PS CS6视频剪辑基本技巧视频剪接和添加图片
Posted 一只爬爬虫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PS CS6视频剪辑基本技巧视频剪接和添加图片相关的知识,希望对你有一定的参考价值。
系列讲座导读
上一讲,介绍了PS CS6可以实现视频剪接、添加图片、添加声音、添加字幕、添加logo、添加动画等6种功能,今天这讲介绍一下视频剪接和添加图片这两个功能。
目录
一、基本操作
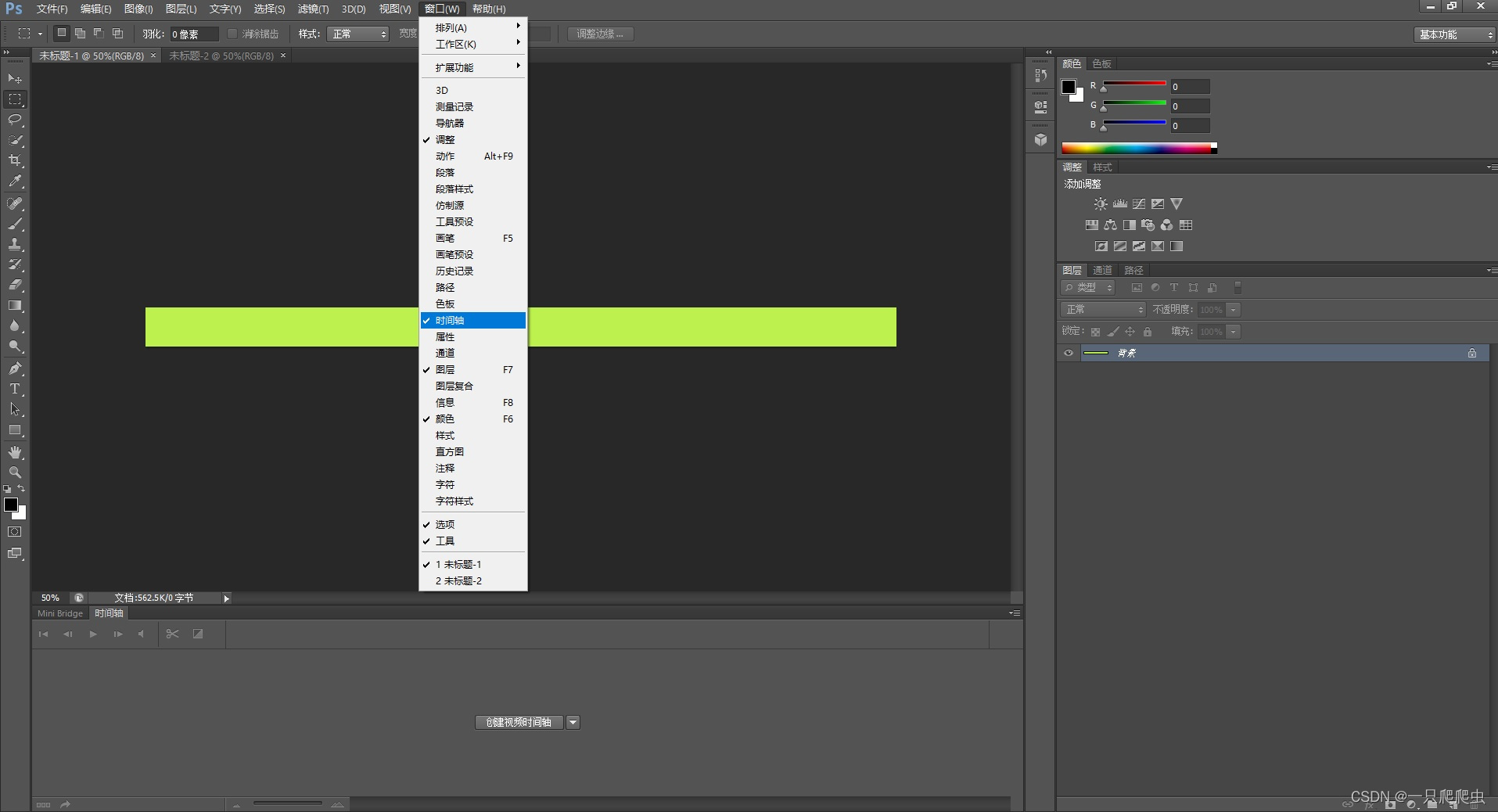
首先打开CS6,如果在主工作区域下方没有时间轴这个窗口,那么需要提前打开这个窗口,操作步骤:
1、打开时间轴窗口
菜单“窗口”->勾选“时间轴”
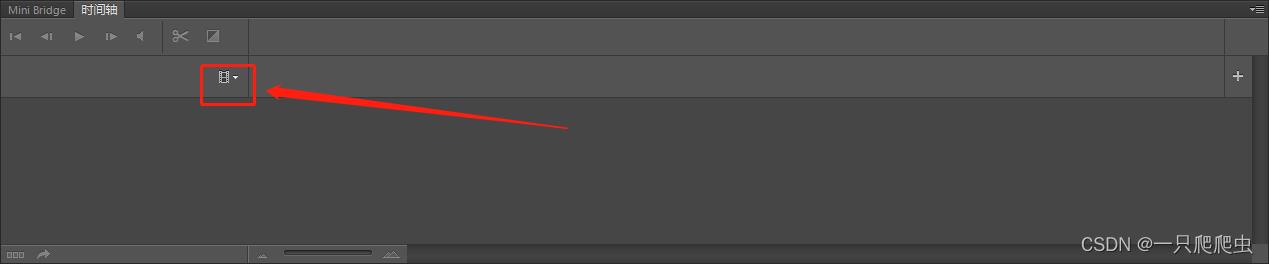
2、创建时间轴
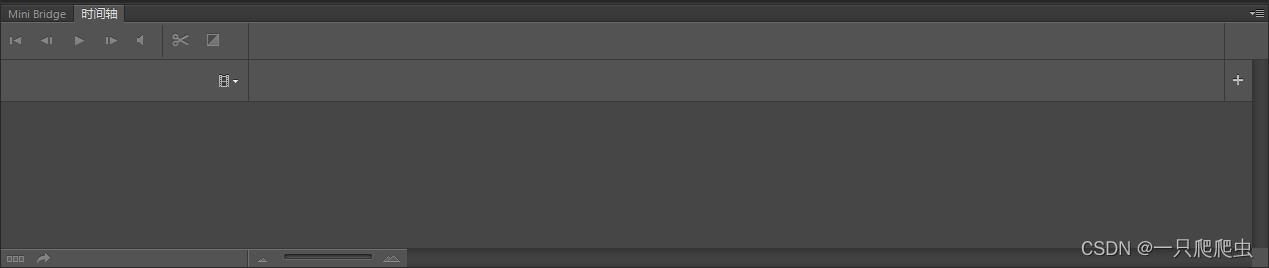
如果此时工作区内没有任何的图层,那么勾选时间轴后的时间轴窗口如图1-2所示:
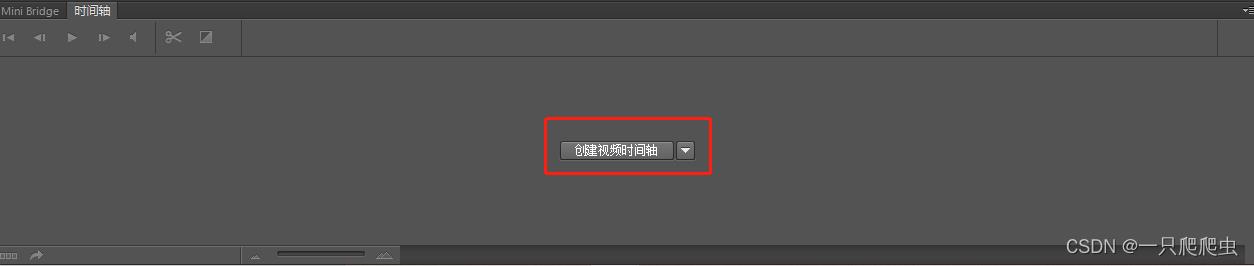
如果已经存在一个背景层,那么时间轴窗口如图1-3所示。
点时间轴窗口中间的“创建视频时间轴”按钮,然后在时间轴窗口出现如图1-4所示信息:
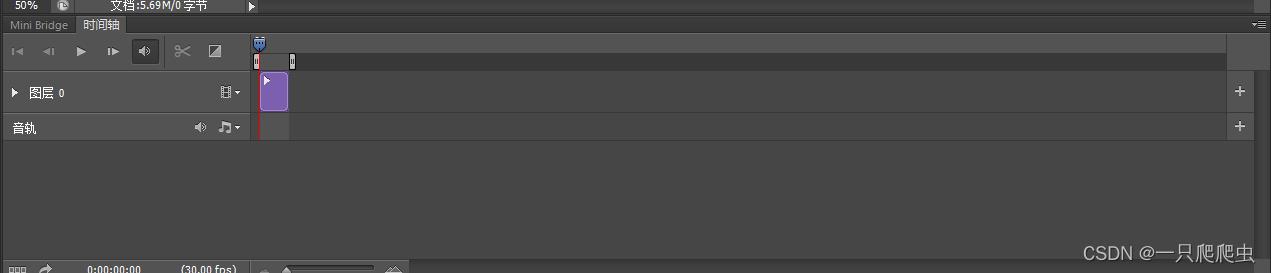
图层0:指刚刚打开CS6时创建的一个文件背景层,这个层就是我们将来要剪接视频、添加图片的层,点击视频图标后边的▼,在弹出的菜单中有“添加媒体”和“新建视频组”两个功能,前者就是在图层0这一个视频组添加视频或者图片文件;后者就是再另外新建一个视频组。

音轨:指和背景层同步播放的音频,这个就是我们将来要添加声音的层。
