分布式消息中间件之RabbitMQ学习笔记[一]
Posted 山河已无恙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式消息中间件之RabbitMQ学习笔记[一]相关的知识,希望对你有一定的参考价值。
写在前面
- 嗯,陆续的整理一些中间件的笔记
- 今天和小伙伴们分享
RabbitMQ相关笔记 - 博文偏理论,内容涉及:
RabbitMQ的简单介绍AMQP协议标准介绍RabbitMQ Demo
- 食用方式:
- 了解
生产者消费者模式 - 通过本文,对
RabbitMQ有大概认识
- 了解
户外依然大雨滂沱,只是这回彷彿不仅命运一人独自哭泣,不晓得由来,窗外的雨水似乎渗上我心头,有些寒冻,有些缩麻,还有些苦涩。城市万家灯火,橘黄街灯与家户里的温暖流洩,我总觉得这时候的我,最脆弱。 -----《Unser Leben Unser Traum》
RabbitMQ简介
RabbitMQ是一个由Erlang语言开发的基于AMOP标准的开源消息中间件。RabbitMQ最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
其具体特点包括:
- 保证可靠性( Reliability),
RabbitMQ使用一些机制来保证可靠性,如持久化、传输确认、发布确认等。 - 具有灵活的路由(Flexible Routing)功能。在消息进入队列之前,是通过
Exchange (交换器)来路由消息的。对于典型的路由功能,RabbitMQ已经提供了一些内置的Exchange来实现。针对更复杂的路由功能,可以将多个Exchange绑定在一起,也可以通过插件机制来实现自己的Exchange. - 支持消息集群(Clustering),多台
RabbiMQ服务器可以组成一个集群,形成一个逻辑Broker. - 具有高可用性(Highly Available),队列可以在
集群中的机器上进行镜像,使得在部分节点出现问题的情况下队列仍然可用。 - 支持多种协议(Multi-protocol),
RabbitMQ除支持AMQP协议之外,还通过插件的方式支持其他消息队列协议,比如STOMP, MQTT等。 - 支持多语言客户端(Many Client),
RabbitMQ几乎支持所有常用的语言,比如Java..NET,Ruby等 - 提供管理界面(Management UI),
RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息Broker的许多方面 - 提供跟踪机制(Tracing),
RabbitMQ提供了消息跟踪机制,如果消息异常,使用者可以查出发生了什么情况。 - 提供插件机制(Plugin System),
RabbitMQ提供了许多插件,从多方面进行扩展,也可以编写自己的插件.
我们先来看一下AMOP协议,了解消息中间件的小伙伴,这个协议应该不陌生,这里我们简单了解下
AMQP标准
在2004年,摩根大通和iMatrix开始着手Advanced Message Queuing Protocol (AMQP)开放标准的开发。2006年,发布了AMQP规范。目前AMQP协议的版本为1.0。
一般来说,将AMQP协议的内容分为三部分:基本概念、功能命令和传输层协议。
-
基本概念:指
AMQP内部定义的各组件及组件的功能说明。 -
功能命令:指该协议所定义的一系列命令,应用程序可以基于这些命令来实现相应的功能。
-
传输层协议(TCP/UDP):是一个网络级协议,它定义了数据的传输格式,消息队列的客户端可以
基于这个协议与消息代理和AMQP的相关模型进行交互通信,该协议的内容包括数据帧处理、信道复用、内容编码、心跳检测、数据表示和错误处理等。
主要概念
Message (消息):消息服务器所处理数据的原子单元。消息可以携带内容,从格式上看,消息包括一个内容头、一组属性和一个内容体。
这里所说的消息可以对应到许多不同
应用程序的实体,比如一个应用程序级消息、一个传输文件、一个数据流帧等。消息可以被保存到磁盘上,这样即使发生严重的网络故障、服务器崩溃也可确保投递消息可以有优先级,高优先级的消息会在等待同一个消息队列时在低优先级的消息之前发送,当消息必须被丢弃以确保消息服务器的服务质量时,服务器将会优先丢弃低优先级的消息。消息服务器不能修改所接收到的并将传递给消费者应用程序的消息内容体。消息服务器可以在内容头中添加额外信息,但不能删除或修改现有信息。
