钉钉杯大学生大数据挑战赛初赛 A:银行卡电信诈骗危险预测 Baseline
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了钉钉杯大学生大数据挑战赛初赛 A:银行卡电信诈骗危险预测 Baseline相关的知识,希望对你有一定的参考价值。
【钉钉杯大学生大数据挑战赛】初赛 A:银行卡电信诈骗危险预测 Baseline

目录
- 【钉钉杯大学生大数据挑战赛】初赛 A:银行卡电信诈骗危险预测 Baseline
- 1 题目
- 2 Python实现
- 3 完整代码
1 题目
一、问题背景:
数字支付正在发展,但网络犯罪也在发展。电信诈骗案件持续高发,消费者 受损比例持续走高。报告显示,64%的被调查者曾使用手机号码同时注册多个账户,包括金融类账户、社交类账户和消费类账户等,其中遭遇过电信诈骗并发生 损失的比例过半。用手机同时注册金融类账户及其他账户,如发生信息泄露,犯 罪分子更易接管金融支付账户盗取资金。
随着移动支付产品创新加快,各类移动支付在消费群体中呈现分化趋势,第三方支付的手机应用丰富的场景受到年轻人群偏爱,支付方式变多也导致个人信 息也极易被不法分子盗取。根据数据泄露指数,每天有超过 500 万条记录被盗, 这一令人担忧的统计数据表明 - 对于有卡支付和无卡支付类型的支付,欺诈仍 然非常普遍。
在今天的数字世界,每天有数万亿的银行卡交易发生,检测欺诈行为的发生 是一个严峻挑战。
二、数据描述:
该数据来自一些匿名的数据采集机构,数据共有七个特征和一列类标签。下 面对数据特征进行一些简单的解释(每列的含义对我们来说并不重要,但对于机 器学习来说,它可以很容易地发现含义。它有点抽象,但并不需要真正了解每个 功能的真正含义。只需了解如何使用它以便您的模型可以学习。许多数据集,尤 其是金融领域的数据集,通常会隐藏一条数据所代表的内容,因为它是敏感信息。 数据所有者不想让他人知道,并且数据开发人员从法律上讲也无权知道)
-
**distance_from_home:**银行卡交易地点与家的距离;
-
**distance_from_last_transaction:**与上次交易发生的距离;
-
**ratio_to_median_purchase_price:**近一次交易与以往交易价格中位数的比率;
-
**repeat_retailer:**交易是否发生在同一个商户;
-
**used_chip:**是通过芯片(银行卡)进行的交易;
-
**used_pin_number:**交易时是否使用了 PIN码;
-
**online_order:**是否是在线交易订单;
-
**fraud:**诈骗行为(分类标签);
三、解决问题:
(1)使用多种用于数据挖掘的机器学习模型对给定数据集进行建模;
(2)对样本数据进一步挖掘分析,通过交叉验证、网格调优对不同模型的参 数进行调整,寻找最优解,将多个最优模型进行进一步比较;
(3)通过对 precision(预测精度)、recall(召回率)、f1-score(F1 分 数值)进行计算,给出选择某一种预测模型的理由;
(4)将模型性能评价通过多种作图方式进行可视化
2 Python实现
2.1 数据分析与探索
(1)读取数据
import datetime
import numpy as np
import pandas as pd
import numpy as np
from tqdm import tqdm
tqdm.pandas()
import csv
import os
import pickle
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
train = pd.read_csv('card_transdata.csv')
train
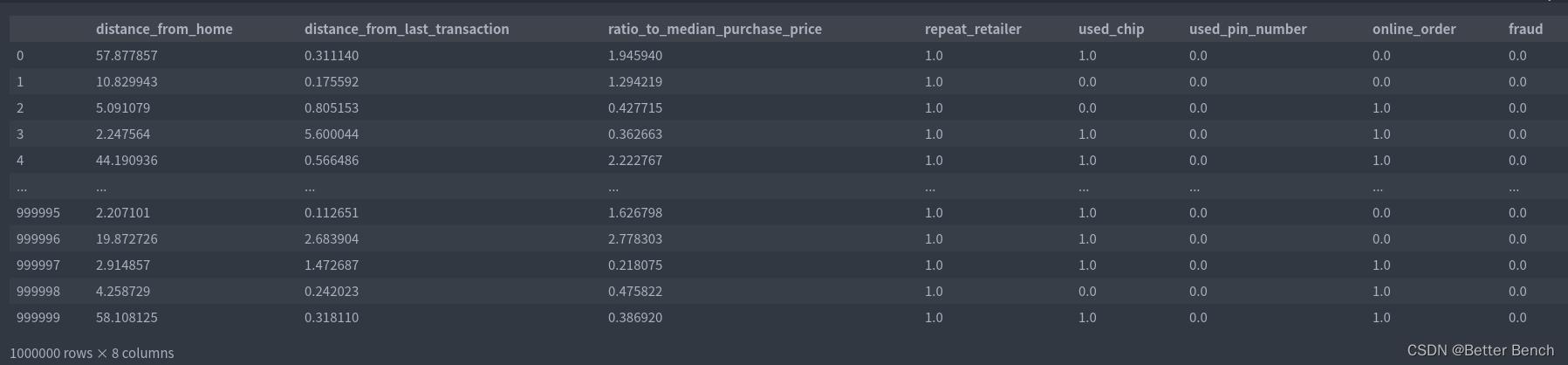
可以看到有100万条数据,
train.columns