点音轨栏右边音频符号后面的▼,在弹出的菜单中有“添加音频”和“新建音轨”两个选项,前者是为此音轨添加音频文件,后者是新建一个音轨。
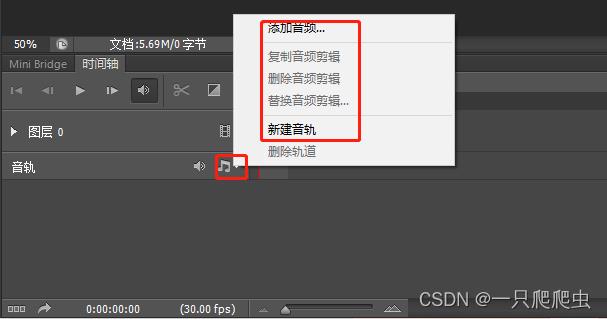
注意:最终的视频成品文件,可能由多个视频组和多个音轨组成。
二、视频剪接
1、打开已存在的视频文件
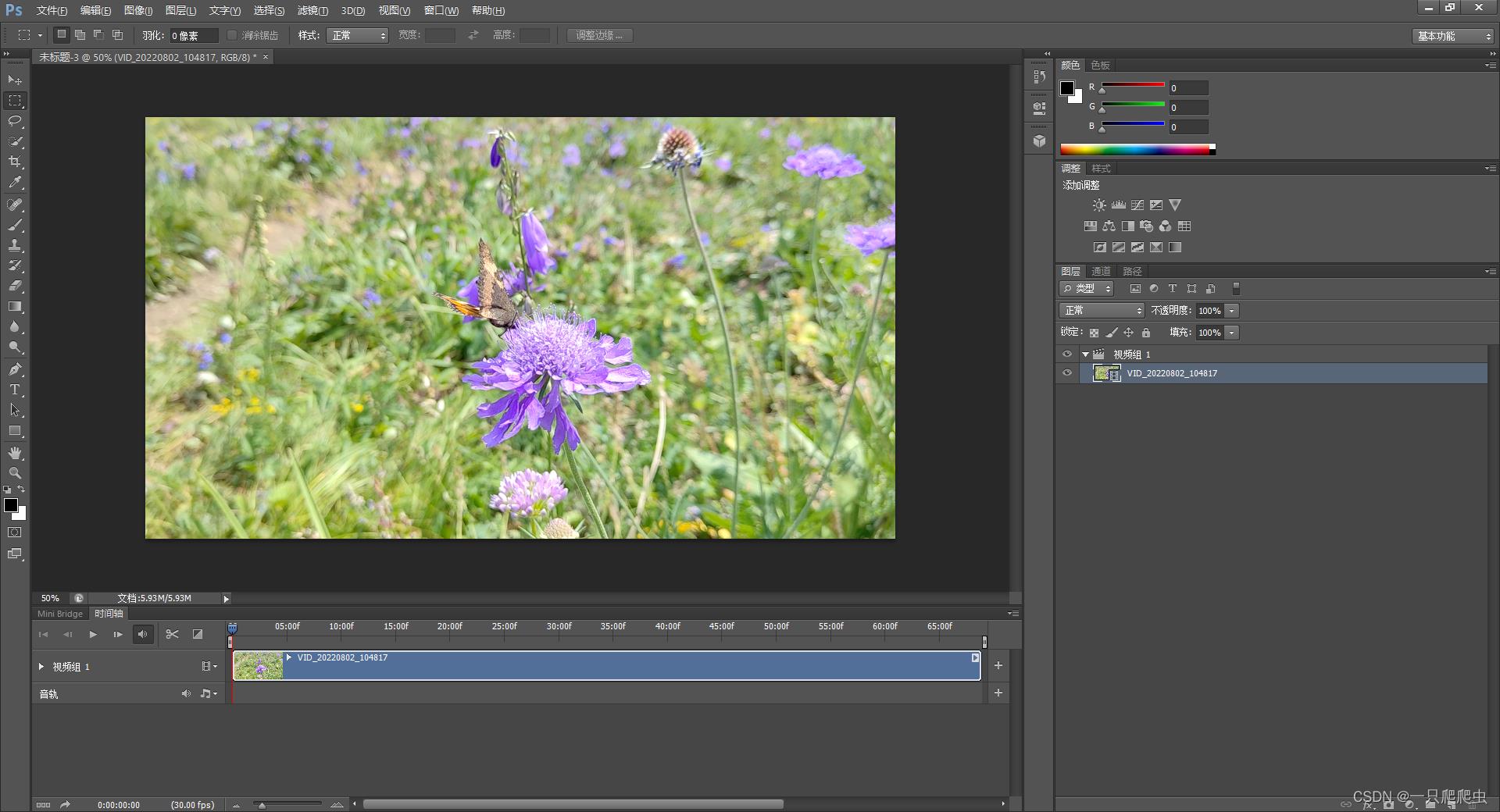
如图2-1所示,单击添加视频图标,然后在2-2所示的弹出菜单中点“添加媒体”,然后在弹出的“添加剪辑”对话框中选择你需要的mp4文件添加进来,添加后的效果如图2-3所示,添加完成后会自动把视频文件分成视频组和音轨两部分。

2、修改视频组和视频片段名称
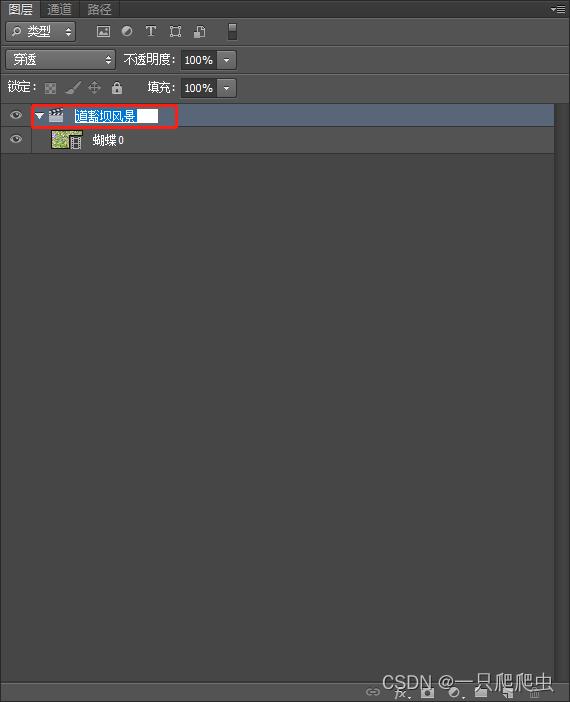
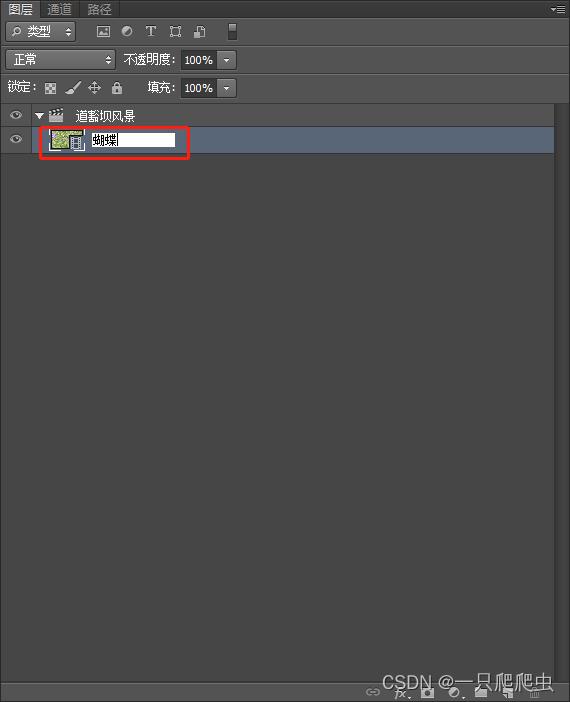
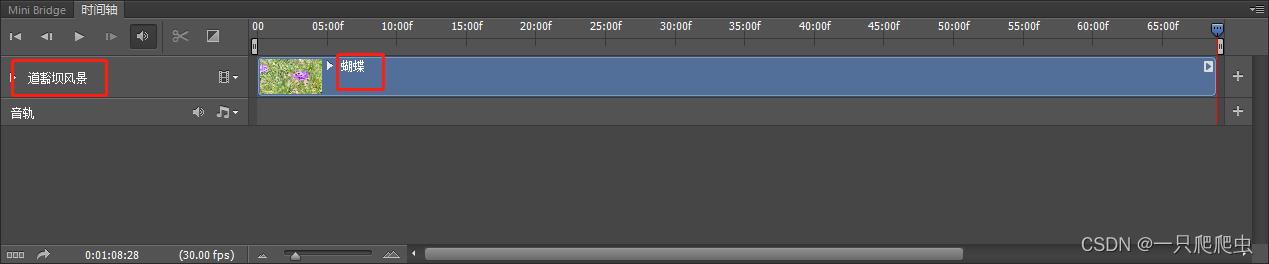
通过双击图层管理器中的视频组名称,可以改动这个名字,如图2-4所示,改为“道豁坝风景”。也可以双击视频组内某个视频的名字,改动这段视频的名称,如图2-5所示,把视频名称改为“蝴蝶”。注意,当图层区的视频组和视频名称修改之后,时间轴窗口的名称也相应改变,如图2-6所示。
3、添加另外一个视频
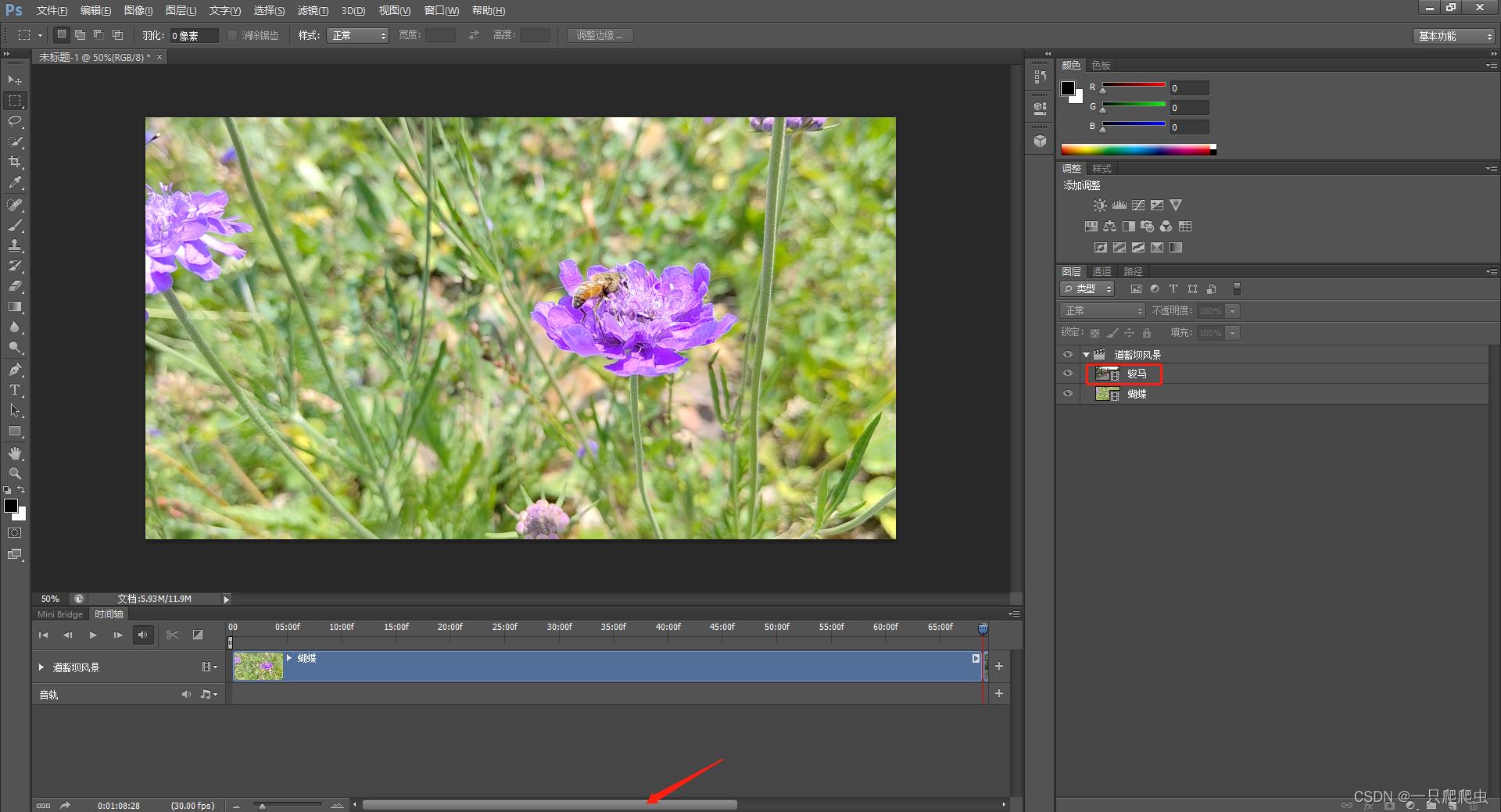
在“道豁坝风景”这个视频组内,再添加另外一个视频片段,并改名字为“骏马”,如图2-7所示。
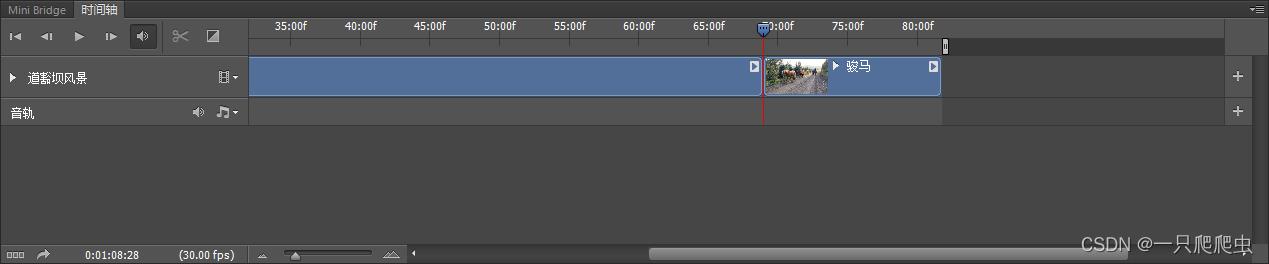
在时间轴区域,由于第一个视频占据了时间较长,所以新添加的“骏马”片段看不到,那么需要拖放一下对话框下侧的滑块就能看到了,如图2-8所示。
