PCA分析(主成分分析)--结果解读
Posted 植保小萌新
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PCA分析(主成分分析)--结果解读相关的知识,希望对你有一定的参考价值。
主成分分析(PCA)是一个很好的工具,可以用来降低特征空间的维数。PCA的显著优点是它能产生不相关的特征,并能提高模型的性能。
PCA用于减少用于训练模型的特征维度数量,它通过从多个特征构造所谓的主成分(PC)来实现这一点。
PC的构造方式使得PC1方向在最大变化上尽可能地解释了你的特征,然后PC2在最大变化上尽可能地解释剩余特征,PC1和PC2通常可以解释总体特征变化中的绝大部分信息。
PCA它允许我们在二维平面上可视化数据的分类能力
PC(主成分)A(分析)
一、得分图
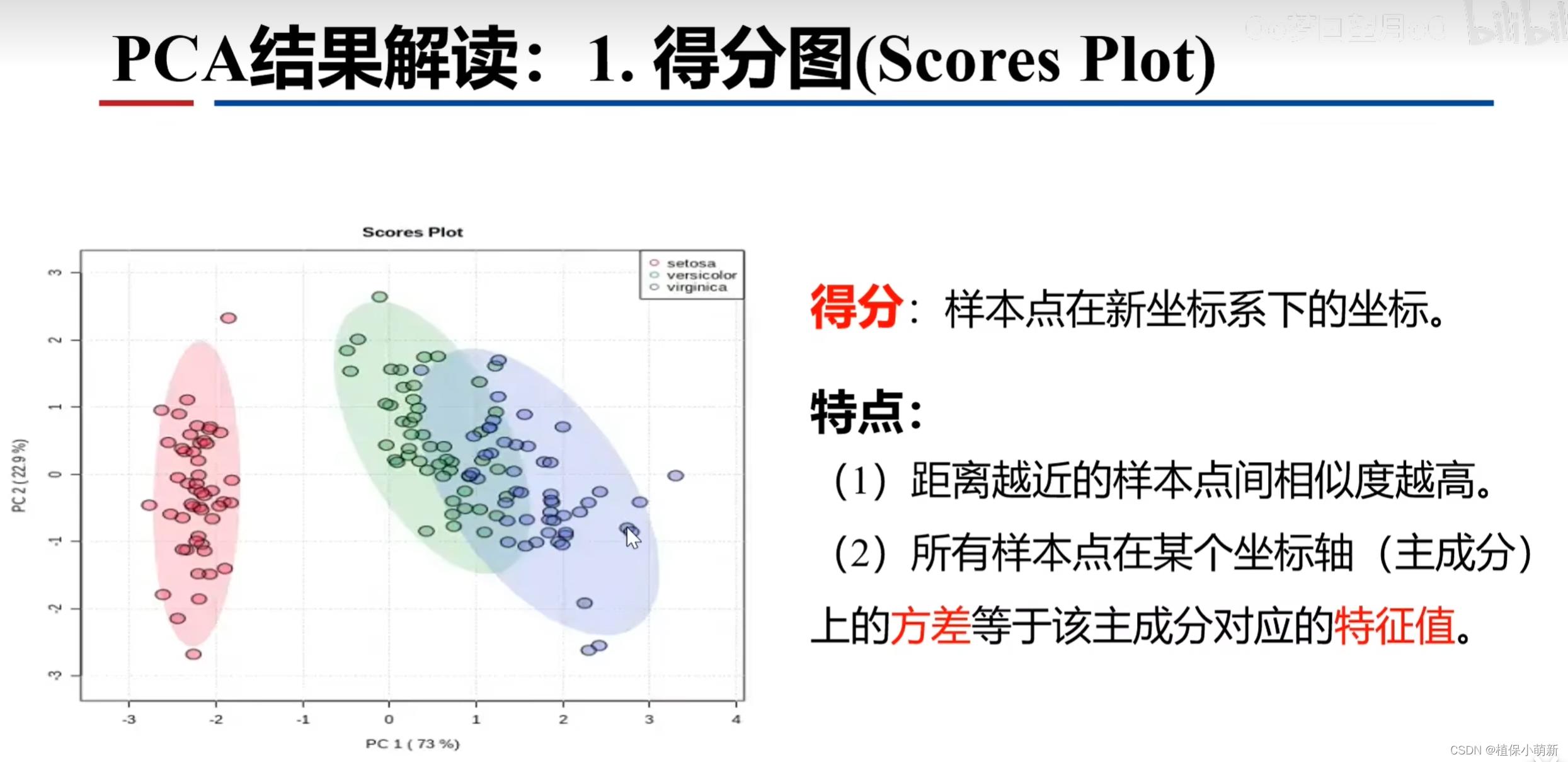
得分图是最常用的主成分分析的图,对于一些较好的结果能够将不同的散点进行聚集并将同类型的散点看为一个整体,如上图所示一共三个整体,粉色整体与其余两个整体相距较远,因此分别与二则差异显著,而绿色和紫色整体间部分重叠即相聚较近因此样本点9的相似度较高,差异不显著。
二、碎石图
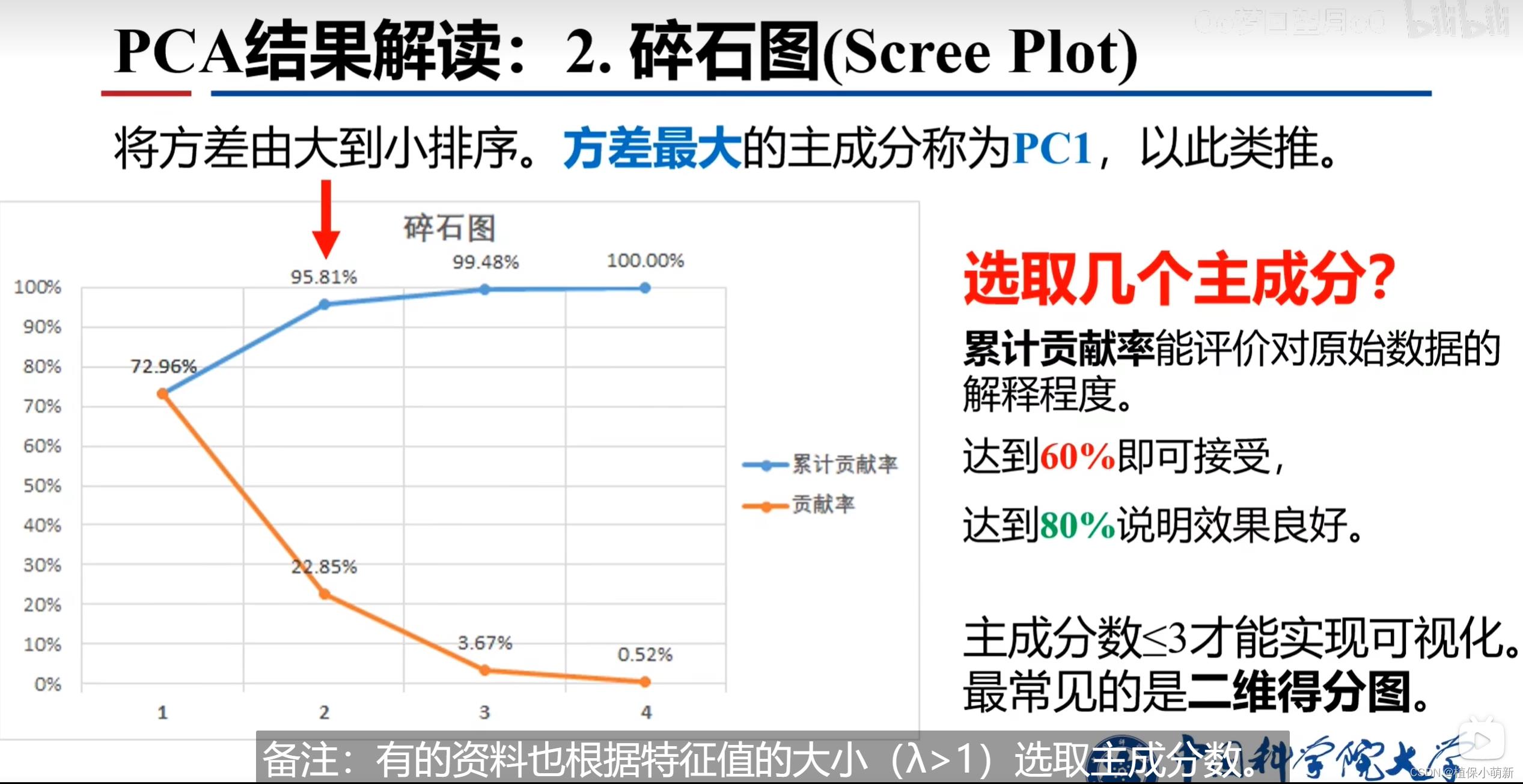
碎石图的作用之一就是能够让你在选择PC时进行提前抉择,看到底是选择PC1与PC2组合还是选择PC1与PC2组合和PC2与PC3组合......,而选择原则就是根据累计贡献率,一般认为60%是最低标准。贡献率:是指某个组成份方差除以所有主成分的方差之和,其具有最大贡献率的为PC1依次类推。方差最大的为PC1,第二大的为PC2依次类推。
补充:主成分的个数都是自己预先色设定好的,比如三种鲜花中的数据分别包含其花瓣长度、宽度、叶片长度、宽度等数十个指标,但其主成分为3个,即为其鲜花种类。这里理解起来可能比较抽象,但是大家可以想一下为什么我们要使用这个方法?我们用PCA分析的目的就是实现降维处理数据,比如三种鲜花数十个指标我们如果一一进行方差分析这将是无比巨大的工作量,而且也不一定能将结果讲的清楚,我们在图像中利用主成分在横轴和纵轴另这一个线性组合整体代表了以前一值为横坐标和纵坐标的情形。
三、载荷图

不管是组成份1(PC1)还是PC2,都是完全包含各个度量指标的,而PC的e个数在这个例子中是由花种类决定的且二者相等。
PC轴坐标代表的实际意义如图所示,按照对应关系分别为线性组合的系数,同时足矣相关性的描述(越近正相关性越强)
##素材来源:
主成分分析(PCA)
参考技术A 在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少指标会损失很多信息,容易产生错误的结论。因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。
PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主元,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
如图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
为什么u1比u2好呢?可以有两种解释,第一种解释是样本点到这个直线的 距离足够近 ,第二种解释是样本点在这个直线上的 投影能尽可能的分开 。
假设三维空间中有一系列点,这些点分布在一个过原点的斜面上,如果你用自然坐标系x,y,z这三个轴来表示这组数据的话,需要使用三个维度,而事实上,这些点的分布仅仅是在一个二维的平面上,那么,问题出在哪里?如果你再仔细想想,能不能 把x,y,z坐标系旋转一下 ,使数据所在平面与x,y平面重合?这就对了!如果把旋转后的坐标系记为x',y',z',那么这组数据的表示只用x'和y'两个维度表示即可!认为把数据降维后并没有丢弃任何东西,因为这些数据在平面以外的第三个维度的分量都为0,即z'的坐标为0。假设这些数据在z'轴有一个很小的抖动,那么我们仍然用上述的二维表示这些数据,理由是我们可以认为这两个轴x'和y'的信息是数据的主成分,而这些信息对于我们的分析已经足够了,z'轴上的抖动很有可能是噪声。
内积运算:
内积的几何意义:
注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
A与B的内积等于A到B的投影长度乘以B的模。再进一步,如果我们假设B的模为1,即让|B|=1|B|=1,那么就变成了:
则内积几何意义:设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度!
(1)什么是基?
如上图,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2)。但是 只有一个(3,2)本身是不能够精确表示一个向量的 。这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2,我们隐式把以x轴和y轴上正方向长度为1的向量为标准,即基为(1,0)和(0,1)。因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应,非常方便。
所以,要准确描述向量,首先要确定一组基,然后给出基所在的各个直线上的投影值,进而确定坐标值。
(2)什么是基变换?
实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量。例如:(1,1)和(-1,1)也可以成为一组基。
一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了。则(1,1)和(-1,1)同方向上模为1的新基为:
(3)用矩阵表示基变换
