主成分分析(PCA)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主成分分析(PCA)相关的知识,希望对你有一定的参考价值。
参考技术A在前面我们学习了一种有监督的降维方法——线性判别分析(Linear Dscriminant Analysis,LDA)。LDA不仅是一种数据压缩方法还是一种分类算法,LDA将一个高维空间中的数据投影到一个低维空间中去,通过最小化投影后各个类别的类内方差和类间均值差来寻找最佳的投影空间。
本文介绍的主成分分析(Principe Component Analysis,PCA)也是一种降维技术,与LDA不同的是,PCA是一种无监督降维技术,因此PCA的主要思想也与LDA不同。LDA是一种有监督的分类兼降维技术,因此其最大化均值差最小化类内差的思想够保证在降维后各个类别依然能够很好地分开。但PCA只用来降维而无需分类,因此PCA需要考虑的是如何在降维压缩数据后尽可能的减少数据信息的损失。在PCA中使用协方差来表示信息量的多少,至于为什么能这么表示后面再进行介绍。下面我们从一些基本的线代知识开始。
在进行数据分析时我们的数据样本经常被抽象为矩阵中的一组向量,了解一些线代基础知识理解PCA非常重要,但在这里我们并不准备也不可能将所有的线代知识都罗列以便,因此这里我们仅会复习一些对理解PCA较为重要的东西。更多线代的内容可参考下面几个链接:
为了方便,我们这里以一个二维平面为例。
在前面我们说了,在数据处理时我们经常讲一个样本数据当作一个向量。在二维平面中,一个向量从不同的角度有不同的理解方式,例如对于向量 (-2, 3) T :
在我们描述任何东西的时候其实都是选择了一个参照系的,也即事物都是相对的,最简单的运动与静止(以静止的事物为参照),说一个有点意思的——人,人其实也是放在一个参考系中的,我们可以将其理解为生物种类系统,抛开这个大的系统去独立的定义人是很难让人理解的。向量也是这样的,虽然我们前面没有指明,但是上面的向量其实是在一个默认坐标系(或称为空间)中的,也即x,y轴,但是在线性代数中我们称其为基。在线代中任何空间都是由一组线性无关的(一维空间由一个基组成)基向量组成。这些基向量可以组成空间中的任何向量。
现在假设我们有如下一个矩阵相乘的式子:
因此,上面的例子可以有两种理解方式:
(1)如果我们将值全为1对角方阵视为标准坐标系,则它表示在 i=(1, -2) T 和 j=(3, 0) T 这组基底下的坐标 (-1, 2) T 在基底 (1, 0) T 、(0, 1) T 下的坐标,如下:
当我们讨论向量 (-1, 2) T 时,都隐含了一个默认的基向量假设:沿着x轴方向长度为1的 i,沿着y轴长度为1的j。
但是,(-1, 2) T 可以是任何一组基底下的向量。例如,他可能是i\'=(2,1) T , j\'=(-1, 1) T 这组基下的一个向量。此时他在我们默认坐标系 i=(1, 0) T ,j=(0, 1) T 下的计算过程如下:
我们可以从另一个角度理解基地变换的过程:我们先 误认为 (-1, 2) T 是坐标系i=(1, 0) T ,j=(0, 1) T 下的坐标,此时我们通过线性变换[[2, -1], [1, 1]](每个嵌套列表看做一行)把坐标轴i,j(基坐标)分别变换到了新的位置 i1=(2, 1) T , j1=(-1, 1) T (他们也是用默认坐标系表示的),即[2, -1], [1, 1]]。此时我们把“误解”转换成了真正的向量。如下:
在上面我们说了矩阵是一种变换,现在我们继续从这个角度来理解特征值和特征向量。为了方便理解,我们在这里做一个类比——将变换看作物理中的作用力。我们知道一个力必须有速度和方向,而矩阵对一个向量施加的变换也是一样的。考虑一下特征向量的定义:
上面介绍了一些基本的线性代数相关的知识,下面开始介绍PCA的原理。
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
要完全数学化这个问题非常繁杂,这里我们用一种非形式化的直观方法来看这个问题。
为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0(这样做的道理和好处后面会看到)。中心化的数据为:
通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
以上图为例,可以看出如果向x轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向y轴投影最上面的两个点和分布在x轴上的两个点也会重叠。所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,我们用数学方法表述这个问题。
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
如果我们还是单纯只选择方差最大的方向,很明显,这个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。 从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
