自监督学习之掩码自动编码器(Masked Autoencoders, MAE)——音频识别方面
Posted 没用的阿鸡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自监督学习之掩码自动编码器(Masked Autoencoders, MAE)——音频识别方面相关的知识,希望对你有一定的参考价值。
自监督学习之掩码自动编码器(Masked Autoencoders, MAE)——音频识别方面
1.参考文献
《Masked Autoencoders that Listen》
2.背景
Transformers和self-supervised learning(自监督学习)占据了计算机视觉(Computer Vision,CV)和自然语言处理(natural language processing, NLP)的主导地位。
使用BERT进行屏蔽自动编码,通过对大规模语言语料库的自监督预训练,为各种NLP任务提供了一种新的最新技术。类似地,在CV社区中,Vision Transformers (ViT)变得越来越流行,在自监督的图像表示学习中,掩码自动编码器(MAE)使CV社区更接近BERT在NLP中的成功。
在这项工作中,主要研究了听的方面,即音频识别方面,如Audioset(规模最大的音频数据集),环境声识别(ESC-50),语音指令识别(SPC-2, SPC-1),说话人识别(VoxCeleb)。
3.掩码自动编码器
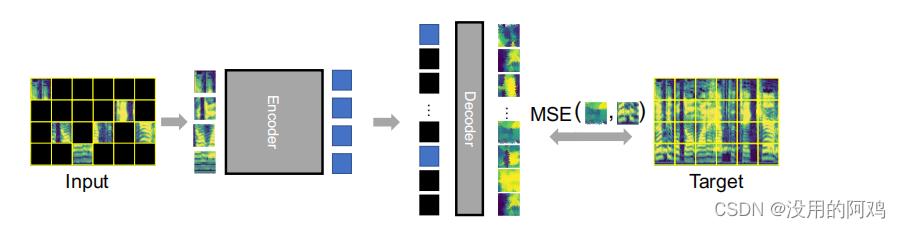
MAE如上图所示。
①将音频的时频谱图分割成许多patch,对大部分patch进行掩码处理;
②通过把剩余可见的patch块进行编码操作;
③然后通过解码操作,对顺序恢复和掩码patch块进行重构输出;
④并与目标时频谱图计算MSE损失以此更新编码器和解码器;
这里编码器使用12-layer ViT-Base (ViT-B)
解码器用standard Transformer模块。
具体细节可以看原文。
4.微调至下游任务
MAE最终只保留编码器部分,解码器将删除,这样就能应用到下游任务。
5.结果
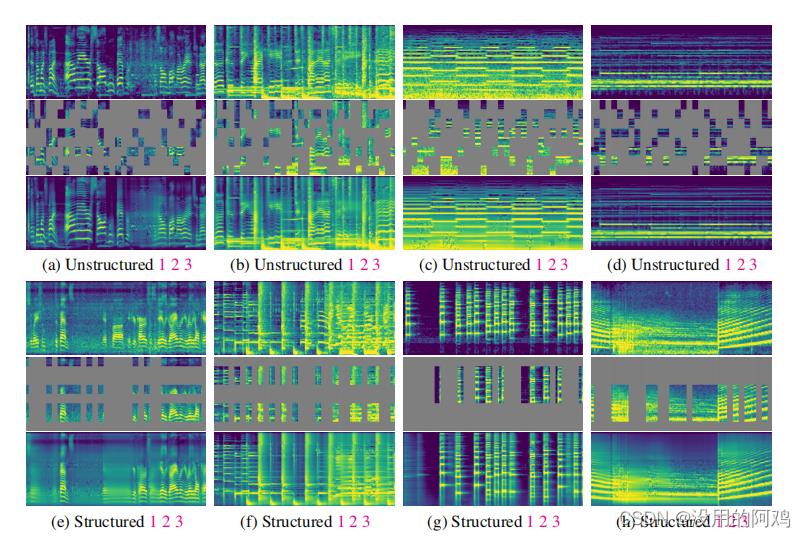
谱图修复结果如上图所示
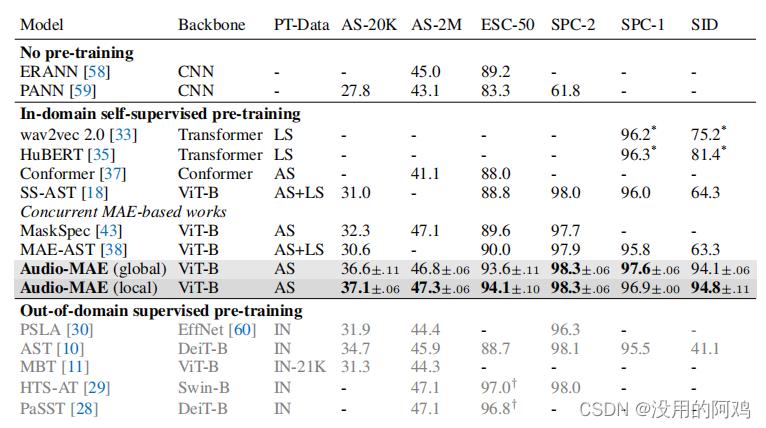
MAE下游任务结果如上表所示
6.应用拓展
MAE预训练模型可以用于各种下游任务,对于提升识别率都很有效。
Numpy掩码数组masked arrays,这一篇就够了
Numpy掩码数组masked arrays,这一篇就够了
- MaskedArray是numpy.ndarray的一个子类,因此它继承了索引和切片机制。
1. 什么是掩码数组
掩码数组是包括可能缺少或无效项的数组。numpy.ma模块为numpy提供了一个几乎可以替代numpy的替代品,它支持带掩码的数据数组。
数组计算时,数据集可能是不完整的或者由于存在无效数据而使得计算结果是被污染的。 例如,传感器可能无法记录数据,或记录了无效值。ma模块通过引入屏蔽数组,提供了一种解决此问题的方便方法。
掩码数组是标准numpy.ndarray和掩码的组合。掩码可以是nomask,表示关联数组的值无效,也可以是boolean数组,用于确定关联数组的每个元素的值是否有效。 当掩码的某个元素为False时,关联数组的相应元素有效,并被称为未掩码。当掩码的一个元素为真时,关联数组的相应元素被称为掩码(无效)。
该包确保在计算中不使用屏蔽项。
2.示例
概念有点抽象,看一个例子感受一下:
2.1 一个例子走进掩码数组
掩码数组可以帮助进行numpy的相应运算而忽略无效值
# 掩码数组可以帮助进行numpy的相应运算而忽略无效值
import numpy as np
import numpy.ma as ma
x = np.array([1, 2, 3, -1, 5])
# 假设上述数组x中第4个值是无效的,那么可以建立一个掩码数组如下mx
mx = ma.masked_array(x, mask=[0, 0, 0, 1, 0])
# 接下来就可以忽略无效数据,而计算数据集x的平均值了
print(mx.mean())
# 得到结果2.75
ma模块的主要特性是MaskedArray类,它是numpy.ndarray的一个子类。
numpy.ma模块可用作numpy的附加模块;
2.2 创建一个数组第二个值是无效的
import numpy.ma as ma
# 创建一个数组第二个值是无效的
y = ma.array([1, 2, 3], mask = [0, 1, 0])
2.3 创建一个数组所有靠近1.e20的值是无效的
import numpy.ma as ma
# 创建一个数组所有靠近1.e20的值是无效的
z = ma.masked_values([1.0, 1.e20, 3.0, 4.0], 1.e20)
2.4 只获取有效项
import numpy.ma as ma
