得分最优的一对合并,并更新得分C(i,j),直到只剩余一个节点为止。
打包算法伪代码

Treemap 布局生成
通过层次打包得到生成树之后,可以用来指导布局的生成
确定包内布局方向
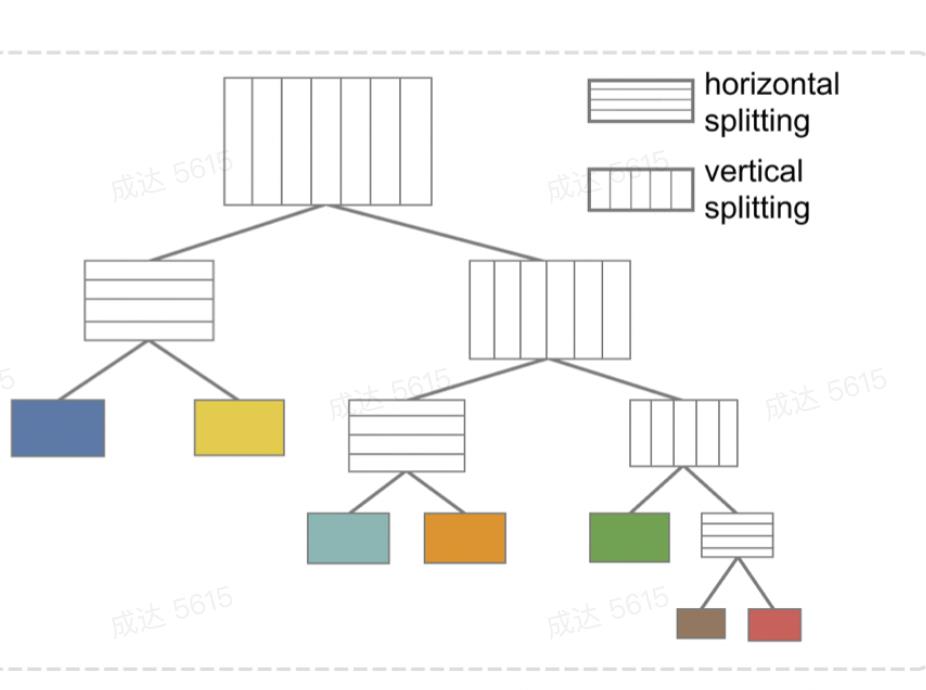
采用每个数据项在所有时间步中的权重的中位数,作为其权重来对矩形进行划分。在水平与垂直划分之间,选择长宽比更优的一种划分方式。在每一帧中都保持这种划分方式,得到最终的treemap布局
可选项:针对每个时间步单独调整包内布局方向
为了进一步改善视觉效果,对于层次树中的倒数第二层的节点,在每个时间步中,针对水平与垂直两种划分方式,分别计算其里面的两个节点的长宽比a1,a2,并计算a1/a2,选择比值大于1.1的那种布局方式,作为在该时间步内的布局方式。
可以看做是一种局部调整。
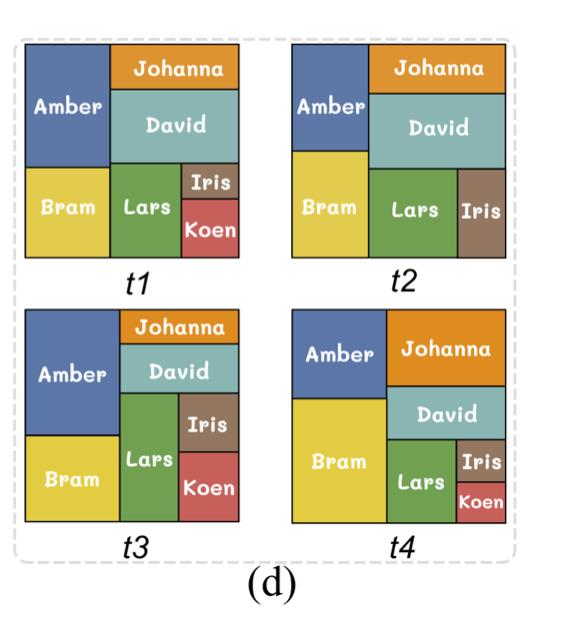
最后得到了treemap的布局:
对交互的支持
删除/插入数据
对于删除/插入的数据,只需要将其后面/前面的时间步里面的权重设为0即可。sizePairs布局算法可以保持整体布局的稳定。
数据比较
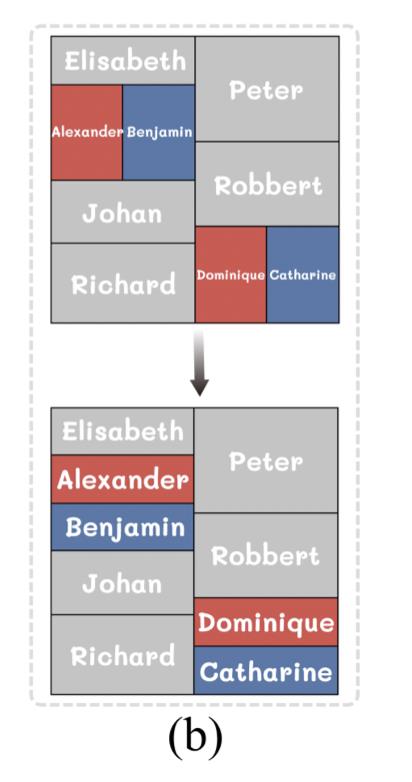
若用户对两个数据项比较感兴趣,想对其进行对比。传统的treemap很难保证能将这两项数据放在一起进行比较。对于sizePairs,只需要将用户选择的两个数据项所对应的叶子节点打包在一起即可
标签友好
交互式的数据探索中往往会在treemap里引入标签。sizePairs可以得到一种分层的结构,允许通过调整父节点内两个子节点的布局方向,来完全兼容子节点的标签展示。
算法评价
评价指标
Corner-travel distance