或者,通过调节“控制时间轴显示比例”滑块来缩小比例,即可完全显示出两个视频片段,如图2-9所示。

在同一个视频组添加两个视频,这两个视频在时间上是连续的,这样就相当于把两个视频片段拼接在了一起。
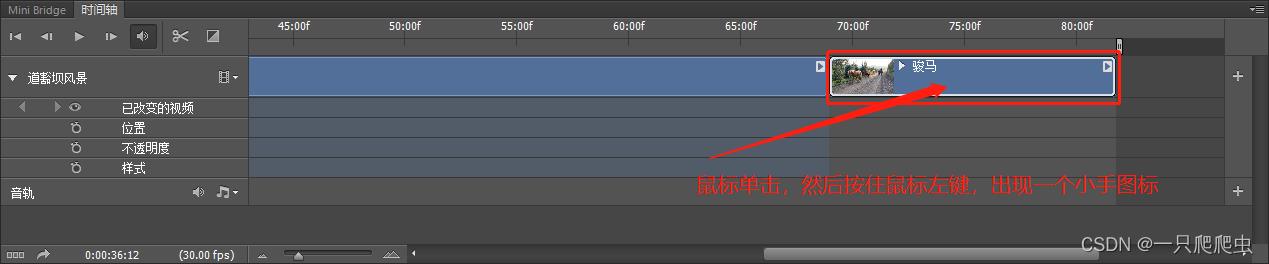
4、调节视频片段的播放顺序
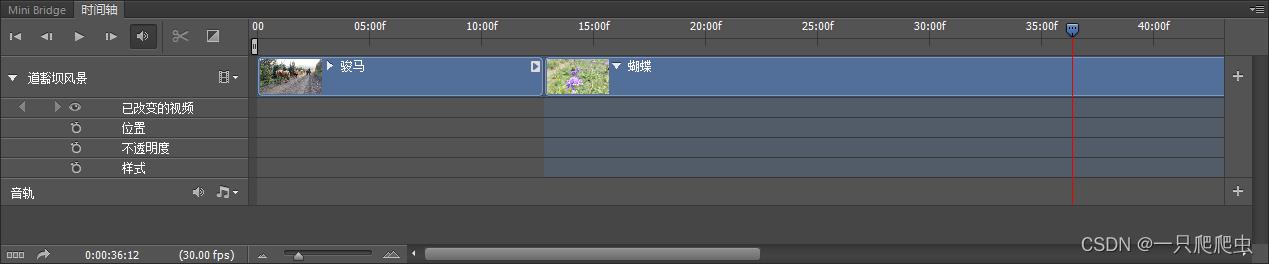
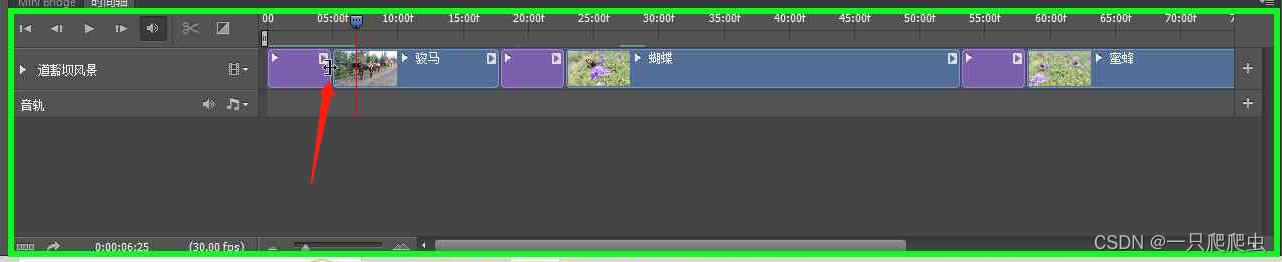
当想调整视频片段播放顺序时,只需要鼠标单击选中要调整的片段,然后按住鼠标左键,出现小手图标,如图2-10所示,然后拖动这个片段,移动到需要的播放位置即可,如图2-11所示。
5、剪开视频片段
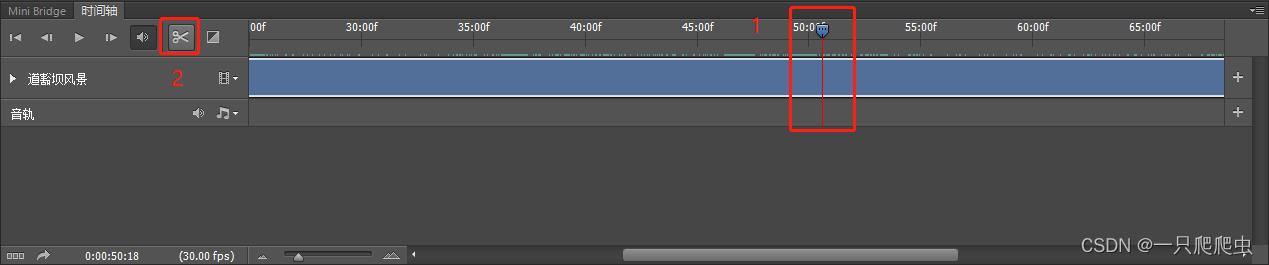
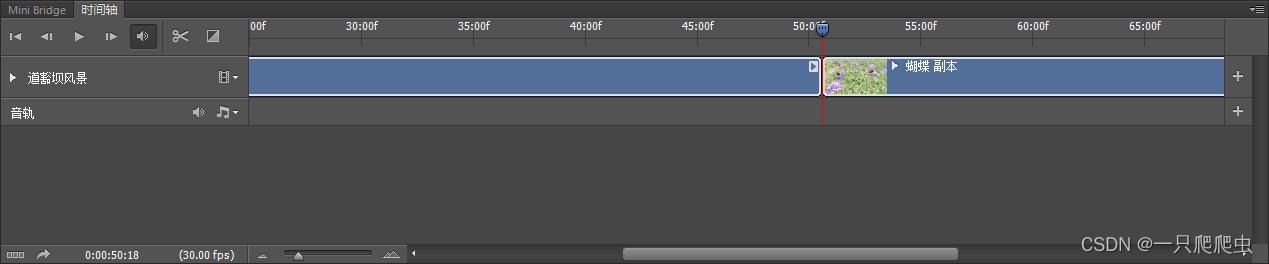
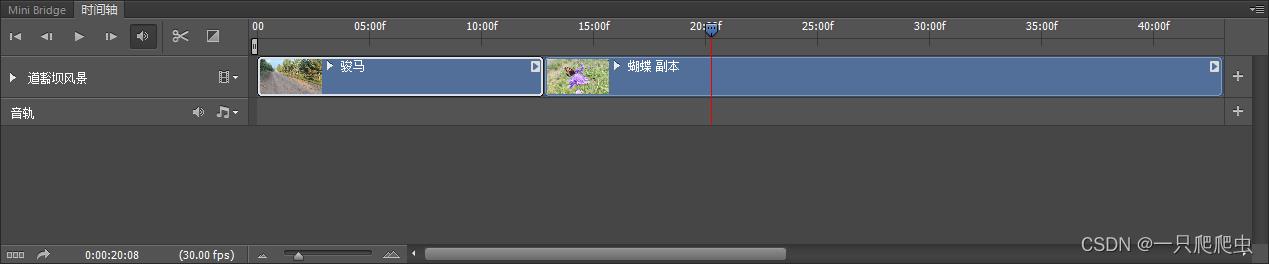
如果想在某一个视频片段中间插入其他视频或者图片,那么就需要先在插入点剪开。比如在“蝴蝶”这个视频片段中,前半段是蝴蝶,后半段是蜜蜂,想把两部分剪开。操作方法:首先把时间轴播放滑块拖放到要剪开的地方,如图2-12所示。然后单击“在播放头处拆分”图标,就是那个小剪刀,既可以完成剪开动作,剪开后的效果如图2-13所示,剪开的前半部分视频片段名称不变,后半部分名称系统自动命名为“蝴蝶副本”,我们可以改成自己需要的“蜜蜂”即可。
6、剪掉视频片段中的一部分
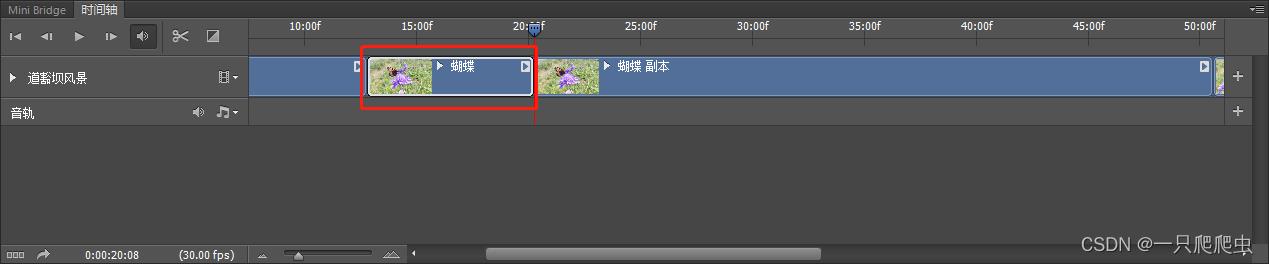
