swinUnet官方代码测试自己的数据集(已训练完毕)
Posted 小小小MaYi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了swinUnet官方代码测试自己的数据集(已训练完毕)相关的知识,希望对你有一定的参考价值。
***************************************************
码字不易,收藏之余,别忘了给我点个赞吧!
***************************************************
---------Start
首先参考上一篇的训练过程,因为测试需要用到训练获得的权重。
1、检查相关文件
1.1 检查test_vol.txt的内容是否是测试用的npz文件名称
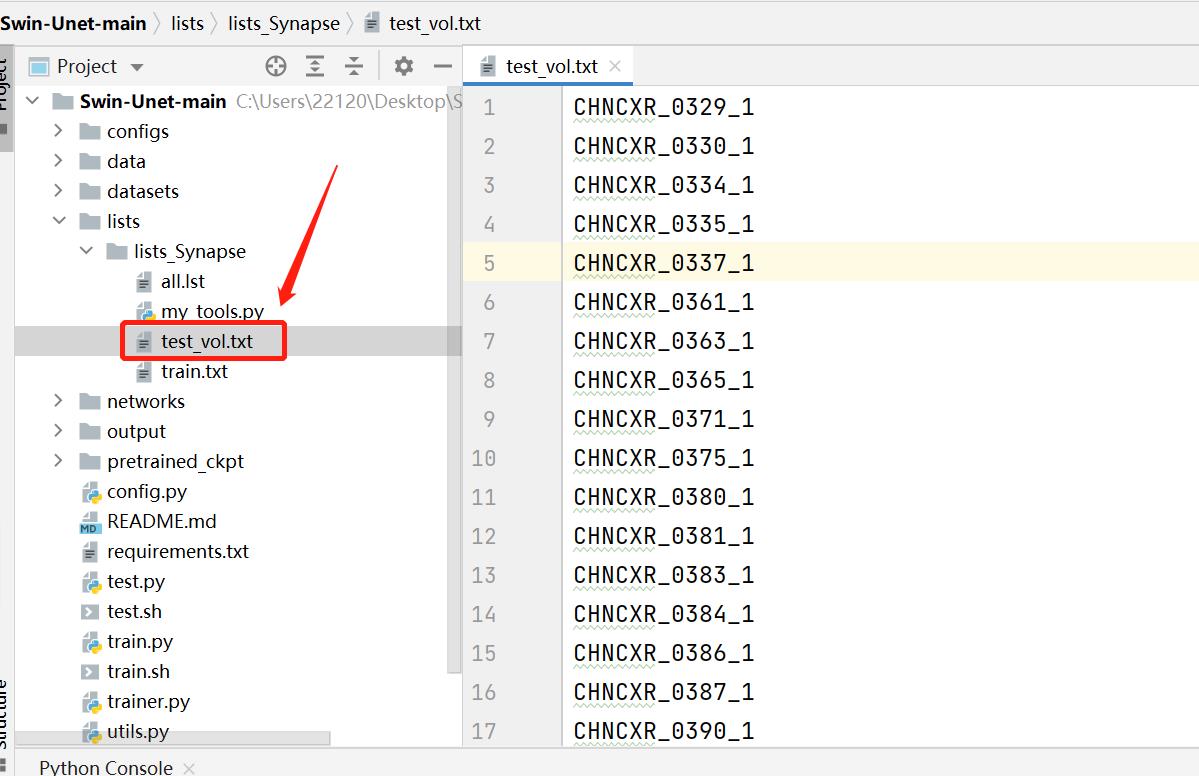
测试集的npz文件
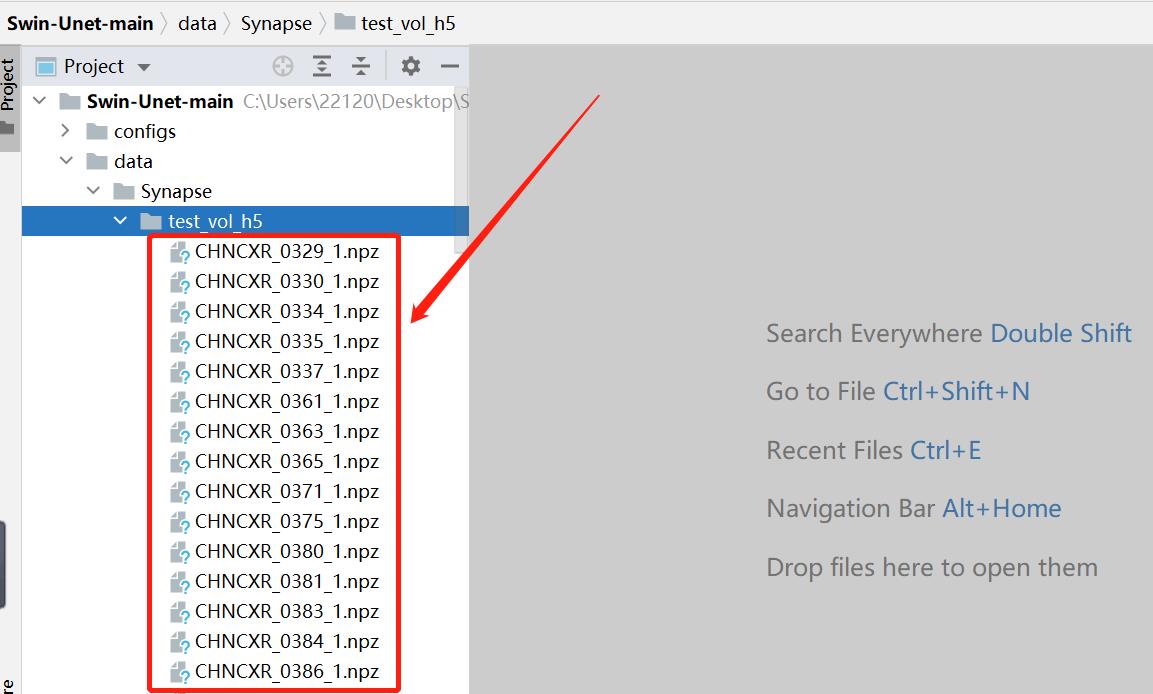
1.2 检查模型权重文件
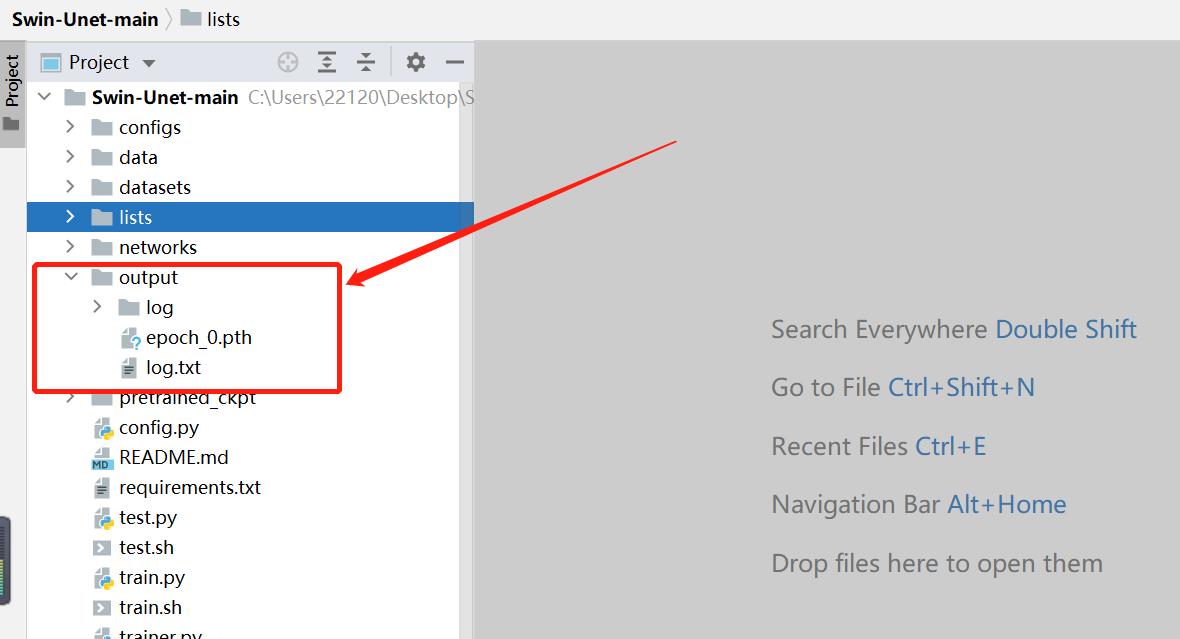
2、修改部分代码
2.1 修改dataset_synapse.py
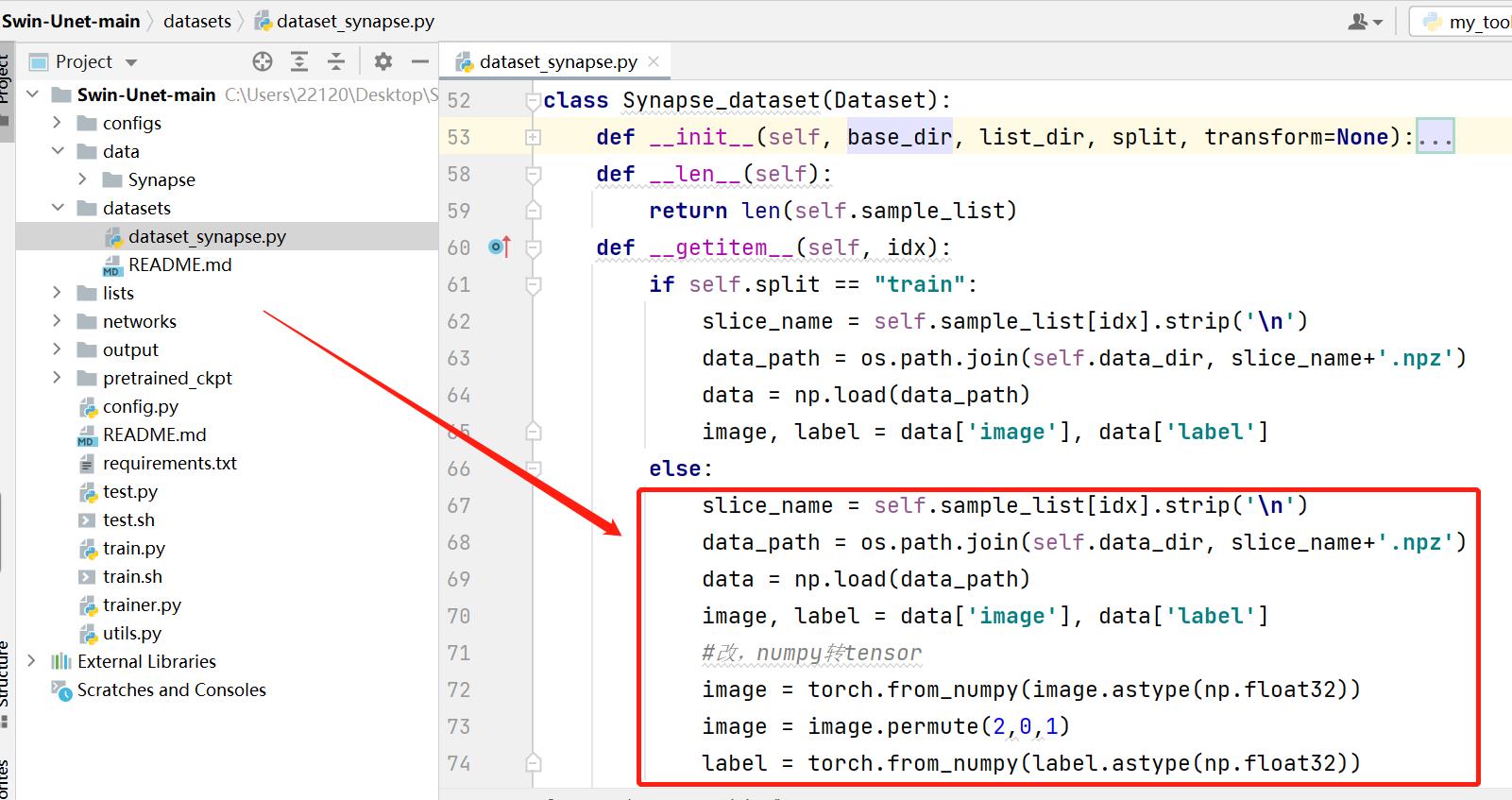
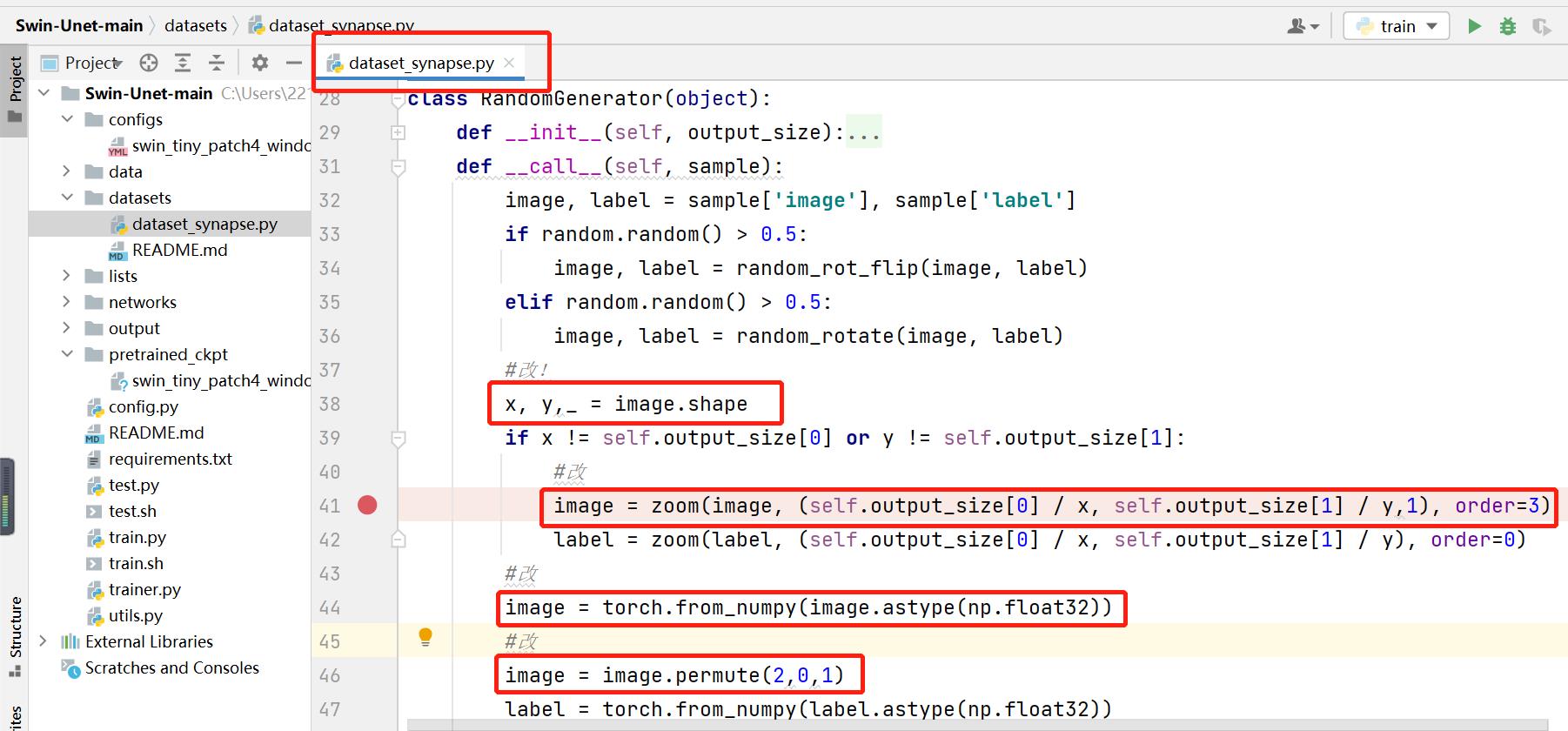
slice_name = self.sample_list[idx].strip('\\n')
data_path = os.path.join(self.data_dir, slice_name+'.npz')
data = np.load(data_path)
image, label = data['image'], data['label']
#改,numpy转tensor
image = torch.from_numpy(image.astype(np.float32))
image = image.permute(2,0,1)
label = torch.from_numpy(label.astype(np.float32))