-
Publisher (消息生产者):也是一个向交换器发布消息的客户端应用程序。 -
Exchange (交换器):用来接收消息生产者所发送的消息并将这些消息路由给服务器中的队列。 -
Binding (绑定):用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则
所以可以将交换器理解成一个由绑定构成的路由表(路由控制表,IP寻址)。
-
Virtual Host (虚拟主机):它是消息队列以及相关对象的集合,是共享同一个身份验证和加密环境的独立服务器域。每个虚拟主机本质上都是一个mini版的消息服务器,拥有自己的队列、交换器、绑定和权限机制。 -
Broker (消息代理):表示消息队列服务器,接受客户端连接,实现AMQP消息队列和路由功能的过程。 -
Routing Key (路由规则):虚拟机可用它来确定如何路由一个特定消息。 -
Queue (消息队列):用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可被投入一个或多个队列中。消息一直在队列里面,等待消费者连接到这个队列将其取走。 -
Connection (连接):可以理解成客户端和消息队列服务器之间的一个TCP连接。 -
Channel (信道):仅仅当创建了连接后,若客户端还是不能发送消息,则需要为连接创建一个信道。信道是一条独立的双向数据流通道,它是建立在真实的TCP连接内的虚拟连接。
AMQP命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,它们都通过信道完成。一个连接可以包含多个信道,之所以需要信道,是因为TCP连接的建立和释放都是十分昂贵的,如果客户端的每一个线程都需要与消息服务器交互,如果每一个线程都建立了一个TCP连接,则暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。
Consumer (消息消费者):表示一个从消息队列中取得消息的客户端应用程序。
核心组件的生命周期
消息的生命周期,一条消息的流转过程通常是这样的:
Publisher(消息生产者)产生一条数据,发送到Broker(消息代理),Broker中的Exchange(交换器)可以被理解为一个规则表(Routing Key和Queue的映射关系-Binding),Broker收到消息后根据Routing Key查询投递的目标Queue.Consumer向Broker发送订阅消息时会指定自己监听哪个Queue,当有数据到达Queue时Broker会推送数据到Consumer.
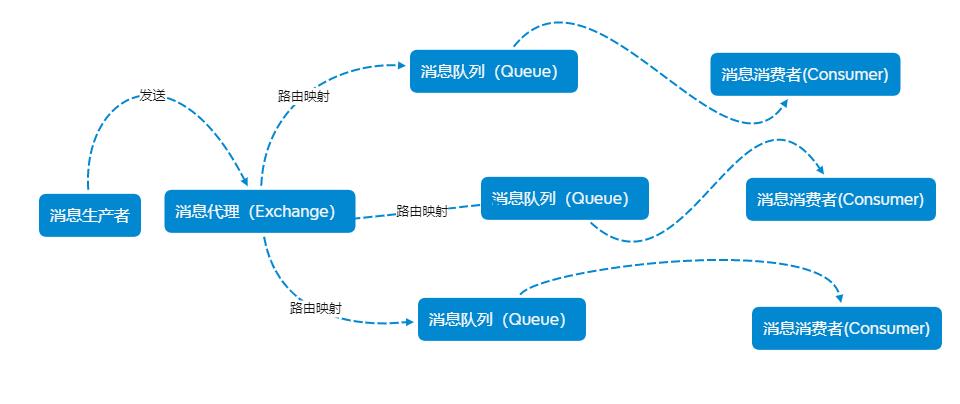
交换器的生命周期
每台AMQP服务器都预先创建了许多交换器实例,它们在服务器启动时就存在并且不能被销毁。如果你的应用程序有特殊要求,则可以选择自己创建交换器,并在完成工作后进行销毁。
队列的生命周期
这里主要有两种消息队列的生命周期,即持久化消息队列和临时消息队列。持久化消息队列可被多个消费者共享,不管是否有消费者接收,它们都可以独立存在。临时消息队列对某个消费者是私有的,只能绑定到此消费者,当消费者断开连接时,该消息队列将被删除。
RabbitMQ基本概念
如图是RabbitMQ的整体架构图。
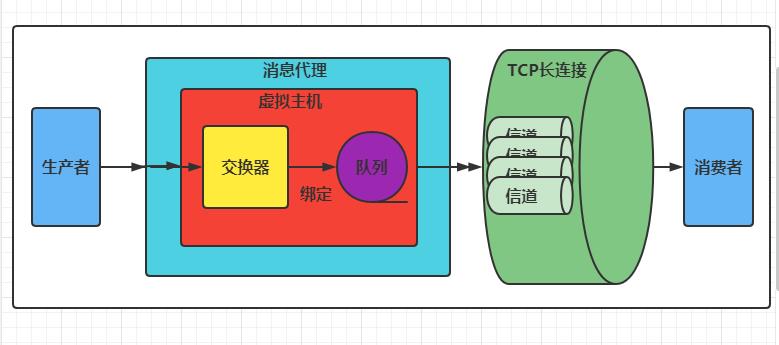
Message (消息):消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列可选属性组成,这些属性包括 routing-key (路由键),priority (相对于其他消息的优先级)、 delivery-mode (指出该消息可能需要持久化存储)等。
Publisher (消息生产者):一个向交换器发布消息的客户端应用程序。
Exchange (交换器):用来接收生产者发送的消息,并将这些消息路由给服务器中的队列。.