可以看到,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积除以元素数m。
当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标: 将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
上面我们导出了优化目标,但是这个目标似乎不能直接作为操作指南(或者说算法),因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是我们来了灵感:
假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X:
然后我们用X乘以X的转置,并乘上系数1/m:
根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设C=1/m(XX T ),则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的 。这样说可能还不是很明晰,我们进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为P对X做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
现在所有焦点都聚焦在了协方差矩阵对角化问题上,有时,我们真应该感谢数学家的先行,因为矩阵对角化在线性代数领域已经属于被玩烂了的东西,所以这在数学上根本不是问题。
由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量λ重数为r,则必然存在r个线性无关的特征向量对应于λ,因此可以将这r个特征向量单位正交化。
则对协方差矩阵C有如下结论:
以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。
到这里,我们发现我们已经找到了需要的矩阵P:P = E T .
P是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是C的一个特征向量。如果设P按照Λ中特征值的从大到小,将特征向量从上到下排列,则用P的前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
PCA的特征向量的求解除了使用上述最大化方差的矩阵分解方法,还可以使用最小化损失法,具体可参见: 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA) 。
总结一下PCA的算法步骤:
设有m条n维数据。
LDA和PCA都用于降维,两者有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
首先我们看看相同点:
我们接着看看不同点:
参考:
PCA的数学原理
线性代数的直觉
线性判别分析LDA原理总结
主成分分析(PCA)原理及R语言实现
如果你的职业定位是数据分析师/计算生物学家,那么不懂PCA、t-SNE的原理就说不过去了吧。跑通软件没什么了不起的,网上那么多教程,copy一下就会。关键是要懂其数学原理,理解算法的假设,适合解决什么样的问题。
学习可以高效,但却没有捷径,你终将为自己的思维懒惰和行为懒惰买单。
PCA的原理和普通实现
PCA原理
2019年05月16日
用了这么久的PCA,看了很多人的讲解,基本上都是一上来就讲协方差矩阵、特征值、特征向量和奇异值分解,其实这对新手是非常不友好的。
PCA只是一种思想,核心就是线性变化,线性代数里的工具只是一种高效的实现PCA的手段,但并不是唯一的工具。
PCA的核心思想:假设我们的数据有D1, D2,···,Dn个维度,PCA就是要构造一个线性变换,PCi = W1D1 + W2D2 +···+ WnDn,Wj就是第j维度在第i个PC中的权重。找PC有先后顺序,我们总是先找总方差最大的PC,方差解释度是统计里最重要的一个概念。然后我们再找与前一个PC线性无关的能解释最多方差的下一个PC,以此类推,知道得到所有的n个PC。最终的结果就是原先的n个维度通过线性变换,变成了新的n个线性无关的按方差解释度排序的PC。主成分中的“主principal”针对的就是方差解释度。
先从一个玩具的案例开始,熟悉的R数据mtcars,取其中1、3列,二维可视化方便些:
mpg disp Mazda RX4 21.0 160 Mazda RX4 Wag 21.0 160 Datsun 710 22.8 108 Hornet 4 Drive 21.4 258 Hornet Sportabout 18.7 360 Valiant 18.1 225


我们先用R的prcomp包跑一下,熟悉一下PCA的输入输出:
my_data <- mtcars[,c(1,3)] head(my_data) plot(my_data, main="raw data") my_data <- scale(my_data, center = T, scale = T) plot(my_data, main = "scaled data") # mtcars.pca <- prcomp(mtcars[,c(1:7,10,11)], center = TRUE,scale. = TRUE) mtcars.pca <- prcomp(my_data, center = F,scale. = F) summary(mtcars.pca) plot(mtcars.pca$x, main = "after PCA")
Importance of components:
PC1 PC2
Standard deviation 1.3592 0.39045
Proportion of Variance 0.9238 0.07622
Cumulative Proportion 0.9238 1.00000
PCA的输入很简单,就是一个矩阵,行为样本,列为维度/特征;
这里我把scale这一步单独列出来了,大家可以看下scale的效果是什么,PCA的原始数据如果没有scale,PCA的结果就是错的,因为PCA非常看重方差占比,我们的数据的单位往往千差万别,必须scale,使得不同维度的方差可比。
PCA的输出,sdev、rotation、x;sdev标准差是每个PCA的方差解释度的平方根,肯定是递减的;rotation旋转,很形象,PCA只是把原维度做了旋转而已,rotation是个矩阵里面就是原维度如何通过线性变换,得到PC的;x就是PCA之后原来数据在新的PC下的坐标。
sdev the standard deviations of the principal components (i.e., the square roots of the eigenvalues of the covariance/correlation matrix, though the calculation is actually done with the singular values of the data matrix). rotation the matrix of variable loadings (i.e., a matrix whose columns contain the eigenvectors). The function princomp returns this in the element loadings. x if retx is true the value of the rotated data (the centred (and scaled if requested) data multiplied by the rotation matrix) is returned. Hence, cov(x) is the diagonal matrix diag(sdev^2).
For the formula method, napredict() is applied to handle the treatment of values omitted by the na.action.
输入输出明确了,接下来我们开始做一些个性化的事情:
1. 如果我有新的数据,如何看它在原PCA里的位置?
看下PC是如何得到的,从rotation里我们可以得到线性变换的方程。
PC1 PC2 mpg -0.7071068 0.7071068 disp 0.7071068 0.7071068
PC1 = -0.7071068 * mpg + 0.7071068 * disp
PC2 = 0.7071068 * mpg + 0.7071068 * disp
把新数据代入到这个方程里就可以求新数据的PC score了,在R里,一般用矩阵乘法实现:Newdata %*% rotation
2. 如何找对我们某个PC贡献最大或top10的维度?取绝对权重最大的top维度集合
在对RNA-seq数据进行PCA分析时非常实用,我们发现了感兴趣的PC,往往要找哪些基因贡献最大,或者直接可视化我们某个基因在前两个PC中的位置。
3. 如何在原数据里可视化我们的投射/旋转方法?
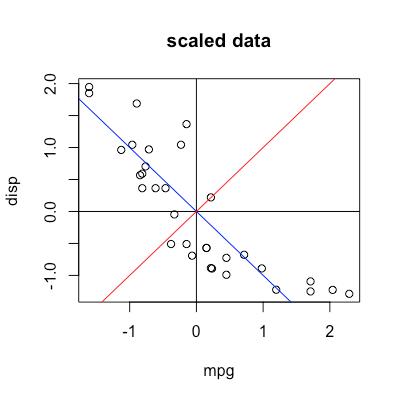
蓝线就代表了我们原坐标下的PC1方向,如何反向找出蓝线的斜率呢?
假设蓝线为y=kx,那么向量[1, k]在rotation的作用下必然变为[c, 0],c的大小和符号是不确定的,但我们有一个确定的0,有点线性代数基础的就知道如何解k了。
plot(my_data, main = "scaled data") abline(v=0) abline(h=0) abline(coef = c(0, -0.7071068/0.7071068), col="blue") abline(coef = c(0, 0.7071068/0.7071068), col="red")
那么我们就知道了第一个方差最大的方向是y = -0.7071068/0.7071068 * x,第二个方差最大的就是y = 0.7071068/0.7071068.