2.2 修改test.py代码
修改相关参数和文件路径
is_savenii:是否保存预测结果图片
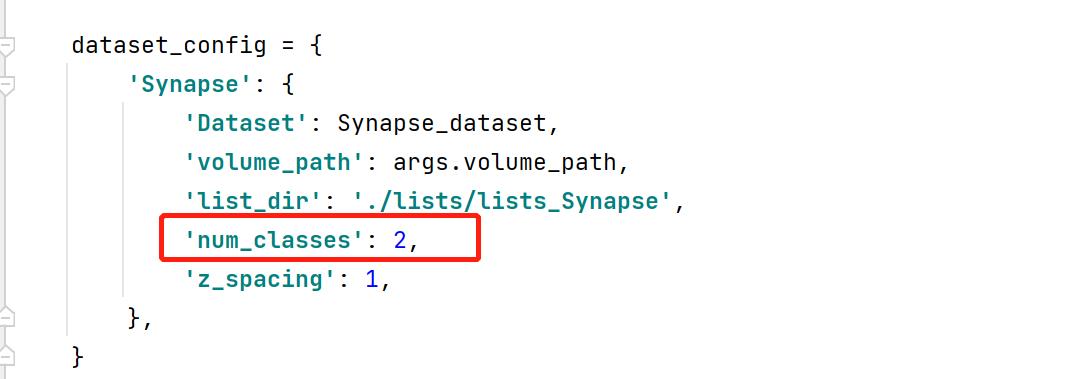
num_classes:预测的目标类别数+1
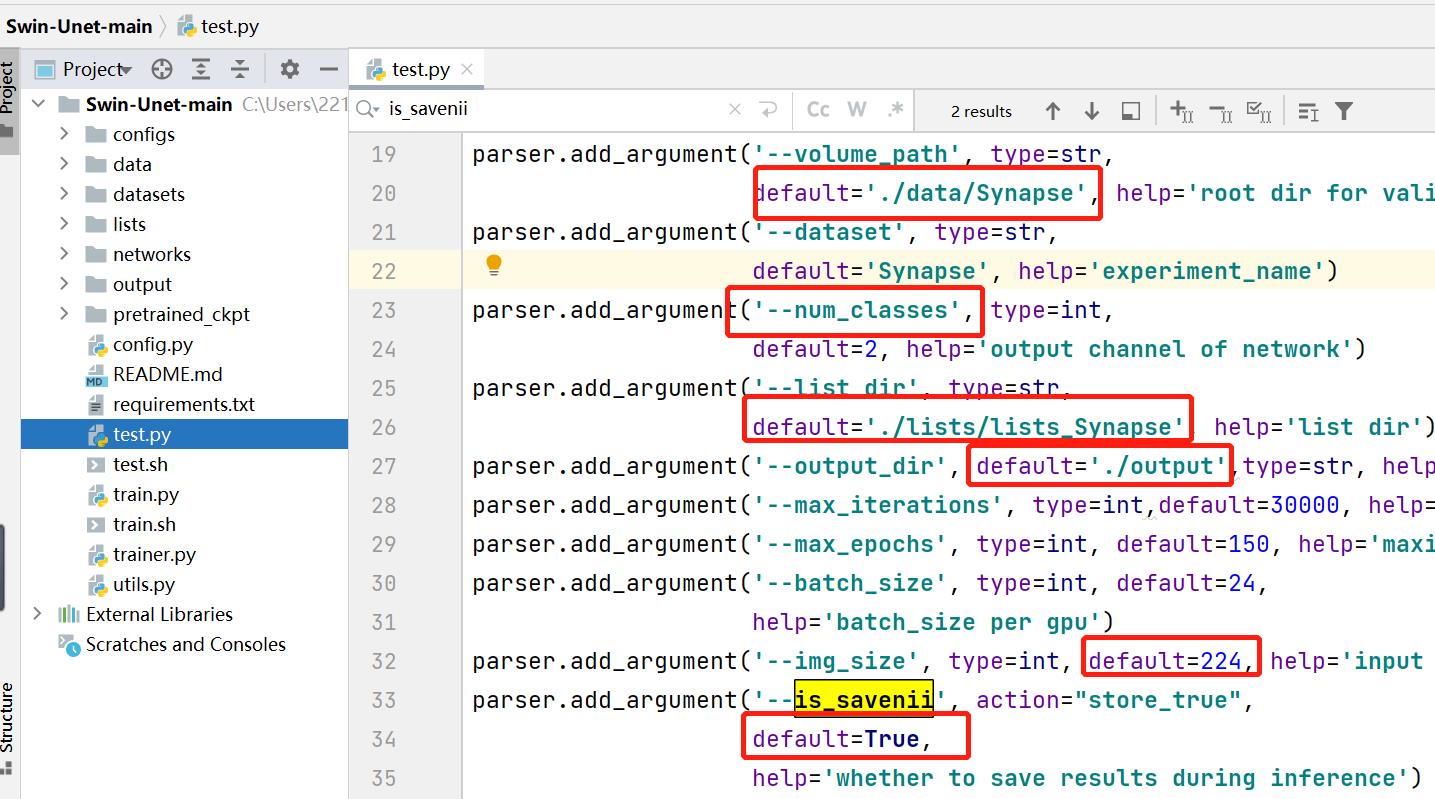
cfg:swinUnet网络结构配置文件
test_save_dir:保存预测结果文件夹
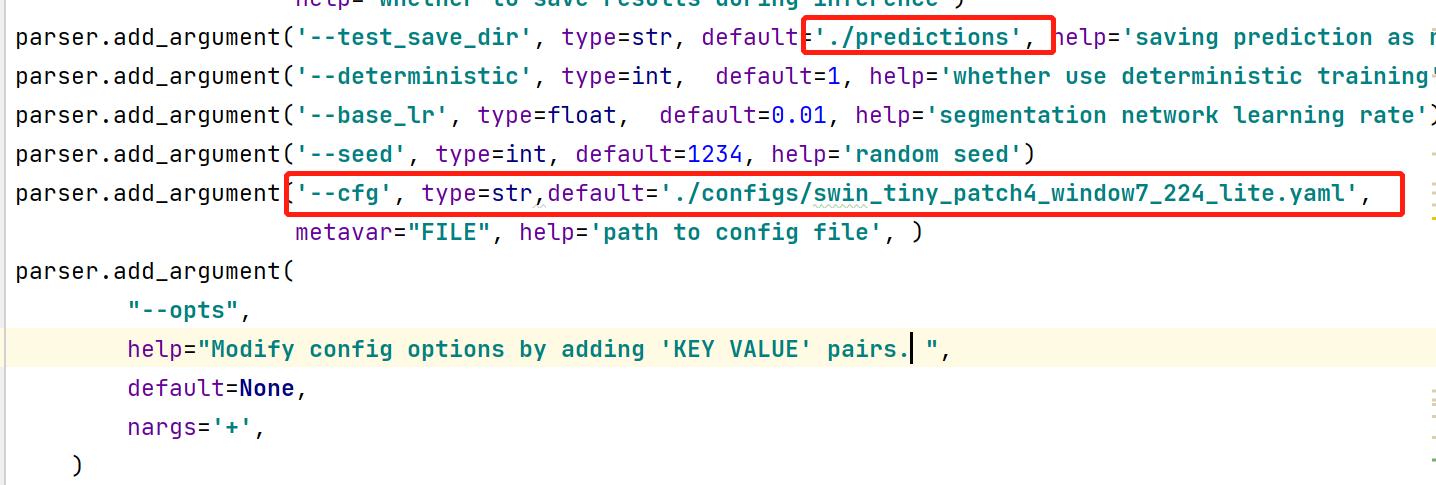
num_classes:预测的目标类别数+1
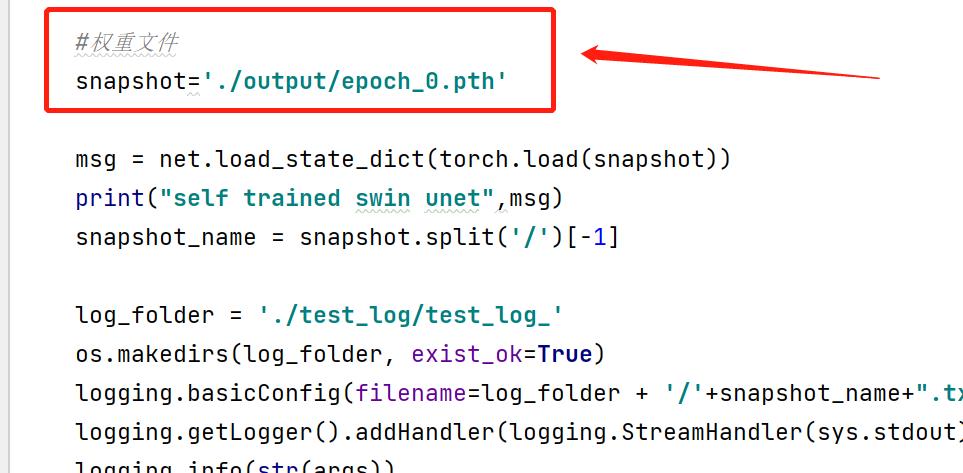
自定义权重路径
2.3 修改util.py代码(分两种情况)
第一种情况:保存预测原图,保存的结果是一张灰度图,每个像素的值代表该像素属于哪个类别。例如(0:背景,1:目标1,2:目标2…),这是一张全黑图。
def test_single_volume(image, label, net, classes, patch_size=[256, 256], test_save_path=None, case=None, z_spacing=1):
image, label = image.squeeze(0).cpu().detach().numpy(), label.squeeze(0).cpu().detach().numpy()
_, x, y = image.shape
# 缩放图像符合网络输入大小224x224
if x != patch_size[0] or y != patch_size[1]:
image = zoom(image, (1, patch_size[0] / x, patch_size[1] / y), order=3)
input = torch.from_numpy(image).unsqueeze(0).float().cuda()
net.eval()
with torch.no_grad():