Index([‘distance_from_home’, ‘distance_from_last_transaction’, ‘ratio_to_median_purchase_price’, ‘repeat_retailer’, ‘used_chip’, ‘used_pin_number’, ‘online_order’, ‘fraud’], dtype=‘object’)
以下分析以前1000个数据为例
label = train[:1000]['fraud']
x_train = train[:1000][['distance_from_home', 'distance_from_last_transaction',
'ratio_to_median_purchase_price', 'repeat_retailer', 'used_chip',
'used_pin_number', 'online_order']]
(2)缺失值查看
for i in range(len(x_train.columns)):
print(train.T.isna().iloc[i].value_counts())
False 1000000 Name: distance_from_home, dtype: int64
False 1000000 Name: distance_from_last_transaction, dtype: int64
False 1000000 Name: ratio_to_median_purchase_price, dtype: int64
False 1000000 Name: repeat_retailer, dtype: int64
False 1000000 Name: used_chip, dtype: int64
False 1000000 Name: used_pin_number, dtype: int64
False 1000000 Name: online_order, dtype: int64
没有缺失值
也可以可视化查看
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(16,5))
sns.heatmap(train.T.isna(), cmap='mako_r')
ax.set_title('Missing Values', fontsize=15)
for tick in ax.yaxis.get_major_ticks():
tick.label.set_fontsize(12)
plt.show()
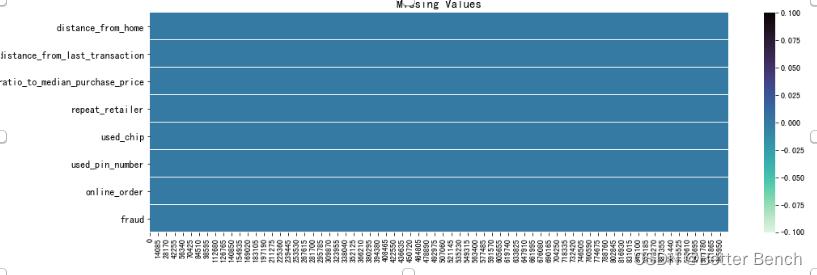
(3)异常值查看
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
x_train = train[:1000][['distance_from_home', 'distance_from_last_transaction','ratio_to_median_purchase_price', 'repeat_retailer', 'used_chip','used_pin_number', 'online_order']]
scaler = MinMaxScaler()
scaler = scaler.fit(x_train) # 本质生成 max(x) 和 min(x)
data = scaler.transform(x_train)
plt.grid(True) # 显示网格
# 绘制箱线图 #, labels=list("ABCDEFG"))#,
plt.boxplot(data, labels=list("ABCDEFG"), sym="r+", showmeans=True)
plt.show() # 显示图片
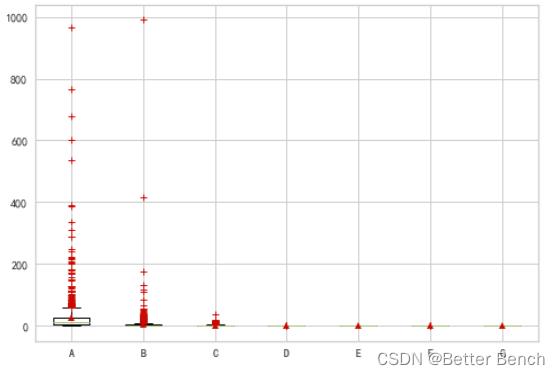
distance_from_home、distance_from_last_transaction、ratio_to_median_purchase_price中异常值较多,‘repeat_retailer’, ‘used_chip’,‘used_pin_number’, 'online_order’是二分类的类别特征