比如在本例中,在蝴蝶视频部分,从15:00f-20:00f这个时间段的是不想要的,那么15:00f处是视频的开头,那么还需要在20:00f这里再剪一刀,如图2-14所示。然后选中要删除的这一段,按delete键即可删掉了,如图2-15所示。
三、插入图片
在一段视频中插入图片和插入其他视频是一样的操作。
比如,本例在骏马、蝴蝶、蜜蜂三个视频片段前边各插入一张jpg格式静态图片,上边分别写有“骏马”、“蝴蝶”、“蜜蜂”两个字,三张图片的分别率为1920像素*1080像素,如图3-1、3-2、3-3所示。



操作步骤:
1、插入图片
点“道豁坝风景”视频组的“添加媒体”,选中三幅图片,点“打开”,就把三张图片一起添加到视频组了,注意默认最新添加的文件都放在视频组的最后,如图3-4所示。
2、移动图片
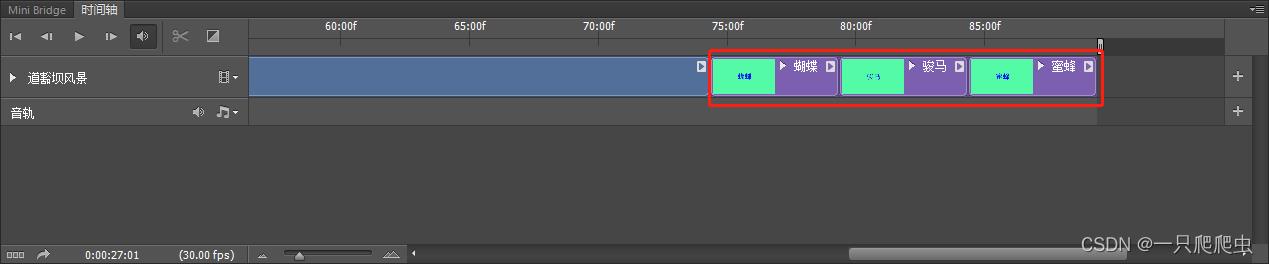
拖动三张图片,放到相应位置,如图3-5所示。
3、改变图片播放时间
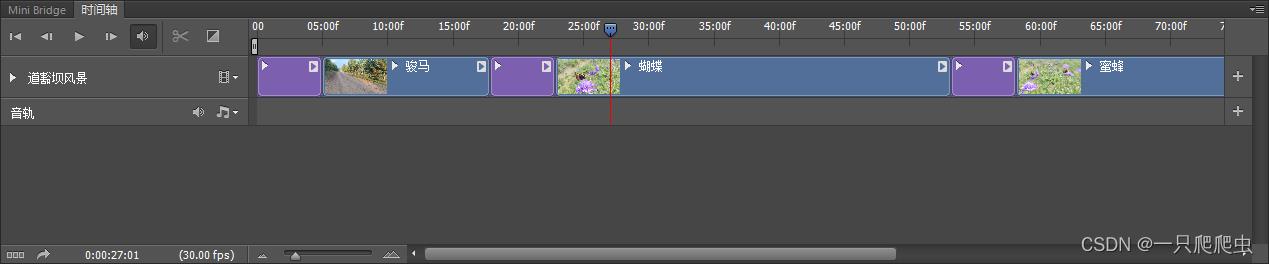
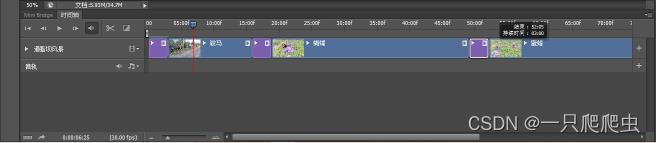
图片默认播放时间为5秒钟,可以调短一些,选中“骏马.jpg”,鼠标放在这个图片片段的最右边缘,出现一个如图3-6所示的光标,然后拖动鼠标,把播放时间调整为3秒钟,同样也把蝴蝶.jpg、蜜蜂.jpg两个图片播放时间也调短为3秒,如图3-7所示。
4、播放预览
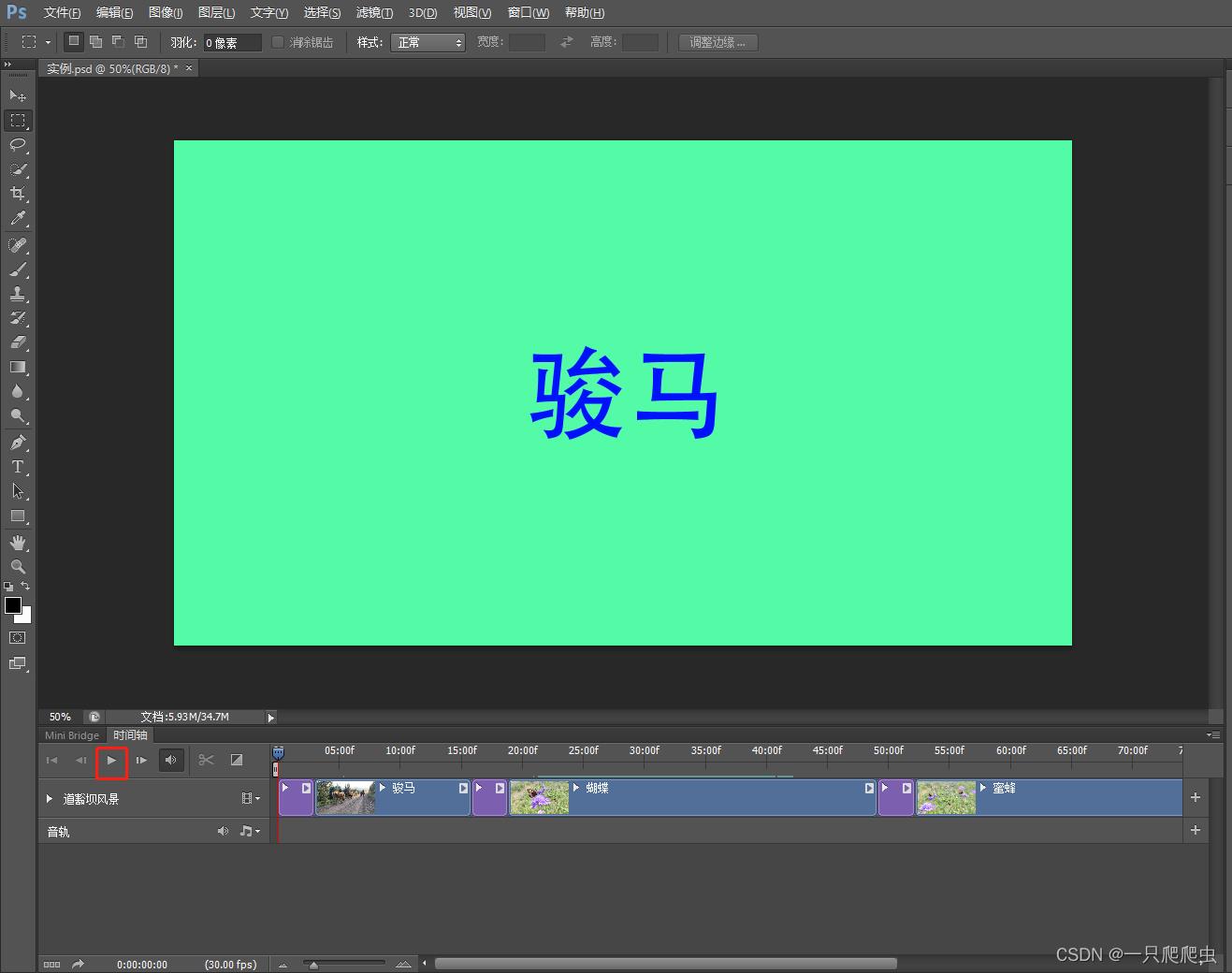
点击播放按钮,如图3-8所示,既可以看到播放效果,gif格式的图片如图3-9所示。

『cs231n』视频数据处理
视频信息
和我之前的臆想不同,视频数据不仅仅是一帧一帧的图片本身,还包含个帧之间的联系,也就是还有一个时序的信息维度,包含人的动作判断之类的任务都是要依赖动作的时序信息的