out = torch.argmax(torch.softmax(net(input), dim=1), dim=1).squeeze(0)
out = out.cpu().detach().numpy()
# 缩放预测结果图像同原始图像大小
if x != patch_size[0] or y != patch_size[1]:
prediction = zoom(out, (x / patch_size[0], y / patch_size[1]), order=0)
else:
prediction = out
metric_list = []
for i in range(1, classes):
metric_list.append(calculate_metric_percase(prediction == i, label == i))
if test_save_path is not None:
#保存预测结果
prediction = Image.fromarray(np.uint8(prediction)).convert('L')
prediction.save(test_save_path + '/' + case + '.png')
return metric_list
第二种情况:保存可见图像,将不同类别映射成不同的颜色。只需要将上面代码的if test_save_path is not None:里面的内容替换成下面的代码即可。
#将不同类别区域呈彩色展示
#2分类 背景为黑色,类别1为绿色
if test_save_path is not None:
a1 = copy.deepcopy(prediction)
a2 = copy.deepcopy(prediction)
a3 = copy.deepcopy(prediction)
#r通道
a1[a1 == 1] = 0
#g通道
a2[a2 == 1] = 255
#b通道
a3[a3 == 1] = 0
a1 = Image.fromarray(np.uint8(a1)).convert('L')
a2 = Image.fromarray(np.uint8(a2)).convert('L')