RabbitMQ是AMQP协议的一个开源实现,所以其基本概念也就是AMQPt中的基本概念。关于其他的概念小伙伴可以看上面。
(1) AMQP中的消息路由
在AMQP中增加了Exchange和Binding的角色。生产者需要把消息发布到Exchange上,消息最终到达队列并被消费者接收,而Binding决定交换器上的消息应该被发送到哪个队列中。
(2)交换器类型
不同类型的交换器分发消息的策略也不同,目前交换器有4种类型: Direct, Fanout, Topic,Headers。其中Headers交换器匹配AMQP消息的Header而不是路由键。此外, Headers交换器和Direct交换器完全一致,但性能相差很多,目前几乎不用了。
RabbitMQ Demo
RabbitMQ官网:https://www.rabbitmq.com/
RabbitMQ服务安装
基于Docker的安装:
RabbitMQ镜像 :https://registry.hub.docker.com/_/rabbitmq?tab=description&page=2&ordering=last_updated
# 启动docker服务
[root@liruilong ~]# systemctl restart docker
# 查看镜像
[root@liruilong ~]# docker images
#指定版本,该版本包含了web控制页面
[root@liruilong ~]# docker pull rabbitmq:management
运行容器:
方式一:默认guest 用户,密码也是 guest
[root@liruilong ~]# docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 -p 5672:5672 rabbitmq:management
方式二:设置用户名和密码
[root@liruilong ~]# docker run -d --hostname my-rabbit --name rabbit -e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password -p 15672:15672 -p 5672:5672 rabbitmq:management
发布服务,将端口映射到15672,5672
[root@liruilong ~]# docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 -p 5672:5672 rabbitmq:management
2189f2fa53f1e76306a2ad422e0fa33bca1ae0f3ee77514573d71aca9ce24801
[root@liruilong ~]#
这里需要注意的是端口绑定,需要把访问端口和管理端口同时绑定。如果是ESC的话,需要配置安全组
访问路径:http://localhost:15672/ 登录

下面我们通过具体的Demo来深入学习下Rabbit相关概念
Hello World!