视频数据处理的两种基本方法

- 使用3D卷积网络引入时间维度:由于3D卷积网络每次的输入帧是有长度限定的,所以这种方法更倾向于关注局部(时域)信息的任务
- 使用RNN/LSTM网络系列处理时序信息:由于迭代网络的特性,它更擅长处理全局视频信息

发散:结合两种方法的新思路
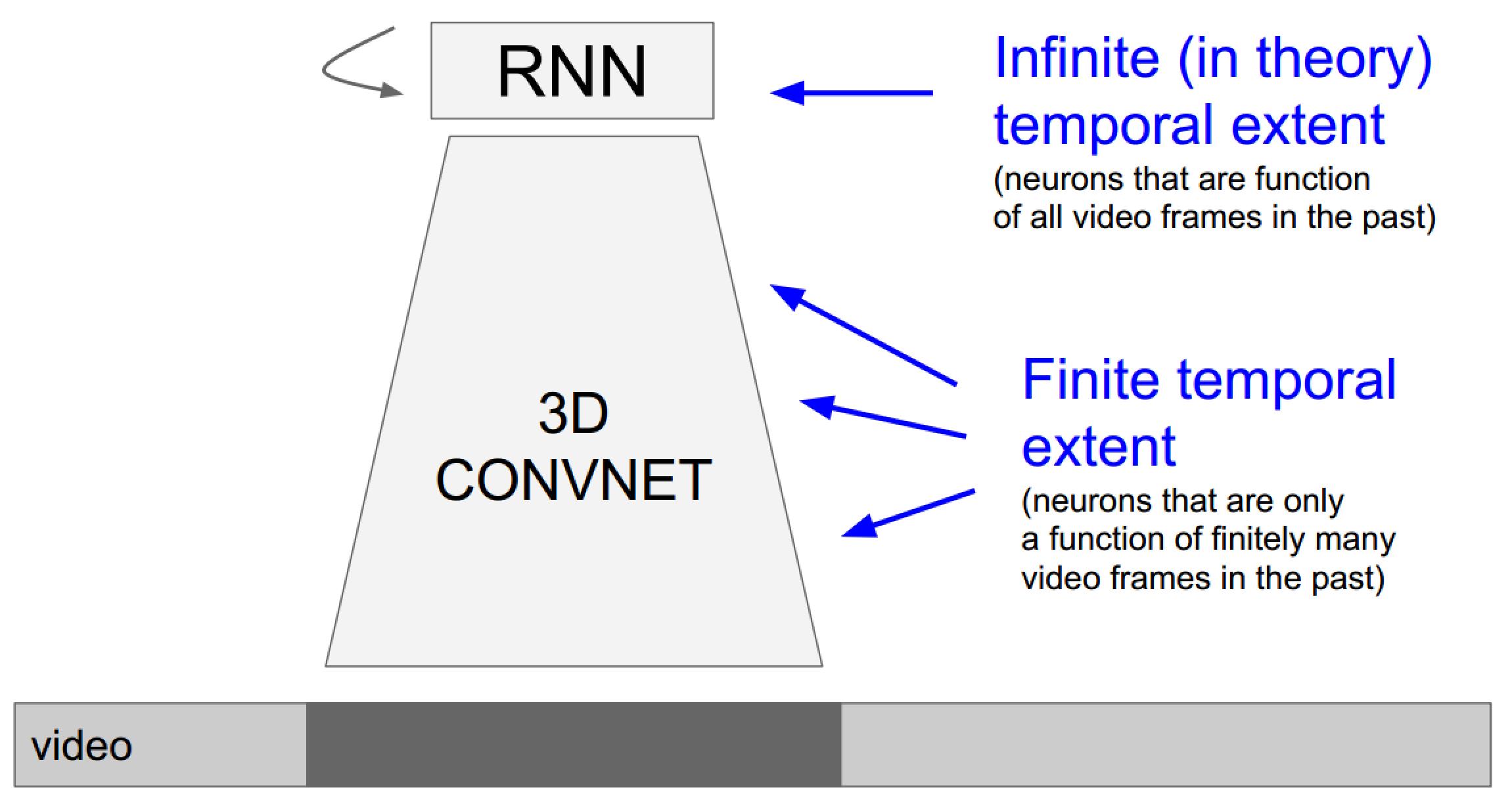
上面的具体实现也未必需要3D卷积,毕竟递归网络自己已经包含了时序信息了:
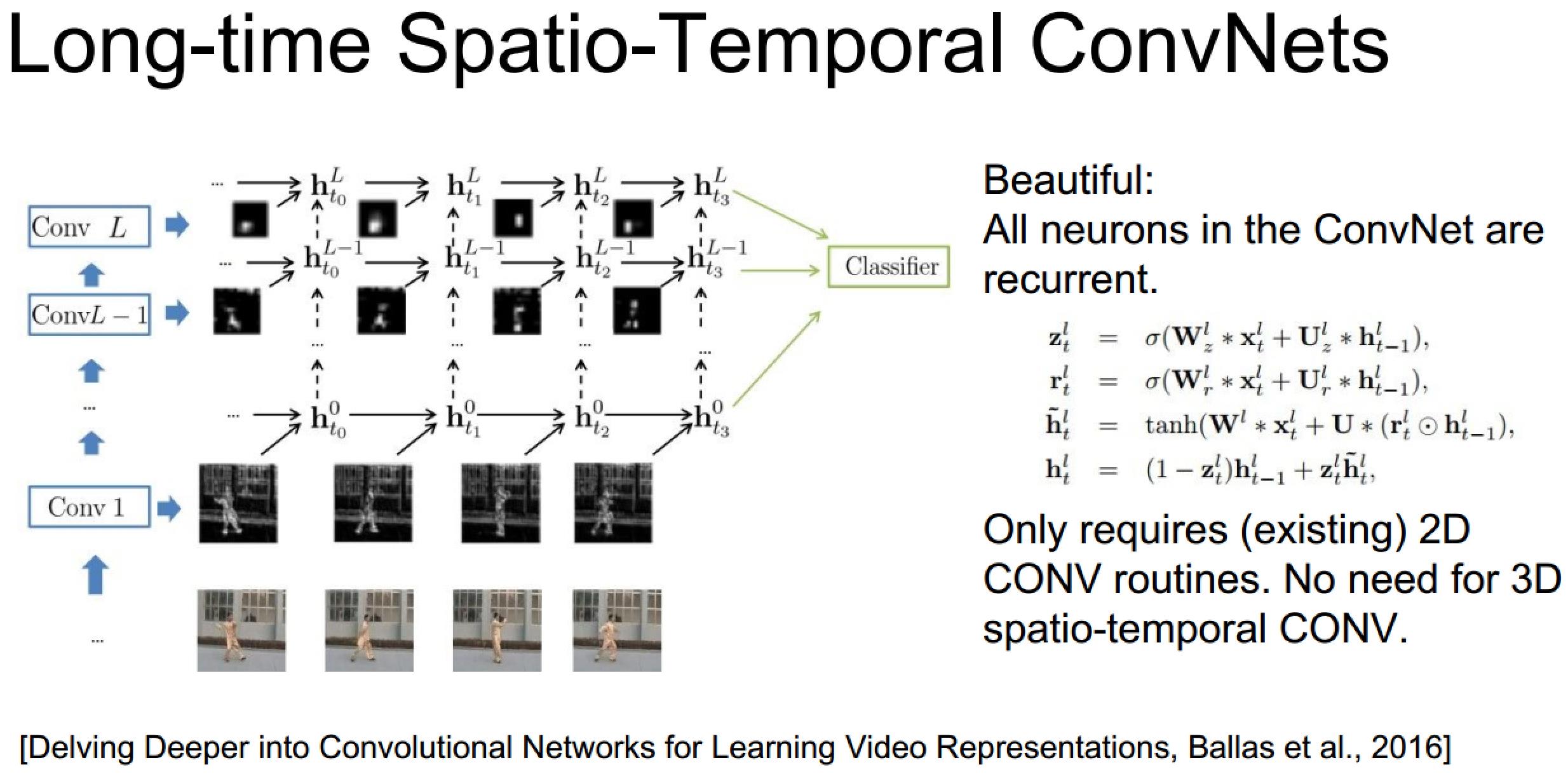
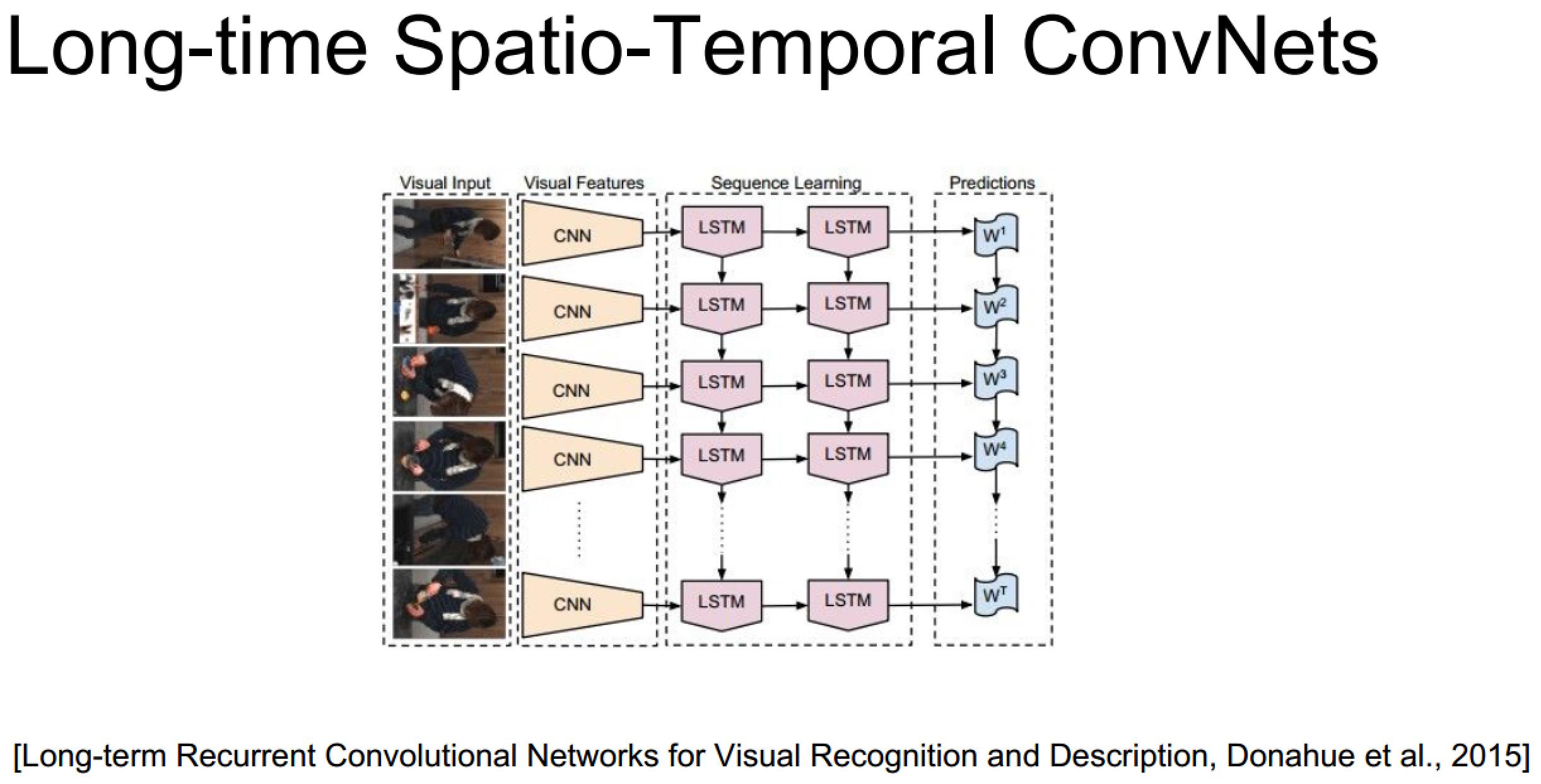
3D卷积神经网络理解
1、3D卷积
3D卷积是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用3D卷积核。在这个结构中,卷积层中每一个特征map都会与上一层中多个邻近的连续帧相连,因此捕捉运动信息。例如下图,一个卷积map的某一位置的值是通过卷积上一层的三个连续的帧的同一个位置的局部感受野得到的。
需要注意的是:3D卷积核只能从cube中提取一种类型的特征,因为在整个cube中卷积核的权值都是一样的,也就是共享权值,都是同一个卷积核(图中同一个颜色的连接线表示相同的权值)。我们可以采用多种卷积核,以提取多种特征。
对于CNNs,有一个通用的设计规则就是:在后面的层(离输出层近的)特征map的个数应该增加,这样就可以从低级的特征maps组合产生更多类型的特征。
传统的2D卷积方法是用一个2维的卷积层对特征图进行采样,从而得到下一层的特征图,形式如下:


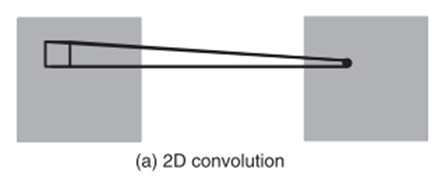