# 只获取有效项法一
x = ma.array([[1, 2], [3, 4]], mask=[[0, 1], [1, 0]])
print(x[~x.mask])
# masked_array(data=[1, 4],
# mask=[False, False],
# fill_value=999999)
# 只获取有效项法2
print(x.compressed())
# array([1, 4])
2.5 取消标识无效(注意标识硬编码的需要先软化在标识)
import numpy.ma as ma
# 取消标识项无效
x = ma.array([1, 2, 3], mask=[0, 0, 1])
print(x)
# masked_array(data=[1, 2, --],
# mask=[False, False, True],
# fill_value=999999)
x[-1] = 5
print(x)
# masked_array(data=[1, 2, 5],
# mask=[False, False, False],
# fill_value=999999)
x = ma.array([1, 2, 3], mask=[0, 0, 1], hard_mask=True)
print(x)
# masked_array(data=[1, 2, --],
# mask=[False, False, True],
# fill_value=999999)
x[-1] = 5
print(x)
# masked_array(data=[1, 2, --],
# mask=[False, False, True],
# fill_value=999999)
print(x.soften_mask())
# masked_array(data=[1, 2, --],
# mask=[False, False, True],
# fill_value=999999)
x[-1] = 5
print(x)
# masked_array(data=[1, 2, 5],
# mask=[False, False, False],
# fill_value=999999)
print(x.harden_mask())
# masked_array(data=[1, 2, 5],
# mask=[False, False, False],
# fill_value=999999)
# 硬编码的需要先软化才可以标识取消无效
x = ma.array([1, 2, 3], mask=[0, 0, 1])
print(x)
# masked_array(data=[1, 2, --],
# mask=[False, False, True],
# fill_value=999999)
x.mask = ma.nomask
print(x)
# masked_array(data=[1, 2, 3],
# mask=[False, False, False],
# fill_value=999999)
2.6 修改Masked Array标记项为无效项
import numpy.ma as ma
# 修改Masked Array标记项为无效项
x = ma.array([1, 2, 3])
x[0] = ma.masked
print(x)
# masked_array(data=[--, 2, 3],
# mask=[ True, False, False],
# fill_value=999999)
y = ma.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
y[(0, 1, 2), (1, 2, 0)] = ma.masked
print(y)
# masked_array(
# data=[[1, --, 3],
# [4, 5, --],
# [--, 8, 9]],
# mask=[[False, True, False],
# [False, False, True],
# [ True, False, False]],
# fill_value=999999)
z = ma.array([1, 2, 3, 4])
z[:-2] = ma.masked
print(z)
# masked_array(data=[--, --, 3, 4],
# mask=[ True, True, False, False],
# fill_value=999999)
参考
以上是关于自监督学习之掩码自动编码器(Masked Autoencoders, MAE)——音频识别方面的主要内容,如果未能解决你的问题,请参考以下文章
ConvMAE:Masked Convolution 遇到 Masked Autoencoders
PyTorch笔记 - MAE(Masked Autoencoders) PyTorch源码
PyTorch笔记 - MAE(Masked Autoencoders) PyTorch源码