Java客户端访问RabbitMQ实例
RabbitMQ支持多种语言访问。使用java需要添加的maven依赖,下面我们看一个简单的 Hello World! Demo
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>4.1.0</version>
</dependency>

消息生产者
package msg_queue.rabbitmq;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* @author Liruilong
* @Description TODO 消息生产者
* @date 2022/4/20 20:46
**/
public class Producer
public static void main(String[] args) throws IOException, TimeoutException
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("guest");
factory.setPassword("guest");
//设置 RabbitMQ 地址
factory.setHost("localhost");
//默认访问5672端口 factory.setPort(5672);
factory.setVirtualHost("/");
//建立到代理服务器到连接
try (Connection conn = factory.newConnection();
//创建信道
Channel channel = conn.createChannel())
//声明交换器
String exchangeName = "hello-exchange";
// 交换器类型为direct
channel.exchangeDeclare(exchangeName, "direct", true);
// 定义 路由键
String routingKey = "testRoutingKey";
//发布消息
byte[] messageBodyBytes = "学习Rabbitmq".getBytes();
channel.basicPublish(exchangeName, routingKey, null, messageBodyBytes);
首先创建一个连接工厂,再根据连接工厂创建连接,之后从连接中创建信道,接着声明一个交换器和指定路由键,然后才发布消息,最后将所创建的信道、连接等资源关闭。代码中的ConnectionFactory, Connection、 Channel都是RabbitMQ提供的API中最基本的类。
ConnectionFactory是Connection的制造工厂Connection代表RabbitMQ的Socket连接,它封装了Socket操作的相关逻辑。Channel是与RabbitMQ打交道的最重要的接口,大部分业务操作都是在Channel中完成的,比如定义队列、定义交换器、队列与交换器的绑定、发布消息等。
消息消费者
package msg_queue.rabbitmq;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* @author Liruilong
* @Description TODO 消息消费者
* @date 2022/4/20 20:48
**/
public class Consumer
public static void main(String[] args) throws IOException, TimeoutException
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("guest");
factory.setPassword("guest");
factory.setHost("127.0.0.1");
factory.setVirtualHost("/");
//建立到代理服务器到连接
try (Connection conn = factory.newConnection();
//创建信道
final Channel channel = conn.createChannel())
//声明交换器
String exchangeName = "hello-exchange";
// true 设置是否持久化
channel.exchangeDeclare(exchangeName, "direct", true);
//获取队列,不带任何参数的queueDeclare()方法,默认会创建一个由rabbitmq命名的(形如amq.gen-LhQzlgv3GhDOv8PIDabOXA)、排他的、自动删除的、非持久化的队列。
String queueName = channel.queueDeclare().getQueue();
String routingKey = "testRoutingKey";
//绑定队列,通过键 testRoutingKey 将队列和交换器绑定起来
channel.queueBind(queueName, exchangeName, routingKey);
//消费消息
while (true)
// 设置是否自动确认,当消费者接收到消息后要告诉 mq 消息已接收,如果将此参数设置为 true 表示会自动回复 mq,如果设置为 false,要通过编程实现回复
boolean autoAck = false;
channel.basicConsume(queueName, autoAck
// 设置消费者获取消息成功的回调函数
, (consumerTag, delivery) ->
System.out.printf("消费的消息体内容:%s\\n", new String(delivery.getBody(), "UTF-8"));
System.out.println("消费的路由键:" + delivery.getEnvelope().getRoutingKey());
System.out.println("消费的内容类型:" + delivery.getProperties().getContentType());
System.out.println("consumerTag:"+consumerTag);
//确认消息
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
// 设置消费者获取消息失败的回调函数
, consumerTag ->
System.out.println("consumerTag:"+consumerTag);
);
消费的消息体内容:学习Rabbitmq
消费的路由键:testRoutingKey
消费的内容类型:null
consumerTag:amq.ctag-rC_49IlY-Awwj7G_hXIR_Q
消息消费者同样需要创建一个连接工厂,再根据连接工厂创建连接,之后从连接中创建信道,然后创建交换器,路由建,创建队列,通过路由建将交换器和队列绑定。
通道