2.2 K折模型训练和网格调参
2.2.1 支持向量机回归SVR
from sklearn.svm import SVR # 引入SVR类
from sklearn.pipeline import make_pipeline # 引入管道简化学习流程
from sklearn.preprocessing import StandardScaler # 由于SVR基于距离计算,引入对数据进行标准化的类
from sklearn.model_selection import GridSearchCV # 引入网格搜索调优
from sklearn.model_selection import cross_val_score # 引入K折交叉验证
X = x_train
y = label
pipe_SVR = make_pipeline(StandardScaler(),SVR())
score1 = cross_val_score(estimator=pipe_SVR,
X = X,
y = y,
scoring = 'r2',
cv = 10) # 10折交叉验证
print("10折 CV 准确率: %.3f" % ((np.mean(score1))))
10折 CV 准确率: 0.679
# 下面我们使用网格搜索来对SVR调参:
from sklearn.pipeline import Pipeline
pipe_svr = Pipeline([("StandardScaler",StandardScaler()),
("svr",SVR())])
param_range = [0.0001,0.001,0.01,0.1,1.0,10.0,100.0,1000.0]
param_grid = ["svr__C":param_range,"svr__kernel":["linear"], # 注意__是指两个下划线,一个下划线会报错的
"svr__C":param_range,"svr__gamma":param_range,"svr__kernel":["rbf"]]
gs = GridSearchCV(estimator=pipe_svr,
param_grid = param_grid,
scoring = 'r2',
cv = 10) # 10折交叉验证
gs = gs.fit(X,y)
print("网格搜索最优得分:",gs.best_score_)
print("网格搜索最优参数组合:\\n",gs.best_params_)
网格搜索最优得分: 0.6910531241525832
网格搜索最优参数组合: ‘svr__C’: 10.0, ‘svr__gamma’: 0.1, ‘svr__kernel’: ‘rbf’
2.2.2 支持向量机SVM
from sklearn.model_selection import GridSearchCV
def blind_gridsearch(model, X, y):
C_range = np.logspace(-2, 10, 5)
gamma_range = np.logspace(-5, 5, 5)
param_grid = dict(gamma=gamma_range, C=C_range)
grid = GridSearchCV(SVC(), param_grid=param_grid)
grid.fit(X, y)
print(
'The best parameters are with a score of :0.2f.'.format(
grid.best_params_, grid.best_score_
)
)
。。。略
blind_gridsearch(SVC(), features, labels)
The best parameters are ‘C’: 10000000000.0, ‘gamma’: 1e-05 with a score of 0.97.