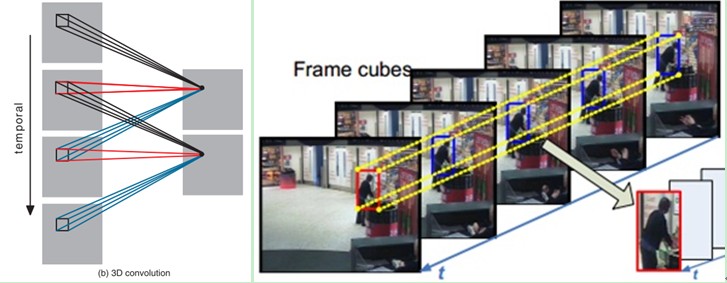
tf.nn.conv3d(input, filter, strides, padding, name=None) Computes a 3-D convolution given 5-D input and filter tensors. In signal processing, cross-correlation is a measure of similarity of two waveforms as a function of a time-lag applied to one of them. This is also known as a sliding dot product or sliding inner-product. Our Conv3D implements a form of cross-correlation. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, in_depth, in_height, in_width, in_channels]. filter: A Tensor. Must have the same type as input. Shape [filter_depth, filter_height, filter_width, in_channels, out_channels]. in_channels must match between input and filter. strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1. padding: A string from: "SAME", "VALID". The type of padding algorithm to use. name: A name for the operation (optional). Returns: A Tensor. Has the same type as input. tf.nn.avg_pool3d(input, ksize, strides, padding, name=None) Performs 3D average pooling on the input. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, depth, rows, cols, channels] tensor to pool over. ksize: A list of ints that has length >= 5. 1-D tensor of length 5. The size of the window for each dimension of the input tensor. Must have ksize[0] = ksize[4] = 1. strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1. padding: A string from: "SAME", "VALID". The type of padding algorithm to use. name: A name for the operation (optional). Returns: A Tensor. Has the same type as input. The average pooled output tensor.