消息客户端和消息服务器之间的通信是双向的,不管是对客户端还是服务器来说,保持它们之间的网络连接是很耗费资源的。为了在不占用大量TCP/P连接的情况下也能有大量的逻辑连接, AMQP增加了通道(Channel)的概念…
RabbitMQ支持并鼓励在一个连接中创建多个通道,因为相对来说创建和销毁通道的代价会小很多。需要提醒的是,作为经验法则,应该尽量避免在线程之间共享通道,你的应用应该使用每个线程单独的通道,而不是在多个线程上共享同一个通道,因为大多数客户端不会让通道线程安全(因为这将对性能产生严重的负面影响)。
工作队列(又名:任务队列)
上面的Demo是一个一对一的消息中间件模式,即一个消费者只对应一个生产者,生产者指定路由键把消息发生到交换器,消费者通过路由键绑定交换器和工作队列,从而获取工作队列的消息。但是在实际的情况中,往往并不是这样。一个生产者要对应好多个消费者,比如我们需要导出数据量相对较大的excel或者pdf文件,这是一个相对耗时的操作,有时可能还会涉及到IO阻塞,所以一般会放到异步处理,如果把这种行为当中是一种任务来看,常见的处理方式是,通过消息队列或者定时任务,或者一个调度框架来处理。任务状态放到数据库里。
一般情况下通过消息队列是一种很好的解决办法,因为我们可以起多个工作进程来处理工作队列中任务。
来看一个Demo,这里我们体验下 python的Rabbitmq客户端
需要安装依赖包 pika
python -m pip install pika --upgrade
在消费者里面使用python的sleep方法来模拟执行时间,在生产中通过’…'来声明任务的执行时间。
下面的代码是一个生产者,用于生产消息.即创建任务
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
"""
@File : send.py
@Time : 2022/04/21 00:09:19
@Author : Li Ruilong
@Version : 1.0
@Contact : 1224965096@qq.com
@Desc : rabbitmq 消息生产者
"""
# here put the import lib
import pika
import sys
# 建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.26.55'))
# 建立信道
channel = connection.channel()
message = ' '.join(sys.argv[1:]) or "Hello World!"
# 声明队列,设置durable参数为True,表示在server重启中要“活下来”,持久化。
channel.queue_declare(queue='hello', durable=True)
# 发送消息到队列,这里使用默认交换器,指定路由建和消息实体
channel.basic_publish(
exchange = ''
, routing_key = 'hello'
, body = message)
print(" [x] Sent %r" % message)
connection.close()
运行多次脚本生成不同的耗时的任务。
D:\\python\\code\\rabbit_mq_demo>
D:\\python\\code\\rabbit_mq_demo>py send.py 这是一本100的pdf...
[x] Sent '这是一本100的pdf...'
D:\\python\\code\\rabbit_mq_demo>py send.py 这是一本200的pdf......
[x] Sent '这是一本200的pdf......'
D:\\python\\code\\rabbit_mq_demo>py send.py 这是一本400的pdf.............
[x] Sent '这是一本400的pdf.............'
D:\\python\\code\\rabbit_mq_demo>py send.py 这是一本500的pdf................
[x] Sent '这是一本500的pdf................'
D:\\python\\code\\rabbit_mq_demo>
然后我们创建消费者进程来执行工作队列中的任务
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
@File : receive.py
@Time : 2022/04/21 00:11:58
@Author : Li Ruilong
@Version : 1.0
@Contact : 1224965096@qq.com
@Desc : 消费者
"""
# here put the import lib
import pika, sys, os
import time
def main():
connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.26.55'))
channel = connection.channel()
# 获取队列
channel.queue_declare(queue='hello',durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
# 成功接收消息的回调
def callback(ch, method, properties, body):
print(" [x] 开始生成文件 %r" % body.decode())
# 有几个点就睡眠几秒
time.sleep(body.count(b'.'))
print(" [x] 生成文件结束")
# 接收消息
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
channel.start_consuming()
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
print('Interrupted')
try:
sys.exit(0)
except SystemExit:
os._exit(0)
循环调度
这里我们运行两个消费者进程,可以发现工作队列被多个消费者顺序消费。在一些PDF文件生成中我们也可以使用类似的方式
D:\\python\\code\\rabbit_mq_demo>python receive.py
[*] Waiting for messages. To exit press CTRL+C
[x] 开始生成文件 '这是一本200的pdf......'
[x] 生成文件结束
[x] 开始生成文件 '这是一本500的pdf................'
[x] 生成文件结束
=============================
D:\\python\\code\\rabbit_mq_demo>python receive.py
[*] Waiting for messages. To exit press CTRL+C
[x] 开始生成文件 '这是一本100的pdf...'
[x] 生成文件结束
[x] 开始生成文件 '这是一本400的pdf.............'