2.2.3 XGBoost
# 导包
import re
import os
from sqlalchemy import create_engine
import warnings
warnings.filterwarnings('ignore')
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
import matplotlib.pyplot as plt
import gc
from sklearn import metrics
from sklearn.model_selection import cross_val_predict,cross_validate
# 设定xgb参数
params=
'objective':'binary:logistic'
,'eval_metric':'auc'
,'n_estimators':500
,'eta':0.03
,'max_depth':3
,'min_child_weight':100
,'scale_pos_weight':1
,'gamma':5
,'reg_alpha':10
,'reg_lambda':10
,'subsample':0.7
,'colsample_bytree':0.7
,'seed':123
。。。略
scores
‘fit_time’: array([0.19092107, 0.11930871, 0.10201693, 0.2144227 , 0.10833335]),
‘score_time’: array([0.00347257, 0.01546097, 0.003299 , 0.00402188, 0.01078582]),
‘test_roc_auc’: array([0.5, 0.5, 0.5, 0.5, 0.5]),
‘train_roc_auc’: array([0.5, 0.5, 0.5, 0.5, 0.5])
# 调参
from sklearn.model_selection import GridSearchCV
train=train[:1000].head(900)
test=train[:1000].tail(100)
param_value_dics=
'n_estimators':range(100,900,500),
'eta':np.arange(0.02,0.2,0.1),
'max_depth':range(3,5,1),
# 'num_leaves':range(10,30,10),
# 'min_child_weight':range(300,1500,500),
xgb_model=XGBClassifier(**params)
clf=GridSearchCV(xgb_model,param_value_dics,scoring='roc_auc',n_jobs=-1,cv=5,return_train_score=True)
clf.fit(x_train, y)
GridSearchCV(cv=5,
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=0.7,
enable_categorical=False, eta=0.03,
eval_metric=‘auc’, gamma=5, gpu_id=None,
importance_type=None,
interaction_constraints=None,
learning_rate=None, max_delta_step=None,
max_depth=3, min_child_weight=100,
missing=nan, monoton…e,
n_estimators=500, n_jobs=None,
num_parallel_tree=None, predictor=None,
random_state=None, reg_alpha=10,
reg_lambda=10, scale_pos_weight=1,
seed=123, subsample=0.7, tree_method=None,
validate_parameters=None, …),
n_jobs=-1,
param_grid=‘eta’: array([0.02, 0.12]), ‘max_depth’: range(3, 5),
‘n_estimators’: range(100, 900, 500),
return_train_score=True, scoring=‘roc_auc’)
clf.best_estimator_
XGBClassifier(base_score=0.5, booster=‘gbtree’, colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=0.7,