普通实现
如何用普通方法,不用线性代数和矩阵来求呢?
先明确总方差这个概念:
单一维度的方差好理解,直接求var就行,比如我们scale后,mpg和disp的方差就都为1了。
但是我们的数据PCA之后,PC1的方差就为1.847425,PC2的方差为0.1524486。
Importance of components:
PC1 PC2
Standard deviation 1.3592 0.39045
Proportion of Variance 0.9238 0.07622
Cumulative Proportion 0.9238 1.00000
如何理解总方差呢?其实很简单,就是所有PC的方差之和。PC1的Proportion of Variance是这么算的:1.847425/(1.847425 + 0.1524486)
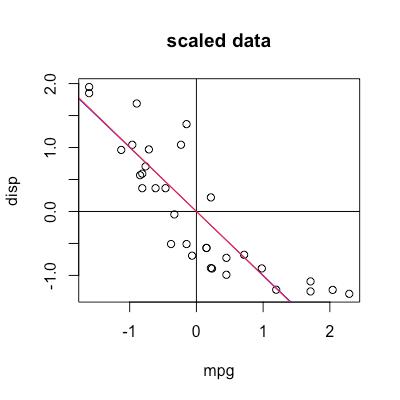
现在我们手动来做PCA,先求第一个PC,就是要找蓝线y = kx,如何求k?
我们要把所有点投射到蓝线上,然后要让所有的投影点的在蓝线这个维度方差最大化。
这里没办法了,点太多不可能手算,所以只能用最大似然估计了。
最大似然估计用的mle函数,此函数需要一个似然函数,变得就是A,就是Ax+By+C=0,我们就是不停地试A,然后看什么情况下我们所有的点在此线上投影的方差最大。
最后的结果是:1.009254*x + y = 0,可以看到与原来的线几乎重合,我们手动算出来的PC和prcomp算出来的一模一样。
这里的这个似然函数的构造有一点技巧:需要知道怎么算点到线的距离;根据勾股定理算投影长度,需要判断投影的正负。
PC1定了,其实PC2也就定了,因为只有一条线与PC1正交,就是垂直的线。所以也就不重复算了。
似然函数和最大似然估计不清楚的可以看我的这个文章:似然函数 | 最大似然估计 | likelihood | maximum likelihood estimation | R代码
##################
nll <- function(A) {
# A=1
B=1; C=0
m <- my_data[,1]
n <- my_data[,2]
if (A!=0) {
raw_sign <- as.integer(n > -m/A)
raw_sign[raw_sign==0] <- -1
} else {
raw_sign <- 1
}
p <- sqrt(((A*m+B*n+C)^2 / (A^2 + B^2)) + m^2 + n^2) * raw_sign
var(p)
}
est <- stats4::mle(minuslog=nll, start=list(A=1), )
summary(est)
plot(my_data, main = "scaled data")
abline(v=0)
abline(h=0)
abline(coef = c(0, -0.7071068/0.7071068), col="blue")
abline(coef = c(0, -1.009254), col="red")
参考:
Principal component analysis - wiki
Principal Component Analysis in R
主成分分析(Principal components analysis)-最大方差解释
PCA的线性代数实现
自此,我们已经了解了PCA的思想内涵,普通实现。
这个时候再来讲PCA的线性代数实现才是合适的,为什么线性代数里的工具能高效的实现PCA?
R的PCA包,prcomp和princomp,The function princomp() uses the spectral decomposition approach. The functions prcomp() and PCA()[FactoMineR] use the singular value decomposition (SVD).