对每个矩形,对于相邻的两个时间步,计算其Corner-travel distance并取平均值。
w(R),h(R)是整体布局的宽度,用来衡量short-term stability。
Normalized location drift
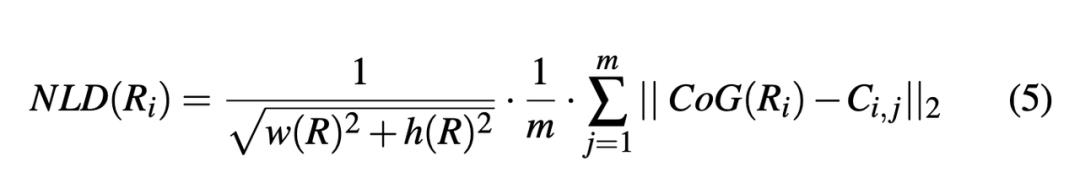
C(i,j)是矩形i在时间步j的中心,CoG(Ri)是所有时间步中矩形中心的平均值,用来衡量long-term stability。
Aspect ratio
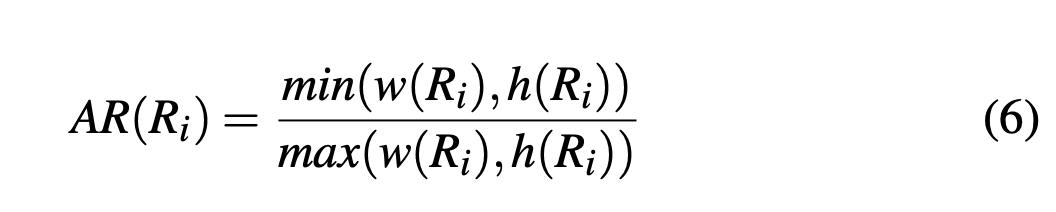
矩形的长宽比,所有矩形所有时间步取平均值。
实验结果


从结果中我们可以看到,使用SizePairs 算法,各项指标都能得到一个比较好的结果。
几点思考
时序数据布局 统一的算法框架
抽象总结本文的算法框架,可以看出其采用时序数据变化过程中相互弥补保持稳定的思想,
先设定了两个优化目标:布局稳定性、美观程度
通过打包将能够相互弥补的两个数据放到一块,实现稳定性。在打包过程中,兼顾美观性
设计与稳定性、美观性相关量化指标,衡量两个数据项打包的好坏:

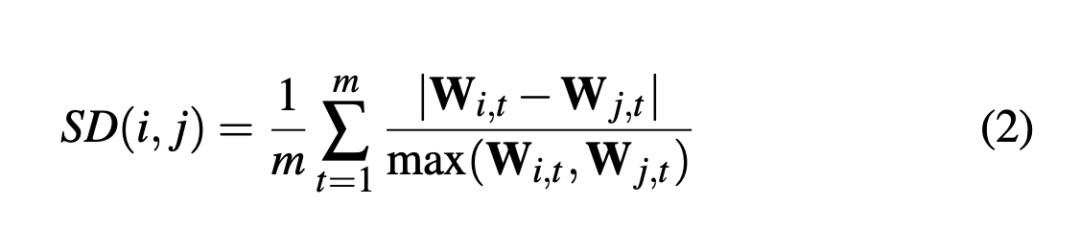
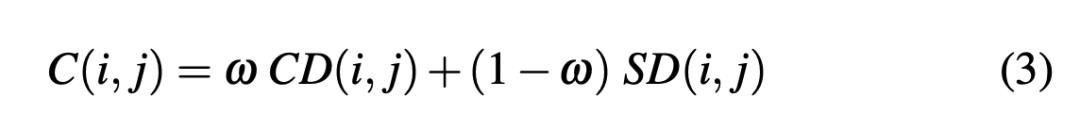
通过参数在多个指标间进行平衡
对于这种NP难的问题,采用启发式的层次打包方法,找出最优的打包方案,确定全局的布局
再设计了与美观性相关的度量指标,确定包内的布局,得到最终的布局结果
对于追求稳定性与美观性的时序数据可视化,都可以采用此算法框架。
例如,该算法可无缝应用到时序词云的布局中。
在时序词云中,主要追求高稳定性、低空白率与合适的长宽比
只需要将算法中的打分函数换成与词云稳定性相关的度量函数,根据空白率、长宽比确定包内的布局,采用完全相同的算法流程,就可以得到一个很好的时序词云布局,用来生成词云动画:



其他
历年VIS报告:https://www.youtube.com/c/IEEEVisualizationConference
以上是关于论文精读HumanNeRF的主要内容,如果未能解决你的问题,请参考以下文章