enable_categorical=False, eta=0.02, eval_metric=‘auc’, gamma=5,
gpu_id=-1, importance_type=None, interaction_constraints=‘’,
learning_rate=0.0199999996, max_delta_step=0, max_depth=3,
min_child_weight=100, missing=nan, monotone_constraints=‘()’,
n_estimators=100, n_jobs=6, num_parallel_tree=1, predictor=‘auto’,
random_state=123, reg_alpha=10, reg_lambda=10, scale_pos_weight=1,
seed=123, subsample=0.7, tree_method=‘exact’,
validate_parameters=1, …)
2.3 特征工程
2.3.1 特征分析
平行坐标是多维特征直轴被水平复制用于每个特征。实例显示为从每个垂直轴到代表该特征值的位置绘制的一条线段。这允许同时可视化许多维度;事实上,给定无限的水平空间(例如滚动窗口),技术上可以显示无限数量的维度!
# 安装包:pip install yellowbrick - i https: // pypi.tuna.tsinghua.edu.cn/simple
from yellowbrick.features import ParallelCoordinates
# Load the classification data set
X = x_train
y = label
# Specify the features of interest and the classes of the target
features = ['distance_from_home', 'distance_from_last_transaction',
'ratio_to_median_purchase_price', 'repeat_retailer', 'used_chip',
'used_pin_number', 'online_order'
]
classes = ["unoccupied", "occupied"]
# Instantiate the visualizer
。。。略
# Fit and transform the data to the visualizer
visualizer.fit_transform(X, y)
# Finalize the title and axes then display the visualization
visualizer.show()
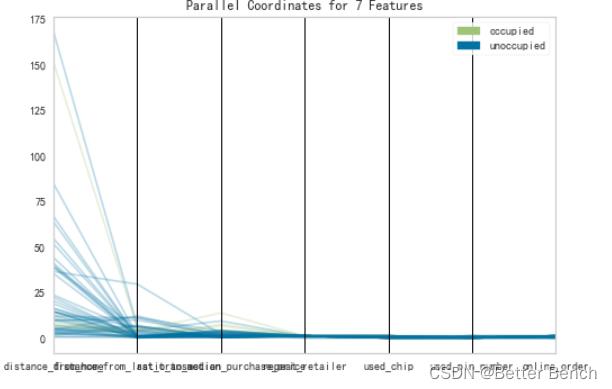
RadViz是一种多元数据可视化算法,它围绕一个圆的圆周均匀地绘制每个特征尺寸,然后在圆的内部绘制点,以便该点将其在从中心到每个弧的轴上的值标准化。这种机制允许尽可能多的维度适合一个圆,极大地扩展了可视化的维度。
# 安装包:pip install yellowbrick - i https: // pypi.tuna.tsinghua.edu.cn/simple
from yellowbrick.features import RadViz
# Load the classification dataset
X = x_train
y = label
# Specify the target classes
classes = ["unoccupied", "occupied"]
# Instantiate the visualizer
。。。略
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.transform(X) # Transform the data
visualizer.show()
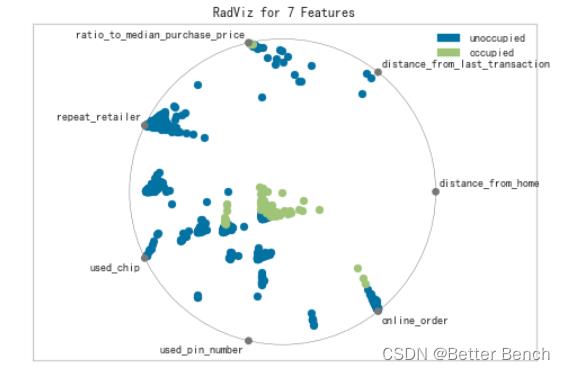
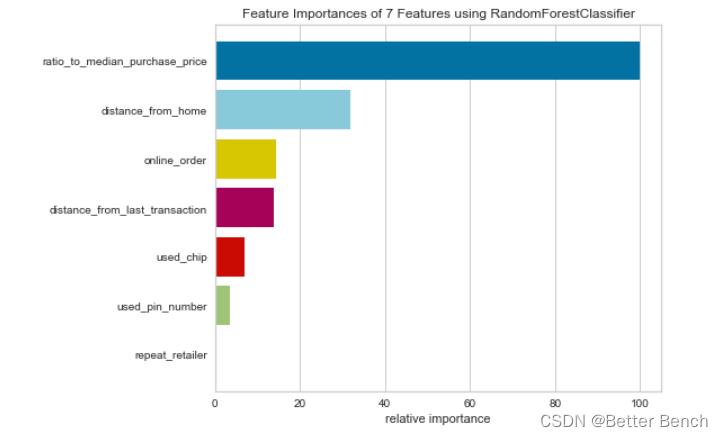
2…3.1 特征重要性可视化
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.model_selection import FeatureImportances
# Load the classification data set
X = x_train
y = label
。。。略
viz = FeatureImportances(model)
viz.fit(X, y)
viz.show()
2.3.3 特征选取
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from yellowbrick.model_selection import RFECV