将(3,2)变换为新基上的坐标,就是用(3,2)与第一个基做内积运算,作为第一个新的坐标分量,然后用(3,2)与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标。可以稍微推广一下,如果我们有m个二维向量,只要将二维向量按列排成一个两行m列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示:
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果 。
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?看下图:
那么如何选择最优基这个问题被形式化为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
至此我们知道一下几点:
对原始数据进行(线性变换)基变换可以对原始样本给出不同的表示;
基的维度小于数据的维度可以起到降维的效果;
对基变换后的新样本求其方差,选取使其方差最大的基作为最优基。
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
至此,我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
推广到一般情况:
(1)拉格朗日法
(2) 奇异值分解法(SVD)
在PCA降维过程中,当进行协方差矩阵上求解特征值时,如果面对维度高达10000*10000 ,可想而知耗费的计算量程平方级增长。面对这样一个难点,从而引出奇异值分解(SVD),利用SVD不仅可以解出PCA的解,而且无需大的计算量。
PCA算法的主要优点有:
1、仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2、各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3、计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
1、主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2、方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
以上是关于PCA分析(主成分分析)--结果解读的主要内容,如果未能解决你的问题,请参考以下文章
R语言使用psych包的principal函数对指定数据集进行主成分分析PCA进行数据降维(输入数据为原始数据)使用nfactors参数指定抽取的主成分的个数principal函数结果解读
R语言使用psych包的principal函数对指定数据集进行主成分分析PCA进行数据降维(输入数据为原始数据)计算每个样本(观察)的主成分的分数计算得分与特定变量的相关性并解读结果