[x] 生成文件结束
默认情况下,RabbitMQ 会按顺序将每条消息发送给下一个消费者。平均而言,每个消费者都会收到相同数量的消息。这种分发消息的方式称为循环。
消息确认
消费者消费消息的时候需要一定的时间,如果在这个时间内,消费者挂掉,但是生产队列并不知道消费者挂掉,正常我们希望如果一个消费者挂掉,我们希望将任务交付给另一个消费者。
在 RabbitMQ 通过 消息确认 来实现。当消费者处理完任务是,会返回一个 ack(nowledgement) ,告诉 RabbitMQ 一个特定的任务已经被接收、处理并且 RabbitMQ 可以自由地删除它。当消费者挂掉,没有发生ack时(其通道关闭、连接关闭或 TCP 连接丢失),RabbitMQ 将认为消息没有完全处理并将消息重新排队。如果同时有其他消费者在线,它会迅速将其重新发送给另一个消费者。这样,即使消费者挂掉,也可以确保不会丢失任何消息。
对消费者的ack心跳默认为 30 分钟,通过这种机制,这有助于检测异常的消费者。
默认情况下,消息自动确认是打开的。在前面的示例中,我们通过auto_ack=True 关闭了它。
#channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
channel.basic_consume(queue='hello', on_message_callback=callback)
消息持久性
如果 RabbitMQ 服务器停止,我们的任务仍然会丢失。当 RabbitMQ 退出或崩溃时,它会忘记队列和消息,除非你告诉它不要这样做。确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久的。
队列
channel.queue_declare(queue='task_queue',durable=True)
这里需要注意的是:
- RabbitMQ 不允许
使用不同的参数重新定义现有队列,并且会向任何尝试这样做的程序返回错误。 - 通过
queue_declare获取队列,当更改时需要同时应用于生产者和消费者代码。
通过上面的配置,即使 RabbitMQ 重新启动,task_queue队列也不会丢失。将息标记为持久的需要设置delivery_mode为pika.spec.PERSISTENT_DELIVERY_MODE值
关于消息持久性的注意事项
将消息标记为持久性并不能完全保证消息不会丢失。虽然它告诉 RabbitMQ 将消息保存到磁盘,但是当 RabbitMQ 接受消息并且还没有保存它时,仍然有很短的时间窗口,如果您需要更强的保证,那么您可以使用 发布者确认。
消息
channel.basic_publish(
exchange=''
, routing_key='hello'
, body=message
, properties=pika.BasicProperties(
delivery_mode=pika.spec.PERSISTENT_DELIVERY_MODE
))
公平调度
循环调度调度的一个很大的缺点就是,不会衡量任务的执行时间,当某些耗时长的任务恰好落在了一个消费者身上,那对那个消费者太不公平,所以我们希望可以有一种公平的调度机制。正常的解决方案,我们可以设置不同的调度策略,通过算法计算,利用不同消费者指标值,为每个消费者打分,选择合适的。
那么 RabbitMQ 又是如何处理的?
RabbitMQ 使用带有prefetch_count=1设置的Channel#basic_qos通道方法 。这使用basic.qos协议方法来告诉 RabbitMQ 一次不要给一个worker多个消息。或者,换句话说,在工作人员处理并确认之前的消息之前,不要向工作人员发送新消息。相反,它将把它分派给下一个不忙的消费者
# 接收消息
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='hello', on_message_callback=callback)
总结
RabbitMQ最大的优势在于提供了比较灵活的消息路由策略、高可用性、可靠性,以及丰富的插件、多种平台支持和完善的文档。不过,由于AMQP协议本身导致它的实现比较重量,从而使得与其他MQ (比如Kafka)对比其吞吐量处于下风。在选择MQ时关键还是看需求-是更看重消息的吞吐量、消息堆积能力还是消息路由的灵活性、高可用性、可靠性等方面,先确定场景,再对不同产品进行有针对性的测试和分析,最终得到的结论才能作为技术选型的依据
关于不同的交换器区别优势,匹配方式,路由等,包括集群的搭建会在之后的博文中和小伙伴们分享
整理参考博文书籍
《分布式消息中间件实践》 RabbitMQ部分
RabbitMQ官网:https://www.rabbitmq.com/
以上是关于分布式消息中间件之RabbitMQ学习笔记[一]的主要内容,如果未能解决你的问题,请参考以下文章