# Create a dataset with only 3 informative features
。。。略
# Load the classification dataset
X = x_train
y = label
# Instantiate RFECV visualizer with a linear SVM classifier
visualizer = RFECV(SVC(kernel='linear', C=1))
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.show()

2.4 模型评价
2.4.1 LogisticRegression模型评价ROC曲线
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from yellowbrick.classifier import ROCAUC
# Load the classification dataset
X=x_train[['distance_from_home', 'distance_from_last_transaction',
'ratio_to_median_purchase_price', 'repeat_retailer', 'used_chip',
'used_pin_number', 'online_order']]
y = label
# Create the training and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# Instantiate the visualizer with the classification model
model = LogisticRegression(multi_class="auto", solver="liblinear")
visualizer = ROCAUC(model, classes=["not_fraud", "is_fraud"])
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.show()
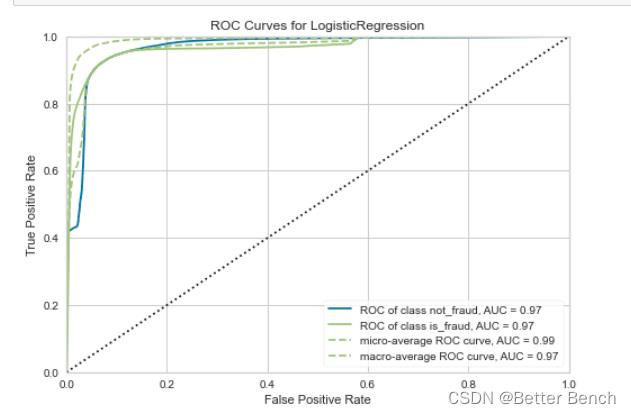
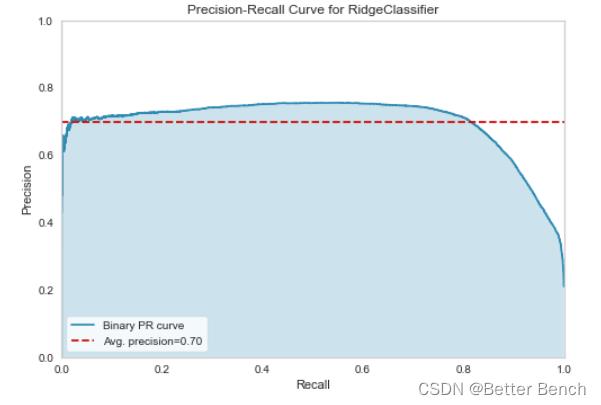
2.4.2 Precision-Recall Curves 召回率
import matplotlib.pyplot as plt
from sklearn.linear_model import RidgeClassifier
from yellowbrick.classifier import PrecisionRecallCurve
from sklearn.model_selection import train_test_split as tts
# Load the dataset and split into train/test splits
X = x_train
y = label
X_train, X_test, y_train, y_test = tts(
X, y, test_size=0.2, shuffle=True, random_state=0
)
# Create the visualizer, fit, score, and show it
viz = PrecisionRecallCurve(RidgeClassifier(random_state=0))
viz.fit(X_train, y_train)
viz.score(X_test, y_test)
viz.show()
# Specify class weights to shift the threshold towards spam classification
weights = 0:0.2, 1:0.8
# Create the visualizer, fit, score, and show it
viz = PrecisionRecallCurve(
LogisticRegression(class_weight=weights, random_state=0)
)
viz.fit(X_train, y_train)
viz.score(X_test, y_test)
viz.show()
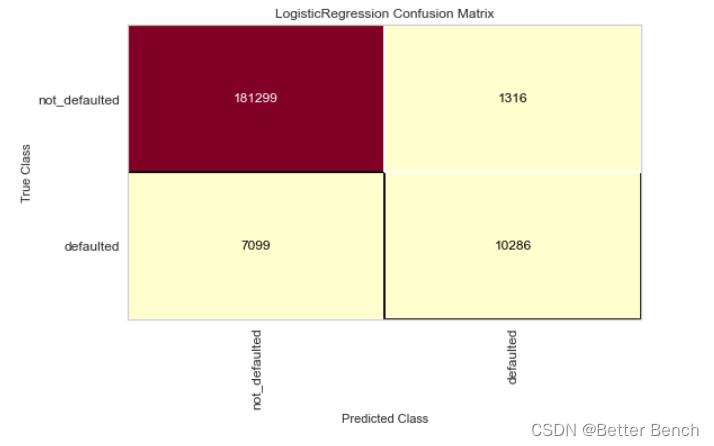
2.4.3 混淆矩阵
from yellowbrick.classifier import confusion_matrix
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split as tts