a3 = Image.fromarray(np.uint8(a3)).convert('L')
prediction = Image.merge('RGB', [a1, a2, a3])
prediction.save(test_save_path+'/'+case+'.png')
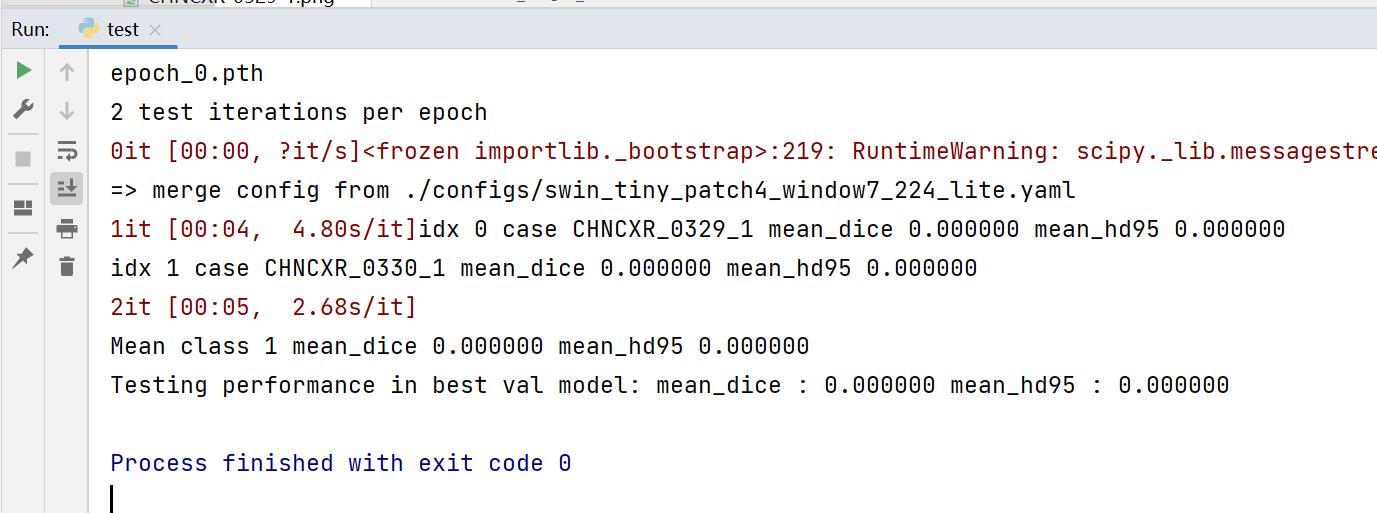
至此,设置完毕,右键run运行,若控制台出现下面的结果,则表示运行正确,我这里的权重只训练了一个epoch,所以预测的都是0。
3、查看预测结果
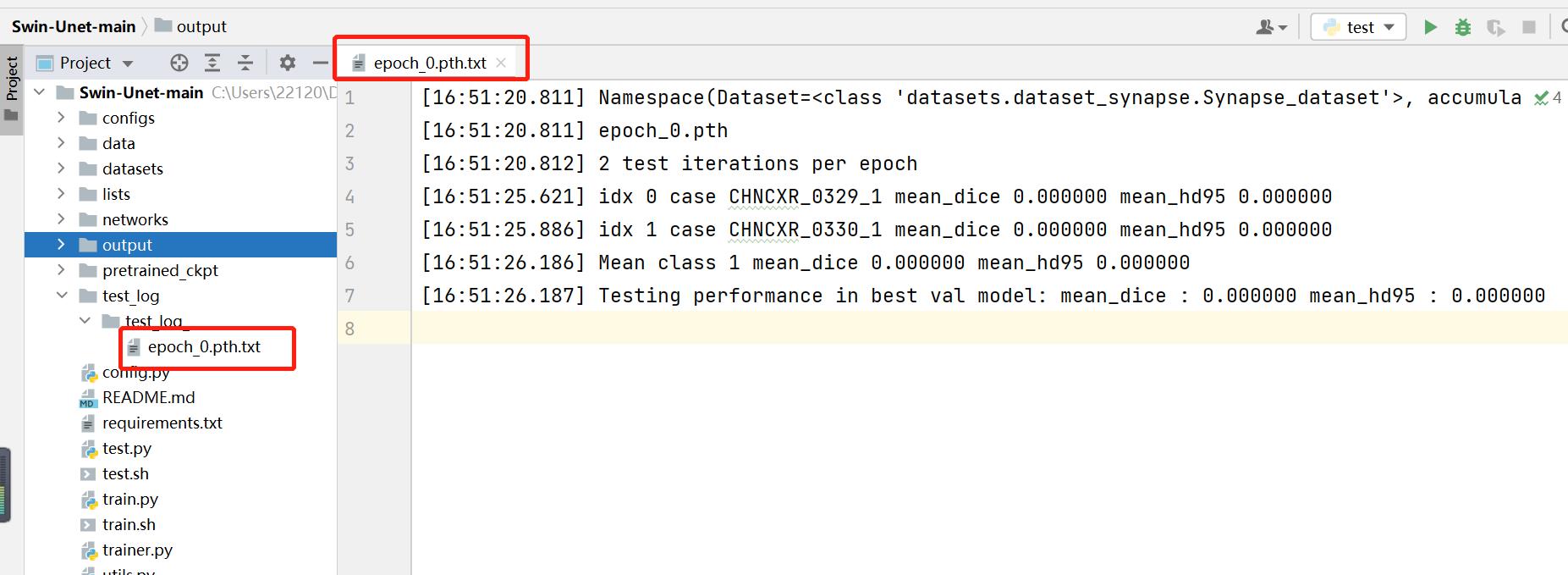
查看日志文件
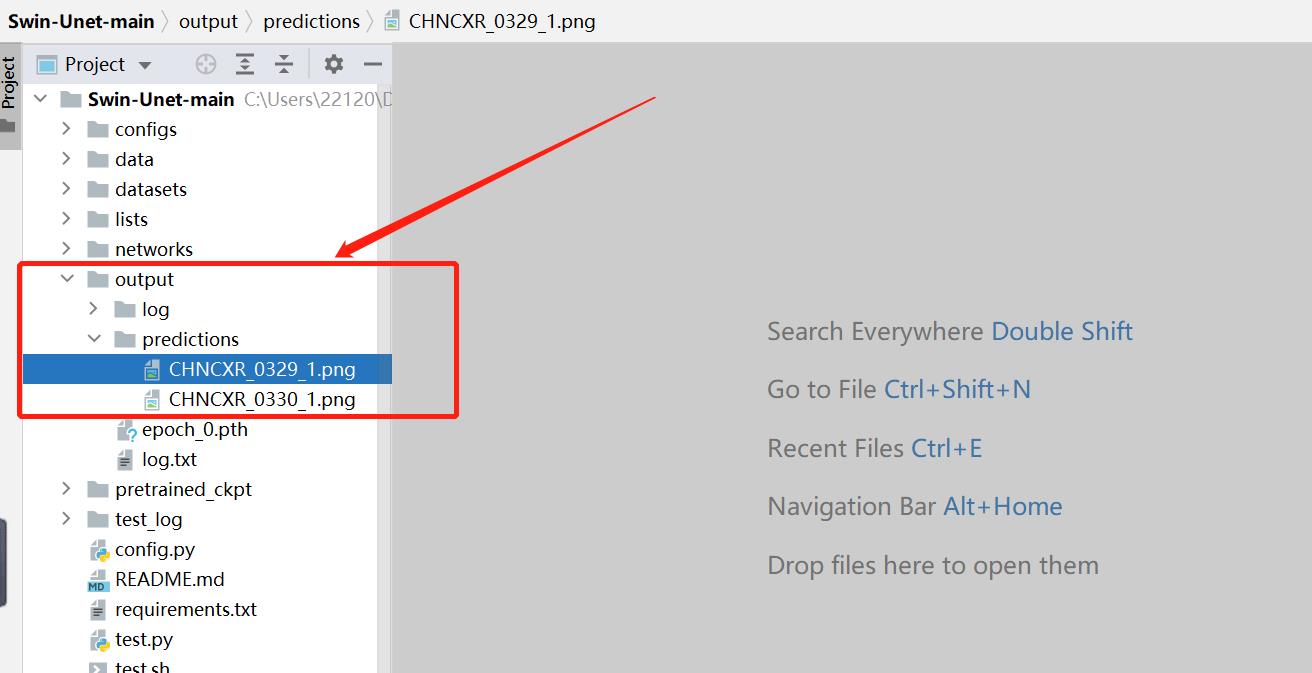
查看预测结果图
总结: swinUnet主要由swin_transform模块构成,数据量太少的时候训练效果很差,跟TransUnet不能比。由于仅文字表述某些操作存在局限性,故只能简略描述,有任何疑问可下方留言评论或私信,回复不及还望见谅,感激不尽!
SwinUnet官方代码训练自己数据集(单通道灰度图像的分割)
***************************************************
码字不易,收藏之余,别忘了给我点个赞吧!
***************************************************
---------Start
关于swinUnet网络的测试部分请移步另一篇博文
官方代码:https://github.com/HuCaoFighting/Swin-Unet
目的:训练Swin-Unet分割肺部区域
数据集位置:https://www.kaggle.com/datasets/nikhilpandey360/chest-xray-masks-and-labels
实现效果:
输入原图
输出标签
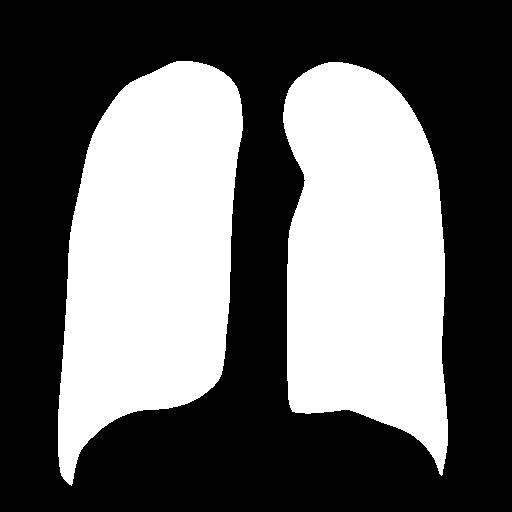
此文中只用了整个数据集中的345张图像用来完成整个分割任务!