tf.nn.max_pool3d(input, ksize, strides, padding, name=None) Performs 3D max pooling on the input. Args: input: A Tensor. Must be one of the following types: float32, float64, int64, int32, uint8, uint16, int16, int8, complex64, complex128, qint8, quint8, qint32, half. Shape [batch, depth, rows, cols, channels] tensor to pool over. ksize: A list of ints that has length >= 5. 1-D tensor of length 5. The size of the window for each dimension of the input tensor. Must have ksize[0] = ksize[4] = 1. strides: A list of ints that has length >= 5. 1-D tensor of length 5. The stride of the sliding window for each dimension of input. Must have strides[0] = strides[4] = 1. padding: A string from: "SAME", "VALID". The type of padding algorithm to use. name: A name for the operation (optional). Returns: A Tensor. Has the same type as input. The max pooled output tensor.
2、3D卷积神经网络架构
文中的3D CNN架构包含一个硬连线hardwired层、3个卷积层、2个下采样层和一个全连接层。每个3D卷积核卷积的立方体是连续7帧,每帧patch大小是60x40,架构如下:
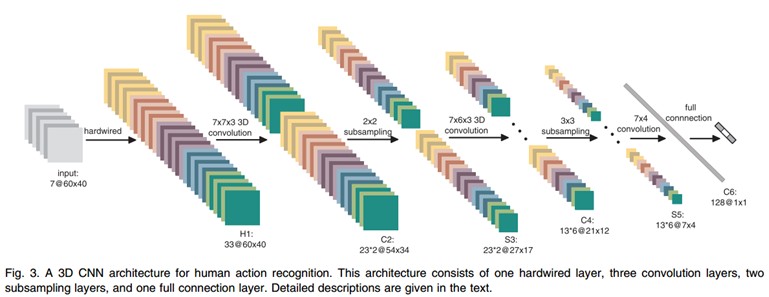
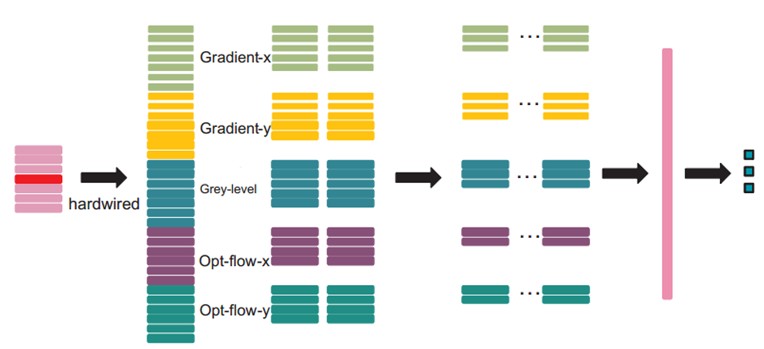
在第一层,我们应用了一个固定的hardwired的核去对原始的帧进行处理,产生多个通道的信息,然后对多个通道分别处理。最后再将所有通道的信息组合起来得到最终的特征描述。这个实线层实际上是编码了我们对特征的先验知识,这比随机初始化性能要好对于这个做法(原文“相比于随机初始化,通过先验知识对图像的特征提取使得反向传播训练有更好的表现”),梯度表征了图像的边沿的分布,而光流则表征物体运动的趋势,3D卷积通过提取这两种信息来进行行为识别。,每帧提取五个通道的信息分别是:灰度、x和y方向的梯度,x和y方向的光流。其中,前面三个都可以每帧都计算。然后水平和垂直方向的光流场需要两个连续帧才确定。所以是7x3 + (7-1)x2=33个特征maps。
然后我们用一个7x7x3的3D卷积核(7x7在空间,3是时间维)在五个通道的每一个通道分别进行卷积。为了增加特征map的个数(实际上就是提取不同的特征),我们在每一个位置都采用两个不同的卷积核,这样在C2层的两个特征maps组中,每组都包含23个特征maps。23是(7-3+1)x3+(6-3+1)x2前面那个是:七个连续帧,其灰度、x和y方向的梯度这三个通道都分别有7帧,然后水平和垂直方向的光流场都只有6帧。54x34是(60-7+1)x(40-7+1)。
在紧接着的下采样层S3层max pooling,我们在C2层的特征maps中用2x2窗口进行下采样,这样就会得到相同数目但是空间分辨率降低的特征maps。下采样后,就是27x17=(52/2)*(34/2)。
C4是在5个通道中分别采用7x6x3的3D卷积核。为了增加特征maps个数,我们在每个位置都采用3个不同的卷积核,这样就可以得到6组不同的特征maps,每组有13个特征maps。13是((7-3+1)-3+1)x3+((6-3+1)-3+1)x2前面那个是:七个连续帧,其灰度、x和y方向的梯度这三个通道都分别有7帧,然后水平和垂直方向的光流场都只有6帧。21x12是(27-7+1)x(17-6+1)。
S5层用的是3x3的下采样窗口,所以得到7x4。

到这个阶段,时间维上帧的个数已经很小了, (3 for gray, gradient-x, gradient-y, and 2 for optflow-x and optflow-y)。在这一层,我们只在空间维度上面卷积,这时候我们使用的核是7x4,然后输出的特征maps就被减小到1x1的大小。而C6层就包含有128个特征map,每个特征map与S5层中所有78(13x6)个特征maps全连接,这样每个特征map就是1x1,也就是一个值了,而这个就是最终的特征向量了。共128维。

经过多层的卷积和下采样后,每连续7帧的输入图像都被转化为一个128维的特征向量,这个特征向量捕捉了输入帧的运动信息。输出层的节点数与行为的类型数目一致,而且每个节点与C6中这128个节点是全连接的。
在这里,我们采用一个线性分类器来对这128维的特征向量进行分类,实现行为识别。
模型中所有可训练的参数都是随机初始化的,然后通过BP训练。
后面还有一些其他的处理,不过对于理解3D卷积意义不大了,不再赘述,有兴趣的自行查阅相关文章吧(cs231n课件上引用论文图时均给出了出处)
2、双流神经网络(了解发展脉络)
时间轴:时间+空间双流神经网络 -> 16年CVPR的3D卷积+双流网络
Two-Stream Convolutional Networks for Action Recognition in Videos提出的是一个双流的CNN网络,分别捕捉空间和时间信息
3D Convolutional Neural Networks for Human Action Recognition提出了3D卷积方法
Convolutional Two-Stream Network Fusion for Video Action Recognition在原双流论文的基础上做了改进

左边是单纯在某一层融合,右边是融合之后还保留时间网络,在最后再把结果融合一次。论文的实验表明,后者的准确率要稍高。
融合的前提要求是,在这一层,空间与时间网络的特征图长宽相等,且channel数一样(channel在很多论文都有提及,暂时的理解是,channel就代表对应的卷积层中,特征图的个数,因为对上一层输入的特征图,每用一个卷积核,就会产生一个新的特征图,所以需要一个channel来统计总共产生了多少特征图)。具体融合方法很多,详见论文即可。
在把两个网络的特征图融合后,还需要进行另一次卷积操作。假设在时间t,我们得到的特征图是xt,那么对于一大段时间t=1….T,我们要把这段时间内的所有特征图(x1,…,xT)综合起来,进行一次3D时间卷积,最后得到的,就是融合后的特征图输出。注意,此时输出的,仍然是一系列在时间上的特征图。然后再输入到更高层网络,继续训练学习。
以上是关于PS CS6视频剪辑基本技巧视频剪接和添加图片的主要内容,如果未能解决你的问题,请参考以下文章
单反拍摄的图片在电脑上无法查看光圈值等详细信息,也用过cs6和exif还是无法查看,该怎么解决