消息队列学习笔记
Posted Java小学生的成长日志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息队列学习笔记相关的知识,希望对你有一定的参考价值。
一 . 消息队列的理解
消息队列中间是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋问题,实现高性能,高可用,可伸缩和最终一致性架构
使用比较多的消息队列有activeMQ,RabbitMQ,
二,消息队列的应用场景
1.异步处理
场景说明:
用户注册后,需要发注册邮件和注册短信.传统的方式有两种:
1)串行方式:将注册信息写入数据库之后,发送注册邮件,在发送注册短信,以上三个任务完成后,返回给客户端.
2) 并行方式: 将注册信息写入数据库成功之后,发送注册邮件的同时,发送注册短信,以上三个动作完成后,返回给客户端.与串行的最大差别就是:并行的方式可以提高处理时间
小结:
如以上案例描述,传统的方式,系统的性能(并发量,吞吐量,响应时间)会有瓶颈,如何解决这个问题呢?引入消息队列,将不必须的业务逻辑异步处理.按照以上约定,用户的相应时间相当于是注册信息写入数据库的时间,也就是50ms,注册消息,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,提高了系统的吞吐量.
2.应用解耦
场景说明:
用户下单后,订单系统需要通知库存系统,传统的做法是,订单系统调用库存系统的接口.传统模式的缺点:1)假如库存系统无法访问,则订单减少库存则失败,从而导致订单失败,2)订单系统与库存系统耦合
引入消息队列后:1)订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户下单成功.2)库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作, 3)假如在下单时,库存系统不能正常使用,也不影响正常下单,因为下单后,订单系统写入消息队列后就不在关心其他的后续操作了,实现订单系统与库存系统的应用解耦
3.流量的削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或抢购中广泛使用
应用 场景:
秒杀活动一般会因为流量过大,导致流量的暴增,应用挂掉,为解决这个问题,一般需要在前端应用前端切入消息队列.1)可以控制活动的人数,2)可以避免短时间内高流量压垮应用,3)用户的请求,服务器接收后,首先写入消息队列,假如消息队列长度超过最大数量,则直接抛弃应用请求或跳转到错误页面,4)秒杀业务根据消息队列中的请求信息,再做后续处理.
4.日志处理
日志吹是指将消息队列中在日志处理中,比如kafka的应用,解决大量日志传输的问题,架构简化如下
日志采集客户端,负责日志数据采集,定时写入kafka队列
kafka消息队列,负责日志数据的接受,存储和转发
日志处理应用:订阅并消费kafka队列中的日志数据
5.消息通讯
消息通讯是指,消息队列一般都内置了高效的通讯机制,因此也可以用在纯的消息通讯.比如实现点对点消息队列,或者聊天室等
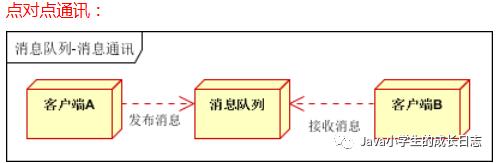
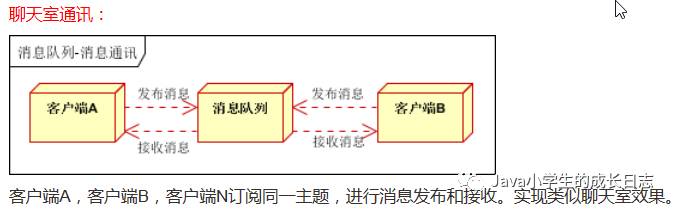
以上事假是消息队列的两种消息模式,点对点或者发布订阅模式.
三. 消息中间件示例
1.电商系统
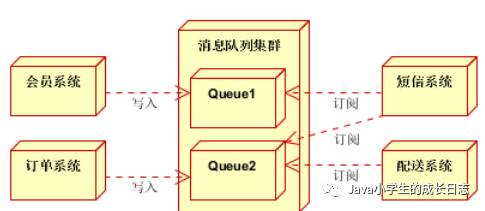
消息队列采用高可用,可持久化的消息中间件.比如activeMQ,RabbitMQ,RocketMQ,
1)应用将株高逻辑处理完成后,写入消息队列.消息发送是否成功可以卡其消息的确认模式.(消息队列返回消息接受成功状态后,应用在返回,这样保障消息的完整性)
2)扩展流程(发短信,配送处理)订阅队列消息.采用推或拉的方式获取消息并处理
3)消息将应用解耦的同事,带来了数据一致性问题,可以采用最终一致性方式解决.比如主数据写入数据库,扩展应用根据消息队列,并结合数据库方式实现基于消息队列的后续处理
2.日志收集系统
分为zookeeper注册中心,日志收集客户端,kafka集群和storm集群(OtherApp)四部分组成.
日志收集客户端,用于采集应用系统的日志,并将数据推送到kafka队列
kafka集群:接收,路由,存储,转发等消息处理
storm集群:与otherapp处于同一级别,采用拉的方式消费队列中的数据
kafka是LinkedIn开源的MQ系统,,主要特点是基于pull的模式处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,0.8开始支持赋值,不支持事务,适合产生大量数据的互联网应用的数据收集业务.
rabbitMQ是使用Erlang语言开发的开元消息队列系统,基于AMQP协议来实现,AMQP的主要特征是面向消息,队列,路由 (包括点对点和发布/订阅),可靠性,安全.AMQP协议更多用在企业系统内部,对数据一致性,稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次.
RocketMQ是阿里开源的消息中间件,它是纯Java开发,来了具有高吞吐量,高可用性,适合大规模分布式应用的特点.rocketMQ思路起源于kafka,但并不是kafka的一个copy,他对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景.
zoreMQ只是一个网络编程的pattern库,将常见的网络请求形式(分组管理,链接管理,发布订阅等)模式化,组件化,简言之socket之上,MQ之下.对于MQ来说,网络传输只是它的一部分,更多需要处理的是消息存储,路由,broker服务发现和查找,事务,消费模式(ac,重投),集群服务等
rabbitMQ/kafka/ZeroMQ都是提供消息队列服务,但是很大的却别
在面向服务框架中通过消息代理(比如rabbitMQ/Kafka等),使用生产者-消费者模式在服务间进行一步通讯是一种比较好的思想.
以为服务间以来由强耦合变成了松耦合.消息代理都会提供持久化机制,,在消费者负载高或者掉线的情况下会把消息保存起来,不会丢失,就是说生产者和消费者不需要同时在线,这是传统的请求-应答模式比较难做到的,需要一个中间件来专门做这件事,其次消息代理可以根据消息本身做简单的路由策略,消费者可以根据这个来做负载均衡,业务分离等
缺点也有,就是需要额外搭建下次代理集群( 但是优点是大于缺点的)
rabbitMQ支持AMQP(二进制),STOMP(文本),MQTT(二进制),HTTP(里面包装其他协议)等协议.kafka使用自己的协议
kafka自身服务和消费者都需要依赖zookeeper.
rabbitMQ在有大量消息堆积的情况下性能会下降,毕竟AMQP设计的初衷不是用来持久化海量信息的,而kafka一开始是用来处理海量日志的.
总的来说,rabbitMQ和kafka都是优秀的分布式消息代理服务,是要合理部署,基本上可以满足生产条件下的任何需求
以上是关于消息队列学习笔记的主要内容,如果未能解决你的问题,请参考以下文章