待续~
2019年04月25日
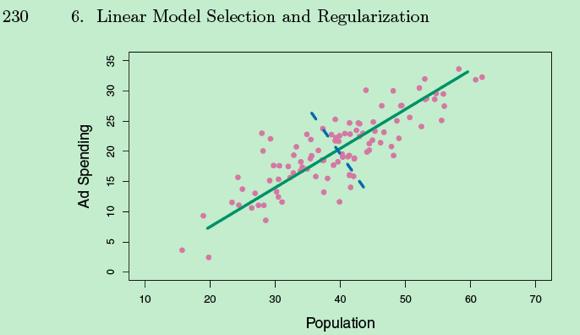
不该先说covariacne matrix协方差矩阵的,此乃后话,先从直觉理解PCA。先看一个数据实例,明显的两个维度之间有一个相关性,大部分的方差可以被斜对角的维度解释,少数的noise则被虚线解释。
我们的任务就是通过线性变化,找出一个维度能最大的解释数据的方差;然后继续找正交的第二个维度,直至最后一个正交维度。
不用矩阵思维我们都可以做,构造一个线性组合,优化方案就是方差最大,然后寻找另一个正交维度。
熟悉了普通解法,我们再来矩阵的解法。
PCA里最重要的就是covariacne matrix协方差矩阵,它完美的包含了我们需要的信息,变量内的方差,变量间的相关程度协方差;
我们想要干什么呢?我们的目的是将covariacne matrix对角化,也就是变量内的方差最大,变量间的相关程度协方差为0;
PCA的灵魂是什么?特征值和特征向量。Ax=λx. A是covariacne matrix,λ是特征值,x是特征向量。这个线性变化意味着什么呢?意味着在经过x处理(线性变换/移动)通过正交矩阵正交化后,A变成了特征值对角矩阵,也就是变量内的方差最大,变量间的相关程度协方差为0。这也解释了为什么covariacne matrix的特征值其实就是每个PC的variance。按variance排列也就自然而然了。同时也解释了为什么转化后的PC彼此线性无关,因为它是正交矩阵特征值构成的是对角矩阵。
特征向量的矩阵表征的就是线性变化,所以原先的数据矩阵在施加x运动后,会投射到新的PC里,这也从直觉上理解了PCA的精髓,线性投射。
PCA本身没有降维的功能,只是PCA告诉我们了每个PC的variance解释度,我们选取top 99%的PCs就能解释绝数据里的大部分信息,所以PCA才有了降维的功能!!!
大误区:没有明白特征向量的意义,搞混了特征向量、原数据矩阵和协方差矩阵之间的关系。没有完全理解对角化和行列式求解之间的联系。如何直观理解特征向量矩阵/投影矩阵的由来还是有点难度的!!!
矩阵特征值是对特征向量进行伸缩和旋转程度的度量,实数是只进行伸缩,虚数是只进行旋转,复数就是有伸缩有旋转。我们一般求得的是实数,所以特征值最大表示在这个方向的运动最大。
如何求实对称矩阵的特征值和特征向量?
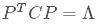
看来不把线性代数学通,想彻底搞懂PCA是不可能的了。
讲得人很多,但没有真正讲清楚的。从特征分解到协方差矩阵:详细剖析和实现PCA算法
求协方差矩阵的特征值和特征向量已经很明确了,但对角化的目的,以及为什么协方差矩阵的特征向量具有投影的功能没讲清楚。
协方差矩阵是实对称矩阵,不具有运动特性,所以不该从运动的角度去解释。
从定义出发,Ax=cx:A为矩阵,c为特征值,x为特征向量。矩阵A乘以x表示,对向量x进行一次转换(旋转或拉伸)(是一种线性转换),而该转换的效果为常数c乘以向量x(即只进行拉伸)。我们通常求特征值和特征向量即为求出该矩阵能使哪些向量(当然是特征向量)只发生拉伸,使其发生拉伸的程度如何(特征值大小)。这样做的意义在于,看清一个矩阵在那些方面能产生最大的效果(power),并根据所产生的每个特征向量(一般研究特征值最大的那几个)进行分类讨论与研究。知乎Rex
talia有个PPT讲得非常严谨。
不得不惊叹数学的神奇,一个复杂问题用这么精简巧妙的方式解决了。
对于基因表达(>30000 gene),表观(十万以上enhancer)等超多特征的数据,降维是绕不开的,尤其是在计算样本或细胞间的关系时,降维能有效的减少计算量。
降维的另一个作用就是可视化,所以分析单细胞数据总能见到PCA、t-SNE和diffusionMap。人最多可以看三维的数据,还得移动看,学术上严谨些,只用二维数据。
PCA,以基因表达数据为例,每个基因在样本间都是在变得,而且有很多是相互相关的,举个例子,如果两个/一群基因是完全相关的,那我们完全只需要一个变量/维度就可以解释样本里的所有变异。PCA就是通过线性变化,把原来的所有变量(n个)转化为新的n个PC,这些PC彼此间线性无关,而且可以根据变异的解释量来排序PC,每个变量对新的PC都有一个简单的线性转换公式。
PCA的数学基础:要有线性代数基础。PCA和SVD的联系。
问题:
1.为什么说PCA有降维的功能?明明线性变化后有与变量数相等的PC。
2.PCA适合给什么样的数据降维?什么情况下用其他降维方法会更好?