1、下载官方代码并解压
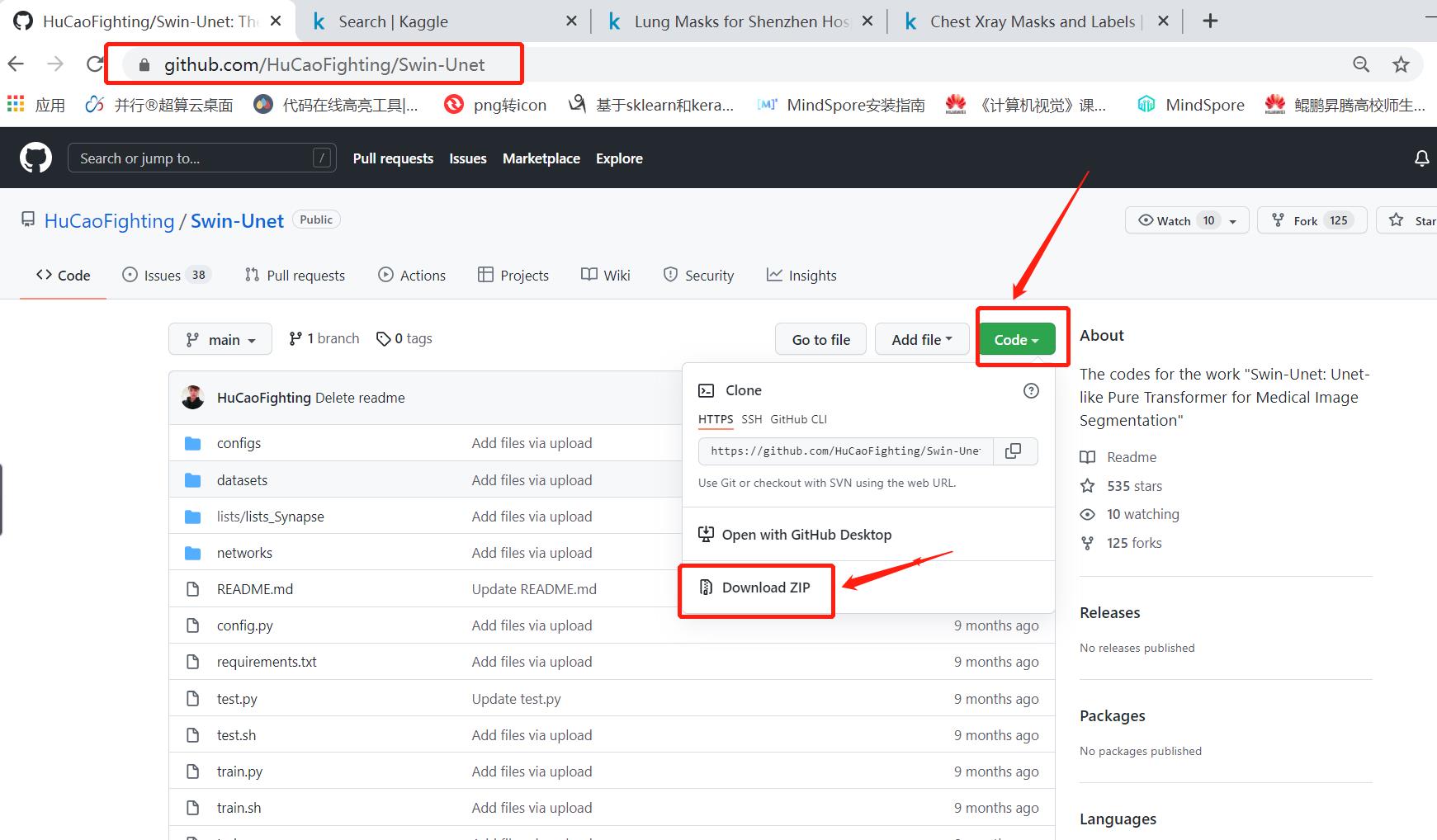
解压后的文件夹:
2、下载数据集并解压
我们只需要用到以下两个文件夹:分别代表图片和标签。原文件中图片有800张,标签只有704张,有部分img没有标签,需要在制作npz文件的时候注意一下。
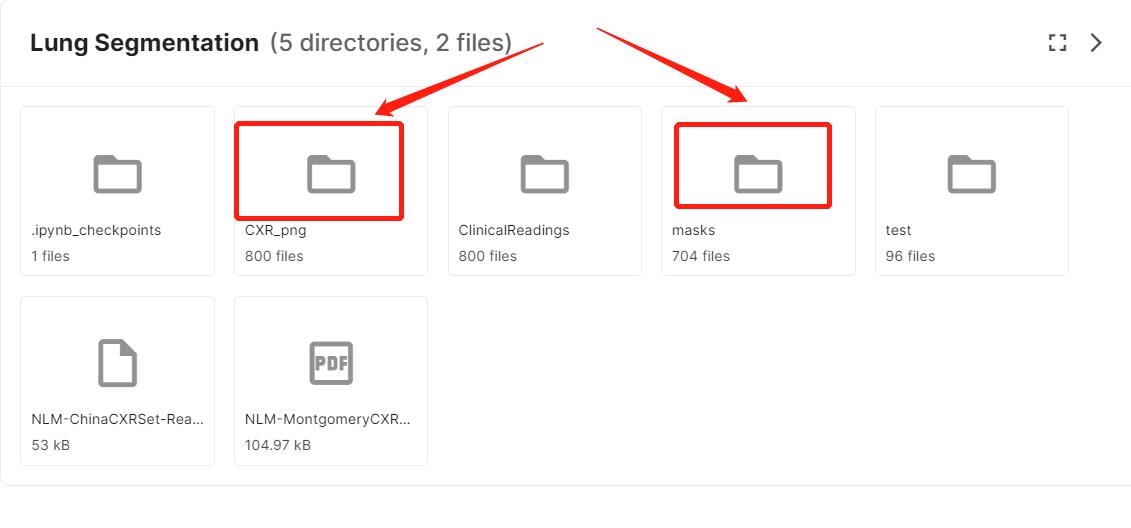
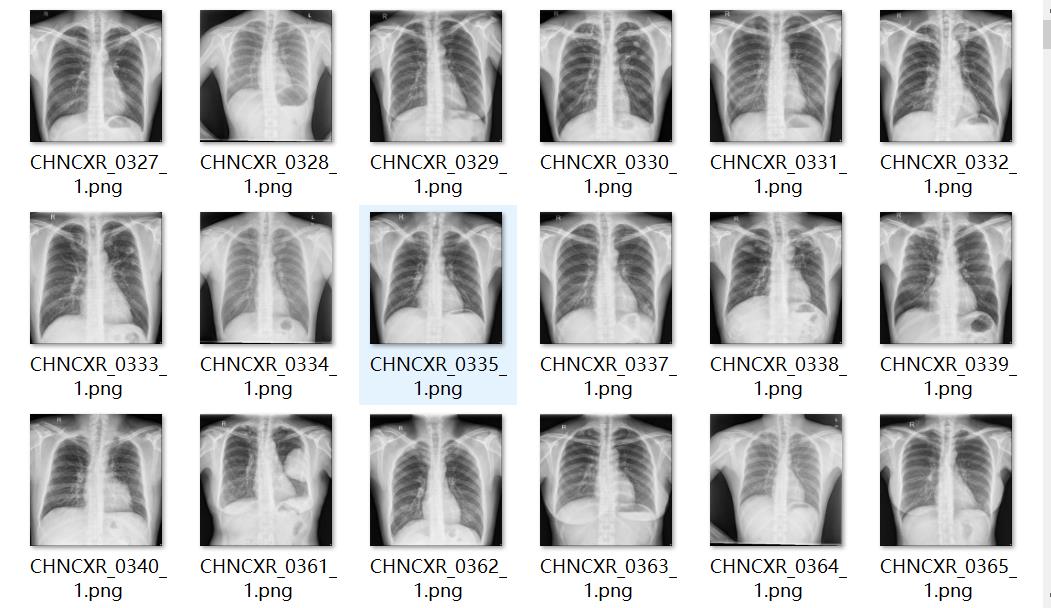
这是本文用到的345张图像和对应的mask
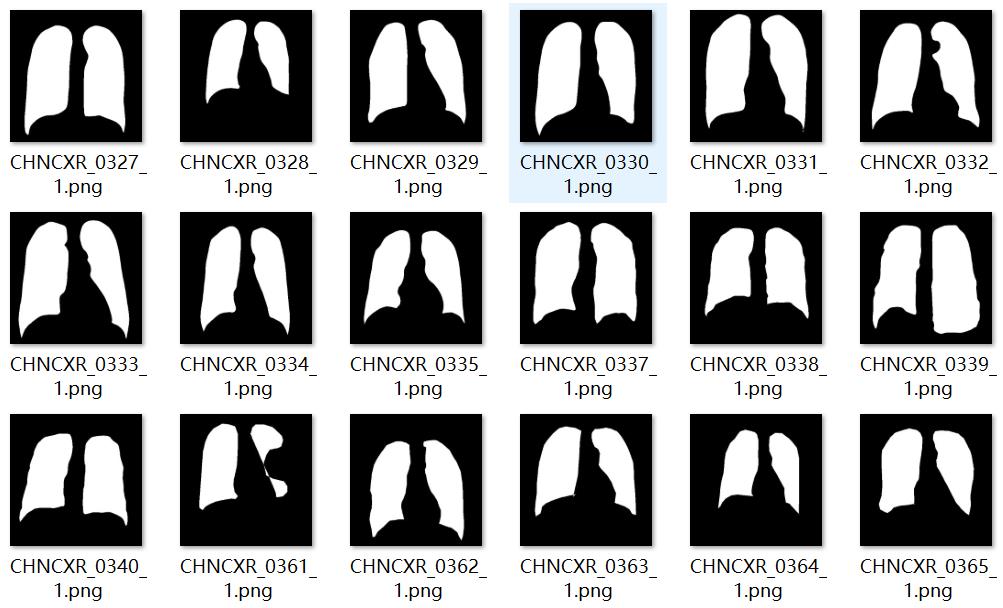
用于分割任务的标签,
3、生成.npz文件
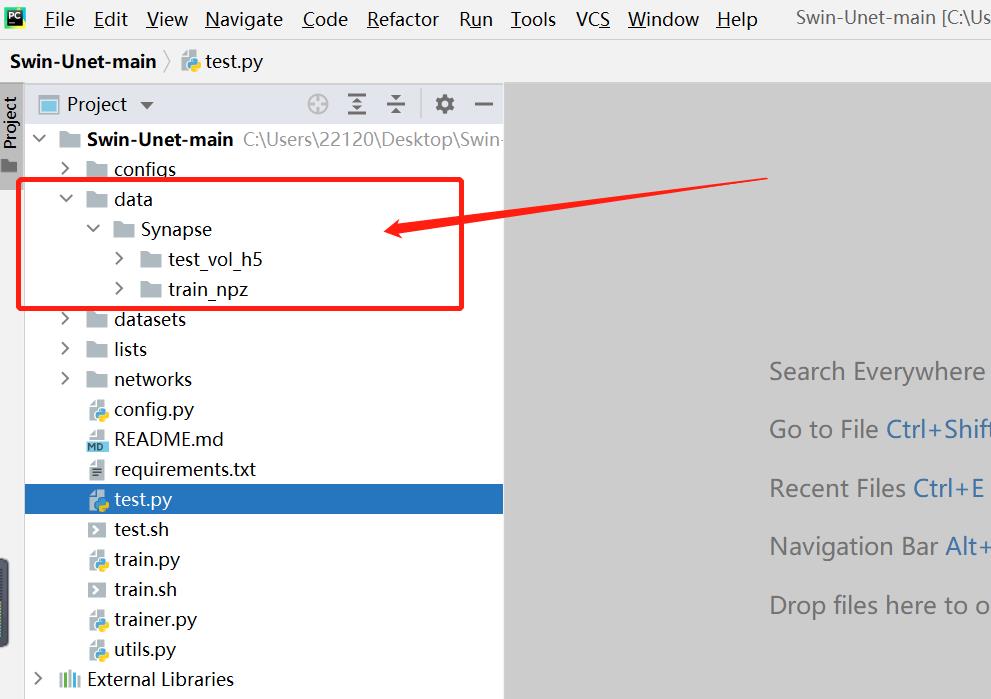
pycharm打开项目文件,配置好python解释器,创建data目录
data目录中,train_npz是用来存放训练所用的npz文件,test_vol_h5用来存放测试所用的npz文件,这是官方命名,可以少改代码。
将图像和标签转化成.npz文件
将原图像和标签保持在同目录

转换代码:(根据自己数据的位置修改下路径),若是只有背景+目标两个类别,这个代码可以直接用,若是三个及以上类别的分割,代码应该根据你的图像数据做调整,调整之后保证以下代码的label数组中,背景用0像素,目标用1,2,3,4…像素分别表示,一个像素值代表一种类别。例如(0:背景,1:类别1,2:类别2,3:类别3…)。
def npz():
#原图像路径