# Instantiate the visualizer with the classification model
confusion_matrix(
LogisticRegression(),
X_train, y_train, X_test, y_test,
classes=['not_defaulted', 'defaulted']
)
plt.tight_layout()
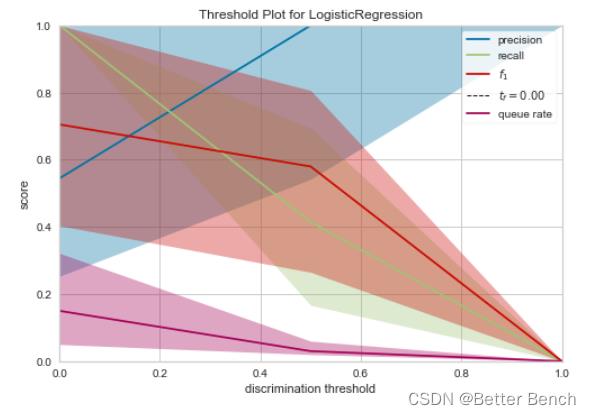
2.4.4 Discrimination Threshold 甄别阈
from sklearn.linear_model import LogisticRegression
from yellowbrick.classifier import DiscriminationThreshold
X = x_train
y = label
# Instantiate the classification model and visualizer
。。。略
visualizer.fit(X, y) # Fit the data to the visualizer
visualizer.show()
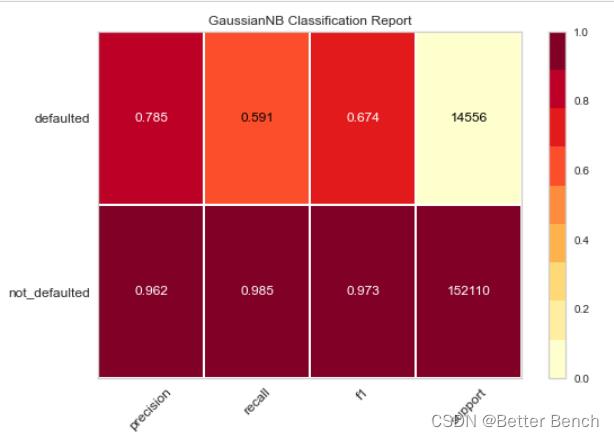
2.4.5 F1值+Presion+recall
from sklearn.model_selection import TimeSeriesSplit
from sklearn.naive_bayes import GaussianNB
from yellowbrick.classifier import ClassificationReport
X = x_train
y = label
# Specify the target classes
classes = ['not_defaulted', 'defaulted']
# Create the training and test data
tscv = TimeSeriesSplit()
for train_index, test_index in tscv.split(X):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
# Instantiate the classification model and visualizer
。。。略
visualizer.fit(X_train, y_train) # Fit the visualizer and the model
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.show()
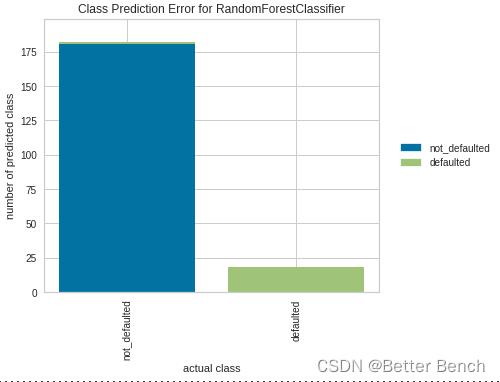
2.4.6 类预测误差
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import ClassPredictionError
from yellowbrick.datasets import load_credit
X = x_train
y = label
# Specify the target classes
classes = ['not_defaulted', 'defaulted']
# Perform 80/20 training/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20,
random_state=42)
# Instantiate the classification model and visualizer
。。。略
# Fit the training data to the visualizer
visualizer.fit(X_train, y_train)
# Evaluate the model on the test data
visualizer.score(X_test, y_test)
# Draw visualization
visualizer.show()
2.5 最终模型可视化
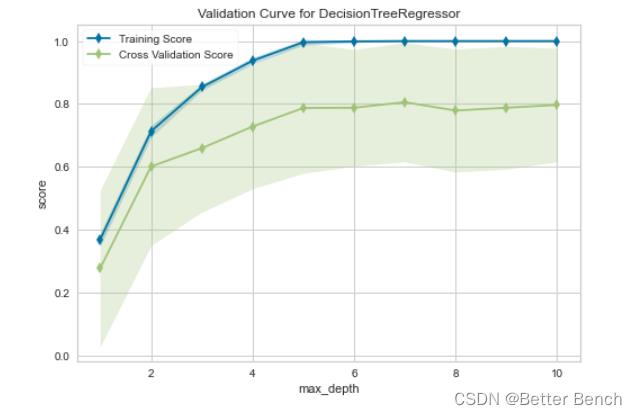
2.5.1 验证曲线
from yellowbrick.model_selection import ValidationCurve
from sklearn.tree import DecisionTreeRegressor
# Load a regression dataset
X = x_train
y = label
。。。略
# Fit and show the visualizer
viz.fit(X, y)
viz.show()
2.5.2 学习曲线
钉钉杯大学生大数据挑战赛初赛B 航班数据分析与预测 Python代码实现Baseline