3.能不能把PCA的大致计算过程写下来?
4.PCA的应用,我有一个很感兴趣的维度,请把对该维度贡献最大的变量找出来;我有一个新的样品,能否给我一个新的PC打分
5.variance,如何理解特征向量表征了变异比例?
6.如何直观理解协方差,covariance?
7.PCA里是如何利用特征值和特征向量的?
8.如何理解“主成分分析就是把协方差矩阵做一个奇异值分解,求出最大的奇异值的特征方向”?
9.PCA和ICA有什么关系?
10.特征值和特征向量单独表示很好理解,如何写成对角矩阵形式?矩阵和向量基本运算要熟练。这里纠结了好久
11.PCA在图像压缩和图像识别方面也有应用。
12. 为什么特征向量的矩阵可以用于空间转换?
学习是一个思维发散和收敛的过程,不断深入,不断回归。
为了防止我又忘了我的目的,以下梳理一下我的任务:
1. 如何对RNA-seq的数据做PCA分析?
2. PCA原理;如何做到重新分配variance的?
3. 如何理解得到的PC;
4. 有个感兴趣的PC,如何提取出关键基因;
5. 如何把一个新的样本投射到已经建立的PCA坐标里,打分预测?
好了,开始发散,先到线性代数里走一圈。
PCA计算的起点是协方差矩阵,方差描述的是一群点偏离均值的程度(偏离度(平方)的均值/期望),标准差是方差的标准化,具有与原数据一样的单位/量纲。协方差描述的是两个变量之间的协同关系(两个变量与其各自均值的协变度),是相关性系数的前体(除以两个变量的标准差后就是相关性系数)。
协方差公式简单,但却有许多惊奇的特性,它居然可以描述两个变量的协同变化程度。协方差矩阵更是计算生物学的利器(协方差矩阵有什么意义?),很多工具分析的起点。
问题:为什么有了标准差还要方差,两者不是重复吗?为什么方差的度量选择了平方?为什么描述性统计的两个核心指标是均值和方差,而不是均值和标准差?参考链接, 可导。
题外话:为什么样本的方差要除以n-1而不是n?参考链接:无偏估计。

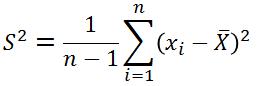


接下来就是求协方差矩阵covariance matrix的特征值和特征向量了eigenvalue and eigenvector。

直观理解,A就是我们的矩阵,它可以看作是运动,v是特征向量,特征值和特征向量表征的是一个矩阵的特征(如何理解矩阵特征值?),在可视化工具里,给定一个矩阵,我们可以找到它的一些特征值和特征向量,意思就是特征向量在运动后(乘以A),方向不变,长度变了,变化的长度就是λ。
线性代数就是解方程,前面解的方程是Ax=b,现在解的方程是Ax=λx.