path = r'G:\\dataset\\Segmentation\\LungSegmentation\\npz\\images\\*.png'
#项目中存放训练所用的npz文件路径
path2 = r'G:\\dataset\\Unet\\TransUnet-ori\\data\\Synapse\\train_npz\\\\'
for i,img_path in enumerate(glob.glob(path)):
#读入图像
image = cv2.imread(img_path)
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
#读入标签
label_path = img_path.replace('images','labels')
label = cv2.imread(label_path,flags=0)
#将非目标像素设置为0
label[label!=255]=0
#将目标像素设置为1
label[label==255]=1
#保存npz
np.savez(path2+str(i),image=image,label=label)
print('------------',i)
# 加载npz文件
# data = np.load(r'G:\\dataset\\Unet\\Swin-Unet-ori\\data\\Synapse\\train_npz\\0.npz', allow_pickle=True)
# image, label = data['image'], data['label']
print('ok')
将训练和测试的图像数据分别生成为train_npz和test_vol_h5中的npz文件
生成npz文件对应的txt文件
txt文件的内容是模型训练和测试过程中读入图像数据的名称。忽略my_tools.py文件。
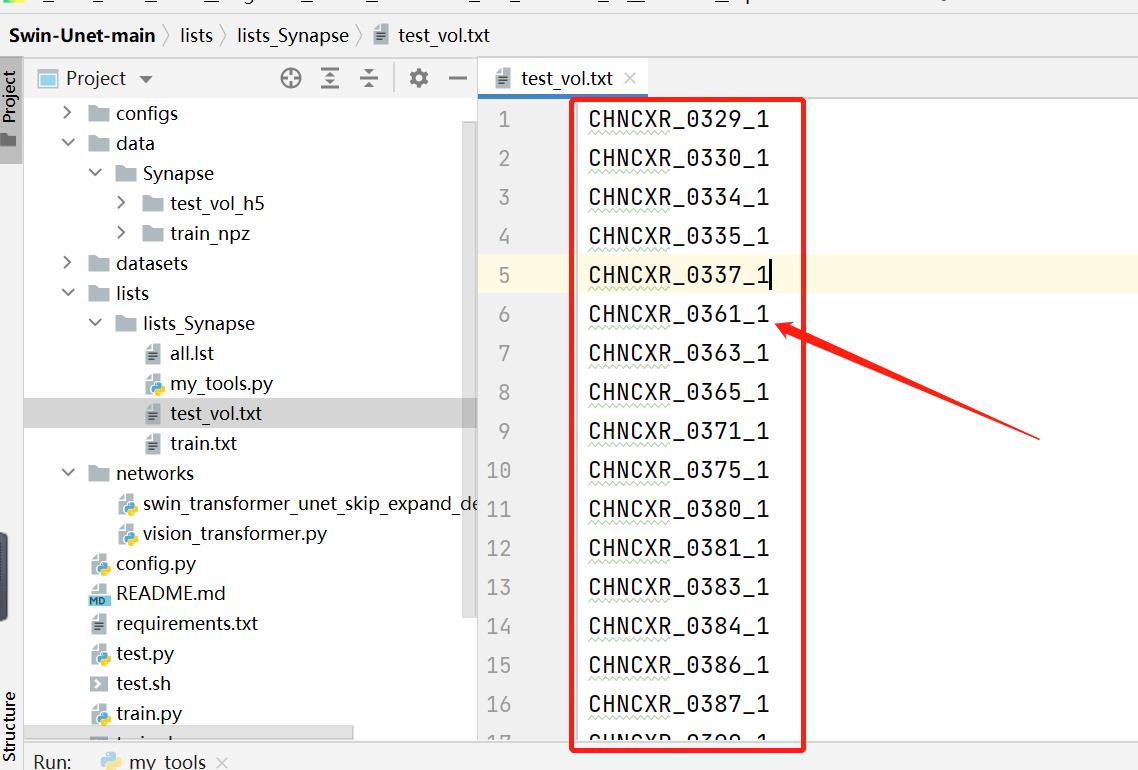
生成txt文件的代码,根据训练和测试的npz文件分别生成train.txt和test_vol.txt文件。
def write_name():
#npz文件路径
files = glob.glob(r'C:\\Users\\22120\\Desktop\\Swin-Unet-main\\data\\Synapse\\test_vol_h5\\*.npz')
#txt文件路径
f = open(r'C:\\Users\\22120\\Desktop\\Swin-Unet-main\\lists\\lists_Synapse\\test_vol.txt','w')
for i in files:
name = i.split('\\\\')[-1]
name = name[:-4]+'\\n'
f.write(name)
4、下载预训练权重
权重下载好之后,放入项目的pretrained_ckpt文件夹下,官方只提供了输入大小为224的模型权重。
5、修改部分代码
当你的图像数据是单通道时,按照文中写的内容修改后肯定能正常训练。若是三通道及以上的输入图像,也照着文中写的内容修改,若仍有问题,可以评论或私信我,一起解决吧。
5.1 修改train.py
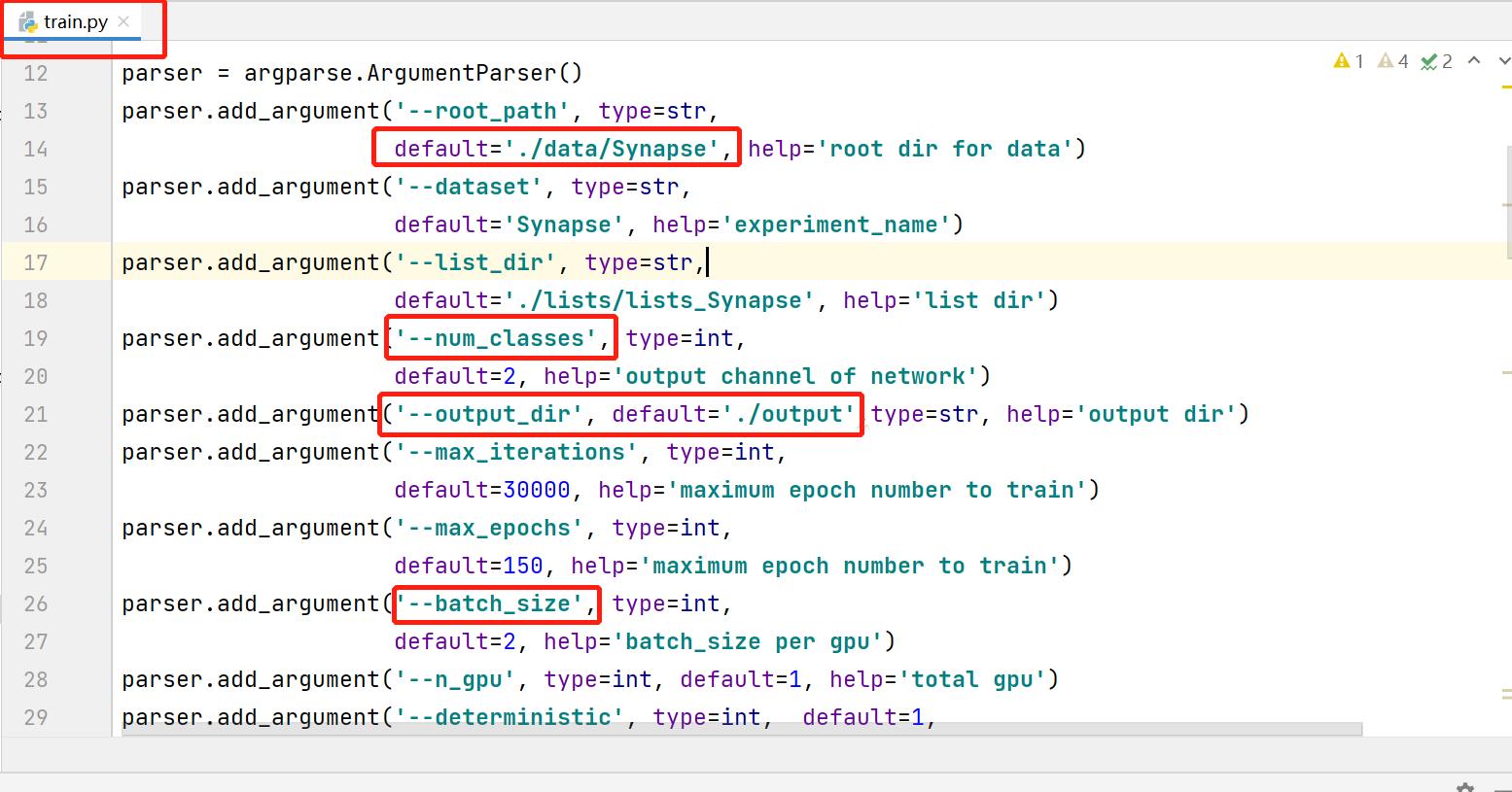