说多了感觉脱离实际了,show me your code
需要注意的细节:scale会影响结果
head(mtcars) res <- prcomp(mtcars, scale. = F, center = F, retx = T) # res2 <- princomp(mtcars) plot(res$x[,1:2]) res$x[1:5,1:5] res$sdev
res$rotation[1:5,1:5] recover <- as.matrix(mtcars) %*% as.matrix(res$rotation) recover[1:5,1:5]
> head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
一般的主成分分析返回的信息有: sdev标准差,平方后就是每一个PC所能解释的方差,也就是特征向量;rotation对应了特征向量的矩阵;x就是最终的投射后的矩阵,就是原矩阵乘以特征向量rotation。
有个无法还原的就是Ax=λx,协方差矩阵乘以特征向量矩阵不等于右边,不知道哪里出错了。需要看下源码
The Mathematics Behind Principal Component Analysis 数学基础,步骤很清楚,怎么做讲得很清楚,但没讲出缘由,为什么可以这么做
Principal Component Analysis in R: prcomp vs princomp R代码
Principal Component Analysis (PCA) - THE MATH YOU SHOULD KNOW! 数学部分完全不懂
Principal Components Analysis: Theory and Application to Gene Expression Data Analysis 正统paper
再谈协方差矩阵之主成分分析 - 传神的讲了协方差矩阵的神奇作用
PCA的数学原理 非常不错了
总结一下:做PCA,首先我们会构建特征/变量的协方差矩阵,然后求其特征值和特征向量,top特征向量构建的矩阵就能将原始数据投射到新的相互独立的且排好序的PC空间里。
新的问题:
1. 为什么这样就可以投射到新的PC了?特征向量可以理解为对原来的所有维度进行重构了,特征向量相当于是对应的线性权重,这就是PCA核心的线性变换过程。为什么特征向量就是权重,如何理解?
2. 为什么求解的特征值就是对应特征向量的方差,这些是怎么联系起来的?必须理解协方差矩阵的特征值和特征向量意味着什么!
深刻理解到,线性代数和概率论不学好,搞统计研究就会举步维艰。
Dimensionality reduction for visualizing single-cell data 需要总结一下
番外篇:
1. PCA与聚类的关系,PCA不是聚类,它只是降维,只是在RNA-seq当中,好的replicates往往会聚在一起,才会误以为PCA可以做聚类。PCA是降维,是聚类的准备工作,最常见的聚类是k-means聚类,为了降低计算复杂度,我们可以在PCA的结果里做聚类。
2. 协方差矩阵为什么比相关性矩阵用途更广?因为协方差里包含了两种信息,变量间的相关性以及变量内部的方差,相关性标准化后丢失了太多的信息,所以用得少了。
例子:以小学生基本生理属性为案例,分享下R语言的具体实现,分别选取身高(x1)、体重(x2)、胸围(x3)和坐高(x4)。具体如下:
> student<- data.frame( + x1=c(148,139,160,149,159,142,153,150,151), + x2=c(41 ,34 , 49 ,36 ,45 ,31 ,43 ,43, 42), + x3=c(72 ,71 , 77 ,67 ,80 ,66 ,76 ,77,77), + x4=c(78 ,76 , 86 ,79 ,86 ,76 ,83 ,79 ,80) + ) > student.pr <- princomp(student,cor=TRUE) > summary(student.pr,loadings=TRUE) Importance of components: Comp.1 Comp.2 Comp.3 Comp.4 Standard deviation 1.884603 0.57380073 0.30944099 0.152548760 Proportion of Variance 0.887932 0.08231182 0.02393843 0.005817781 Cumulative Proportion 0.887932 0.97024379 0.99418222 1.000000000 Loadings: Comp.1 Comp.2 Comp.3 Comp.4 x1 -0.510 0.436 -0.139 0.728 x2 -0.513 -0.172 -0.741 -0.398 x3 -0.473 -0.761 0.396 0.201 x4 -0.504 0.448 0.524 -0.520 > screeplot(student.pr,type="lines")