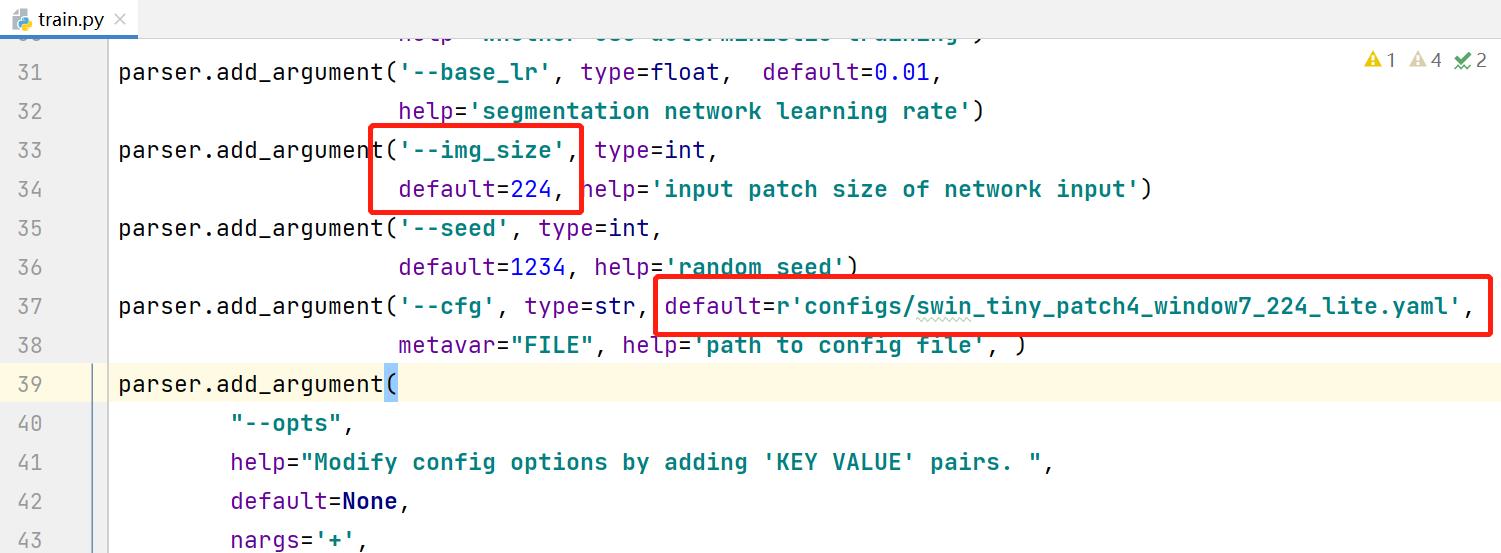
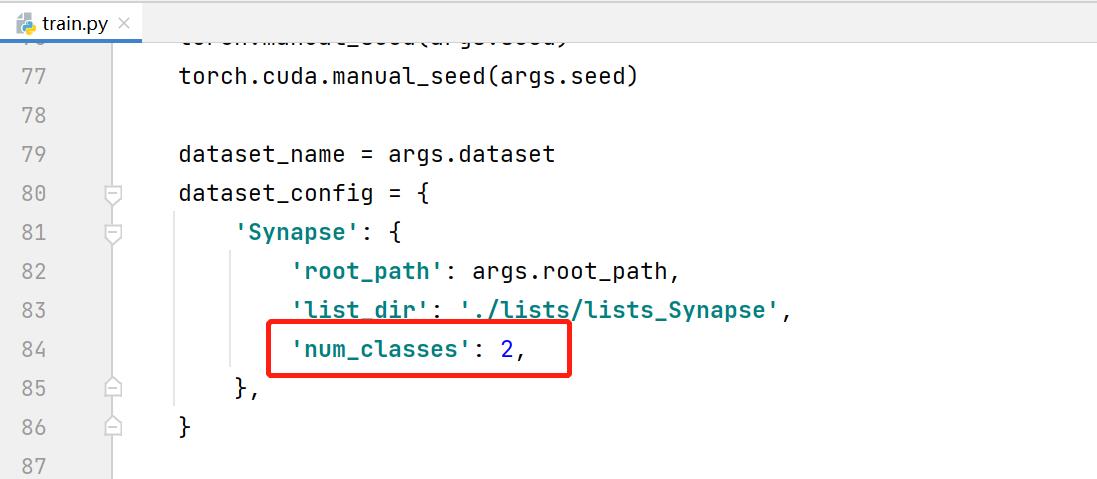
修改常规参数,配置文件路径,注意num_classes等于背景+预测目标类别个数。因为修改之处不多,见谅没有放上修改后的代码,参考图中标识修改即可。
output_dir:训练日志和输出权重保存的路径
root_path:为数据集存放的根目录
5.2 修改dataset_synapse.py
自己生成的npz文件和官方的npz文件格式有差异,在这里做了调整,调整之后完全一致。
5.3. 修改trainer.py文件
设置trainer.py文件中的DataLoader函数中的num_workers=0
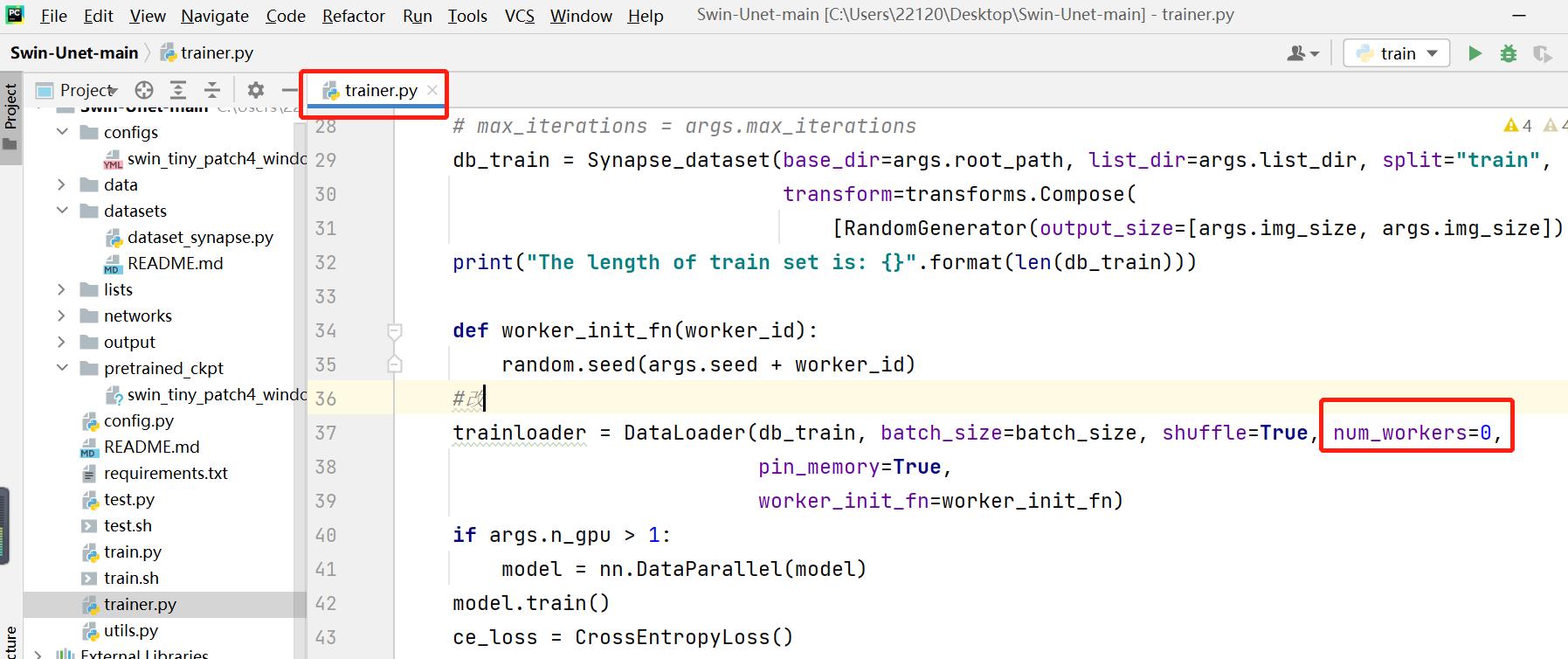
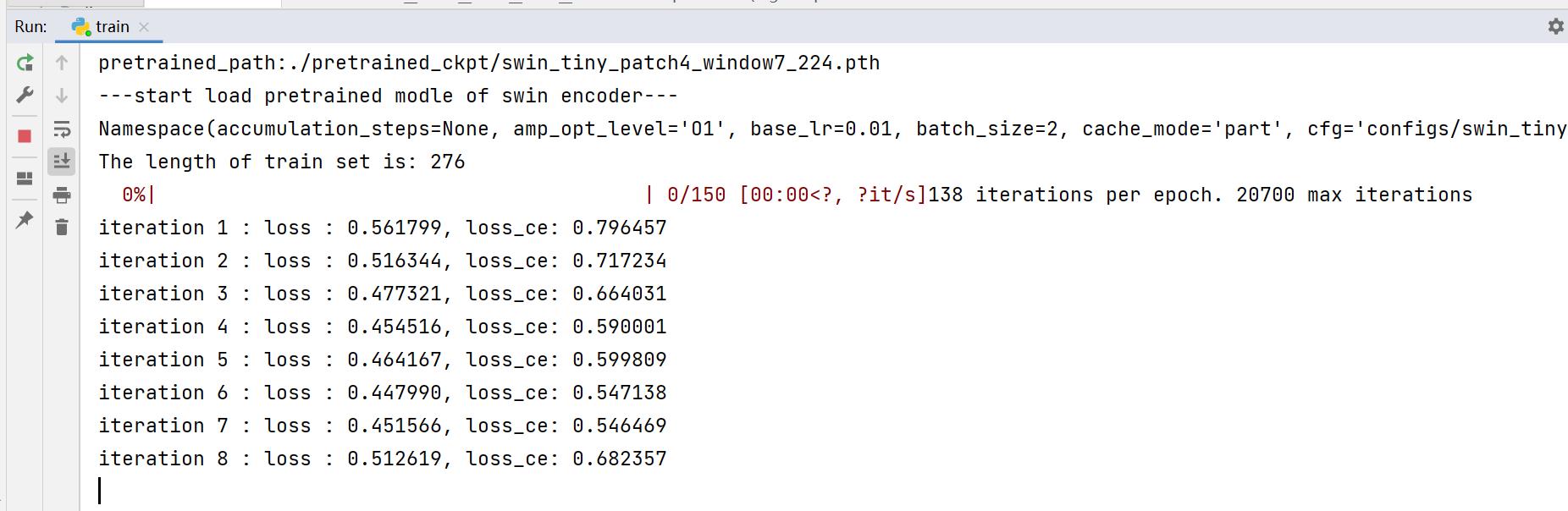
至此,所有代码修改完毕,执行train.py文件,若控制台有以下输出,即成功跑通!
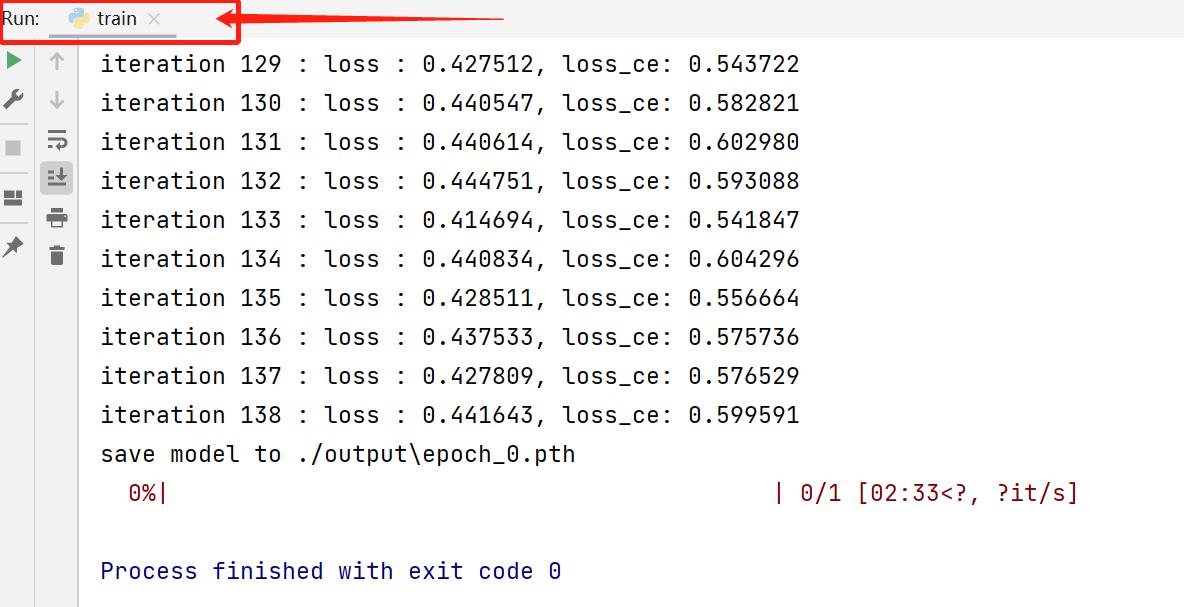
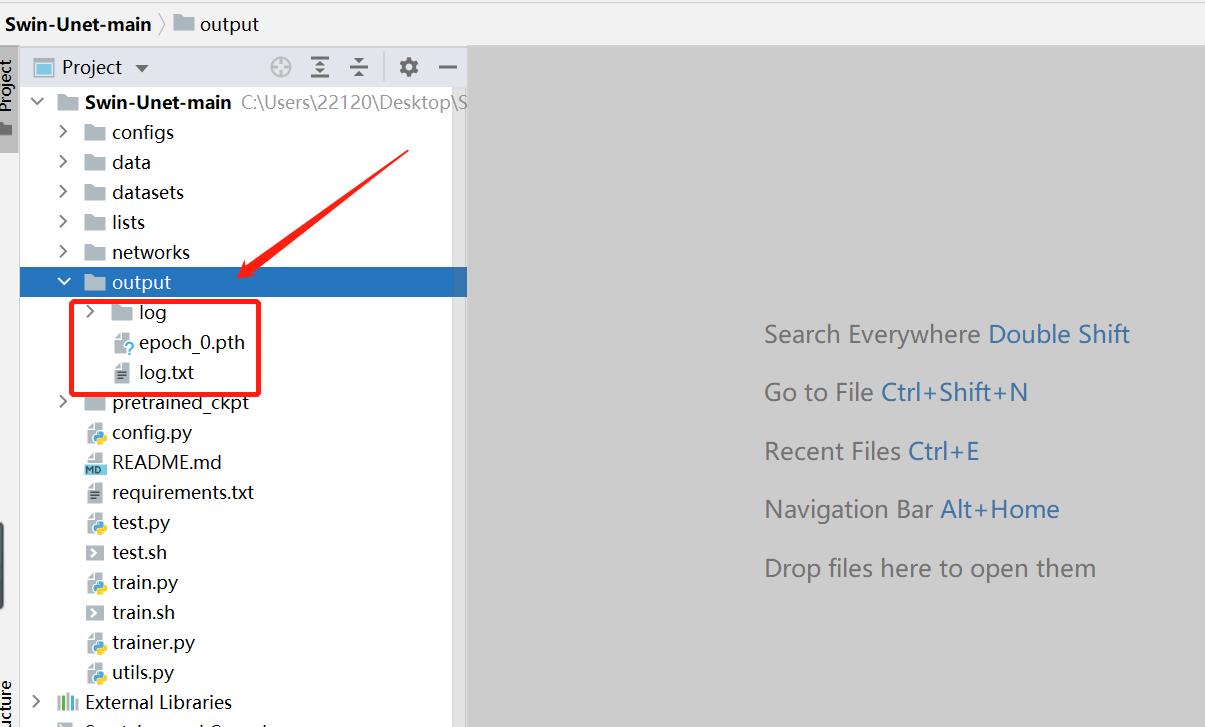
训练完毕后项目文件中的output文件夹里存放着训练的输出日志和模型权重。
总结: 由于仅文字表述某些操作存在局限性,故只能简略描述,有任何疑问可下方留言评论或私信,回复不及还望见谅,感激不尽!
以上是关于swinUnet官方代码测试自己的数据集(已训练完毕)的主要内容,如果未能解决你的问题,请参考以下文章