standard deviation:标准差
Proportion of Variance:方差的占比
Cumulative Proportion:累计贡献率
由上图可见四项指标做分析后,给出了4个成分,他们的重要性分别为:0.887932、0.08231182、0.02393843、0.005817781,累积贡献为:0.887932、0.97024379、0.99418222 1.000000000各个成分的碎石图也如上,可见成份1和成份2的累积贡献已经达到95%,因此采用这两个成份便可充分解释学生的基本信息。
可以算出 Z1 和 Z2的公式
> temp<-predict(student.pr) > plot(temp[,1:2])

参考链接:R语言与数据分析之五:主成分分析(还有很多系列,慢慢看)
主成分分析(Principal Component Analysis,PCA)的目标是用一组较少的不相关的变量代替大量相关变量,同时尽可能保留原始变量的信息,推导所得的变量就成为主成分,是原始变量的线性组合。也就是将N个变量(N维),通过线性组合,降维到K个综合变量(K维,K <N)来归纳性解释某一个现象。
先举个简单例子帮助理解吧:
某篮球俱乐部有40名男同学,同学之间各个指标存在或大或小的差异,包括身高、体重、视力、百米速度、肺活量、每天练球时长、睡眠时间等指标。在季度选拔中,40名同学进球得分数(成绩)存在差异,那么这些指标是否均与成绩相关?或者相关性有多大?
此时可能就要用到PCA,分析方法简述如下:
1选择初始变量
比如以上7个指标作为变量(a1 - a7),40名同学作为样本。
2对原始数据矩阵进行标准化,做相关系数矩阵
(1)原始数据矩阵:每行为40名男同学的各项指标值,每列为各项指标在40名同学中的体现;
(2)因为各个指标度量单位不同,取值范围不同,不宜直接由协方差矩阵出发,因此选择相关系数矩阵。
3计算特征值及相应特征向量
4判断主成分的个数
最常见的方式是根据特征值判断,一般选择特征值大于1的变量数作为PC个数,假如,此项分析中特征值大于1的有两个,则最终可以有2个主成分(具体主成分个数可以根据实际研究调整)。
5得到主成分表达式
通过分析得到第一主成分(PC1)和第二主成分(PC2),假设表达式如:(a1*表示a1标准化后的数值)

6结合数据的实际意义开展分析
PC1比PC2更能解释样本间差异的原因(如下图中横纵轴的百分比)。PC1的线性组合中a1、a2、a3、a6贡献度较大(前面的系数较大),PC2的线性组合中a5贡献度较大。以PC1为横轴,各个样本根据成绩大小有明显区分,说明以上7个指标中,身高、体重、视力、每天练球时长这4个指标与同学的成绩相关性更强。为了迎合线性组合的概念,应该找个更合适的词语来综合描述身高、体重、视力、每天练球时间这4个指标,以涵盖这4个指标的意义。理解了以上的概念,再将主成分分析用于RNA-seq也很容易理解。

参考链接:
StatQuest: Principal Component Analysis (PCA) clearly explained (2015) 必须一看
How to perform dimensionality reduction with PCA in R 具体实现
主成分分析(Principal components analysis)-最大方差解释
Principal component analysis for clustering gene expression data
主成分分析 - stanford
主成分分析法 - 智库
主成分分析(Principal Component Analysis)原理
主成分分析及R语言案例 - 文库
主成分分析法的原理应用及计算步骤 - 文库
【机器学习算法实现】主成分分析(PCA)——基于python+numpy
主成分分析(PCA)原理详解(推荐)
主成分分析-生物信息
主成份分析(PCA)在生物芯片样本筛选中的应用及在R语言中的实现
以上是关于主成分分析(PCA)的主要内容,如果未能解决你的问题,请参考以下文章